







【摘要】 在最初开发ARM架构时,处理器的时钟速度和内存的访问速度大致相同。今天的处理器内核要复杂得多,其时钟速度可以快上几个数量级。但是,外部总线和内存设备的频率并没有扩大到同样的程度。有可能实现小块的片上SRAM,它可以以与内核相同的速度运行,但是与标准的DRAM块相比,这种RAM非常昂贵,因为后者的容量可以达到数千倍。在许多基于ARM处理器的系统中,访问外部存储器需要几十甚至几百个内核周期。
cache的技术背景
在最初开发ARM架构时,处理器的时钟速度和内存的访问速度大致相同。今天的处理器内核要复杂得多,其时钟速度可以快上几个数量级。但是,外部总线和内存设备的频率并没有扩大到同样的程度。有可能实现小块的片上SRAM,它可以以与内核相同的速度运行,但是与标准的DRAM块相比,这种RAM非常昂贵,因为后者的容量可以达到数千倍。在许多基于ARM处理器的系统中,访问外部存储器需要几十甚至几百个内核周期。
缓存是位于核心和主内存之间的一个小型快速内存块。它存储了主存储器中资料的副本。对高速缓冲存储器的访问比对主存储器的访问快得多。每当内核读取或写入一个特定的地址时,它首先在高速缓存中寻找。如果它在高速缓存中找到该地址,它就会使用高速缓存中的数据,而不是对主内存进行访问。这大大增加了系统的性能,因为它减少了缓慢的外部存储器访问时间的影响。
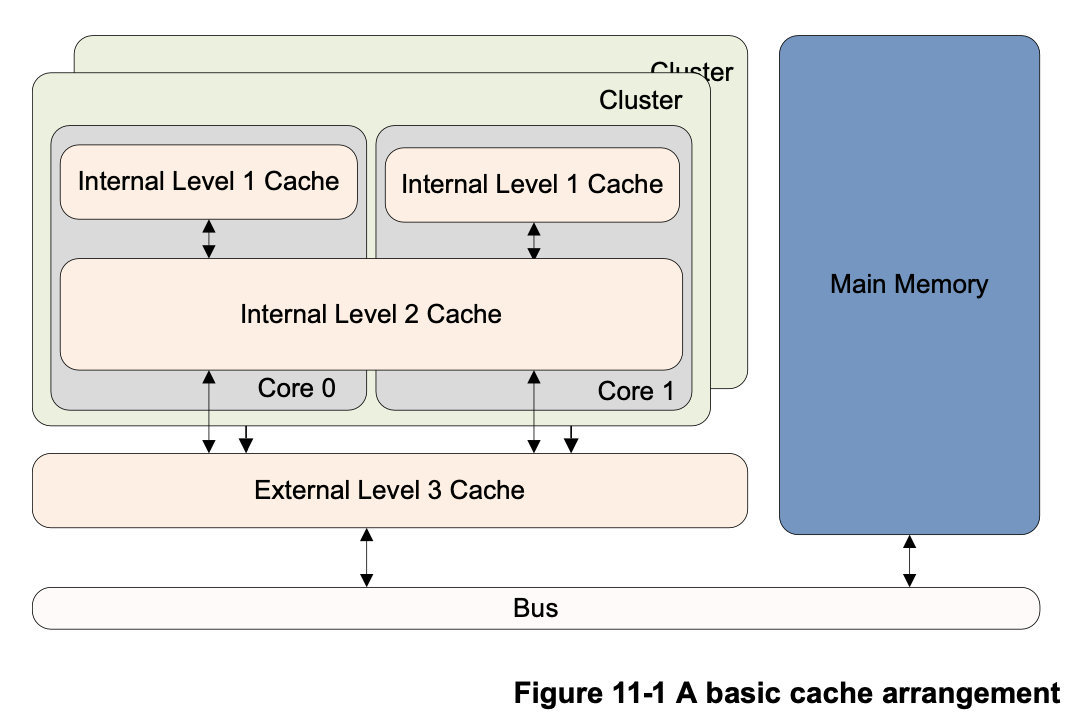
实现ARMv8-A架构的处理器通常有两级或更多的高速缓存。这通常意味着处理器的每个内核都有小的L1指令缓存和数据缓存。Cortex-A53和Cortex-A57处理器通常采用两级或多级缓存,即一个小的L1指令和数据缓存和一个较大的、统一的L2缓存,该缓存在集群的多个内核之间共享。此外,还可以有一个外部L3高速缓存作为外部硬件块,在集群之间共享。
向高速缓存提供数据的初始访问并不比正常速度快。对缓存值的任何后续访问才会更快,而性能的提高正是来自于此。核心硬件会检查缓存中所有的指令获取和数据读取或写入,尽管你必须将内存的某些部分,例如包含外围设备的部分,标记为不可缓存的。因为高速缓存只容纳了主内存的一个子集,所以你需要一种方法来快速确定你要找的地址是否在高速缓存中。
少数情况下,高速缓存中的数据和指令与外部存储器中的数据可能不一样;这是因为处理器可以更新高速缓存的内容,而这些内容还没有被写回主存储器。另外,一个代理可能会在一个核心拿了自己的拷贝后更新主内存。这是一个连贯性的问题,在第14章中有描述。当你有多个内核或内存代理(如外部DMA控制器)时,这可能是一个特别的问题。(埋点+1)
在冯-诺依曼架构中,指令和数据使用一个缓存(一个统一的缓存)。修改后的哈佛架构有独立的指令和数据总线,因此有两个高速缓存,一个指令高速缓存(I-Cache)和一个数据高速缓存(D-Cache)。在ARMv8处理器中,有不同的指令和数据L1高速缓存,由统一的L2高速缓存支持。缓存需要保存地址、一些数据和一些状态信息。
cache长什么样?
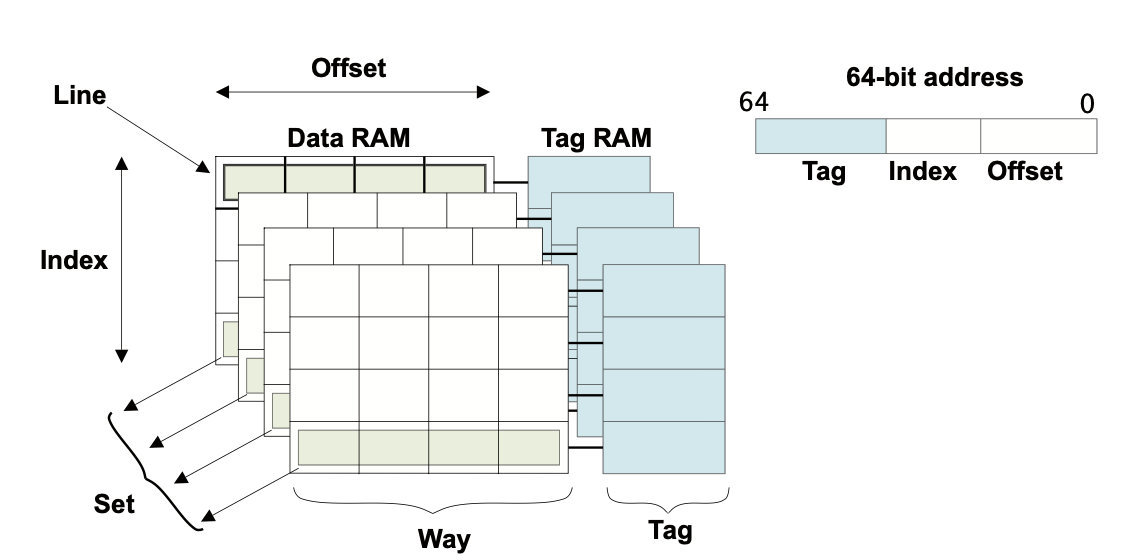
下面我们一个个解释上图中的cache名词:
-
Tag
Tag是cache内存地址的一部分,用于关联与某一行数据的主内存地址。
64位地址的最高位(Tag)告诉cache信息来自于主内存。cache的总大小衡量了其所能容纳的数据量。尽管用于容纳Tag值的RAM不包括在计算中,但是Tag确实占用了cache中的物理空间。
-
Cache Line 一个Tag关联一组Cache数据
如果为每个Tag地址保存一个字的数据,效率会很低,所以通常在同一个Tag下将几个位置组合在一起。这种逻辑块通常被称为Cache Line,指的是缓存中最小的可加载单元,即主内存中的一个连续字块。当一个Cache Line包含已缓存的数据或指令时,它被认为是有效的,而当它不包含已缓存的数据或指令时,则是无效的。
与每一行数据相关的是一个或多个状态位。通常情况下,你有一个有效位,将该行标记为包含可使用的数据。这意味着该地址标签代表了一些真实的值。在数据缓存中,你可能还有一个或多个脏位,标记缓存行(或其一部分)是否包含与主内存内容不相同(比其新)的数据。
-
Index
Index是内存地址的一部分,它决定了在cache的第几行可以找到这个地址。
64位地址的中间位,即Index,标识了此地址是在Cache的第几行。Index被用作查找Cache RAM的地址,不需要作为Tag的一部分进行存储。
-
Way
一条Way是一个缓存的细分,每条Way的大小相等,并以相同的方式进行索引(Index)。一个Set由共享一个特定索引的所有方式的Cache Line组成。
这意味着地址的低几位(称为Offset)不需要存储在标签中。你需要的是整行的地址,而不是行内每个字节的地址。因此,64位地址中其余的五个或六个最不重要的位总是0。
总结一下:Cache由一片片Set和对应的Tag表组成。对于每片Set,它又由Cache Line一条条组成。Tag表标记了各行Tag所关联的Cache Line。
注意:只有Set和Way是架构上的定义,其余名词只是为了查找cache所提出的抽象化概念,并不是物理上的定义。
包容性和排他性cache
对于一个简单的内存读取,例如,单核处理器中的LDR X0, [X1]。
如果X1指向内存中的一个位置,该位置被标记为可缓存的,那么就会在L1数据缓存中进行缓存查找。如果在L1高速缓存中找到了地址,那么数据就会从L1高速缓存中读取并返回给内核。
如果地址在L1缓存中没有找到,但在L2缓存中找到了,那么该缓存行就会从L2缓存中加载到L1缓存中,并将数据返回给内核。这可能会导致一行被驱逐出L1以腾出空间,但它可能仍然存在于较大的L2缓存中。

如果地址不在L1或L2缓存中,数据会从外部内存加载到L1和L2缓存中,并提供给内核。这可能导致线路被驱逐。
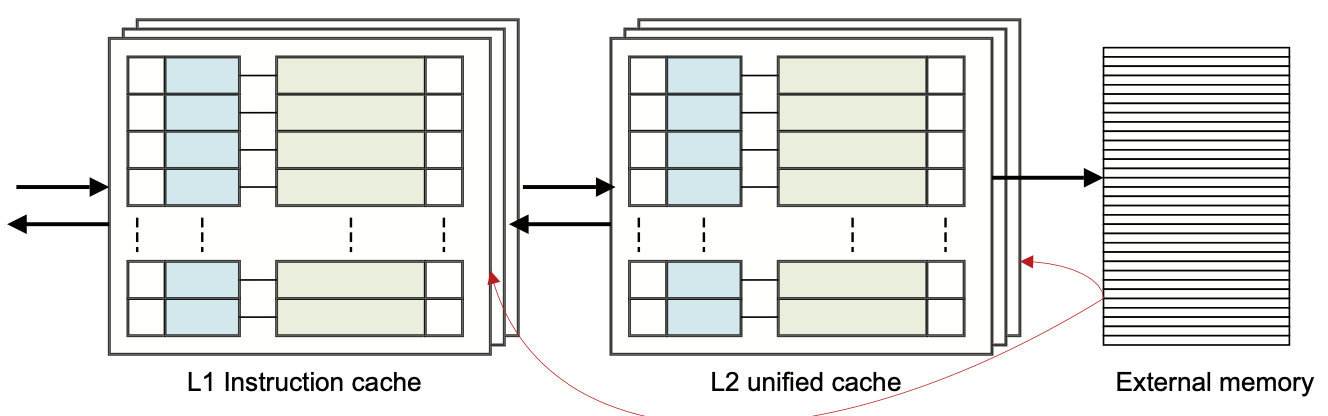
这是个相当简单的观点。对于多核和多集群系统来说,在执行从外部内存加载之前,可能还要检查集群内或其他集群的内核的L2或L1缓存。此外,在这一点上没有考虑L3或系统缓存。
这是一个包容性的高速缓存模型,同样的数据可以同时出现在L1和L2缓存中。在排他性缓存中,数据只能出现在一个缓存中,一个地址不能同时出现在L1和L2缓存中。
直接映射型
对于直接映射型的cache来说,每组只有一个Cache Line。
如下图所示的cache演示,这个cache只有4个Cache Line,每行有4个字,1个字是4字节。Cache控制器根据地址中的Bit[5:2]来选择Cache中的字,使用Bit[13:6]作为索引,来选择4个Cache Line中的1个,Bit[43:14]存储标记值。
查询这个Cache时,当Index和Tag值与查询地址相等并且此Cache包含有效数据时,则发生Cache Hit,然后使用offset值来寻找Cache中的数据。如果这个Cache包含有效数据但是Tag中表示其他地址的值时,那么就需要替换这个Cache Line。由于这个时候出现了频繁的Cache换入换出,就会产生严重的Cache thrashing(颠簸),严重降低系统性能。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1216
1216











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









