







前言
在传统的图像去模糊的网络中,由于输入图像质量较低,不能提供准确的几何先验,而且高质量的参考图像是没有的,会极大限制去模糊网络的性能。为了突破这一限制,论文在人脸图像恢复领域提出了基于StyleGAN和去模糊结合的网络,先对图像进行初步的去模糊,然后利用已经经过预训练的styleGAN这种人脸生成模型在去模糊后图像的基础上进行生成,从而恢复图像更多人脸的纹理、边缘信息,使得看起来更加逼真,兼顾了真实性和保真度。其实本质上个人理解还是一个条件生成的过程,将低质量图像作为条件生成高质量图像。
创新点如下:
①将人脸图像恢复任务与GAN这种具有丰富先验的盲脸生成模型相结合;
②提出了一种网络结构,和CS-SFT层以及新的损失函数,可以很好地兼顾真实性和保真度。
网路结构
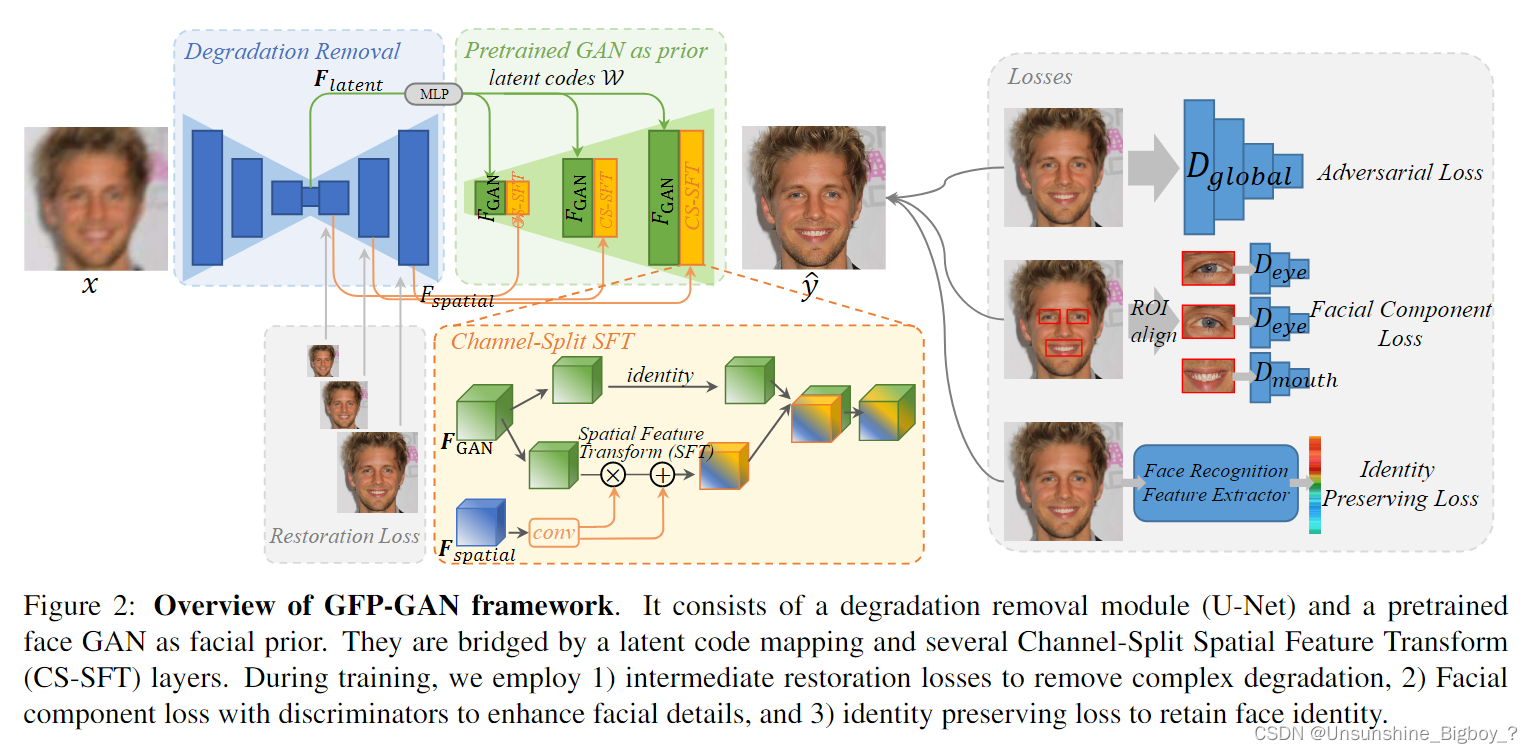
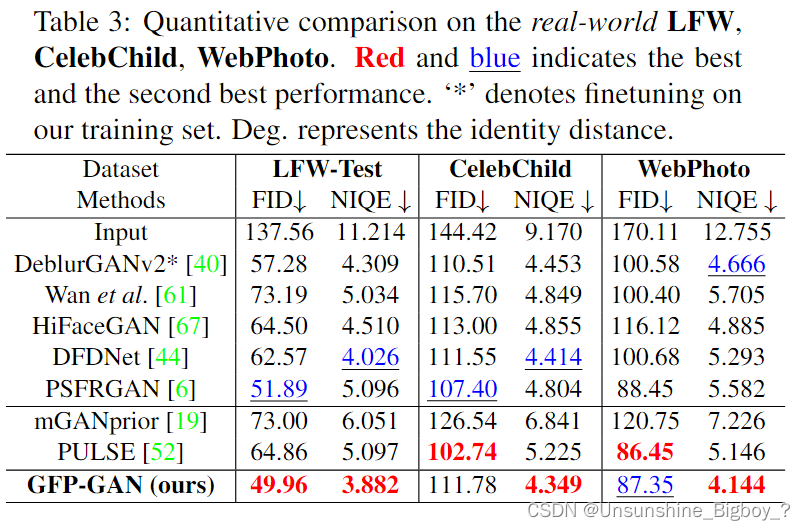
上图就是模型的整体结构,主要由两部分组成,第一部分是一个退化消除网络,可以理解成就是一个U-net结构的去模糊网络,第二部分是一个已经预训练好的类似于styleGAN2的脸部生成网络,它们通过CS-SFT层连接起来。在第一部分中,Unet结构的去模糊网络又分为下采样层(编码器)、中间层和上采样层(解码器),输入的模糊图像在经过上采样层的编码器之后来到中间层,此时将其称为图像的潜在特征 F F F l a t e n t latent latent , F F F l a t e n t latent latent 经过一个MLP之后转化为潜在编码 W W W,作为StyleGAN2的输入,可以生成卷积特征表示为 F F F G A N GAN GAN,包含了大量的脸部细节信息。在Unet的下采样解码器中,将不同尺度(分辨率)的输入去模糊后的图像称为 F F F s p a t i a l spatial spatial,和 F F F G A N GAN GAN一起作为CS-SFT的另外一部分输入进行空间调制。
Degradation Removal Module
如上所描述,其实就是一个去模糊的Unet结构的网络,主要的作用有两个,第一个是去模糊,第二是产生不同尺度的特征编码 F F F l a t e n t latent latent和 F F F s p a t i a l spatial spatial,还有一个细节是针对不同尺度的去模糊图像,都会有GT计算L1损失。
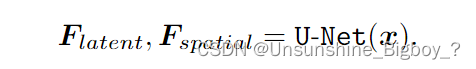
Generative Facial Prior and Latent Code Mapping
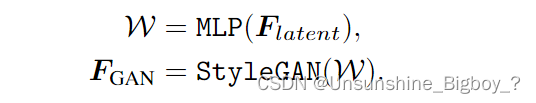
Channel-Split Spatial Feature Transform
首先,不同尺度的 F F F s p a t i a l spatial spatial经过卷积后估计出α和β两个参数,然后与 F F F G A N GAN GAN在维度上均分成两部分,分别是split0和split1,split1进行下式和α和β的计算得到 F F F o u t p u t output output,然后split0进行identity操作,具体没有写这是干什么的。最后进行维度上的拼接得到输出图像。至于每个尺度是怎么最后进行合成一张图像的也没有具体说清楚。
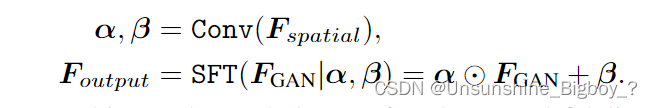
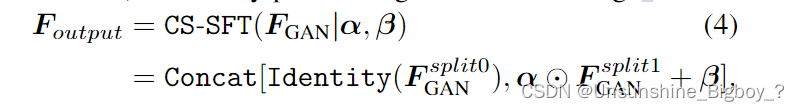
损失函数
损失函数主要包含四个部分
①重建损失:参考ESRGAN,其中包括了除了L1损失之外,还有一个感受损失,用的也是VGG-19的网络来评估图像的真实性。
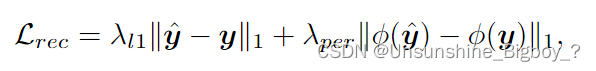
②对抗损失:训练的一个辨别器来对图像的真实性进行估计。

③脸部组成损失:分别对左眼、右眼以及嘴巴三个部位训练局部辨别器对图像ROI区域进行辨别,除此之外,还加入了Gram矩阵,可以很好的计算特征相关性,捕捉纹理信息。
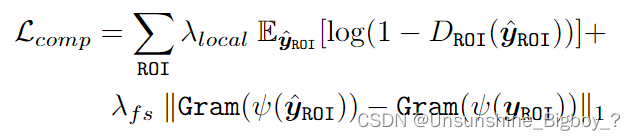
④身份损失:采用了预先训练的人脸识别ArcFace模型,该模型捕捉了身份识别中最突出的特征。身份保留损失强制恢复结果在紧凑的深层特征空间中与地面真实保持较小的距离。
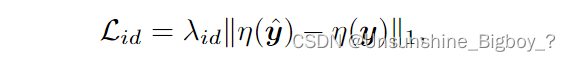
总损失计算如下:
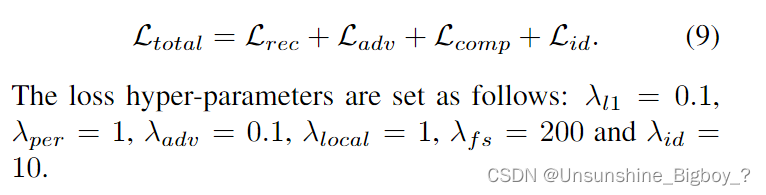
实验
在数据集中,使用的是FFHQ,与之前的图像超分辨任务直接进行bicubic不一样,论文模拟图像退化过程,模糊图像退化如下式,随机挑选参数σ, r, δ q 分别从{0.2 : 10},{1 : 8}, {0 : 15}, {60 : 100}
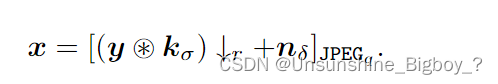
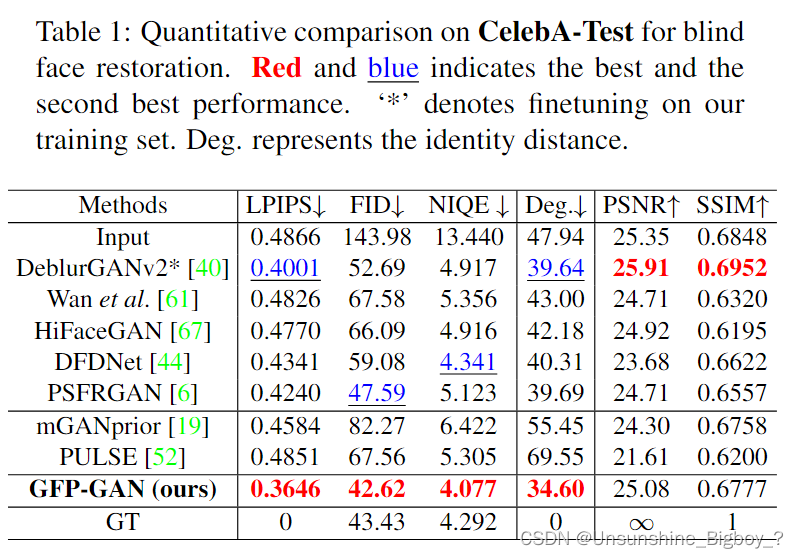
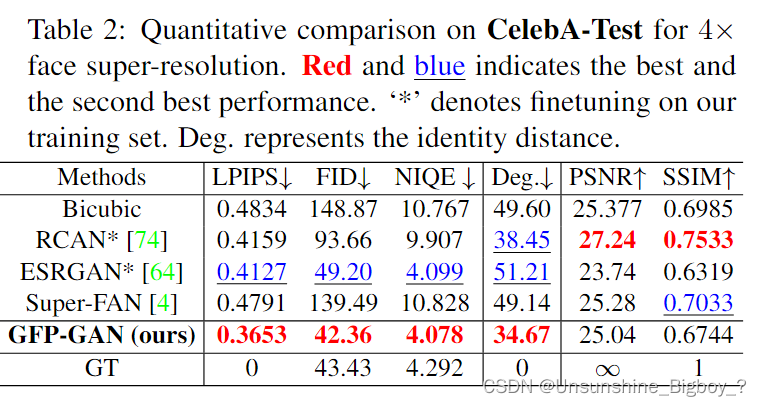
 局限
局限

上图展示的是模型的局限性,对于退化比较严重的图像来说,恢复的图像比较扭曲,像是人工进行后期处理的图片。
总结
GFP-GAN把图像去模糊和生成GAN模型进行了结合,使得从去模糊网络中得到图像的特征条件,然后经过GAN生成后回复高频的信息,所以理论上来说还是一个条件生成模型。之所以效果这么好,很大一部分原因是损失函数的设计比较详细,以往的模型直接以PSNR直接作为损失函数,这其实是不太合理的。这篇论文分别将人脸局部、全局的特征、纹理相似性特征、重建特征、对抗损失都考虑在内,另外一个细节是在训练模糊图像时不时直接使用Bicubic的图像,而是随机退化,这样训练的模型更加贴近真实退化过程。但是,文中也描述了不足,这种合成的退化数据集还是不够贴合真实情况。
解决的问题:
如何从低分辨率低质量的真实图像中获得较好的先验知识,复原人脸图像
提出:GFP-GAN。其包含了一个退化去除模块 和预训练的人脸GAN作为人脸先验。通过直接的潜在代码映射和几个通道分割空间特征变换(CS-SFT)层以从粗到精方式连接。
贡献:
提出了一种新颖的GFP-GAN框架,该框架具有精巧的架构设计,并能融合人脸生成先验。带有CS-SFT层的GFP-GAN在一次正向传递中实现了保真度和纹理忠实度之间的良好平衡。
网络框架
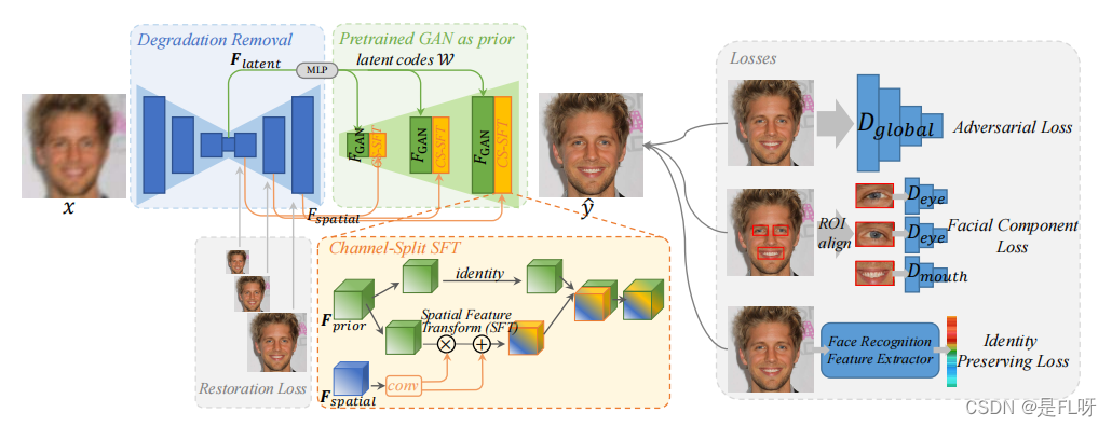
第一步:退化去除模块。基于Unet网络。用于提取清晰潜在特征 F_latent 和 不同分辨率空间特征F_spatial。
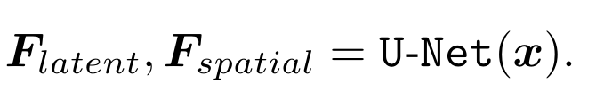
第二步:生成式人脸先验和潜在特征匹配。将潜在特征F_latent匹配到中间潜在编码W ,该编码W 用于从可学习的人脸GAN分布中检索最相近的人脸特征F_GAN;然后,能够用GAN特征获得生成式人脸先验 F_prior
第三步:通道分割的空间特征转换。利用第二步的先验特征 F_prior和第一步的不同分辨率空间特征F_spatial生成高清图像。
但是这种方法难以在真实性和保真度之间达到好的平衡;因此本文将先验特征分解为身份特征部分(用于保留)以及变换特征部分(用于特征调制),采用以下的形式进行求解:
损失函数:
1 重构损失:图像像素级重构以及VGG层次的感知loss重构
2 对抗损失
3 人脸成分损失 鉴别损失+特征样式损失
( 1)鉴别损失:首先使用ROI对齐裁剪感兴趣的区域,对于每个区域,我们训练单独的小型局部鉴别器来区分恢复成分是否真实,从而使生成的面部成分接近自然的面部成分分布
(2)特征样式损失:尝试匹配真实和恢复的面片的Gram矩阵统计
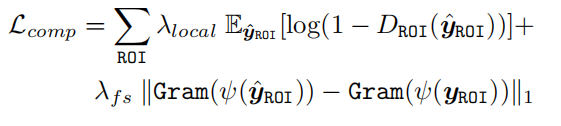
4 人脸身份loss: 采用了预训练人脸识别ArcFace模型
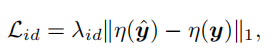



















 1331
1331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











