










在本文中,通过优锐课核心java学习笔记中,我们可以看到,将展示如何使用ELK Stack和Kafka部署建立弹性数据管道所需的所有组件。码了很多专业的相关知识, 分享给大家参考学习。如有不足之处,欢迎补充建议!

在发生生产事件后,恰恰在你最需要它们时,日志可能突然激增并淹没你的日志记录基础结构。 为了防止Logstash和Elasticsearch遭受此类数据突发攻击,用户部署了缓冲机制以充当消息代理。
Apache Kafka是与ELK Stack一起部署的最常见的代理解决方案。 通常,Kafka部署在托运人和索引器之间,用作收集数据的入口点:
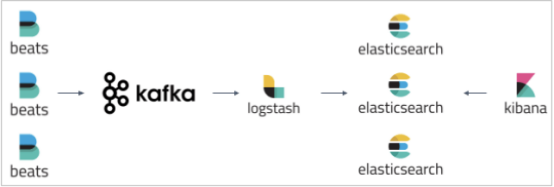
在本文中,我将展示如何使用ELK Stack和Kafka部署建立弹性数据管道所需的所有组件:
Filebeat-收集日志并将其转发到Kafka主题。
Kafka-代理数据流并将其排队。
Logstash-汇总来自Kafka主题的数据,对其进行处理并将其发送到Elasticsearch。
Elasticsearch-为数据建立索引。
Kibana-用于分析数据。
我的环境
要执行以下步骤,我使用本地存储在AWS EC2上设置了一台Ubuntu 16.04计算机。 在现实生活中,你可能会使所有这些组件都在单独的计算机上运行。
我在VPC的公共子网中启动了实例,然后设置了一个安全组,以允许使用SSH和TCP 5601(对于Kibana)从任何地方进行访问。 最后,我添加了一个新的弹性IP地址,并将其与正在运行的实例关联。
本教程使用的示例日志是Apache访问日志。
步骤1:安装Elasticsearch
我们将从在堆栈中安装主要组件Elasticsearch开始。 从7.x版开始,Elasticsearch已与Java捆绑在一起,因此我们可以通过添加Elastic的签名密钥来直接前进:
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
为了在Debian上安装Elasticsearch,我们还需要安装apt-transport-https软件包:
sudo apt-get update
sudo apt-get install apt-transport-https
下一步是将存储库定义添加到我们的系统中:
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo
tee -a /etc/apt/sources.list.d/elastic-7.x.list
剩下要做的就是更新你的存储库并安装Elasticsearch:
sudo apt-get update && sudo apt-get install elasticsearch
在引导Elasticsearch之前,我们需要使用Elasticsearch配置文件在/etc/elasticsearch/elasticsearch.yml中应用一些基本配置:
sudo su
vim /etc/elasticsearch/elasticsearch.yml
由于我们在AWS上安装Elasticsearch,因此我们将Elasticsearch绑定到localhost。 此外,我们需要将EC2实例的私有IP定义为符合主机资格的节点:
network.host: "localhost"
http.port:9200
cluster.initial_master_nodes: ["<InstancePrivateIP"]
保存文件并使用以下命令运行Elasticsearch:
sudo service elasticsearch start
要确认一切正常,请将curl指向:http:// localhost:9200,你应该看到类似以下输出的内容(在开始担心看不到任何响应之前,请给Elasticsearch一两分钟):
{
"name" : "ip-172-31-49-60",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "yP0uMKA6QmCsXQon-rxawQ",
"version" : {
"number" : "7.0.0",
"build_flavor" : "default",
"build_type" : "deb",
"build_hash" : "b7e28a7",
"build_date" : "2019-04-05T22:55:32.697037Z",
"build_snapshot" : false,
"lucene_version" : "8.0.0",
"minimum_wire_compatibility_version" : "6.7.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
步骤2:安装Logstash
接下来,ELK中的“ L” — Logstash。 Logstash将要求我们安装Java 8,这很好,因为这也是运行Kafka的要求:
sudo apt-get install default-jre
验证是否已安装Java:
java -version
openjdk version "1.8.0_191"
OpenJDK Runtime Environment (build 1.8.0_191-8u191-b12-2ubuntu0.16.04.1-b12)
OpenJDK 64-Bit Server VM (build 25.191-b12, mixed mode)
由于我们已经在系统中定义了存储库,因此运行安装Logstash所需要做的全部工作:
sudo apt-get install logstash
接下来,我们将配置一个Logstash管道,该管道将从Kafka主题中提取我们的日志,处理这些日志并将其发送到Elasticsearch进行索引。
让我们创建一个新的配置文件:
sudo vim /etc/logstash/conf.d/apache.conf
粘贴以下配置:
input {
kafka {
bootstrap_servers => "localhost:9092"
topics => "apache"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
}
geoip {
source => "clientip"
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
}
}
如你所见,我们正在使用Logstash Kafka输入插件来定义Kafka主机和我们希望Logstash从中提取的主题。 我们正在对日志进行一些过滤,并将数据发送到我们的本地Elasticsearch实例。
保存文件
文章先写道这里,下次再详更第二章节!
第二更已经更出来,点击下方即可直达。
喜欢这篇文章的可以点个赞,欢迎大家留言评论,记得关注我,每天持续更新技术干货、职场趣事、海量面试资料等等
如果你对java技术很感兴趣也可以加入我的java学习群 V–(ddmsiqi)来交流学习,里面都是同行,验证【CSDN2】有资源共享。
不要再用"没有时间“来掩饰自己思想上的懒惰!趁年轻,使劲拼,给未来的自己一个交代















 230
230











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









