







这个系列是我在观看 B 站一位大佬的讲解后做的笔记
希望我的笔记能让你们更加容易搞懂吧
简单回忆一下上一篇文章
直接看一张图吧:
上一篇文章我们简单的了解了 MySQL 中的存储引擎 Innodb 的数据结构 B+ 树的特点
(没看过的可以往之前翻一翻吧)

本文包含内容:
- 什么是全表扫描和索引树扫描呢?
- 什么叫聚簇索引/非聚簇索引呢?聚簇索引和非聚簇索引的区别?
- 主键索引的优缺点?
- 非聚簇索引有那些类型?
正文开始
1. 什么是全表扫描和索引树扫描呢?
之所以先说这个概念,是为了方便之后我们理解索引。
上图:
在解释一下:当我们需要查询的是一个没有建立索引的字段的时候,Innodb 的工作流程就会从最小的数据开始查,直到有满足条件的数据存在的时候才会返回,
相反 ,当我们查询的是一个带索引的数据的时候,工作流程就可以直接从索引页中获取到数据所存储的位置了~
毫无疑问这种情况是很消耗性能的,如果数据量很大的情况下查询效率必然会受影响
~
上面这个例子中的 索引页是自增主键创建的索引,一般我们叫做 “ 主键索引 ” 或者 “聚簇索引”,这个索引是不需要自己手动创建的,当然主键可以不是 id (一般都是 id),可以用一个 唯一的字段充当

2.什么叫聚簇索引/非聚簇索引呢?聚簇索引和非聚簇索引的区别?
我大致梳理下来,索引可以分成两类
- 聚簇索引 (可以说成:聚集索引 或者 主键索引)
- 非聚簇索引 (可以说出:辅助索引,二级索引 ) . 包含很多中索引的设计
从上面这个例子中我们知道了,
主键索引一般定义的字段是自增主键
~
那么我们就需要知道什么是二级索引了
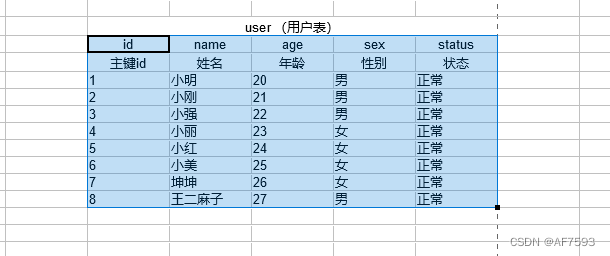
那我们来举个栗子:
假设我有如上图的数据表
~
我们已经知道了Innodb 会按照自增主键Id 默认创建一个 B+ 树 的结构
如果我们执行的语句是select * from user where id = 8因为索引树的存在会很快的获取到数据
如果我们查询的语句是select * from user where age = 27这种情况下会进行全表扫描。
~
好 , 这个时候我们知道了,需要给 age 也创建一个索引方便我们查询
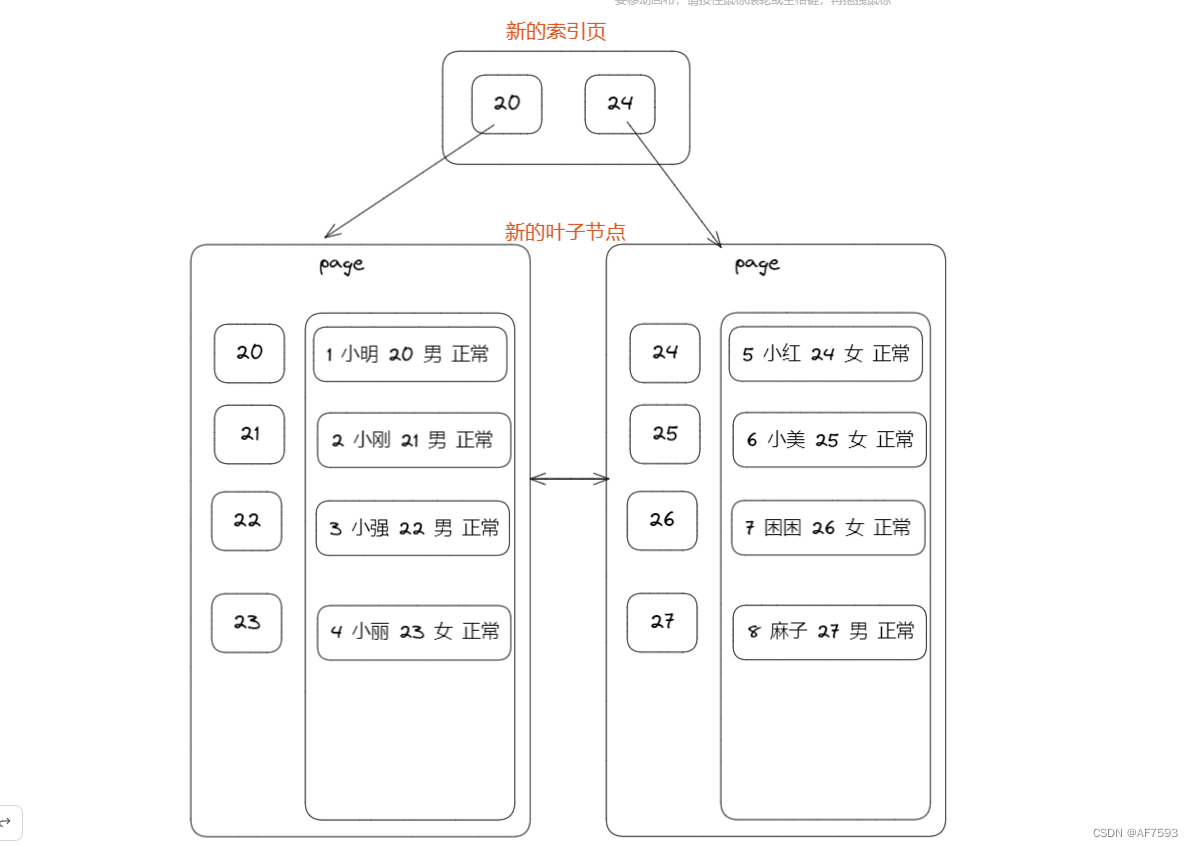
当我们创建索引的时候,Innodb 就会自动给我们创建一个新的 B+ 树结构,如图:
这里并不是从 主键的B+ 树直接拷贝一份新的数据出来,数据真正的存储地址肯定只有一份的,多出来的数据是不好维护的
~
所以MySQL Innodb 生成的新的 索引树是这样的:
叶子节点上只记录 数据所对应的 id 值。
所以执行流程就变成了二级索引树-> 获取到Id -> 主键索引树 -> 获取数据
而 二级索引树获取到Id 之后再去 主键索引树 中取数据的操作就叫做回表
创建的这个新的索引树 就是二级索引
~
那么他们的区别是什么呢?(我主要总结了这两点)
- 聚簇索索引来保存数据,而非聚簇索引的目的仅仅是加快查询速度
- 聚簇索引是唯一的 (默认创建),非聚簇所以可以有多个(不会默认创建)

3. 主键索引的优缺点?
简单描述了
主键索引的工作流程之后
我们肯定不难发现了:
优点:
- 没有回表的操作,可以直接根据主键获取数据,查询效率高
- B+ 树的 next 概念对于主键的 顺序和查找范围速度非常快
缺点:
- 如果不按照顺序来插入会导致页分裂,影响性能,所以一般都会按照 自增的主键Id
- 主键不可更新
4. 非聚簇索引有那些类型?
大家可以百度搜一搜,关键词 mysql 索引。
一大堆的文章,文章的可理解度可能不是很高,而且还会冒出很多 类似于”复合索引,联合索引“ 等名称
如果是初学者,绝对会在索引这个重要的知识点上被绕晕的
~
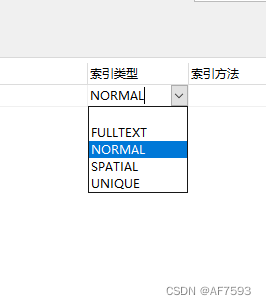
所以我这边就按照 Navicat Premium 中 列出的索引类型来聊一聊
// todo :容我去查查资料在书写以下内容
~
Normal 普通索引
字面意思,大多数情况下都可以使用的索引
~
Unique 唯一索引
表示唯一的,不允许重复的索引
举个例子说明: 每个人都有且只有一个身份证号,如果需要创建这个身份证号的索引,肯定就选择这个唯一索引
~
Full Text 全文索引 (不常用)
举个例子说明: 模糊匹配的时候like + %会查询所有数据,但是数据量大的情况下使用这个索引就会很有效。但是在精准度比较低,(资料上说的,我也没有实际用过)
~
SPATIAL 空间索引(俺也不常用)
这个我也不是很理解,我简单的把 MySQL 上的解释搬过来
MySQL具有与OpenGIS类对应的数据类型。某些类型只能保存单个几何值:GEOMETRY, POINT,LINESTRING,POLYGON
GEOMETRY 能够保存任何类型的几何值。其他的单值类型POINT、LINESTRING以及POLYGON只能保存特定几何类型的值















 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









