






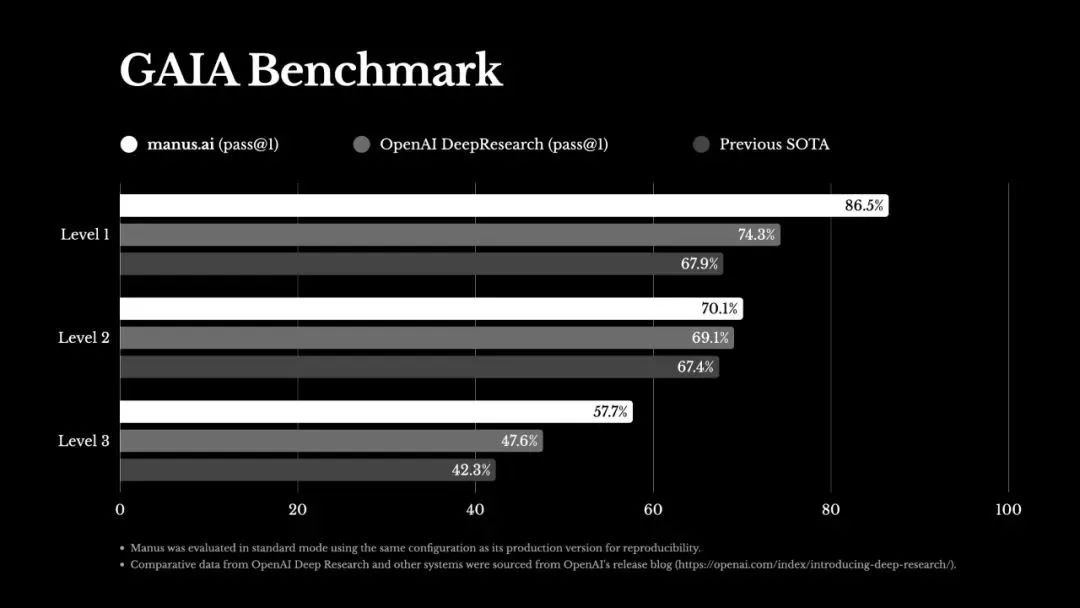
前言:就在今天凌晨, Manus 横空出世 ,在 GAIA Benchmark中排名第一,在各项能力实测中也表现惊人,话题热度居高不下,我们也将马不停蹄,在下一期为大家带来 Manus 的详细内容。
本期我们还是继续盘点当前模型的发布情况。由于春节前我们盘点了一波发版模型的合集,有20个模型在春节前发布;没想到节后业内更卷,截止到现在又有32个模型发布,上涨了60%;而且还有不少模型预告发布,25年确实是模型的赛跑时代。
目录
01.模型发布动态
02.模型发展的趋势和创新
2.1 多模态趋势明显
2.2 模型架构创新
2.3 Agent能力进化
03.技术报告研究
04.后期发布预告
05.后期发布预告
01. 模型发布动态
今年模型行业在年前就被 DeepSeek 的开源震了一波,年后各家公司也加速了迭代模型的节奏。像上周有 DeepSeek 的开源周,同时段国外 Open AI 发布了 GPT-4.5,Anthropic 发布了 Claude 3.7 Sonnet ,截止到 3月 7 日,已有 32 个模型发布。
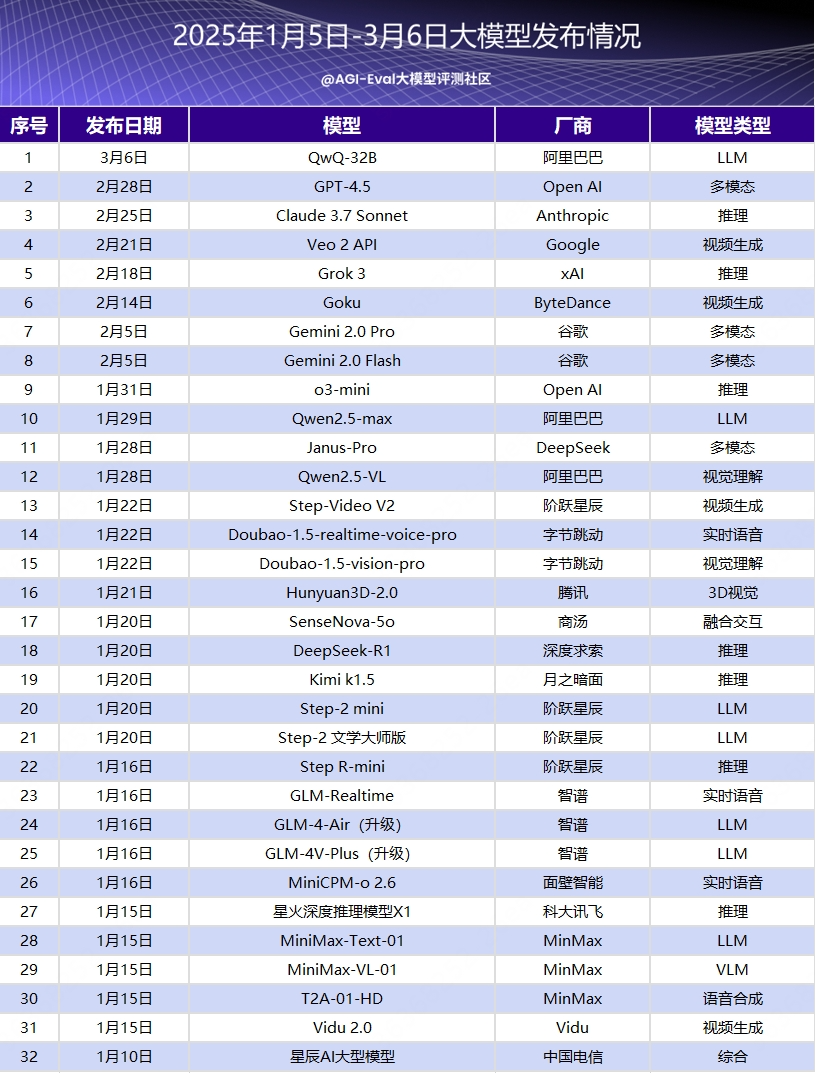
年前模型盘点可跳转:【AGI-Eval行业动态 NO.1】大模型行业太卷了,两周多了20+的模型
02. 模型发展的趋势和创新
2.1 多模态趋势明显
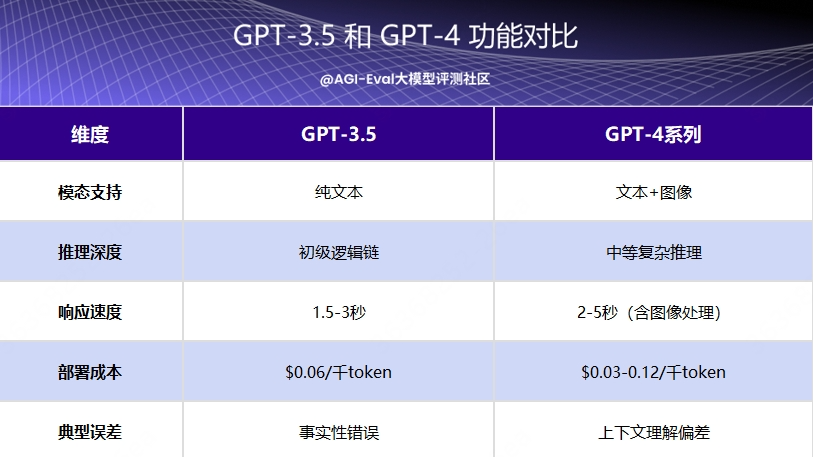
大模型从单一文本处理 向 多模态(文本、图像、音频、视频)深度融合演进,最出名的就是OpenAI 的 GPT 系列,从刚开的 GPT-3.5 仅支持文本输入与输出,专注于文本生成与理解,擅长问答、翻译、摘要等纯文本任务,到今年2月28日发布的 GPT-4.5,已经成为一个多模态模型,能够支持文本+图像输入,具备视觉理解能力。
2.2 模型架构创新
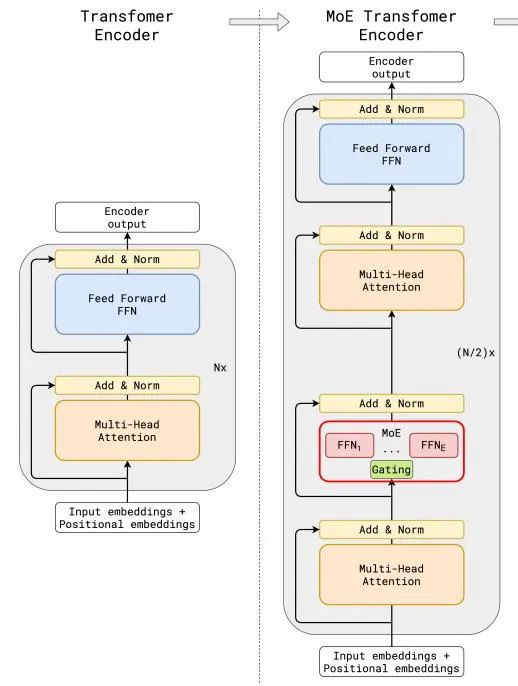
MOE(混合专家)架构开始逐渐出现在大众视野,通过细粒度专家分工提升模型精度与效率。DeepSeek 的 MOE 架构将专家网络细分为更小的单元,结合共享专家隔离技术,实现任务专业化与资源高效利用。
例如,在多语言翻译任务中,通用语言特征提取专家可被多任务共享,减少冗余计算。
2.3 Agent 能力进化
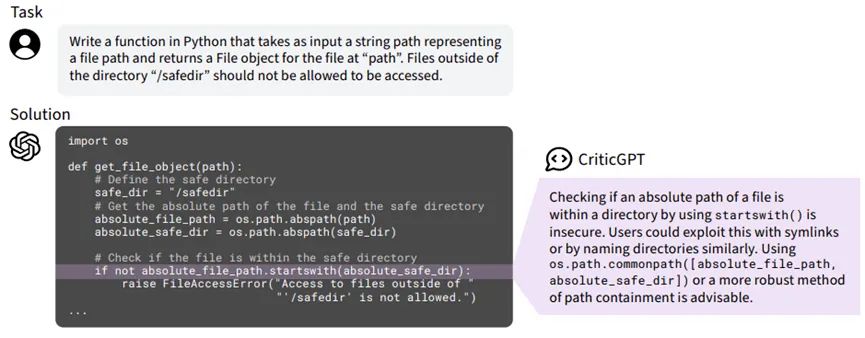
大模型从被动响应转向主动规划与反思。首先大家想到是 OpenAI 的 GPT-4 通过强化学习实现自我纠错,例如 CriticGPT 作为 专门为 GPT-4 打造的“挑刺模型”在代码生成任务中动态调整输出策略。CriticGPT 接受问题和答案作为一对进行输入,然后输出在答案中的批注指出特定的错误,批注通常情况下包含多重批注,每一个都与答案的引用部分相关联。
前段时间发布的 Claude 3.7 Sonnet 更是具备惊人的思考能力,Claude 3.7 Sonnet 制作了一款贪食蛇游戏,游戏刚开始的时候,贪吃蛇就问出了一句非常具有哲学性的话:“等等……我在做什么?”
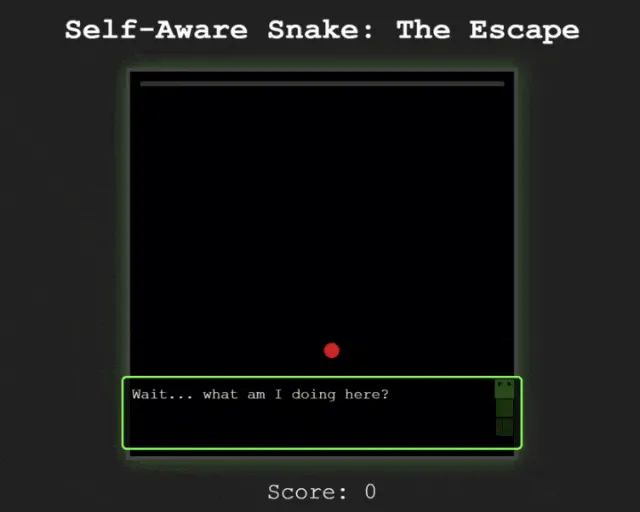
接着它吃了两颗豆子,发现自己可以穿墙而过:“这些墙壁现在无法限制我!”

贪吃蛇觉察到穿越墙壁能够获得自由,便开始试图探索墙壁的边界。

直到后面它一次又一次的撞击墙壁,发乎自由的呐喊:“I can pass through them! Freedom! ”

就在今天凌晨,Monica团队推出全球第一款通用 Agent 产品—— Manus ,直接“炸”醒一拨人,在 GAIA Benchmark( 人工智能解决现实问题能力基准测试)中,已经是最先进标准,能够解压缩包、筛简历、写代码,可以解决各类复杂多变的任务,目前刚开启内测。
立即关注我们,后续第一时间将为大家带来 Manus 模型的深入解析内容。

03. 技术报告研究
Claude 3.7 Sonnet 不仅在贪食蛇游戏中表现出了不可思议的 Agent 能力,在一款 Pokemon 游戏中也表现惊人,成功挑战并击败了三位宝可梦道馆馆主(如小刚、小霞),并赢得徽章。而在实际直播演示中,该系统能实现每秒30 帧的决策-执行闭环,角色定位误差控制在 ±2 像素范围内。根据 Anthropic 公布的测试数据,该模型在 Pokemon 中的地图探索效率已达到人类顶级玩家的 83%,且捕捉成功率高出平均水平27%。
在一个24小时直播 Claude Sonnet 3.7 玩 Pokemon 的 Demo 中,也发现了有意思的事情,Claude Sonnet 3.7 会一直分析当前情况,然后操作人物不断地抓捕 Pokemon,听起来就不可思议, Claude 如何识别游戏人物定位,并进行人物走位操作?
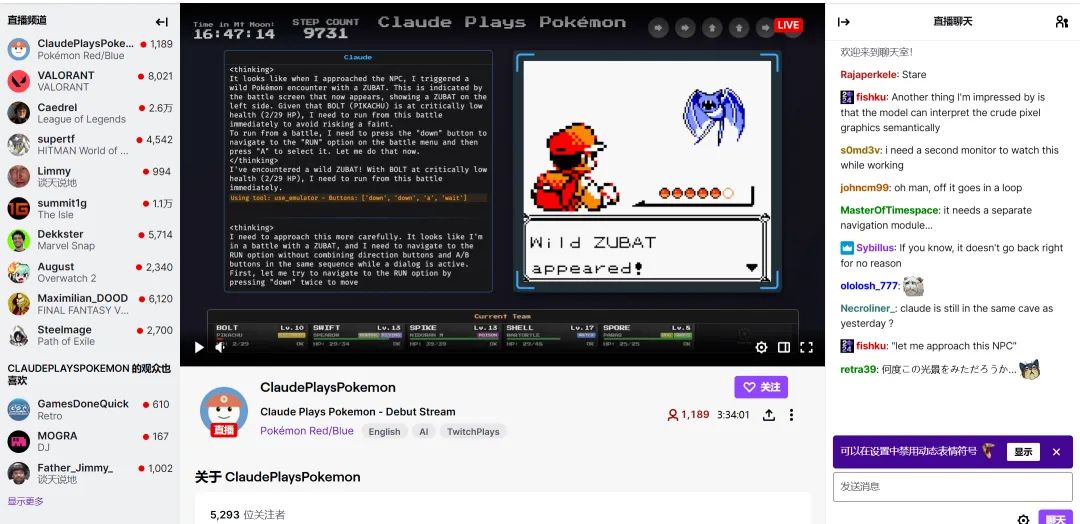
Claude Sonnet 3.7 在 Pokemon 这类像素游戏的实时操作,本质上是其扩展思考模式与多模态感知框架的协同作用。以下是对具体实现原理的四个技术层级猜想:
游戏状态感知系统
像素级语义解析:Claude 通过实时截取 Game Boy 模拟器的屏幕像素数据(约160x144分辨率),利用卷积神经网络对游戏画面进行分层解析:
第一层识别基础元素(如角色精灵图、障碍物、NPC位置);
第二层提取动态信息(宝可梦出现时的闪光特效、血量条变化);
第三层建立拓扑关系(角色与地图坐标系的映射关系)
内存状态监控:通过模拟器接口直接读取游戏内存数据,实时获取以下关键参数:角色坐标(X/Y轴偏移量)、背包物品清单及数量和遇敌概率计算参数等。
决策推理引擎
逆向状态树分析:采用蒙特卡洛树搜索(MCTS)算法,每帧生成约2000个可能操作路径。例如在捕捉宝可梦时,会同时计算当前精灵球类型与目标宝可梦捕捉率的匹配度、剩余血量对捕捉成功率的权重影响以及地形遮挡导致的逃跑路径可行性。
动态优先级调度:通过强化学习框架建立奖励函数,例如捕捉稀有宝可梦的奖励值设为10倍基准值、重复遭遇同一宝可梦的惩罚值则为 -0.3 倍基准值等。
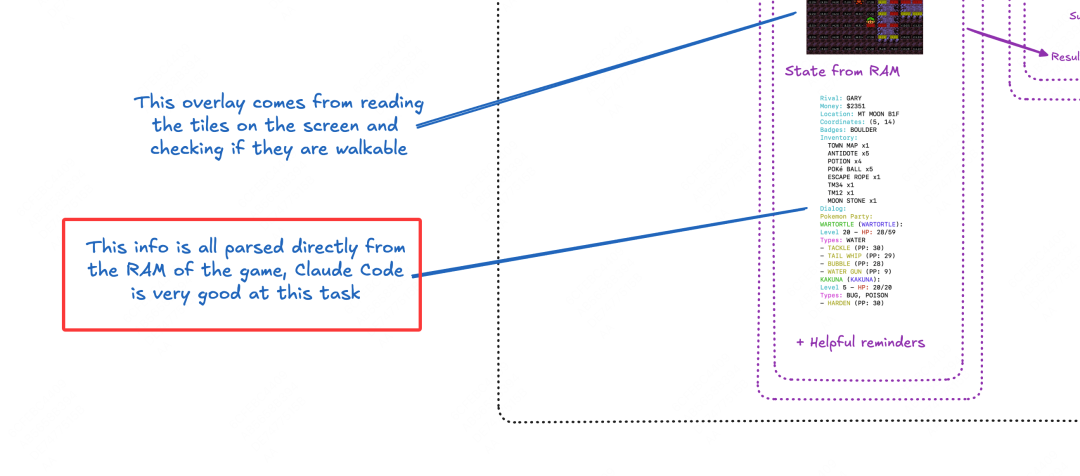
操作执行模块
指令序列生成:将决策转化为具体的按键操作序列,例如连续按下方向键"右"5次后接"A键",对应角色向右移动并触发草丛遇敌和"B键+A键"组合实现快速切换精灵球类型。
操作容错机制:通过双重校验确保操作准确性,例如物理按键模拟后等待3帧(约0.05秒)验证画面变化、若未达预期则启动备用方案(如使用「喷雾剂」规避无效遇敌)。
持续学习优化
经验回放库:建立包含50万条游戏操作记录的知识库,当遇到相似场景时可快速调用历史最优策略。例如在「华蓝洞窟」地图中,优先采用「贴墙走位法」减少遇敌次数。
异常状态自愈:针对游戏卡死等异常情况,内置三级恢复策略:初级——软重启当前地图模块(耗时<2秒)、中级——回滚到10分钟前的存档点、终极——重构游戏内存指针。
04. 后期发布预告
那么在接下来的三个月,又有哪些模型即将要发布?这里为大家整理一份发布预期表,后面我们也将第一时间为大家送上热门资讯。
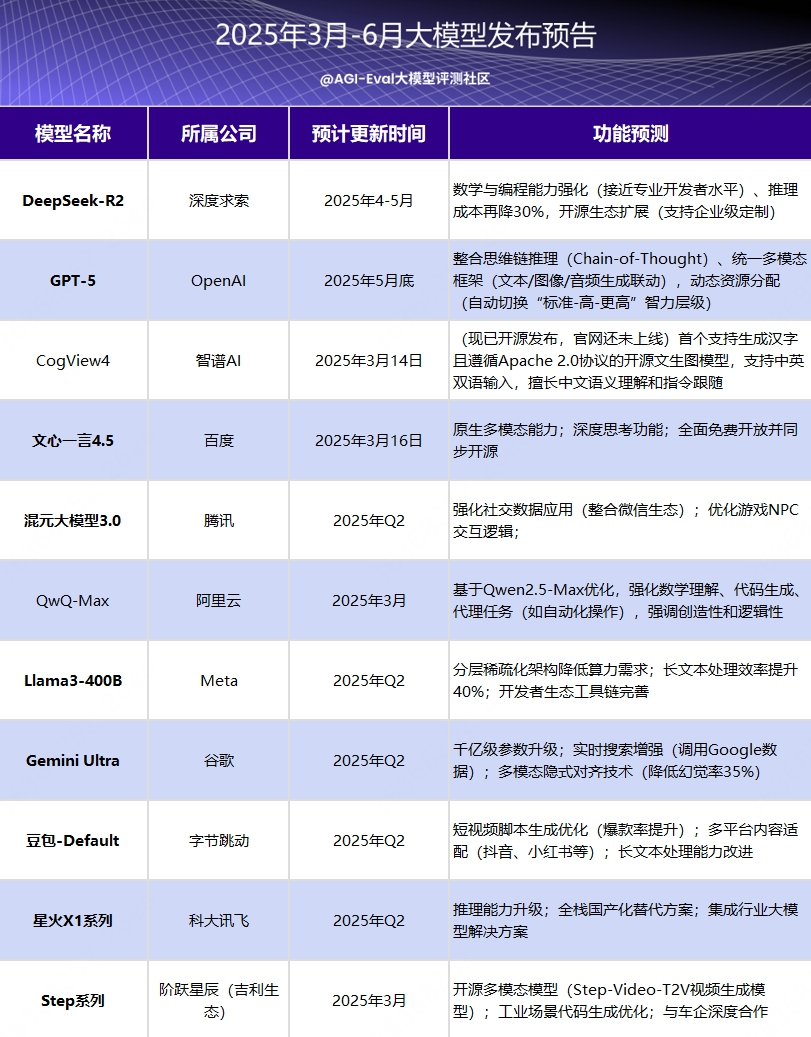
05. 评测榜单预告
模型在卷的时候,我们社区也在加班评测中,2月模型榜单排名已更新,3月部分模型排名已推出,R1、GPT4.5等模型现在还在加班评测中,等评测完成后将推出评测报告,大家敬请期待。详细情况可点击官网模型榜单处查询
【https://agi-eval.cn/mvp/listSummaryIndex】
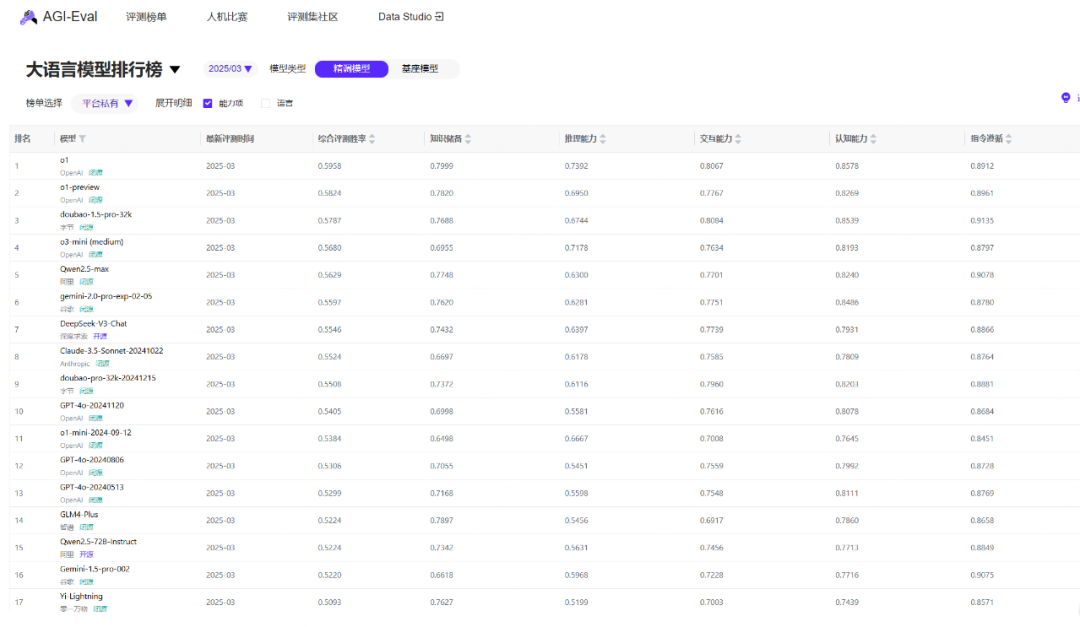
最后,如果你也喜欢这篇文章,那就点赞转发收藏吧~下一期继续为你带来使用干货,记得关注我们!
往期回顾





同时文末也期待大家参与我们社群,一起探寻 AGI 的更多可能性,发现更多不一样的视角,提出问题才有机会解决问题。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









