








一、简介
推荐算法(recommendation algorithm)就是利用用户的一些行为,通过一些数学算法,推测出用户可能喜欢的东西。目前应用推荐算法比较好的地方主要是网络,其中淘宝、拼多多和京东等做的都非常好。
推荐算法主要分为6种:
1.基于内容的推荐(Content-Based Recommendation)
2.基于协同过滤的推荐(Collaborative Filtering Recommendation)
3.基于关联规则的推荐(Association Rule-Based Recommendation)
4.基于效用的推荐(Utility-Based Recommendation)
5.基于知识的推荐(Knowledge-Based Recommendation)
6.组合推荐(Hybrid Recommendation)
详细了解可参考:推荐算法百度百科
我们现在要解决的问题是对未评价的商品进行评分的预测,如下图所示:
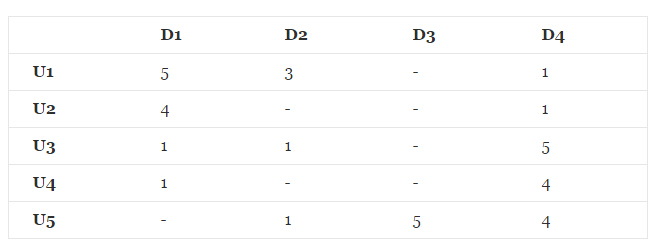
其中,
U
1
、
U
2
、
U
3
、
U
4
、
U
5
U_1、U_2、U_3、U_4、U_5
U1、U2、U3、U4、U5代表用户,
D
1
、
D
2
、
D
3
、
D
4
D_1、D_2、D_3、D_4
D1、D2、D3、D4代表商品。可以看到有的商品用户没有给出评价,我们需要做的事情就是通过推荐算法,将未评价的分数猜测出来。
二、算法原理
1.定义类似于上图的评分矩阵R。
R矩阵维度为
N
∗
M
N*M
N∗M(
N
N
N行
M
M
M列的矩阵),我们可以将
R
R
R分解为
P
P
P矩阵和
Q
Q
Q矩阵,其中P矩阵维度为
N
∗
K
N*K
N∗K,
Q
Q
Q矩阵维度为
M
∗
K
M*K
M∗K(
Q
Q
Q矩阵需要转置一下),于是有:
R
≈
R
^
=
P
∗
Q
T
R \approx \hat{R}=P*Q^{T}
R≈R^=P∗QT
对于
P
P
P,
Q
Q
Q矩阵的解释,直观上,
P
P
P矩阵是
N
N
N个用户对
K
K
K个主题的关系,
Q
Q
Q矩阵是
K
K
K个主题跟
M
M
M个物品的关系,至于
K
K
K个主题具体是什么,在算法里面
K
K
K是一个参数,需要调节的,通常
10
∼
100
10\sim100
10∼100之间。
2.对于
R
^
\hat{R}
R^ 矩阵:
r
^
i
j
=
p
i
T
q
j
=
∑
k
=
1
K
p
i
k
q
k
j
\hat{r}_{ij}=p_{i} ^{T}q_{j}=\sum_{k=1}^{K}p_{ik}q_{kj}
r^ij=piTqj=k=1∑Kpikqkj
R
^
\hat{R}
R^ 与
R
R
R 的维度相同,其中
r
i
j
^
\hat{r_{ij}}
rij^ 是
R
^
\hat{R}
R^ 第
i
i
i 行第
j
j
j 列的元素值。
3.求损失函数并更新变量:
使用原始的评分矩阵
R
R
R与重新构建的评分矩阵
R
^
\hat{R}
R^之间的误差的平方作为损失函数,即:
e
i
j
2
=
(
r
i
j
−
r
^
i
j
)
2
=
(
r
i
j
−
∑
k
=
1
K
p
i
k
q
k
j
)
2
e_{ij}^{2}=(r_{ij}-\hat{r}_{ij})^{2}=(r_{ij}-\sum_{k=1}^{K}p_{ik}q_{kj})^{2}
eij2=(rij−r^ij)2=(rij−k=1∑Kpikqkj)2
通过梯度下降法,更新变量:
- 求导:
∂ ∂ p i k e i j 2 = − 2 ( r i j − ∑ k = 1 K p i k q k j ) q k j = − 2 e i j q k j \frac{∂}{∂_{p{ik}}}e_{ij}^{2}=-2(r_{ij}-\sum_{k=1}^{K}p_{ik}q_{kj})q_{kj}=-2e_{ij}q_{kj} ∂pik∂eij2=−2(rij−k=1∑Kpikqkj)qkj=−2eijqkj
∂ ∂ q k j e i j 2 = − 2 ( r i j − ∑ k = 1 K p i k q k j ) p i k = − 2 e i j p i k \frac{∂}{∂_{q{kj}}}e_{ij}^{2}=-2(r_{ij}-\sum_{k=1}^{K}p_{ik}q_{kj})p_{ik}=-2e_{ij}p_{ik} ∂qkj∂eij2=−2(rij−k=1∑Kpikqkj)pik=−2eijpik
- 根据负梯度的方向更新变量:
p i k ′ = p i k − α ∂ ∂ p i k e i j 2 = p i k + 2 α e i j q k j p_{ik}'=p_{ik}-α\frac{∂}{∂{p_{ik}}}e_{ij}^{2}=p_{ik}+2αe_{ij}q_{kj} pik′=pik−α∂pik∂eij2=pik+2αeijqkj
q k j ′ = q k j − α ∂ ∂ q k j e i j 2 = q k j + 2 α e i j p i k q_{kj}'=q_{kj}-α\frac{∂}{∂{q_{kj}}}e_{ij}^{2}=q_{kj}+2αe_{ij}p_{ik} qkj′=qkj−α∂qkj∂eij2=qkj+2αeijpik
4.在损失函数中加入正则化惩罚项:
通常在求解的过程中,为了能够有较好的泛化能力,会在损失函数中加入正则项,以对参数进行约束。加入正则项后的计算过程如下:
E
i
j
2
=
(
r
i
j
−
∑
k
=
1
K
p
i
k
q
k
j
)
2
+
β
2
∑
k
=
1
K
(
p
i
k
2
+
q
k
j
2
)
E_{ij}^{2}=(r_{ij}-\sum_{k=1}^{K}p_{ik}q_{kj})^{2}+\frac{β}{2}\sum_{k=1}^{K}(p_{ik}^{2}+q_{kj}^{2})
Eij2=(rij−k=1∑Kpikqkj)2+2βk=1∑K(pik2+qkj2)
通过梯度下降法,更新变量:
- 求导:
∂ ∂ p i k E i j 2 = − 2 ( r i j − ∑ k = 1 K p i k q k j ) q k j + β p i k = − 2 e i j q k j + β p i k \frac{∂}{∂{p_{ik}}}E_{ij}^{2}=-2(r_{ij}-\sum_{k=1}^{K}p_{ik}q_{kj})q_{kj}+βp_{ik}=-2e_{ij}q_{kj}+βp_{ik} ∂pik∂Eij2=−2(rij−k=1∑Kpikqkj)qkj+βpik=−2eijqkj+βpik
∂ ∂ q k j E i j 2 = − 2 ( r i j − ∑ k = 1 K p i k q k j ) p i k + β q k j = − 2 e i j p i k + β q k j \frac{∂}{∂{q_{kj}}}E_{ij}^{2}=-2(r_{ij}-\sum_{k=1}^{K}p_{ik}q_{kj})p_{ik}+βq_{kj}=-2e_{ij}p_{ik}+βq_{kj} ∂qkj∂Eij2=−2(rij−k=1∑Kpikqkj)pik+βqkj=−2eijpik+βqkj
- 根据负梯度的方向更新变量:
p i k ′ = p i k − α ( ∂ ∂ p i k e i j 2 + β p i k ) = p i k + α ( 2 e i j q k j − β p i k ) p_{ik}'=p_{ik}-α(\frac{∂}{∂{p_{ik}}}e_{ij}^{2}+βp_{ik})=p_{ik}+α(2e_{ij}q_{kj}-βp_{ik}) pik′=pik−α(∂pik∂eij2+βpik)=pik+α(2eijqkj−βpik)
q k j ′ = q k j − α ( ∂ ∂ q k j e i j 2 + β q k j ) = q k j + α ( 2 e i j p i k − β q k j ) q_{kj}'=q_{kj}-α(\frac{∂}{∂{q_{kj}}}e_{ij}^{2}+βq_{kj})=q_{kj}+α(2e_{ij}p_{ik}-βq_{kj}) qkj′=qkj−α(∂qkj∂eij2+βqkj)=qkj+α(2eijpik−βqkj)
5.算法终止:
每次更新完
R
^
\hat{R}
R^ 后,计算一次
l
o
s
s
loss
loss值,若
l
o
s
s
loss
loss值非常小或者到达最大迭代次数,结束算法。于是就得到了我们最终的预测矩阵
R
^
\hat{R}
R^。
三、算法python实现
import numpy as np
import math
import matplotlib.pyplot as plt
R = np.array([[5, 3, 0, 1], # 用户商品评分,0代表未参与评分
[4, 0, 0, 1],
[1, 1, 0, 5],
[1, 0, 0, 4],
[0, 1, 5, 4]])
N = R.shape[0] # 用户数
M = R.shape[1] # 商品数
K = 5 # 主题数
# 定义P和Q矩阵
P = np.random.rand(N, K) # 初始化P和 Q
Q = np.random.rand(K, M)
def getLoss(R, P, Q, N, M, K, beta): # 损失函数
loss = 0.
for i in range(N):
for j in range(M):
if (R[i][j] == 0):
continue
sum = sum2 = 0
for k in range(K):
sum += P[i][k] * Q[k][j]
sum2 += P[i][k] * P[i][k] + Q[k][j] * Q[k][j]
loss += math.pow(R[i][j] - sum, 2) + beta * sum2 / 2
return loss
def matrix_composition(R, P, Q, N, M, K, alpha = 0.0002, beta = 0.002): # 矩阵分解
loss_list = []
for step in range(5000): # 规定梯度下降次数
loss = getLoss(R, P, Q, N, M, K, beta)
if(loss < 0.001): # 损失值可以忽略不计
break
if(step % 20 == 0): # 每20次记录一下loss变化
plt.scatter(step, loss)
# if(step % 1000 == 0): # 调试
# print(loss)
# update
for i in range(N):
for j in range(M):
if(R[i][j] == 0): # 只看有评分的
continue
sum = 0
for k in range(K):
sum += P[i][k] * Q[k][j]
for k in range(K): # 更新变量
P[i][k] += alpha * (2 * (R[i][j] - sum) * Q[k][j] - beta * P[i][k])
Q[k][j] += alpha * (2 * (R[i][j] - sum) * P[i][k] - beta * Q[k][j])
return P, Q
if __name__ == '__main__':
print('评分矩阵')
print(R)
P, Q = matrix_composition(R, P, Q, N, M, K)
print('P和Q矩阵如下')
print(P)
print()
print(Q)
print()
print(np.dot(P, Q)) # 矩阵计算
plt.show()














 327
327











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









