







一、K-means介绍
K-means算法,也称为K-平均或者K-均值,是一种无监督的聚类算法。对于给定的样本集,按照样本之间的距离大小,将样本划分为K个簇,让簇内的点尽量紧密的连接在一起,而让簇间的距离尽量的大。K-means是一种使用广泛的最基础的聚类算法,通常作为学习聚类算法时的第一个算法。
其他的聚类算法还有:K-medoids、k-modes、Clara、Clarans等
聚类:物理或抽象对象的集合分成由类似的对象组成的多个类的过程被称为聚类。由聚类所生成的簇是一组数据对象的集合,这些对象与同一个簇中的对象彼此相似,与其他簇中的对象相异。
簇:本算法中可以理解为,把数据集聚类成k类,即k个簇。
质心:指各个类别的中心位置,即簇中心。
距离公式:常用的有:欧几里得距离(欧氏距离)、曼哈顿距离、闵可夫斯基距离等。
二、算法步骤
1.文字说明
①.给定一个待处理的数据集;
②.记K个簇的中心分别为
c
1
,
c
2
,
.
.
.
,
c
k
c1,c2,...,ck
c1,c2,...,ck;每个簇的样本数量为
N
1
,
N
2
,
.
.
.
,
N
3
N1,N2,...,N3
N1,N2,...,N3;
③.通过欧几里得距离公式计算各点到各质心的距离,把每个点划分给与其距离最近的质心,从而初步把数据集分为了K类;
④.更新质心:通过下面的公式来更新每个质心。就是,新的质心的值等于当前该质心所属簇的所有点的平均值。
c
j
=
1
N
j
∑
i
=
1
N
j
x
i
,
y
i
c_{j}=\frac{1}{N_{j}}\sum_{i=1}^{N{j}}x_{i},y_{i}
cj=Nj1i=1∑Njxi,yi
⑤.重复步骤3和步骤4,直到质心基本不再变化或者达到最大迭代次数。
2.伪代码
导入或创建训练集,设定K值
随机选取K个点作为初始质心(在数据集的范围内)
repeat
for i=1,2,...,m(m为样本个数)do
计算K个质心到所有样本的欧式距离
把样本中的点划分给距离最近的质心
end for
for i=1,2,..,k do
求每一个簇的数据的平均值
将求出的平均值赋值给各质心
end for
until 当前质心基本不变或者达到最大迭代次数
三、图形展示
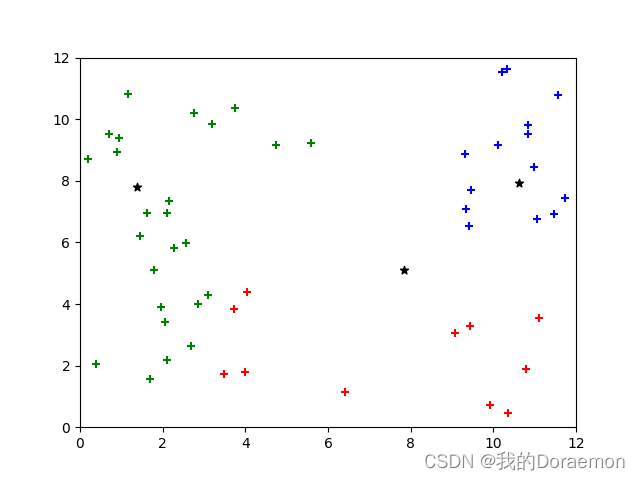
假设K=2,即有两个簇,绿色为最初的样本数据集(图a),红色标记和蓝色标记分别为两个质心(图b)。通过计算样本到红色质心和蓝色质心的距离,实现对样本的分类,然后再不断地更新质心的位置,最终得到了一个比较理想的聚类结果(图f)。

顺序为:a→b→c→d→e→f
可以看到,整个算法是一个不断更新质心和簇的过程。
四、代码实现
import matplotlib.pyplot as plt
from random import uniform
from math import sqrt
import numpy as np
data = [[], []]
n = 50
for i in range(n):
if i < 20:
data[0].append(uniform(0, 4))
data[1].append(uniform(0, 12))
elif i >= 20 and i < 30:
data[0].append(uniform(0, 10))
data[1].append(uniform(0, 10))
else:
data[0].append(uniform(9, 12))
data[1].append(uniform(0, 12))
plt.scatter(data[0], data[1], marker='+')
plt.show()
plt.xlim(0, 12)
plt.ylim(0, 12)
cent = np.empty((3, 2)) # 创建中心
for i in range(3): # 随机初始化中心
cent[i][0] = uniform(0, 12)
cent[i][1] = uniform(0, 12)
dist = np.empty((3, n)) # 距离中心的距离
def distEuclid(x1, y1, x2, y2): # 计算欧几里得距离
return sqrt(pow(x1-x2, 2) + pow(y1-y2, 2))
def k_means(): # k-means算法
for step in range(50):
for i in range(n):
for j in range(3): # 计算距离
dist[j][i]=distEuclid(data[0][i], data[1][i], cent[j][0], cent[j][1])
sumX = [0, 0, 0] # 记录距离每一个中心最近的点X和
sumY = [0, 0, 0] # 记录距离每一个中心最近的点Y和
num = [0, 0, 0] # 记录距离每一个中心最近的点数量
for i in range(n):
mi = min(dist[0][i], dist[1][i], dist[2][i])
for j in range(3):
if(dist[j][i] == mi):
sumX[j] += data[0][i] # update
sumY[j] += data[1][i]
num[j] += 1
if(step == 49): # 最后一次分配画图
c = ''
if (j == 0):
c = 'g'
elif (j == 1):
c = 'b'
else:
c = 'r'
plt.scatter(data[0][i], data[1][i], marker='+', color=c)
for i in range(3): # 画中心
plt.scatter(cent[i][0], cent[i][1], marker='*', c='k')
plt.show()
if __name__ == '__main__':
k_means()
五、K-means 算法存在的问题
由于K-means算法简单且易于实现,因此K-means算法得到了很多的应用,但是从K-means算法的过程中可以发现两个问题:
1.簇中心的个数K是需要事先给定的,对事先比较了解的数据集可以很好地进行分类,但在处理未知数据时无法确定K的值为多少时更合适,就无从下手或者只能盲目尝试。
2.K-means算法在聚类之前,需要随机初始化K个质心,如果质心选择不好,如上面的图形所示,最后的聚类结果可能会比较差。















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









