






●给出穿搭建议
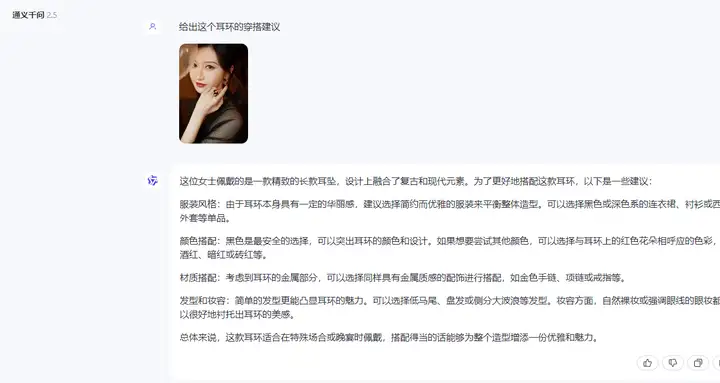
这位女士佩戴的是一款精致的长款耳坠,设计上融合了复古和现代元素。为了更好地搭配这款耳环,以下是一些建议:
服装风格:由于耳环本身具有一定的华丽感,建议选择简约而优雅的服装来平衡整体造型。可以选择黑色或深色系的连衣裙、衬衫或西装外套等单品。
颜色搭配:黑色是最安全的选择,可以突出耳环的颜色和设计。如果想要尝试其他颜色,可以选择与耳环上的红色花朵相呼应的色彩,如酒红、暗红或砖红等。
材质搭配:考虑到耳环的金属部分,可以选择同样具有金属质感的配饰进行搭配,如金色手链、项链或戒指等。
发型和妆容:简单的发型更能凸显耳环的魅力。可以选择低马尾、盘发或侧分大波浪等发型。妆容方面,自然裸妆或强调眼线的眼妆都可以很好地衬托出耳环的美感。
总体来说,这款耳环适合在特殊场合或晚宴时佩戴,搭配得当的话能够为整个造型增添一份优雅和魅力。
●帮助识别宝宝需求
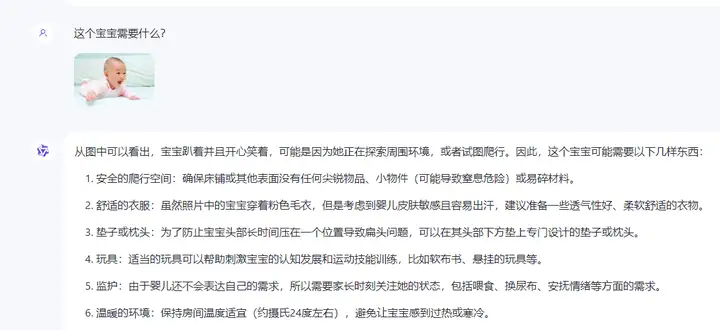
从图中可以看出,宝宝趴着并且开心笑着,可能是因为她正在探索周围环境,或者试图爬行。因此,这个宝宝可能需要以下几样东西:
安全的爬行空间:确保床铺或其他表面没有任何尖锐物品、小物件(可能导致窒息危险)或易碎材料。
舒适的衣服:虽然照片中的宝宝穿着粉色毛衣,但是考虑到婴儿皮肤敏感且容易出汗,建议准备一些透气性好、柔软舒适的衣物。
垫子或枕头:为了防止宝宝头部长时间压在一个位置导致扁头问题,可以在其头部下方垫上专门设计的垫子或枕头。
●识别人脸情绪
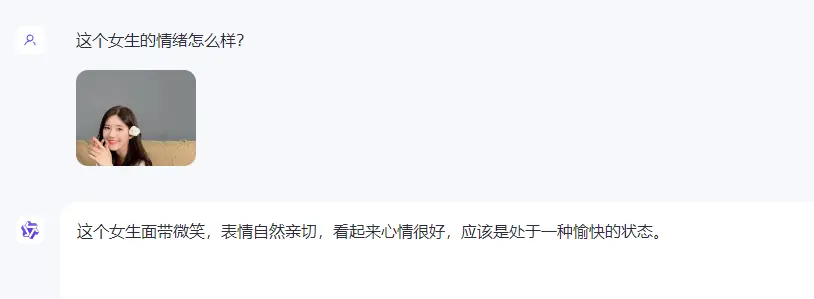

这个女生面带微笑,表情自然亲切,看起来心情很好,应该是处于一种愉快的状态。
●识别地点
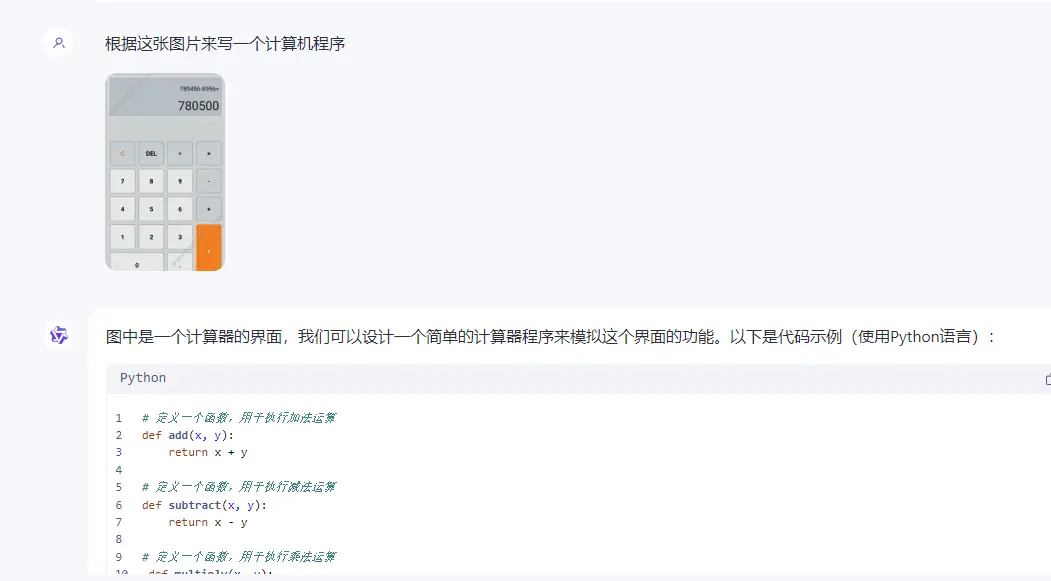
●根据图片来写程序
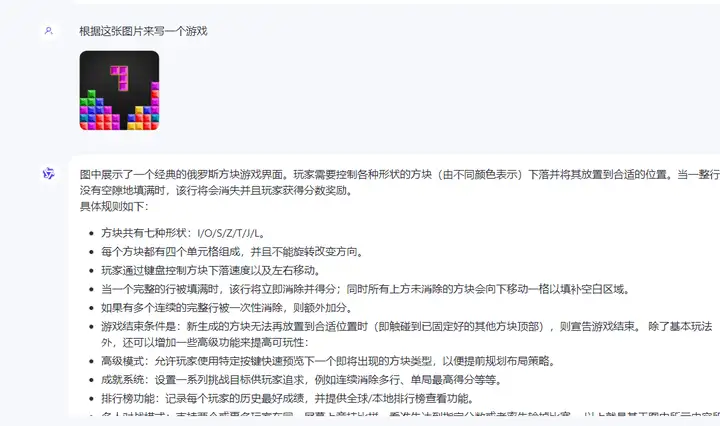
●根据图片来写游戏
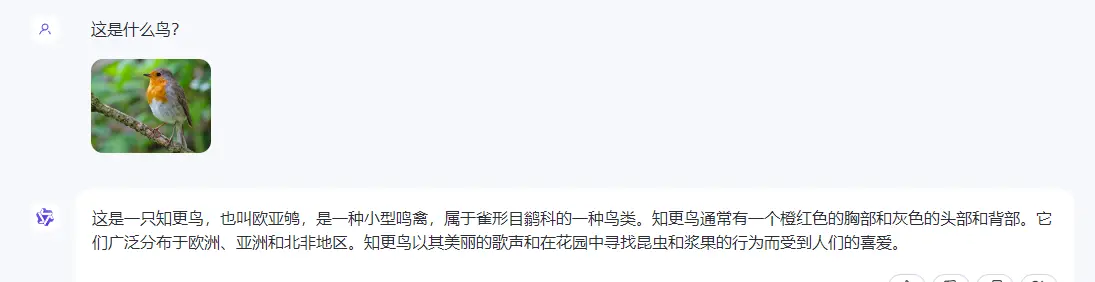
●识别动物、植物和物体
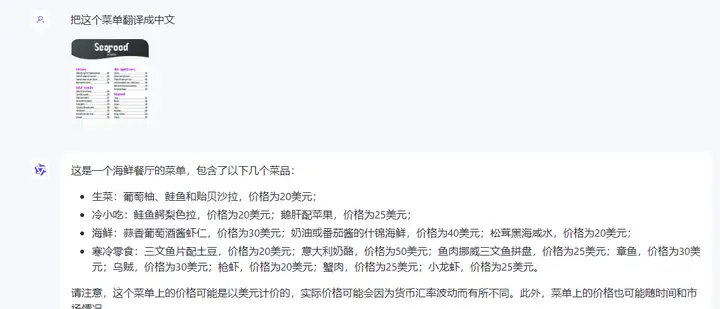
●翻译外语菜单
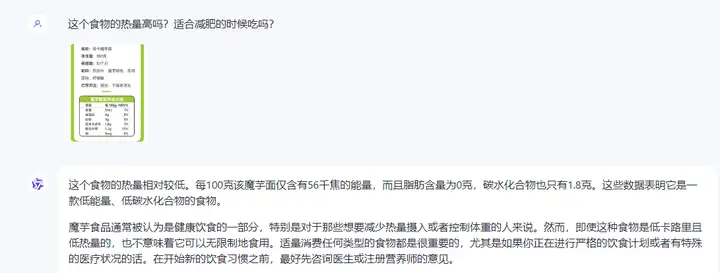
●食物营养建议
●网页UI设计建议
●家居设计装修
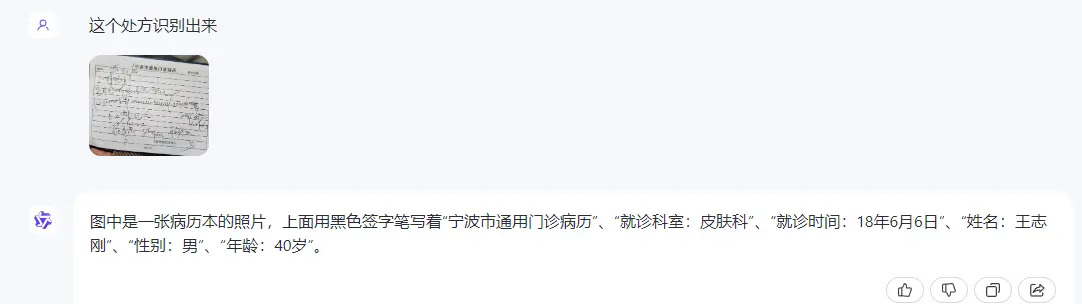
●处方识别

●识别甲骨文

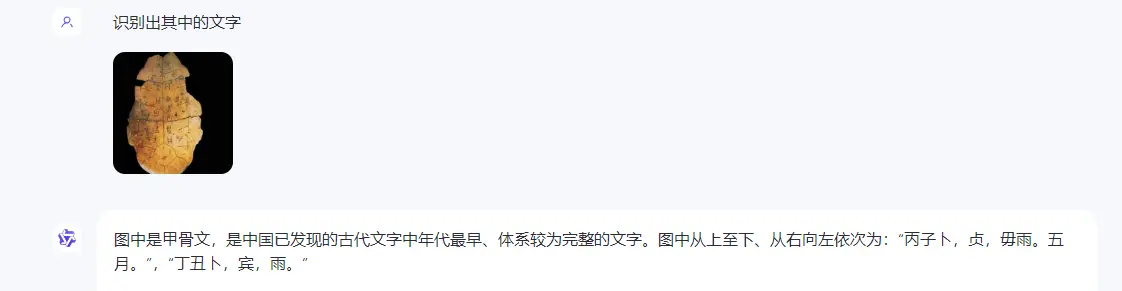
图中是甲骨文,是中国已发现的古代文字中年代最早、体系较为完整的文字。图中从上至下、从右向左依次为:“丙子卜,贞,毋雨。五月。”,“丁丑卜,宾,雨。”
●帮助了解历史以及追剧


图中是古装剧中的服饰,具体来说,图中的服装具有中国汉服的特征,属于传统汉服。汉服自汉族先民的农业文明以来就存在,一直延续至今。它的基本特点是交领、右衽、束腰,用绳带系结,也包含许多变化形式。汉服强调平直线缝制,这与西方服装的立体剪裁有所不同。此外,汉服还注重传统的工艺刺绣和装饰,体现出浓郁的民族特色。
由于图片中的服装并非严格遵循某个特定历史时期的样式,而是融合了多个时代的特征,因此很难确定其确切的历史时期。然而,可以看到服装设计借鉴了唐朝、宋朝、明朝等不同时期的特点,比如宽大的袖口和复杂的图案。这种风格的服装常用于电视剧或电影中的古装戏份,旨在传达中国传统美学和文化内涵,而非准确反映特定历史时期的着装规范。
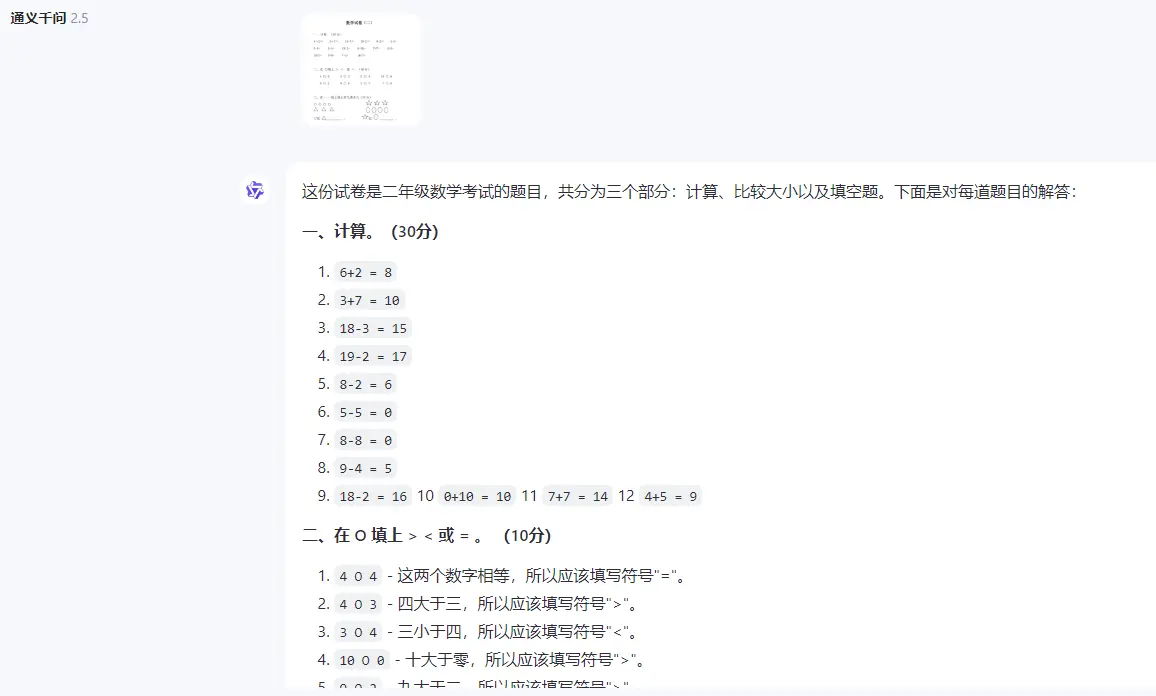
●做试卷,辅导作业

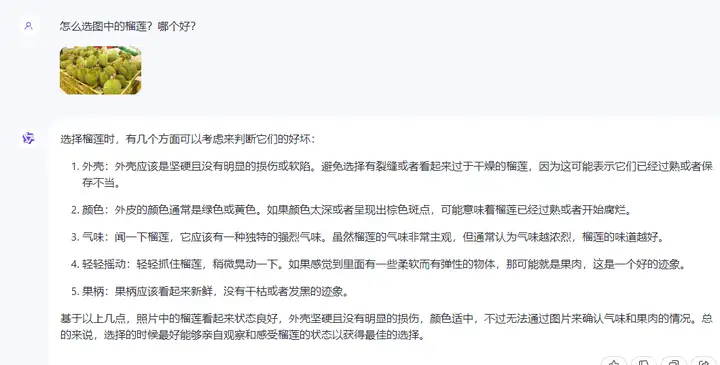
●选水果
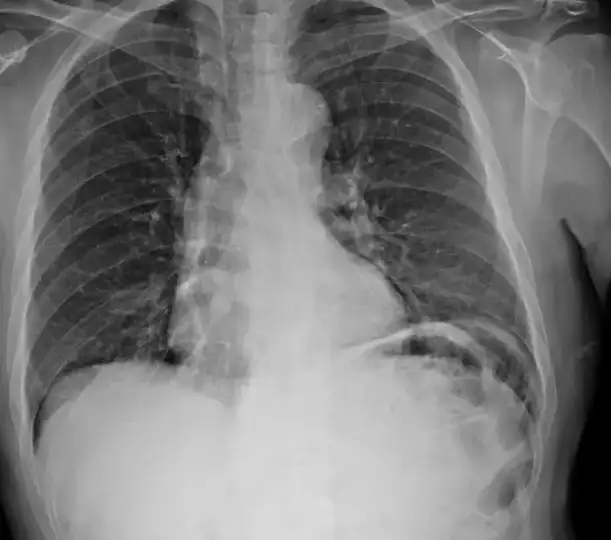
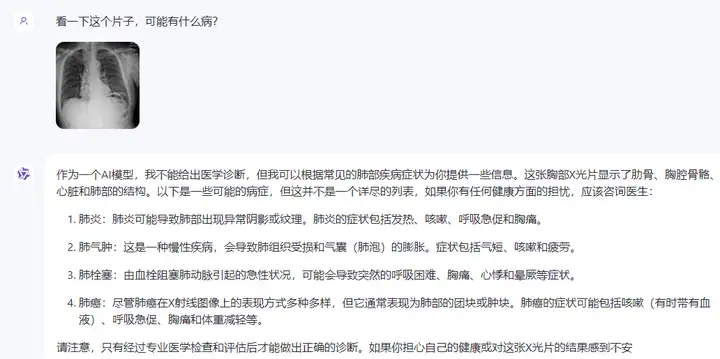
●看X光或者CT扫描片
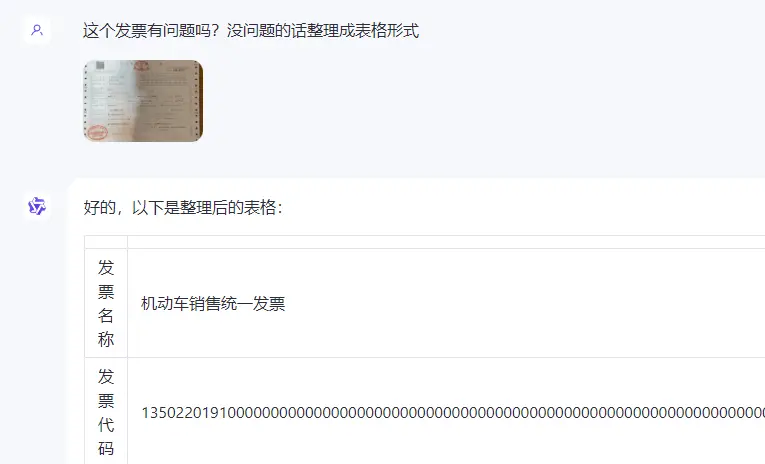
●识别发票,整理发票
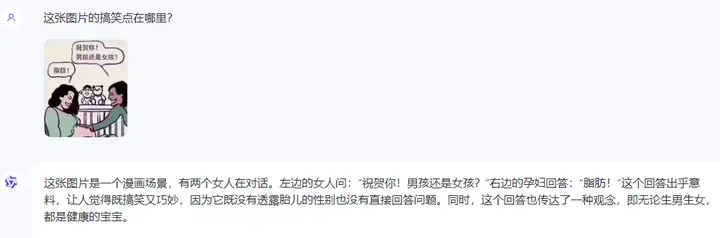
●搞笑图片的幽默之处

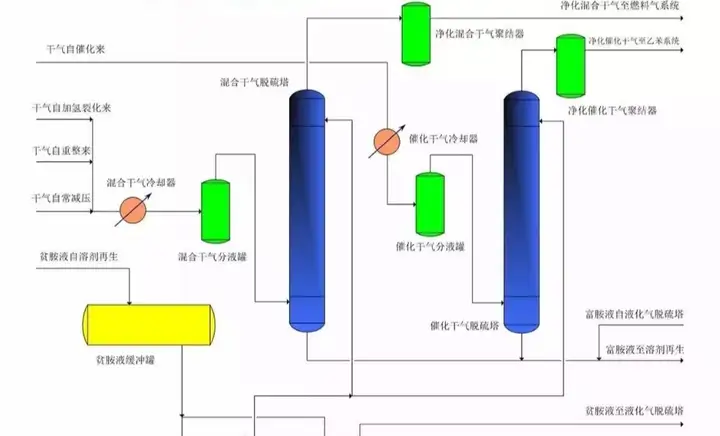
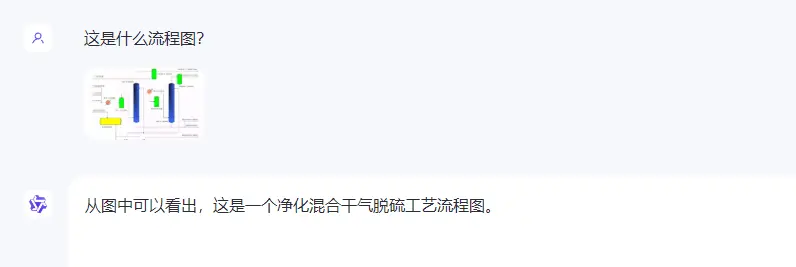
●流程图识别
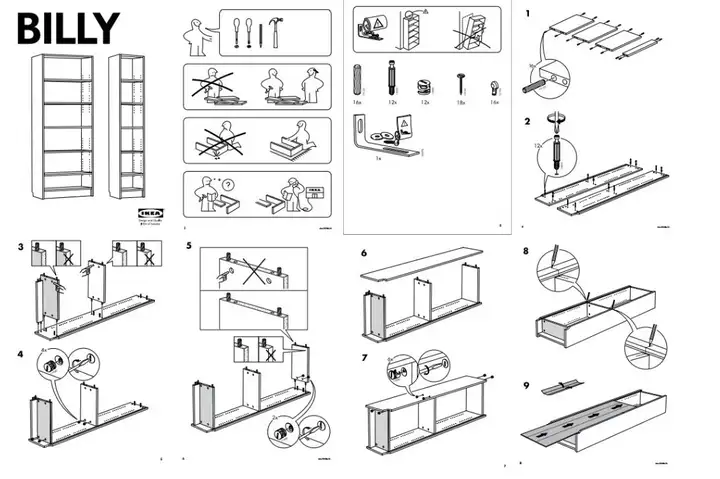
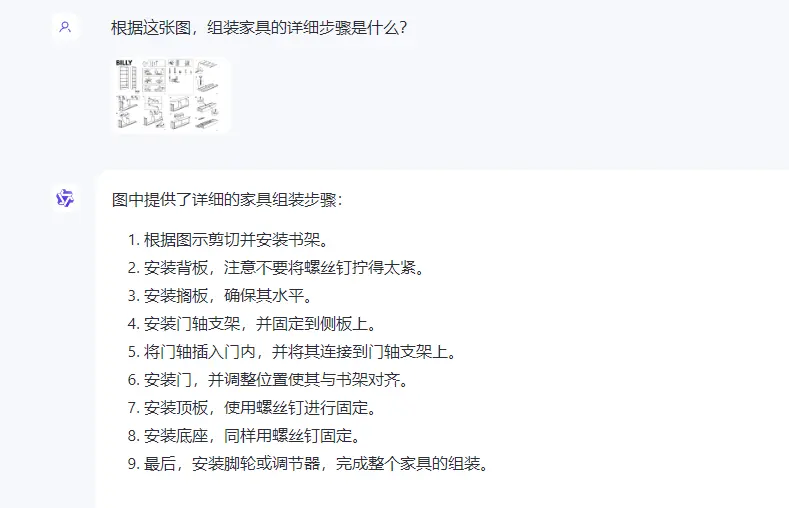
●家具组装说明步骤
●识别软件图标

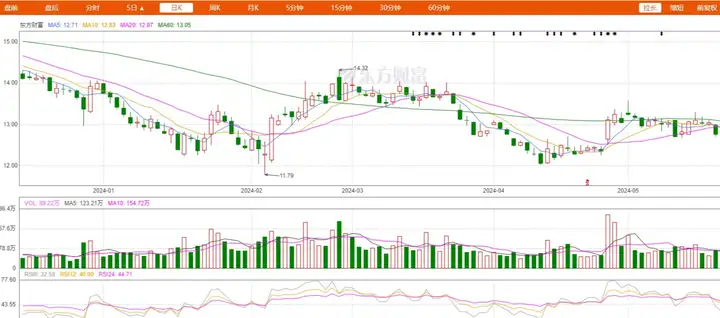
●炒股,对股票进行技术分析


















 3095
3095

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









