







这里写目录标题
实验目的
构建一个神经网络,通过神经网络可以预测给入的样本[温度,持续时间],能否烘焙出好的咖啡豆。
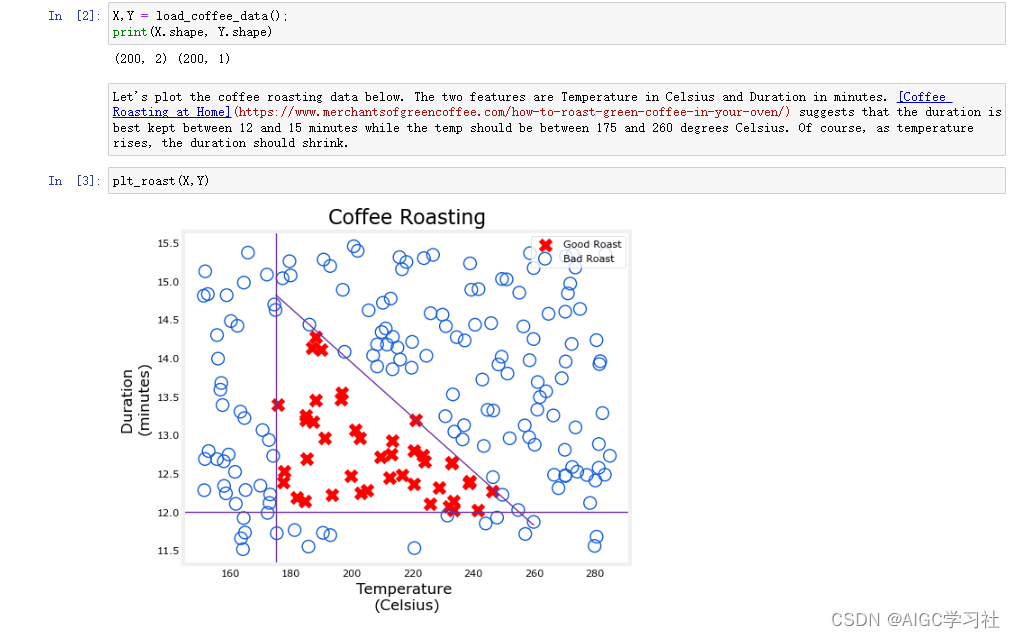
导入训练集并绘制散点图
200个训练样本,每个训练样本的特征是[持续时间,温度],我们假设,如果一个样本的温度在175-260且持续时间在12-15分钟,那么就认为根据这个样本烘焙的咖啡会得到好咖啡,对应图里红叉。相反,输入特征不在这个范围内的,都是坏咖啡的样本,对应图里蓝色圈。
特征缩放处理数据集
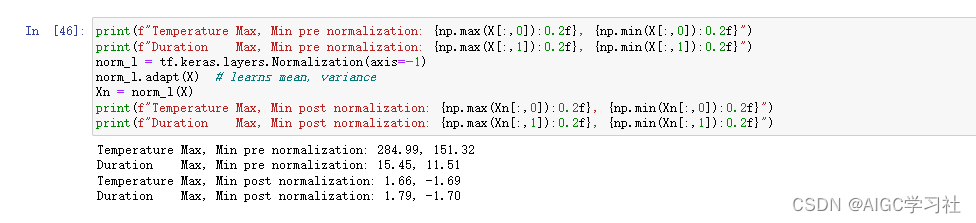
使用 z 标准化处理训练样本的特征,减小每个训练样本的温度差异和持续时间差异(咖啡烘焙)。具体做法是创建一个规范化层,并使用 adapt 方法计算数据的均值和方差,然后对输入数据 X 进行 z 标准化处理,得到新的样本 Xn。
- 原训练样本的温度差异:284.99,151.32。
- 原训练样本的持续时间差异:15.45,11.51。
- z标准化后的温度差异:1.66,-1.69。
- z标准化后的持续时间差异:1.79,-1.70。
扩展数据集
扩展训练集数据,可以减少训练周期数(详见优化模型中的时代和批次)。

TensorFlow构建神经网络模型
1.初步构建神经网络
- 使用Sequential创建前向传播网络,网络设置2个层Dense,第1个层3个神经元。第2个层1个神经元。
- set_seed每次运行代码,模型的结构和参数初始化保持一致。
- tf.keras.Input(shape=(2,)),可以理解成模型的输入层为2个特征的单样本。

2.获取模型信息
- model.summary(),返回模型的相关信息。
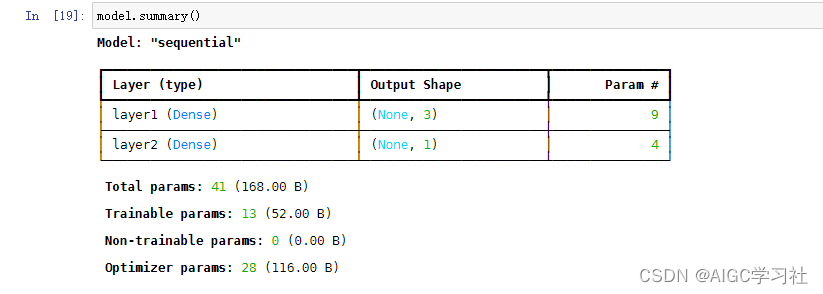
- Param参数的计算
- L1有3个神经元,每个神经元输入的样本包含2个特征,因此每个神经元w有2个,b有1。因此3个神经元一共包含2*3+3=9个参数。
- L2输入L1的3个激活值,可以理解成L2输入的样本包含3个特征,L2只有1个神经元,因此3*1+1。

- 获取每一层的参数,在神经层接收输入的时候,w,b参数就已经被自动初始化了。查看层的参数,也可以可视化的查看summary返回的param都是什么。

2.优化模型
-
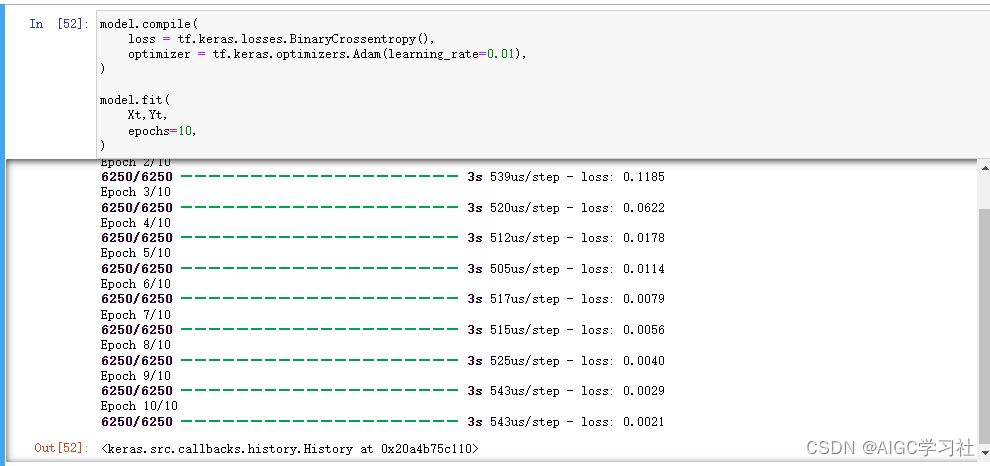
model.compile 语句定义了一个损失函数并指定了一个编译优化。model.fit 语句运行梯度下降并将权重拟合到数据中。简单来说就是优化模型的过程,并且让模型里被自动初始化的参数w,b达到局部最优解。
-
时代和批次:
- epochs=10表示训练时代(周期)数,每个时代包含多次梯度下降的迭代。
- Tensorflow 默认批次大小为32,示例中的数据集样本为200000,因此每个时代的梯度下降迭代次数为200000/32=6250,也就是每个时代执行6250次梯度下降迭代。
- 如果数据集样本数量少,为了保证每个执行足够多的梯度下降迭代次数,就要设置更大的epochs,可能会导致过拟合,所以我们在一开始要扩展数据集样本数量。
-
查看模型优化后的w,b参数。

3.设置模型参数
重新设置w,b,如果后续没有显式的设置修改w,b,那么就会一直使用这个w,b。这样做是确保模型的稳健性,即使TensorFlow库随时间的更新可能会带来变化,也可以确保模型在重新运行时的结果与之前一致。
3.开始预测
- 模型的输出是一个概率,即烘烤好的概率。为了做出决策,必须将概率应用到一个阈值上。在这种情况下,我们将使用 0.5。
- 构建用于测试的训练样本,为了保证结果的准确,测试样本也要z标准化处理。
- 结果分别是0.963和0.0000000303。
- 备注:之前讲述的内容,并没有详细讲述给神经网络传入一个矩阵,矩阵是如何在神经网络中计算的,后面课程会详细讲,这里只需先掌握TensorFlow的使用过程就好。

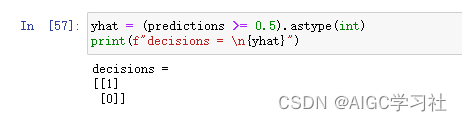
4.转换预测结果
- 预测的是一个概率,我们需要设置阈值0.5,来让概率变成确定的1或0,根据结果0.963和0.0000000303,因此是1和0。这也就是说,200度13.9分钟,能烘焙出好的咖啡豆。而200度17分钟,无法烘焙出好的咖啡豆,烤过头了!

- 更简化的写法。
检测神经元的功能
1.目的
给入神经元与真实数据集范围相同的特征,对比神经元和神经网络的预测效果与真实数据。
2.准备工作
- 图中的散点是根据实际的X,Y绘制,散点图已经呈现出好样本的温度和持续时间是多少,坏样本的温度和持续时间是多少。
- 用于计算神经元或神经网络预测的x,是随机构建的1600个输入样本,它们的特征范围和实际的X的特征范围一致。
- 备注:实际代码中是不一致的,1600个输入样本温度特征在150到285,持续时间特征在11.5到15.5,而实际的范围是温度特征在175-260且持续时间在12-15,这里猜测是为了让两个图形在视觉上更加贴近,以便更好地比较模型的预测结果和实际数据分布。
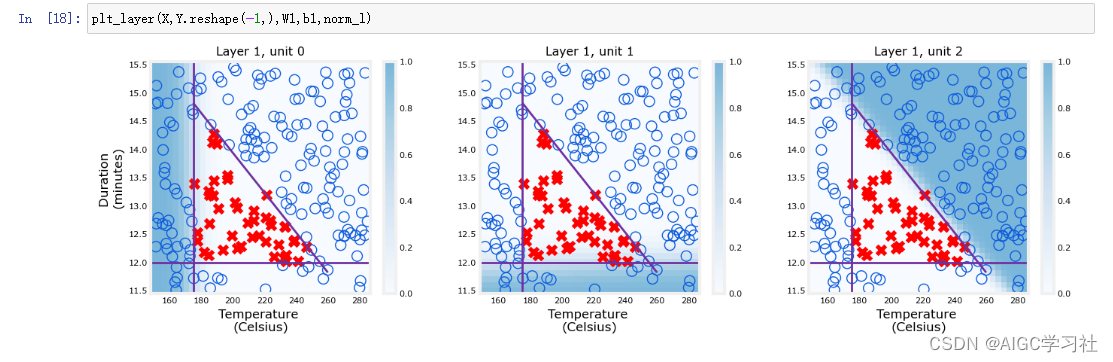
3.第一层的预测与真实数据的对比
-
Unit 0:当输入样本中的温度过低时,这个单元的激活值会较大,颜色就会越深(阴影),此时的输入样本中的温度特征,属于真实数据集中温度低的范围,表示神经元对温度低的训练样本更敏感。
-
Unit 1:当输入样本中的持续时间较短时,这个单元的激活值会较大,颜色就会越深(阴影),此时的输入样本中的持续时间特征,属于真实数据集中持续时间短的范围,表示神经元对持续时间短的样本更敏感。
-
Unit 2:当输入样本中的持续时间过久且温度过高,这个单元的激活值会增大,表示神经元对持续时间过久以及烘焙温度过高的训练样本更敏感。
-
高激活值表示神经元对输入或某些特征的响应强烈,因此我们观察高激活值的分布情况。
这些神经元之所以能根据样本筛选出样本不同的问题,并不是人为设计的功能,而是神经网络通过梯度下降自主学习得到的(也就是不同神经元获得了不同的w,b,这里是吴恩达直接给出了合适的W1,B1),这些学习到的功能与人类可能会选择用于做出相同决策的函数非常相似,表明神经网络能够模拟人类的决策过程。
2.第二层
-
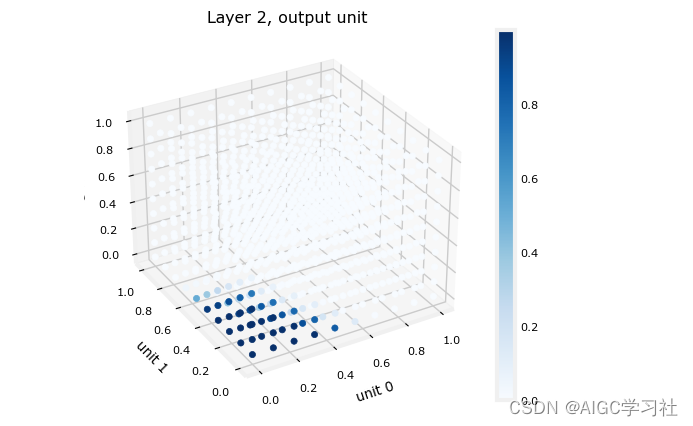
最终层的输入来源于第一层的输出。已知第一层使用了sigmoid激活函数,这意味着其输出值范围被限定在0到1之间。
-
为了更好地理解最终层的行为,可以通过创建一个三维图来展示所有可能的3个输入组合下模型的输出结果。
-
上图中,如果神经元的激活值较高,则表示对应的样本不是好样本,相反,如果神经元的激活值较小,则对应了好的样本。因此下图中,最终层的高激活值(深蓝色)对应3个输入变量取较小值的区域,而较小的3个输入变量,都是上一层神经元好样本计算出的激活值,因此这些区域对应于“good roast”,即良好的烘焙结果。
3.神经网络的整体情况
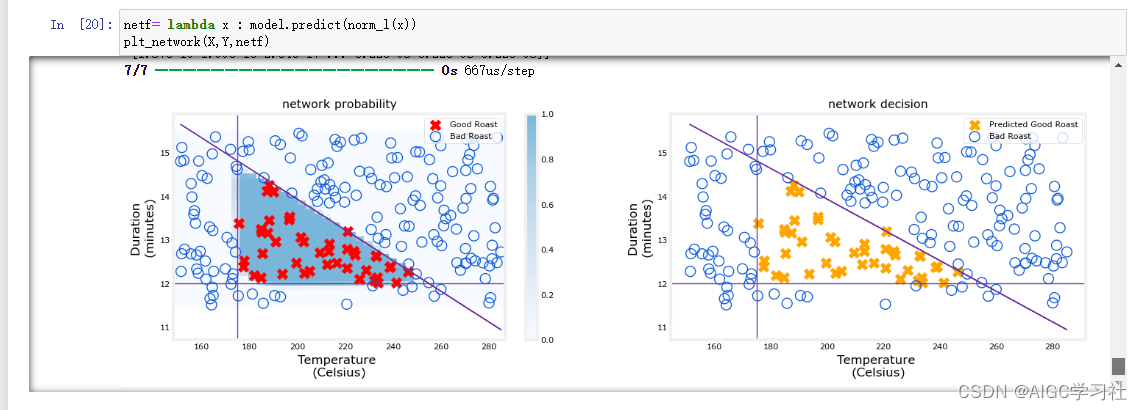
- 左侧图表显示的是神经网络最后一层预测输出(1600个训练样本),神经网络模型的预测是准确的。阴影部分对应高激活值,而高激活值对应的输入样本里的特征范围,与真实数据集好咖啡的特征范围一致。因此可以说,这个神经网络根据训练样本预测出好咖啡是敏感的。
- 而右侧图中的散点,并不是真实数据集里的Y,而是神经网络预测并通过阈值转换的Y,能够看到它跟左侧的数据点Y分布一样,给入神经网络X,预测Y和真实Y时一致的,证明了神经网络预测的准确性。















 1408
1408

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









