







扩散模型在图像和视频生成方面取得了显著的成功。这激发了对视频编辑任务的日益关注,其中视频根据提供的文本描述进行编辑。然而,大多数现有方法只专注于短视频片段的编辑,并依赖于耗时的调整或推理。本文首次提出了Video Instruction Diffusion(VIDiff),一个面向广泛视频任务的统一基础模型。这些任务包括理解任务(如语言引导的视频对象分割)和生成任务(视频编辑和增强)。本文的模型可以根据用户的指令在几秒钟内编辑和翻译出所需的结果。此外,还设计了一个迭代自回归方法,以确保对长视频的编辑和增强具有一致性。在各种输入视频和书面指令上提供了令人信服的生成结果,无论是在定性还是在定量上。更多示例可查看网站:https://ChenHsing.github.io/VIDiff。
引言
近年来,人工智能领域取得了显著的进展,尤其是在自然语言处理(NLP)方面,大语言模型(LLMs)如GPT 将各种任务统一到一个框架下。相比之下,计算机视觉领域的基础模型的发展仍远远落后于NLP,这是由于视觉任务中自然产生的多样性,例如各种输出格式和不同的模型架构。
受到GPT在统一NLP任务方面取得的成功启发,一些基础模型已经涌现出来,旨在统一视觉任务,主要关注理解任务,如识别和检索。尽管如此,对于生成任务的统一框架的研究相对较少。InstructDiffusion 探索了将扩散模型推广到图像编辑和理解任务的通用性。尽管如此,在视频领域统一任务仍然具有挑战性,因为数据分布和任务变化比图像更复杂。很少有人努力设计一个统一框架,同时解决视频理解和编辑任务。
在生成建模任务中,视频到视频(V2V)翻译在社交媒体、广告、推广活动、电视等方面具有巨大潜力。目前,大多数方法依赖于详细的文本描述,这要求准确描述原始和目标视频。此外,大多数方法依赖于耗时的训练和推理过程,如DDIM 反演。而指导性编辑采用用户友好的提示,但目前的技术只能应用于极少数的编辑场景。此外,尽管指导性文本能够减轻对专业提示的需求,但产生对期望输出的精确和详细描述有时需要领域知识,例如艺术或医学。为了能够提供更有效的指导,有必要简化这一过程。
为了解决这些问题,本文提出了一个通用的视频扩散框架,VIDiff,用于多模态指令的各种条件视频到视频翻译。本文的方法接受文本指令和源视频作为输入,并生成目标视频输出。除了文本指令外,还利用“worth a thousand words”的图像作为直观的指令,而无需专业知识。因此,为图像和文本引导的视频编辑设计了一种多模态条件注入机制。本文的方法经过多个阶段的训练,以适应预训练的T2I模型 进行V2V翻译。本文还设计了一个迭代的训练和推理方案,以实现长视频翻译。轻松地将本文的方法扩展到各种任务,建立了一个统一的视频理解和编辑框架。
总的来说,本文的主要贡献可以总结如下:
• 第一个为视频理解和视频增强任务使用统一扩散框架的研究。
• 设计了一个多阶段训练方法,无缝转移T2I模型,用于多模态条件视频翻译任务。
• 提出的迭代生成方法简单而有效,可轻松应用于长视频翻译任务。
• 进行了大量实验证明了方法在定性和定量上的有效性。
相关工作
「语言基础模型」
尽管语言基础模型已成功应用于各种任务,包括图像识别、图像文本检索、视觉问答,甚至图像生成和编辑。然而,对于视频语言基础模型的研究仍然有限。现有方法通常设计用于分类等理解任务。受对比学习的启发,Omnivl探索图像、文本和视频的跨模态对齐,展示在视频分类和检索任务中的有效性。Unmasked Teacher将遮蔽自编码器与对比学习结合在多模态范式中,使其适用于多样的视频语言任务,如分类、检索、时间检测和视频问答。类似Unicorn和OmniTracker的方法旨在统一视频对象分割和跟踪任务。然而,对于视频翻译任务的研究还有限。本文是第一个将多个视频翻译任务设计为统一的基础模型的研究。
「文本引导的图像翻译」
图像编辑是一个复杂的过程,涉及根据特定的指导修改图像,通常是由参考图像提供的,而不是在没有约束的情况下生成图像。已经开发了各种方法来解决这个任务。一种方法包括zero-shot图像到图像翻译技术,如SDEdit,它对参考图像应用扩散和去噪技术。其他方法包括优化技术来改进编辑过程。例如,Imagic利用了来自《An image is worth one word: Personalizing text-to- image generation using textual inversion》的文本反演概念。Null-text Inversion 利用Prompt-to-Prompt 在扩散模型中控制交叉关注力行为。然而,这些方法由于需要每个图像的优化而需要耗时的编辑过程。相反,Instruct Pix2Pix通过在配对的合成数据上进行训练来实现图像编辑。最近,InstructDiffusion在这一范式下统一了几个视觉任务。在本文中,专注于视频翻译任务,相对于图像而言更具挑战性。
「文本引导的视频编辑」
视频编辑方法通常需要原始视频和目标视频的详细文本描述,然后根据这些描述重建视频以进行编辑。Tune-A-Video 和 SimDA 对单一模型进行微调,以生成具有相似运动模式的新视频。Video-P2P 、Vid2Vid-Zero 和 FateZero 利用交叉关注图来调整视频。最近的InstructVid2Vid 和InsV2V 尝试构建基于指令的视频编辑。虽然我们有类似的结构,但重点是在通用框架中统一各种视频任务,我们的方法也适用于编辑长视频。
方法
潜在扩散模型(LDM)的基础知识
扩散模型通过两个关键过程来建模复杂的数据分布:扩散和去噪。给定分布p(x)的输入数据样本x,扩散过程通过在样本上添加随机噪声将其转换为,其中ε从标准正态分布N(0,I)中抽样。这个扩散过程通过T步实现,噪声调度器由参数和参数化。在去噪阶段,模型采用ε-预测和v-预测方法来学习去噪函数,该函数经过训练以最小化均方误差损失,如下所示:

「潜在扩散模型(LDM)」 利用了一个变分自编码器(VAE) 编码器 E 来将输入数据压缩到低维潜在空间。LDM 在训练和推理阶段都进行扩散和去噪过程。其优化目标为:
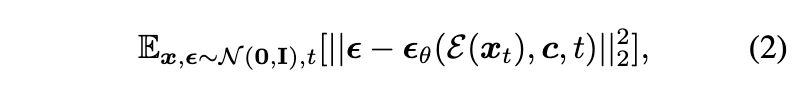
其中,c 是由预训练的 CLIPViT-L/14 模型从文本提示中提取的文本条件。LDM 是一个文本到图像的模型,我们在本文中将其调整为视频到视频的翻译任务。
问题定义
视频理解和生成任务在各个方面有所不同。然而,可以重新表述每个任务并提出一些共性。对于大多数常见的视频任务,可以将它们视为条件视频翻译任务。例如,视频对象分割可以被看作是将原始视频像素翻译成相应的分割图。视频着色任务涉及将灰度视频像素翻译成彩色视频帧。至于视频增强和视频编辑任务,它们本质上也是视频翻译任务。
打算设计一个统一的模型,能够同时处理所有这些任务。因此,在指导性视频翻译中以一致的方式处理上述任务。具体而言,给定源视频 和一条指令 c,目标是将 翻译成相应的目标视频 。为了实现这一目标,在训练阶段,为每个任务构建训练视频三元组 <, , c>。在推理阶段,该方法可以在给定指令 c 的条件下将源视频 翻译为目标视频 。
训练数据构建
正如前面提到的,视频到视频翻译模型的训练依赖于三元组的构建,这些三元组由组成。在本节中,将讨论如何为各种任务收集数据集。三元组数据集的可视化可以在下图1中找到。

「视频重新着色和修复」 对于视频重新着色和视频修复等任务,可以轻松地使用未标记的视频构建训练数据。任何视频都可以转换为灰度版本,并且可以通过创建任意形状的蒙版生成带有缺失部分的视频。至于指令,可以写诸如“convert the grayscale clip into a colorful masterpiece”和“repair the video with missing parts”等短语。这种方法使我们能够轻松地获取视频三元组。
「视频去雾和去模糊」 对于视频去噪和去雾等增强任务,可以利用该领域中常用的数据集,这些数据集都用相应的输入和真值数据进行了注释。因此,我们只需要手动写入一些指令短语,例如“remove the applied haze from this video”和“enhance the clarity of this blurry video”。
「语言引导的视频对象分割」 对于语言引导的视频对象分割任务,目标是根据自然语言指令在视频中识别和分割对象。利用专为此任务指定的已建立的数据集进行训练。至于指令,可以手动制作短语,例如“change the {object} pixels to {color}, while keeping the other pixels constant”。这些类型的指令可以产生优越的视觉效果。
「指导性视频编辑」 对于大多数基于扩散的视频编辑方法,需要对源视频和目标视频的详细文本描述。此外,在训练期间进行单次调整和在推理阶段进行DDIM Inversion 等操作是耗时且资源密集的。对于短视频,这个过程需要几分钟,限制了其实用性。相反,我们的方法在推理阶段只需要原始视频和编辑说明,能够在几秒钟内完成视频编辑。然而,构建视频编辑数据集是具有挑战性的。我们遵循,利用GPT和优秀的视频编辑模型来创建三元组训练数据。
视频任务的统一指导模型
在本小节中,介绍如何设计一个统一的指导模型来处理各种视频任务,并讨论如何将预训练的T2I模型转移到一般视频翻译任务。
「架构」 通用的T2I模型包含一个修改过的U-Net,包括4个下采样/上采样块和1个中间块。每个块通常由空间2D卷积层、自注意力层和带有文本条件的交叉注意力层组成。为了处理视频输入,将2D卷积层膨胀成 3D 卷积 。此外,还添加一个用于运动建模的普通时间注意力 层。在将具有 f 帧 [b, c, f, h, w] 的视频传递给时间模块之前,我们将其重塑为 [(b h w), f, c]。
为了在训练过程中无缝整合时间模块而不产生任何不良影响,我们采用零初始化方法初始化时间变换器的输出投影层,这是根据 [14, 63, 71] 的做法。
「训练阶段」 如下图2所示,设计了一个多阶段的训练方法,以转移 T2I 模型进行 V2V 翻译。

第一阶段恰好是原始的T2I模型训练。在第二阶段,引入了前面提到的时间注意力层,并将U-Net从 2D 膨胀到 3D。通过固定原始 T2I 模型的参数,我们调整时间模块以实现使用视频文本数据集的 T2V 生成。借助前一阶段的预训练,模型学到了良好的时间运动建模。在最后一个阶段,使用收集到的数据集对预训练网络进行微调,以完成视频到视频的翻译任务。
「多模态条件注入机制」 大多数先前的视频编辑方法依赖于提供的文本描述或具体说明。在这里,介绍了一种简单的多模态条件注入机制,用于视频编辑,如下图3所示。
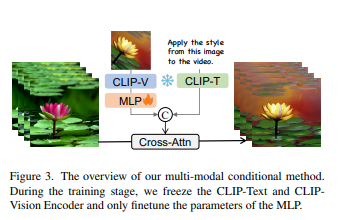
对于给定的文本指令,我们使用 CLIP-Text 编码器提取文本的嵌入。此外,我们希望将图像作为视觉指导以学习与图像样式相关的编辑模式。在训练期间,我们从目标视频中随机选择一帧,并应用数据增强,如翻转、旋转和裁剪,以创建图像指令。然后,该图像指令通过预训练的 CLIP-Vision编码器和一个新添加的 MLP 层进行处理。随后,我们沿着通道维度连接生成的图像嵌入和文本嵌入,形成联合指令嵌入。在这个训练设置中,CLIP 视觉和文本编码器保持固定,只有 MLP 层需要训练。这种方法允许有效的图像指令,消除了需要专业文本指令的需求,从而减少了对专业知识的需求。
「训练流程」 阶段3的详细训练流程如下图4(a)所示。

首先,源视频 和目标视频 都输入到预训练的 VAE编码器中,将它们转换为潜在空间中的 和 。随后,通过扩散过程向目标视频添加噪声。噪声潜在以及源视频的潜在(即条件潜在)在通道维度上连接,并输入到具有时间注意力的膨胀 U-Net 中。在这个过程中,源视频 和指令 c 作为条件,控制去噪过程以翻译到目标视频 。最小化以下潜在扩散目标:

除了根据指令翻译短视频片段外,方法还可以扩展到长视频翻译。训练过程也很简单。在构建训练对时,随机选择源视频的前 n 帧以与目标视频对齐。此外,修改指令以包括诸如“基于前n帧”等短语。这使得网络能够学习在指令中指定的帧数 n 与时间建模之间的对应关系。此外,这种方法通过在计算时间注意力时利用n个参考帧的信息,有助于保持跨每个剪辑的翻译的一致性。
在训练过程中,将多个任务结合到一个统一的训练范式中,每个训练步骤随机选择一个特定的任务。将在后面演示这种多任务训练范式和在单个模型中整合多样任务的有效性。
「推理流程」 在推理过程中,我们针对长视频采用迭代推理方法。如图4(b)所示,对于第一个剪辑 #1,我们采用常规的推理方法。基于源视频和指令作为条件,模型逐渐去噪,从高斯噪声中得到目标视频。一旦获得第一个剪辑,我们可以使用剪辑 #1 的最后 n 帧作为条件。对于下一个剪辑 #2,我们将源视频的初始 n 帧替换为前一个剪辑 #1 中对应的帧。通过这种重叠采样和迭代推理方法,我们的方法在上图4(c)所示的任意长度视频的翻译中保持一致性。
实验
设置
「数据集详情」 模型训练基于三元组 <source, target, instruction>,其中包括上述各种视频任务,如视频去雾、去模糊、重彩、修补、对象分割和视频编辑等。具体而言,对于去雾和去模糊任务,分别使用了 HazeWorld和BSD数据集。对于视频编辑任务,我们遵循 Instruct-Pix2Pix,使用GPT-4和先进的视频编辑模型创建了三元组数据。由于当前视频编辑模型的通用性存在一定局限性,我们仅生成了8,000 对数据,主要关注样式和颜色编辑任务。对于视频对象分割任务,使用 DAVIS-RVOS和 Refer-YoutubeVOS数据集构建了训练集。在训练过程中,将目标视频制定为半透明蒙版。至于视频重彩和修补任务,我们认为任何视频数据集都可以训练这样的网络。使用了上述提到的数据集以及来自 WebVid的部分数据来训练这些任务。
「实施细节」 使用 Stable Diffusion v1.5作为初始化,以利用文本到图像生成的先验知识。此外,利用 AnimateDiff的运动模块来初始化时间层,以实现更好的时间建模。在训练过程中,学习率设置为1e −4。输入视频帧包含16帧,分辨率为256×256。验证了即使在训练过程中使用低分辨率和固定分辨率,方法在推理过程中也可以轻松扩展到任意分辨率和宽高比。一旦训练完成,方法可以轻松应用于各种视频翻译任务。对于每个训练步骤,随机选择一个任务。通过这种方式,我们只需要训练一个统一的模型。由于多任务的相互学习,确认了统一模型的有效性。采用了无分类器扩散引导 ,并引入了两个引导尺度, 和 。这些尺度可以调整,以平衡生成样本与输入视频对齐的程度以及它们遵循编辑指令的程度。在下图5中展示了这两个参数对生成样本的影响。

实验结果
在这一部分,将与基线方法比较我们的模型在多个不同任务上的表现。
「视频编辑」 首先在下表1中列出了几种常见的视频编辑基线方法,比较了它们的各种属性。可以看到,这些方法大多基于一次性调整,意味着它们需要为特定要编辑的视频训练一个专用模型。这不仅需要额外的调整时间,还需要详细的源视频和目标视频的文本描述,极大地限制了它们的通用性。我们的方法类似于 [8, 40],因为它不需要额外的调整。此外,我们的方法支持多模态指令、各种任务以及对长视频的编辑。
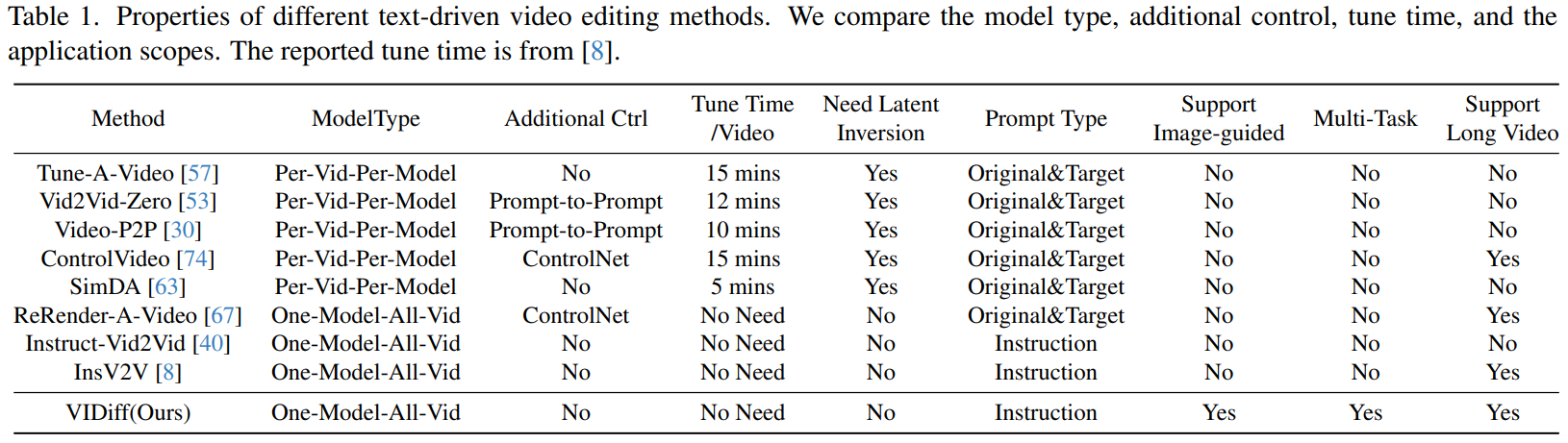
还按照以前的基准方法,复制了一些开源视频编辑技术以进行比较。报告了 CLIP 分数 、PickScore以及不同帧之间的帧一致性。此外,我们进行了用户研究,参与者被呈现了两组报告:一组来自我们的方法,一组来自其他方法。他们被要求选择其中一个在文本和视频匹配以及视频连续性方面更好的。实验结果如下表2所示。我们还报告了在单个NVIDIA A100 GPU上的调整和推断时间。

「视频重彩」 关于视频重彩任务,在一个广泛使用的基准数据集上进行实验。遵循以前的研究,并在 DAVIS数据集的验证集上验证了我们的方法。评估视频重彩任务通常涉及对感知逼真度、颜色生动度和时间一致性的评估。为了评估着色视频的感知逼真度,我们使用了 Fr ́echet Inception Distance (FID)指标,该指标衡量了预测颜色与实际分布之间的相似性。为了评估颜色生动度,采用了 Colorfulness指标。此外,为了评估时间一致性,利用了 Color Distribution Consistency (CDC)指数。此外,还在我们的研究中报告了 PSNR 、SSIM和 LPIPS等指标。将我们的方法与几种自动视频着色技术以及基于样例的视频着色基线进行比较。定量结果见下表3,展示了我们的方法在感知评估指标上的显著改进。此外,我们的方法在结构度量上保持了相当的性能。

「视频增强」 在几个常见的基准数据集上评估我们的模型在视频增强任务中的性能。我们遵循 [43, 65, 76] 的评估方法,其中包括在该领域常用的评估数据集,如 BSD的测试集、Youtube和 DAVIS等。定量结果见下表4。
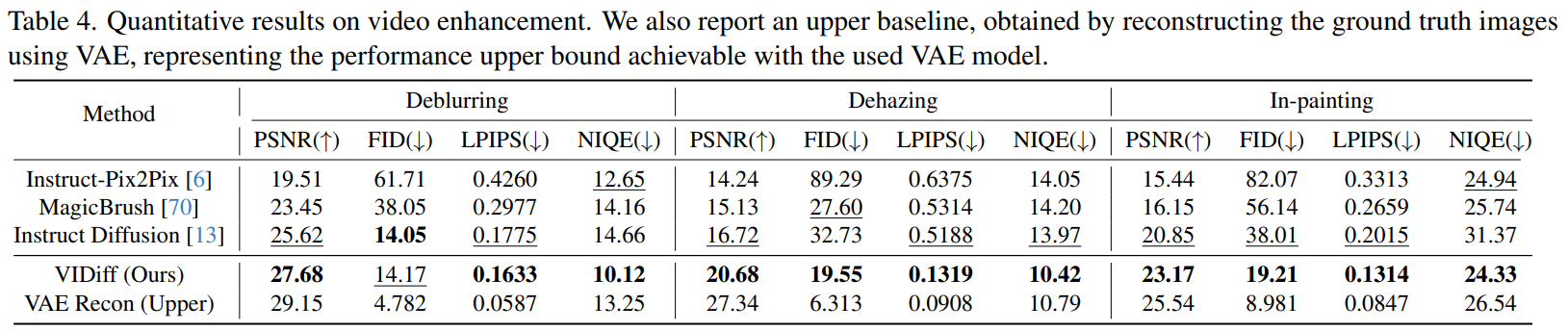
不仅报告了失真度量PSNR,以衡量编辑帧与实际结果之间的差异,还按照中描述的方法计算了一些审美感知图像质量指标,如FID 、LPIPS和 NIQE 。我们将我们的方法与几种主流开源指导性编辑技术进行了比较。可以看到我们的方法在所有指标上显著优于其他方法。最后,我们的模型在图像增强方面的性能受到 VAE模型的限制,这引入了信息损失。因此,我们还报告了VAE 重建原始图像的结果,并与实际结果进行了比较。这充当了一个上限基线,使我们能够衡量基于 LDM的方法可以达到的上限。
「可视化」 这里我们提供了 VIDiff 方法在视频翻译方面的更多可视化结果。我们在下面图8中展示了视频重彩任务的结果,图9展示了视频去雾和视频修补的结果,图10展示了视频去模糊和语言引导的视频对象分割的结果。我们还在图11中展示了多模态指导的视频编辑。对于完全渲染的视频,主要参考我们的项目页面(https://chenhsing.github.io/VIDiff)。






消融研究
「多任务训练的有效性」 目前,多任务学习越来越受欢迎。它不仅使单一模型能够处理多个相关任务,而且还使模型能够实现更好的泛化性能。我们进行了实验,将我们的多任务学习模型与单独训练的单任务模型进行比较。性能差异报告如下图7所示。这次比较涵盖了四个特定任务的测试数据集,表明我们联合训练的模型优于专门的模型。显然,联合训练的模型表现更好。此外,我们观察到这个优势在视频编辑领域也是适用的。

「多阶段迁移学习的好处」 正如我们所知,大多数视频编辑方法都依赖于转移预训练的 T2I 模型Stable Diffusion 。然而,像Instruct-Vid2Vid和 InsV2V这样的方法直接将 T2I 转移到 V2V。原始模型缺乏运动信息,导致时间建模效果差。微调使模型更加关注时间建模,忽略了模型内在的空间传递。我们采用了一种多阶段训练方法,有效地缓解了这个问题。如图7所示,消融实验表明,多阶段迁移方法相较于直接微调,能够获得显著更好的图像质量。
「长视频翻译的有效性」 对于视频重彩和视频编辑等任务,确保长视频的一致性是一个关键挑战。基于扩散的方法主要在短视频剪辑上进行训练,因此它们只能编辑相对较短的视频剪辑。我们提出的自回归长视频翻译范式有效地解决了这个问题。在我们的比较实验中(如下图6所示),可以观察到一个给定的长视频通常被分成不同的剪辑。没有长视频翻译(LVT)的约束,这些不同的剪辑在彼此之间完全不一致。而使用我们的方法,该方法能够在长视频的不同剪辑之间保持良好的一致性。

结论
总的来说,本文介绍了 Video Instruction Diffusion (VIDiff),这是一个新颖的统一框架,用于将视频任务与人类指令对齐。VIDiff将各种视频理解任务视为有条件的视频翻译问题,使我们能够基于指令将视频转化为期望的结果。在多个任务上展示了方法的有效性,联合训练增强了模型的泛化能力。这项研究在构建通用的视频任务建模接口方面迈出了重要的一步,为未来在追求视频理解方面的人工通用智能方面打开了道路。在未来的工作中,计划进一步探讨 VIDiff 的性能和能力,考虑与大语言模型的潜在集成,以实现更多用途的统一视频任务,如视频问答和视频上下文理解。
参考文献
[1] VIDiff : Translating Videos via Multi-Modal Instructions with Diff usion Models
链接: https://arxiv.org/pdf/2311.18837
更多精彩内容,请关注公众号:AI生成未来
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









