








文章链接:https://arxiv.org/pdf/2405.08911
CLIP 模型在zero-shot分类和检索任务中表现非常出色。但最近的研究表明,CLIP 中学习到的表示并不适用于目标检测、语义分割或深度估计等密集预测任务。为了缓解 CLIP 在下游任务中表现不佳的问题,最近引入了多阶段训练方法。
在这项工作中,发现简单地提高图文数据集中描述的质量可以改善 CLIP 的视觉表示质量,从而显著提升其在下游密集预测视觉任务中的表现。事实上,使用高质量描述进行 CLIP 预训练可以超越最近的监督、自监督和弱监督预训练方法。
本文展示了当使用 ViT-B/16 作为图像编码器的 CLIP 模型在经过良好对齐的图文对进行训练时,在语义分割和深度估计任务上分别比最新的 Masked Image Modeling (MIM) 预训练方法(如 Masked Autoencoder (MAE))高出 12.1% 的 mIoU 和低 11.5% 的 RMSE。发现移动端架构也显著受益于 CLIP 预训练。最近的一种移动端视觉架构 MCi2 通过 CLIP 预训练在语义分割任务上的表现与在 ImageNet-22k 上预训练的 Swin-L 相当,而其模型尺寸小了 6.1 倍。此外,还展示了提高描述质量在进行密集预测任务微调时提高了 10 倍的数据效率。
介绍
在计算机视觉领域,先在大规模语料库上进行预训练然后在目标任务上进行微调是一个常见的范式。在过去十年里,一种常见的预训练策略是在 ImageNet 上进行有监督的预训练。最近,诸如对比语言-图像预训练(CLIP)、BEiT和 DINO等在大规模数据集上训练的模型显示出能够学习到通用且高度可迁移的视觉表示。这些预训练模型随后被用作初始化,并在各种下游任务(如目标检测、语义分割和深度估计)中进行微调。
尽管存在多种预训练方法,但没有一种方法能够对所有下游任务表现最佳。此前,CLIP 预训练在密集预测任务(如目标检测和深度估计)上的表现相比 MIM 预训练方法(例如 MAE)和自监督学习(SSL)方法(例如 DINO)不尽如人意。在这项工作中,我们实证研究了以下研究问题:相比 MIM,CLIP 是否在本质上是一个不适合密集预测任务的预训练选择?
在 CLIP 预训练中,学习了一个图像编码器和一个文本编码器,以对齐来自(图像,文本)对的embedding。通过网络爬虫收集的大规模(图像,文本)数据通常是噪声较大的:文本和图像内容可能不太匹配。Cherti 等人表明,预训练数据集的规模显著影响 CLIP 图像和文本编码器学习到的表示质量。在这项工作中,展示了描述(文本模态)的质量显著影响视觉表示(图像模态)的质量。我们发现,通过对齐的描述训练的 CLIP 图像编码器特征不仅在语义区分任务中迁移良好,还在密集预测视觉任务中带来了显著的性能提升。
CLIP 预训练在移动架构上效果很好。大多数移动架构,如[23, 29, 45, 46],要么是CNN-Transformer混合设计,要么是纯卷积设计。像MAE这样的预训练方法是为Transformers量身定制的,不能直接应用于移动端架构。CLIP在DataCompDR上的预训练提高了移动架构在密集预测任务(如目标检测和语义分割)上的性能。后面将发布微调代码及所有checkpoints。
本工作的主要贡献如下:
-
通过系统实验,证明了CLIP能够学习适用于密集预测任务的视觉特征,前提是预训练数据集中的图文对是对齐的。
-
详细比较了CLIP和MAE的预训练策略。展示了在不同的训练计划下,若数据集包含高质量的描述,CLIP预训练可以超过MAE。
-
详细分析了CLIP预训练在密集预测任务中的数据扩展趋势。展示了提高描述质量能够提升数据效率。
-
证明了CLIP预训练即使在移动架构上也有显著益处,在检测、分割和深度估计等视觉任务上实现了最先进的准确率-延迟权衡。
背景
在计算机视觉中学习可迁移表示是一项活跃的研究领域。一个常见的范式是先进行预训练,然后在下游任务(如检测、分割、深度估计等)上进行微调。有监督的预训练被广泛使用,其中模型在大规模标注数据集上进行训练。但大规模获取准确标签是一项挑战,而且大多数大规模标注数据集(如 JFT)是私有的。
最近,自监督预训练取得了显著进展。大多数这些方法不需要准确标注的数据集,而是使用预训练策略,例如实例对比学习、拼图解谜、联合embedding或mask区域重建。特别是,MAE显示出能够学习高度可迁移的表示。但 MAE 存在局限性——Singh 等人表明,较小的图像编码器如 ViT-B/16 无法从数据集扩展中受益。在[43]中,MAE 之后进行弱监督预训练的第二阶段,以在下游任务上获得进一步的显著改进。
对比语言-图像预训练 (CLIP)
CLIP 是一种图像-文本模型,将图像和文本映射到一个联合embedding空间中。CLIP 由图像和文本编码器组成,训练数据集是大规模的配对图像-文本样本,以使得相似的图像和文本被映射得更近,而不同的样本被映射得更远。给定一批个图像-文本对,用,表示 CLIP 模型的图像和文本的维embedding。令表示embedding向量v和embedding矩阵 U之间的相似度,经过温度参数的 Softmax 归一化。
CLIP 损失由图像到文本的损失和文本到图像的损失组成,其中图像到文本的部分定义如下:
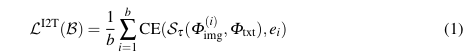
其中,CE 表示交叉熵损失, 是一个在第i个坐标上为 1,其他地方为 0 的b维一热向量。类似地,文本到图像的损失是通过交换文本和图像embedding来定义的。
数据质量对 CLIP 的重要性
CLIP 在下游分类任务中展示了显著的zero-shot能力,而无需在特定任务数据上进行微调。在 CLIP中,一个多模态模型使用来自网络的图像及其噪声文本标注进行训练。最近,数据集规模显著扩大,CLIP 预训练在zero-shot图像分类和检索性能上显示出显著的改进。
Fang 等人表明,CLIP 预训练数据分布的质量和多样性可以解释其新兴的zero-shot能力。基于这一观察,Gadre 等人提出了 DataComp 基准,用于寻找最佳的 CLIP 训练集,并提出了 DataComp-1B(BestPool 过滤),使用公共数据集显著改进了 CLIP 训练,与之前的数据集 LAION-2B相比。最近,Vasu 等人引入了 DataCompDR,除了其他信息,还在大规模的 DataComp-1B 中添加了合成描述,这些描述更干净且对齐良好。
此前,尚未研究过规模和质量对 CLIP 预训练在下游密集预测任务中的影响。Nguyen 等人研究了改进描述以提高图像检索和图像描述生成的性能。Wei 等人观察到 CLIP 预训练在密集预测任务上表现不如其他预训练方法,并建议增加一个微调步骤以改进 CLIP 图像编码器。文献[49]中的结果仅限于早期在相对较小的数据集上训练的 CLIP 模型。相比之下,我们发现,使用更大规模的 DataComp进行 CLIP 预训练,与其他预训练方法相比具有高度竞争力。在这项工作中,展示了在改进描述质量的数据集(如 DataCompDR)上训练的 CLIP 模型显著提高了下游密集预测任务的视觉表示质量。
分析
使用合成描述的 CLIP
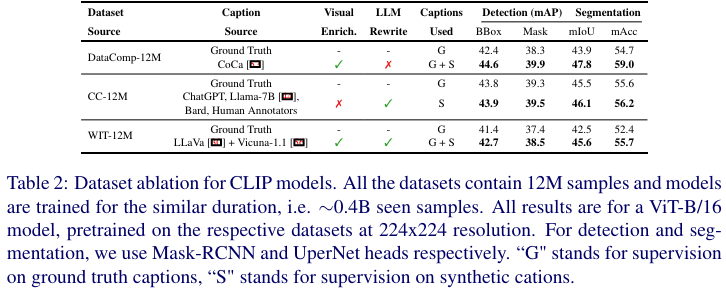
虽然 DataComp 使用过滤启发式方法来获得高质量的描述,但最近的方法已经使用大型视觉基础模型和语言模型生成高质量的合成描述。与来自网络的噪声文本相比,这些描述通常与相应图像更好地对齐且质量更高。我们比较了最近 MobileCLIP、LaCLIP 和 VeCLIP工作中,使用真实描述和合成高质量描述预训练的 CLIP 模型的微调性能。LaCLIP 主要使用大语言模型(LLMs)重写描述,VeCLIP 使用 LLaVA 模型和一个 LLM 为他们的数据集(称为 VeCap)生成描述。
MobileCLIP 使用 CoCa 模型为 DataComp数据集生成描述,从而形成 DataCompDR。VeCap 和 DataCompDR 通过使用视觉语言基础模型生成视觉丰富的描述,而 LaCLIP 仅依赖于 LLM 重述现有的描述。从表2可以看出,改进描述质量导致图像编码器在密集预测任务中具有更好的迁移能力。我们还发现,使用视觉丰富描述预训练的 CLIP 模型在密集预测任务中表现更好。
CLIP 与 MAE
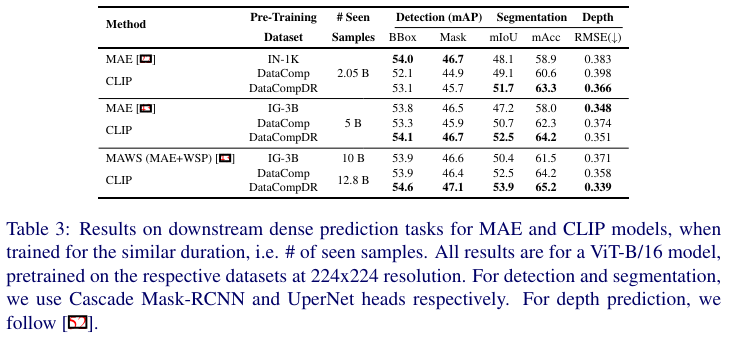
为了公平比较这两种流行的方法,在 DataComp 和 DataCompDR数据集上训练了一个 CLIP 模型,并在两个预训练方法之间匹配所见样本数量(即全局批量大小 × 总迭代次数)。在下表3中,对于 2.05B 个所见样本,我们观察到在目标检测任务中 MAE 比 CLIP 高出 0.9 mAP,但在 DataCompDR 上预训练的 CLIP 在分割任务中比 MAE 高出 3.6 mIoU,在深度估计任务中 RMSE 低 4.4%。
当 MAE 预训练扩展到包含 3B 个独特图像和 28K 类别的 IG-3B 数据集时,我们在检测和分割任务中没有看到任何改进。而 CLIP 预训练在目标检测任务中超过了 MAE,并在分割任务中进一步提高了 4.4 mIoU。在这个规模上,MAE 仅在深度估计任务中表现优于 CLIP 预训练。当在与 MAWS相似的规模上在 DataCompDR 上训练更长时间的 CLIP 模型时,它在所有下游密集预测任务中都超过了 MAE 和 MAWS。
数据扩展
为了理解扩展数据集规模的效果,在 DataComp 和 DataCompDR 上训练 CLIP 模型,子集范围从 1.28M 到全部 1.28B 样本,并在下图2中比较它们的微调性能。对于所有实验,预训练 20k 次迭代,全局批量大小为 65k(相当于在 1.28B 上训练一个周期)。使用第4节中描述的设置,微调图像编码器以进行下游任务。从下图2中,发现改进描述质量在微调密集预测任务时提高了数据效率。在 MS COCO 上,预训练在 DataCompDR 的 12.8M 子集上的 CLIP 模型获得了 44.2 的 mAP,略低于在 DataComp 的 128M 子集上预训练获得的 44.6 mAP(用于目标检测任务)。CLIP 模型可以在 DataCompDR 的 10倍小的子集上进行预训练,以获得与在 DataComp 的较大子集上预训练相似的性能。
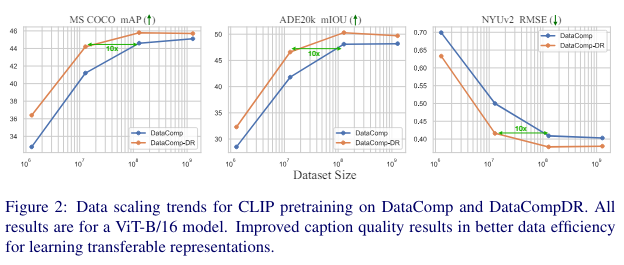
表示分析
为了理解描述质量的影响,绘制了整个 ImageNet-1K 验证集上的平均注意力距离。这有助于我们理解信息流,因为它部分反映了每个注意力头的感受野大小。按照[49]中的描述,[CLS] token 被忽略在平均计算中。从下图3中,我们注意到每个头的平均注意力距离有差异,特别是对于在 DataComp 和 DataCompDR 上训练的描述更干净和更对齐的模型。
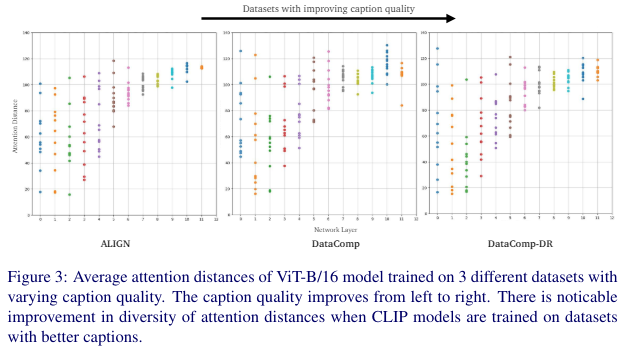
对于在包含噪声描述的 ALIGN 数据集上训练的 CLIP 模型,注意到注意力距离的多样性较少,特别是在较深层次。这直观上表明,最后几层可能存在冗余,模型的容量可能未被充分利用,如[52]所述。当在 DataCompDR 中引入更对齐的描述时,注意到注意力头趋向于更局部,同时保持层内的多样性。正如[31, 49]中观察到的那样,局部注意力对密集预测任务更有利。因此,在描述噪声较少且与图像更对齐的数据集上训练的 CLIP 模型在密集预测任务中表现更好。
实验
本文评估了 CLIP 模型的视觉编码器在四个下游任务中的性能:图像分类、实例分割、语义分割和深度估计。主要关注所有任务的端到端微调性能。
CLIP 预训练。遵循 [28, 47] 中的方法,在 DataComp 和 DataCompDR 上训练 CLIP 模型。对真实描述和合成描述最小化 CLIP 的对比损失,如 [28, 47] 中常见的方法。选择 DataComp 和 DataCompDR 进行实验是因为它们的规模,即 12.8 亿图文对。其他公开可用的数据集如 [16, 28] 仅包含 2 到 4 亿图文对。详细的超参数列表将在补充材料中提供。对于移动架构,直接使用 [47] 中在 DataCompDR 上预训练的 CLIP 模型。
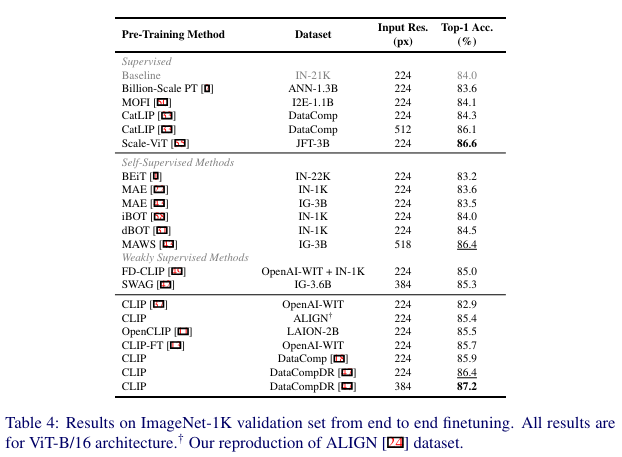
图像分类。在 ImageNet-1K 数据集上微调视觉编码器 100 个周期,遵循 [31, 49] 中的设置。关于具体设置的更多细节将在补充材料中提供。在表4中,我们将监督基线(灰色)与最近的自监督和弱监督方法进行了比较。从下表4可以明显看出,在具有大规模高质量描述的数据集上进行 CLIP 预训练的效果优于最近的最先进预训练方法和在较大噪声描述数据集上训练的其他 CLIP 模型。
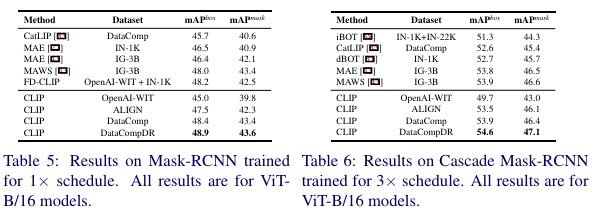
目标检测和实例分割。报告了在 MS-COCO数据集上使用 MaskRCNN 头和 Cascade-MaskRCNN 头进行实例分割的所有模型的性能。模型使用 MMDetection 库 进行训练。MaskRCNN 模型使用 1× 计划进行训练,采用单尺度测试,如 [49] 中描述。Cascade-MaskRCNN 模型使用 3× 计划进行训练,采用单尺度测试。遵循 [31, 49] 中描述的微调设置,更多细节在补充材料中提供。从下表5和表6中可以看出,ViT B/16 在 DataComp 和 DataCompDR 上进行 CLIP 预训练的效果优于最近的最先进预训练方法。
语义分割。使用 UperNet头并遵循 [31] 中描述的设置。模型使用 MMSegmentation 库进行训练。对于移动端模型,使用 SemanticFPN头并按照 [45] 中描述的设置进行训练。更多细节将在补充材料中提供。从下表7中可以看出,CLIP 预训练显著有利于分割任务。事实上,在噪声 ALIGN数据集上训练的 CLIP 也优于 MAWS。当在 DataCompDR 上进行预训练时,我们观察到 mIoU 有显著的 3.5(6.9%)的提升。
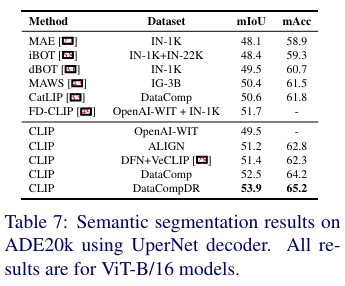
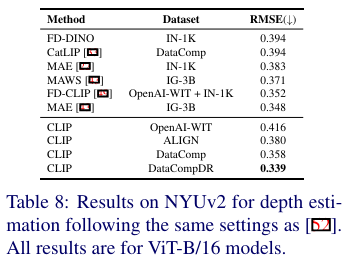
深度估计。在 NYUv2 数据集上报告了均方根误差(RMSE)。使用 [49, 52] 中描述的相同设置,更多细节将在补充材料中提供。从下表8中可以看出,DataCompDR 上预训练的 ViT-B/16 优于最近的最先进预训练方法和多阶段预训练方法,如 [43, 49]。
LIP 预训练对移动架构的影响
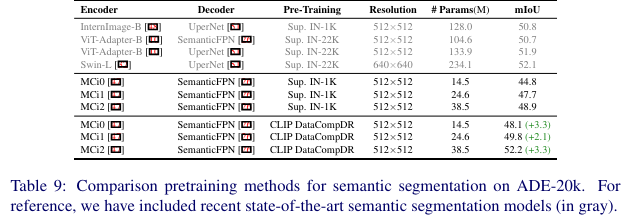
前面分析了在 DataCompDR 上进行 CLIP 预训练对较大架构(即 ViT-B/16)的影响。本节分析 CLIP 预训练对移动架构的好处。具体来说,微调了最近开源的 MobileCLIP 图像编码器。将广泛使用的 ImageNet-1K 上的监督预训练与 DataCompDR 上的 CLIP 预训练进行了比较。
从下表9可以看出,CLIP 在 DataCompDR 上进行预训练使最小架构的 mIoU 提高了 3.3。MCi2 模型获得了 52.2 的 mIoU,类似于更大架构如 Swin-L 和 ViT-Adapter-B模型。
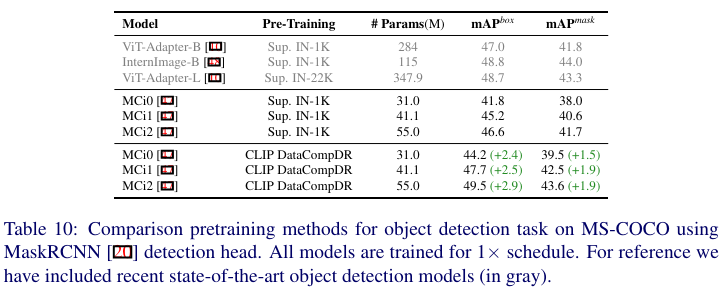
在下表10中,观察到最小模型的边界框 mAP 提高了 2.4,mask mAP 提高了 1.5。MCi2 模型获得了 49.5 的边界框 mAP,这与较大架构如 ViT-Adapter-L相当,甚至优于较新的专用架构如 InternImage-B。
结论
这项工作中,分析了 CLIP 预训练对下游密集预测任务的性能影响。发现预训练数据集的规模和描述的质量有显著的区别。系统地与 MAE(一个流行的视觉变换器自监督预训练方法)进行了比较。与之前的工作相比,表明 CLIP 预训练在与 MAE 竞争时非常有竞争力,甚至在规模上超过 MAE 和最近的 MAWS 预训练方法。表明在具有良好质量描述的数据集上进行大规模 CLIP 预训练会产生一个图像编码器,它能够学习到高度可迁移的表示。此外还表明,CLIP 预训练对较小的架构也有好处。
参考文献
[1] CLIP with Quality Captions: A Strong Pretraining for Vision Tasks















 158
158











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









