







标题:王者归来!Stability-AI又放大招 | Stable Cascade:更快更强的图像生成模型!

Stable Diffusion官方最新发布了Stable Cascade,相较于之前的SD-1.5以及SDXL模型有了质的提升。可谓开源王者归来!
该模型是建立在 Würstchen 架构之上的,与其他模型(如Stable Diffusion)的主要区别在于它在一个更小的潜在空间中运行。为什么这很重要?潜在空间越小,推理速度越快,训练成本越低。潜在空间有多小?Stable Diffusion使用了一个压缩因子为 8,将 1024x1024 的图像编码为 128x128。Stable Cascade实现了一个压缩因子为 42,这意味着可以将 1024x1024 的图像编码为 24x24,同时保持清晰的重构。文本条件模型随后在高度压缩的潜在空间中进行训练。该架构的先前版本实现了比Stable Diffusion 1.5 低 16 倍的成本。
因此,这种类型的模型非常适合对效率要求较高的用途。此外,该方法还可以实现所有已知的扩展,如微调、LoRA、ControlNet、IP-Adapter、LCM 等。训练和推理部分已经提供了其中一些扩展(微调、ControlNet、LoRA)。
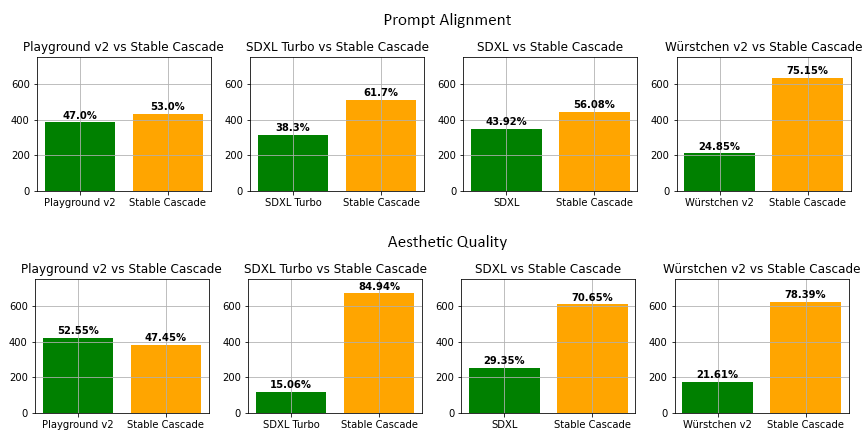
此外,Stable Cascade取得了令人印象深刻的结果,在视觉上和评估上均表现出色。据官方的评估,Stable Cascade在几乎所有比较中在提示对齐和美学质量方面表现最佳。下图显示了使用一组混合的提示和美学提示进行的人类评估结果。具体来说,Stable Cascade(30 个推理steps)与 Playground v2(50 个推理steps)、SDXL(50 个推理steps)、SDXL Turbo(1 个推理steps)和 Würstchen v2(30 个推理steps)进行了比较。
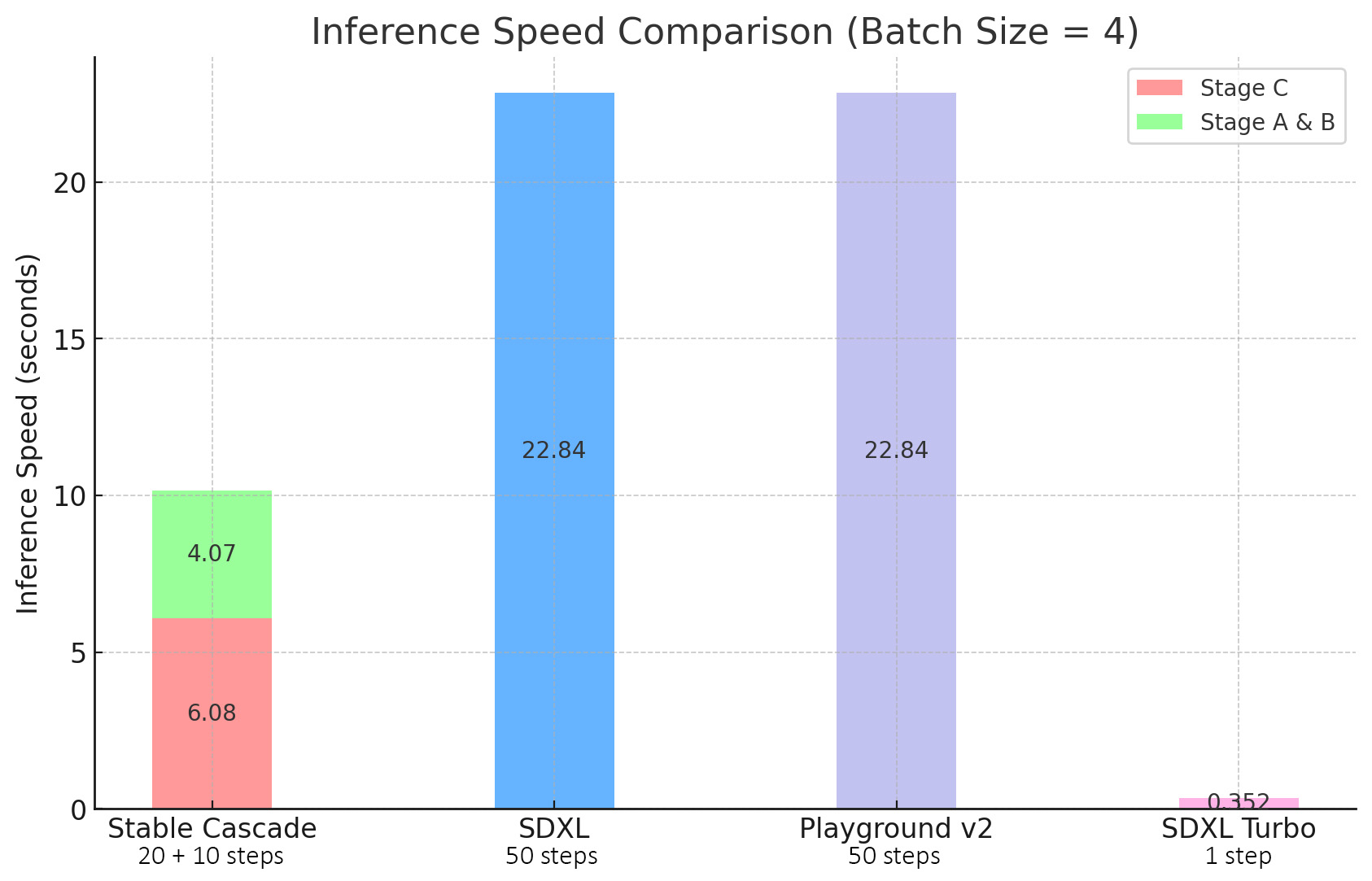
Stable Cascade通过其架构和更高压缩的潜在空间来体现其对效率的关注。尽管最大的模型比Stable Diffusion XL还要多14 亿参数,但仍然具有更快的推理时间,如下图所示。

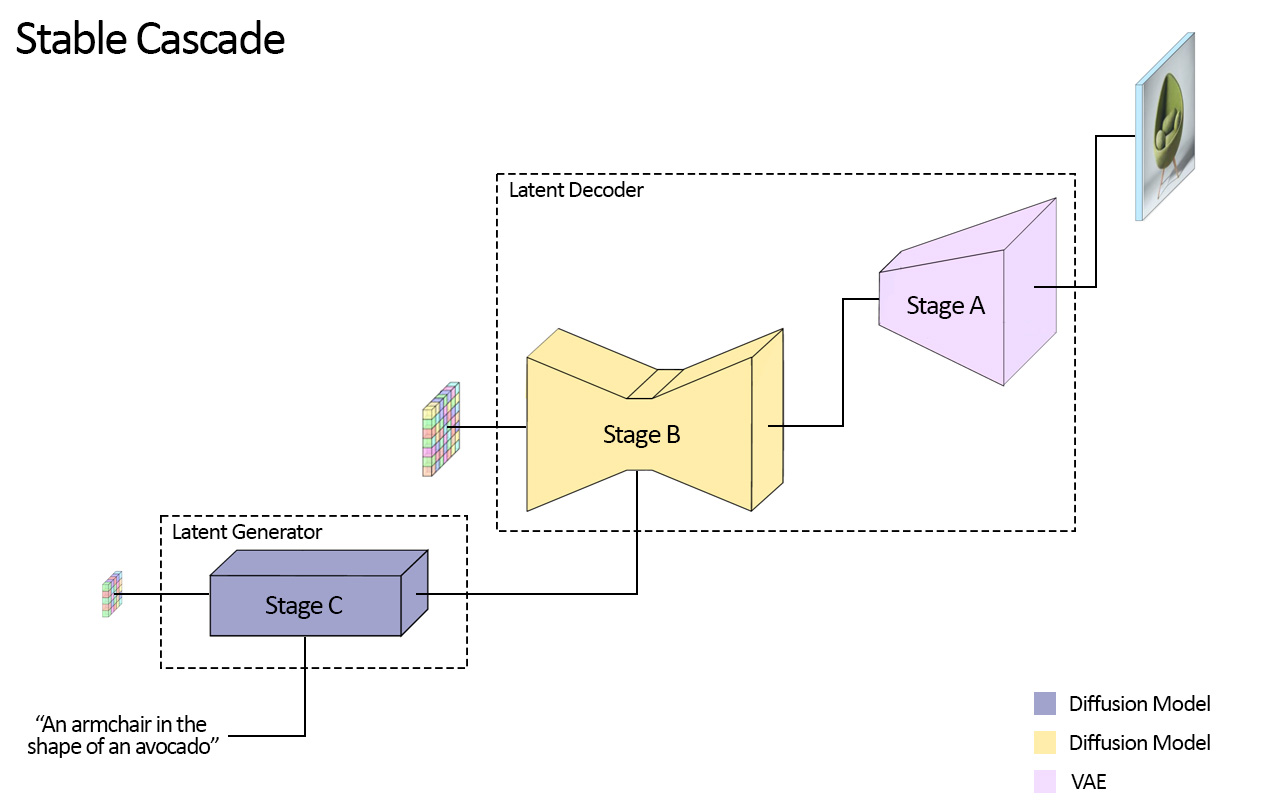
模型概述
Stable Cascade由三个模型组成:Stage A, Stage B和Stage C,,代表了用于生成图像的阶段,因此得名“Stable Cascade”。Stage A 和 B 用于压缩图像,类似于Stable Diffusion中 VAE 的工作。然而,正如前面提到的,通过这种设置可以实现对图像的更高压缩。此外,Stage C 负责在给定文本提示的情况下生成小尺寸的 24 x 24 的潜在特征。以下图片以可视化方式展示了这一点。请注意,阶段 A 是一个 VAE,而Stage B 和 C 都是扩散模型。
对于此版本,提供了三个阶段的checkpoints,其中阶段 C 提供了一个 10 亿参数版本和一个 36 亿参数版本,强烈建议使用 36 亿参数版本,因为大部分工作都是针对其微调的。阶段 B 的两个版本分别为 7 亿参数和 15 亿参数。两者都取得了出色的结果,但是 15 亿参数版本在重建小而精细的细节方面表现出色。因此,如果您使用每个阶段的更大变体,将会获得最佳结果。最后,阶段 A 包含 2000 万参数,并且由于其size小而被固定。
入门指南
推理
通过推理部分提供的推理说明文档可以运行模型。
里面有关下载模型、计算要求以及如何使用模型的一些教程的更多详细信息。
文生图
文生图文档提供文本到图像、图像变体和图像到图像的基本功能。
● 文生图
"Cinematic photo of an anthropomorphic penguin sitting in a cafe reading a book and having a coffee."

● Image Variation
该模型还可以理解图像embeddings,这使得生成给定图像的多角度变化(左图)成为可能。这里没有prompt。

● 图生图
这个过程与通常操作一样,通过将图像添加噪声直到特定程度,然后让模型从该起始点生成图像。这里左侧的图像被加入了噪声达到了 80%,并附带了标题:A person riding a rodent.

此外,该模型也可以在 huggingface 库中访问到。地址:https://huggingface.co/stabilityai/stable-cascade
ControlNet
ControlNet说明文档展示了如何使用训练的 ControlNet,或者如何使用自己训练的 ControlNet 来为 Stable Cascade 提供支持。此版本提供了以下 ControlNet:
● Inpainting / Outpainting

● Face Identity

注意:Face Identity ControlNet目前还未发布,会在以后的某个时间发布。
● Canny

● 超分辨率

这些都可以通过同一个文档使用,并且只需要针对每个控制网络更改配置。可参考:https://github.com/Stability-AI/StableCascade/tree/master/inference
LoRA
官方还提供了LoRA 训练和使用Stable Cascade的实现,可以用于微调文本条件模型(Stage C)。具体来说可以添加和学习新的标注,并向模型添加 LoRA 层。LoRA文档展示了如何使用训练好的 LoRA。例如,对狗进行训练的 LoRA,使用以下类型的训练图像:

生成以下给定提示的狗的图像:
Cinematic photo of a dog [fernando] wearing a space suit.

图像重建
最后,对于人们可能非常感兴趣的一件事,特别是如果您想从头开始训练自己的文本条件模型,甚至可能使用与Stage C 完全不同的架构,那就是使用Stable Cascade使用的(扩散)自编码器,以便能够在高度压缩的空间中工作。就像大家使用Stable Diffusion的 VAE 来训练自己的模型(例如 Dalle3)一样,您可以以同样的方式使用Stage A 和 B,同时从更高的压缩中受益,使您能够更快地训练和运行模型。
文档中也展示了如何对图像进行编码和解码,以及您获得的具体好处。例如,假设您有以下维度为 4 x 3 x 1024 x 1024 的图像batch:

可以将这些图像编码成压缩尺寸为 4 x 16 x 24 x 24,从而获得空间压缩因子为 1024 / 24 = 42.67。然后,您可以使用Stage A 和 B 将图像解码回 4 x 3 x 1024 x 1024,得到以下输出:

正如所看到的,即使对于小细节,重建结果也出奇地接近。标准的 VAE 等等是无法实现这样的重建的。图像重建说明文档中提供更多信息和易于尝试的代码。
训练
官方提供了从头开始训练Stable Cascade、微调、ControlNet 和 LoRA 的代码。大家可以在训练文件夹中找到如何执行这些操作的详细说明。
备注
Stable Cascade代码库处于早期开发阶段。可能会遇到意外错误或训练和推理代码不完全优化的情况。

Gradio App
首先安装gradio 和 diffusers:
pip3 install gradio
pip3 install accelerate # optionally
pip3 install git+https://github.com/kashif/diffusers.git@wuerstchen-v3
然后从工程根目录运行以下命令:
PYTHONPATH=./ python3 gradio_app/app.py
参考链接
github地址:
https://github.com/Stability-AI/StableCascade?tab=readme-ov-file
模型下载:
https://huggingface.co/stabilityai/stable-cascade/tree/main
推理说明文档:
https://github.com/Stability-AI/StableCascade/tree/master/inference
文生图文档:
https://github.com/Stability-AI/StableCascade/blob/master/inference/text_to_image.ipynb
ControlNet文档:
https://github.com/Stability-AI/StableCascade/blob/master/inference/controlnet.ipynb
LoRA文档:
https://github.com/Stability-AI/StableCascade/blob/master/inference/lora.ipynb
图像重建说明文档中:
https://github.com/Stability-AI/StableCascade/blob/master/inference/reconstruct_images.ipynb
训练文件夹:
https://github.com/Stability-AI/StableCascade/blob/master/train
参考论文: Wuerstchen: An Efficient Architecture for Large-Scale Text-to-Image Diffusion Models
更多精彩内容,请关注公众号:AI生成未来

欢迎加群交流AIGC技术


















 736
736

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









