









论文链接:https://arxiv.org/pdf/2408.13423
git链接:https://github.com/Confiner2025/Confiner2025
亮点直击
创新性解耦策略:ConFiner框架通过将视频生成任务解耦为三个独立的子任务,显著优化了生成过程。该方法利用了三种现有的扩散模型专家,每个专家专注于一个特定的任务,从而降低了模型的计算负担,同时提升了生成的质量与速度。
协调去噪技术:该技术在视频生成过程中引入了协作机制,使得使用不同噪声调度器的两个专家能够实现逐步协作,有效提升了视频生成的精细度与一致性。
长视频生成突破:在ConFiner框架基础上,ConFiner-Long通过三种策略实现了高质量、连贯的长视频生成。该框架能够生成长达600帧的连贯视频,标志着长视频生成技术的显著进步。
效果一览
总结速览
解决的问题
-
视频生成质量低:难以同时实现高质量的时间和空间建模。
-
生成过程耗时:通常需要数百次推理步骤,时间成本较高。
-
生成视频长度短:由于VRAM限制,生成视频的长度通常只有2-3秒。
-
模型负担重:单一模型处理复杂的多维度视频生成任务,难以兼顾所有需求。
提出的方案
-
ConFiner框架:将视频生成任务解耦为三个子任务(结构控制、时间细化和空间细化),并使用三个专门的扩散模型专家分别处理这些任务。
-
ConFiner-Long框架:在ConFiner基础上引入三种策略(片段一致性初始化、一致性引导、交错细化)以生成更长的连贯视频。
应用的技术
-
协调去噪技术:解决不同扩散模型之间噪声调度器不一致的问题,使空间和时间专家能够协同工作。
-
片段一致性初始化:通过共享基础噪声,确保不同视频片段初始噪声的一致性。
-
一致性引导策略:利用片段间的噪声差异梯度引导去噪方向,增强去噪的一致性。
-
交错细化策略:在片段交界处将控制阶段和细化阶段交错处理,避免片段拼接处的闪烁问题。
达到的效果
-
提高视频生成质量:通过将任务分解并交给专门模型处理,减少了单一模型的负担,提高了生成的质量。
-
加快生成速度:ConFiner框架只需9次采样步骤即可超越其他模型在100次采样中的表现,生成时间显著减少。
-
生成更长的视频:ConFiner-Long框架能生成长达600帧的高质量且连贯的视频片段。
-
无需额外训练成本:利用现成的扩散模型专家,不需要额外的训练成本。
方法
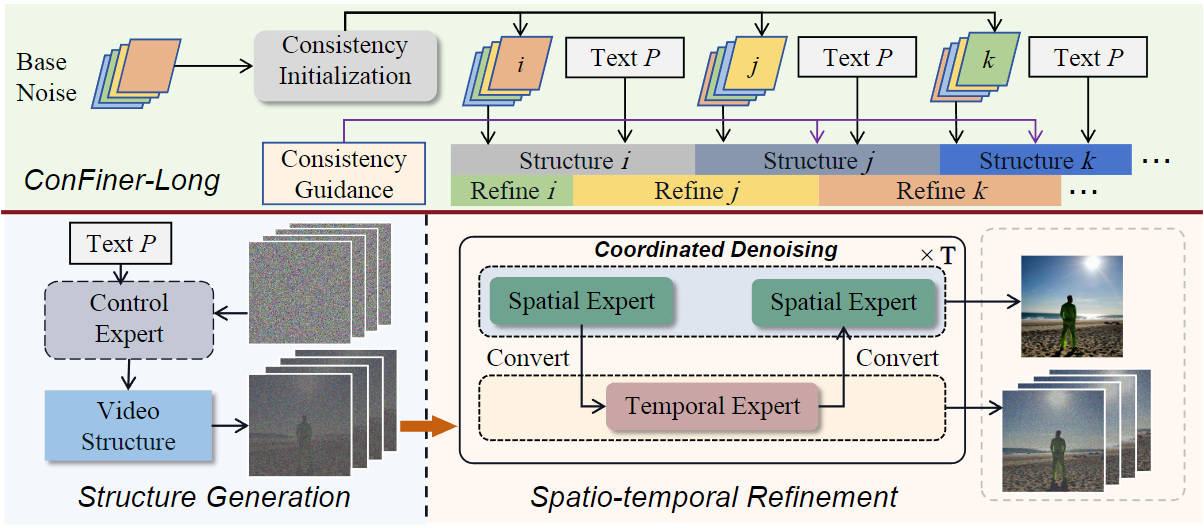
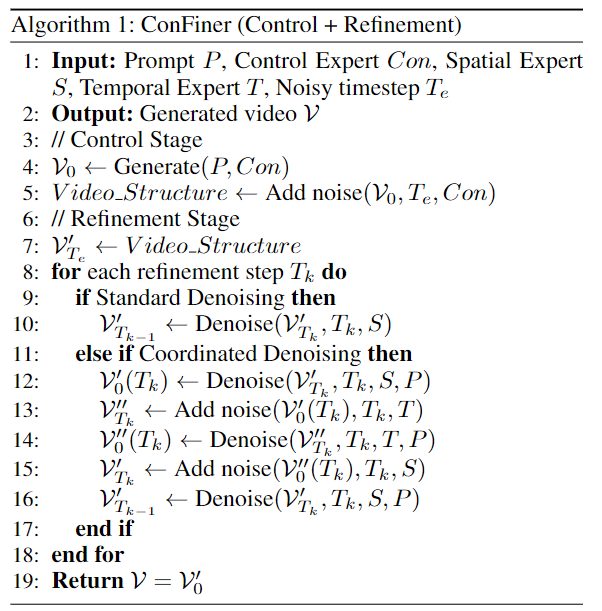
ConFiner由两个阶段组成:控制阶段和精炼阶段。在控制阶段,它生成一个包含粗粒度时空信息的视频结构,该结构决定了最终视频的整体结构和情节。在细化阶段,它根据视频结构细化空间和时间细节。在这个阶段,作者提出了协调去噪,以实现空间专家和时间专家的合作。基于ConFiner,引入了ConFiner Long框架,用于制作连贯一致的长视频。
ConFiner和ConFiner Long的pineline见下图:
ConFiner 框架
ConFiner将视频生成过程解耦。首先,控制专家生成视频结构。随后,时间和空间专家对时空细节进行了细化。空间和时间专家在细化阶段与我们的协调去噪合作。
ConFiner-Long 框架
- 一致性初始化策略:
-
设计一致性初始化策略来提高视频片段之间的一致性。首先采样一个基础噪声 ,然后对其进行帧级打乱,以获得每个片段的初始噪声。共享基础噪声有助于提高片段之间的一致性,同时打乱操作保持了一定的随机性。
-
- 交错细化机制:
-
在生成长视频时,采用交错的控制阶段和细化阶段处理方法。具体来说,将前一个视频片段的后半部分与下一个片段的前半部分作为同一次细化处理的输入,从而实现更自然的片段过渡。这种方法有助于减少过渡处的断裂感。
-
- 一致性引导机制:
-
引入一致性引导机制来促进生成内容与前一个片段的一致性。在视频片段的采样过程中,利用L2损失的梯度来引导采样方向。L2损失计算当前片段噪声与前一个片段噪声之间的差异,并通过调整噪声预测来提高片段间的一致性。
-
总结而言,这些方法通过空间和时间专家的交替处理和一致性策略,旨在提高视频生成的质量和一致性,特别是在长视频生成过程中,确保了视频片段之间的平滑过渡和连贯性。
快来看,ConFiner Long方法仅用9个推理步骤生成的视频:

实验
效果对比
ConFiner 与其他视频扩散模型的训练和推理成本。结果展示在下表 4 中。
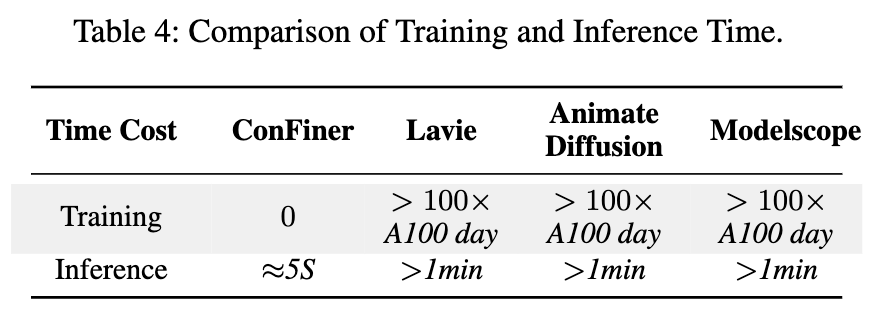
研究者们使用了 AnimateDiff-Lightning 作为控制专家,Stable Diffusion 1.5作为空间专家。Lavie和 Modelscope两个开源模型为时间专家。
客观评价
作者使用了前沿基准测试工具 Vbench在客观评价实验中。Vbench 提供了 800 个提示,用于测试视频生成模型的各种能力。在我们的实验中,每个模型生成了 800 个视频,并使用四个指标评估视频的时间质量和逐帧质量。
-
时间质量指标:主观一致性(Subject Consistency)和运动平滑度(Motion Smoothness)。
-
逐帧质量指标:美学质量(Aesthetic Quality)和成像质量(Imaging Quality)。
使用了 AnimateDiff-Lightning、Lavie 和 Modelscope T2V,分别生成了 10、20、50 和 100 步的总时间步数的视频。然后,使用 ConFiner 进行生成,设置为 9(4+5)步和 18(8+10)步,其中 Te 设置为 100。所有评价结果展示在表 1 中。每个实验在单个 RTX 4090 上可以完成,耗时 3-5 小时。每个实验重复进行了五次,使用不同的随机种子。
主观评价
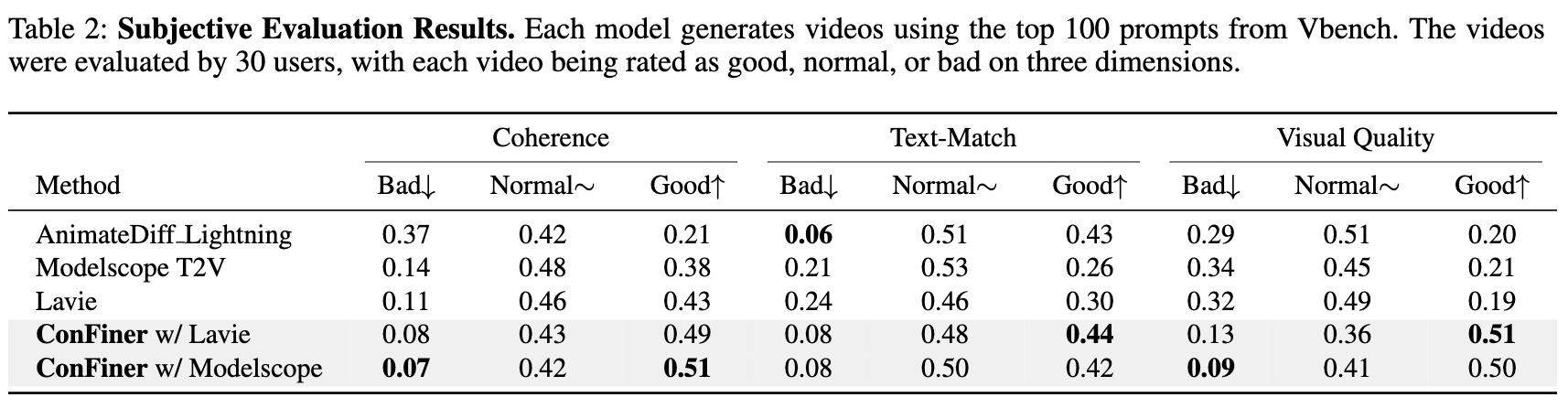
使用 ConFiner 生成了 18 步推理的视频,使用 Vbench 中的前 100 个提示。这些视频与由 AnimateDiff-Lightning、Modelscope T2V 和 Lavie(50 步推理)生成的视频一起,由 30 名用户进行评估。用户在以下三个维度上对每个视频进行了评分:连贯性(coherence)、文本匹配(text-match)和视觉质量(visual quality),每个维度分为三个等级:好(good)、正常(normal)和差(bad)。评分结果展示在下表 2 中。
控制和细化阶段的消融研究
根据公式(6),在控制阶段对生成的视频应用了步噪声,以创建细化阶段的优化空间。较大的值增加了细化阶段的影响。我们将设置为 50、100、200、300 和 500,与客观实验中的其他实验设置一致。性能比较结果展示在下表5中。
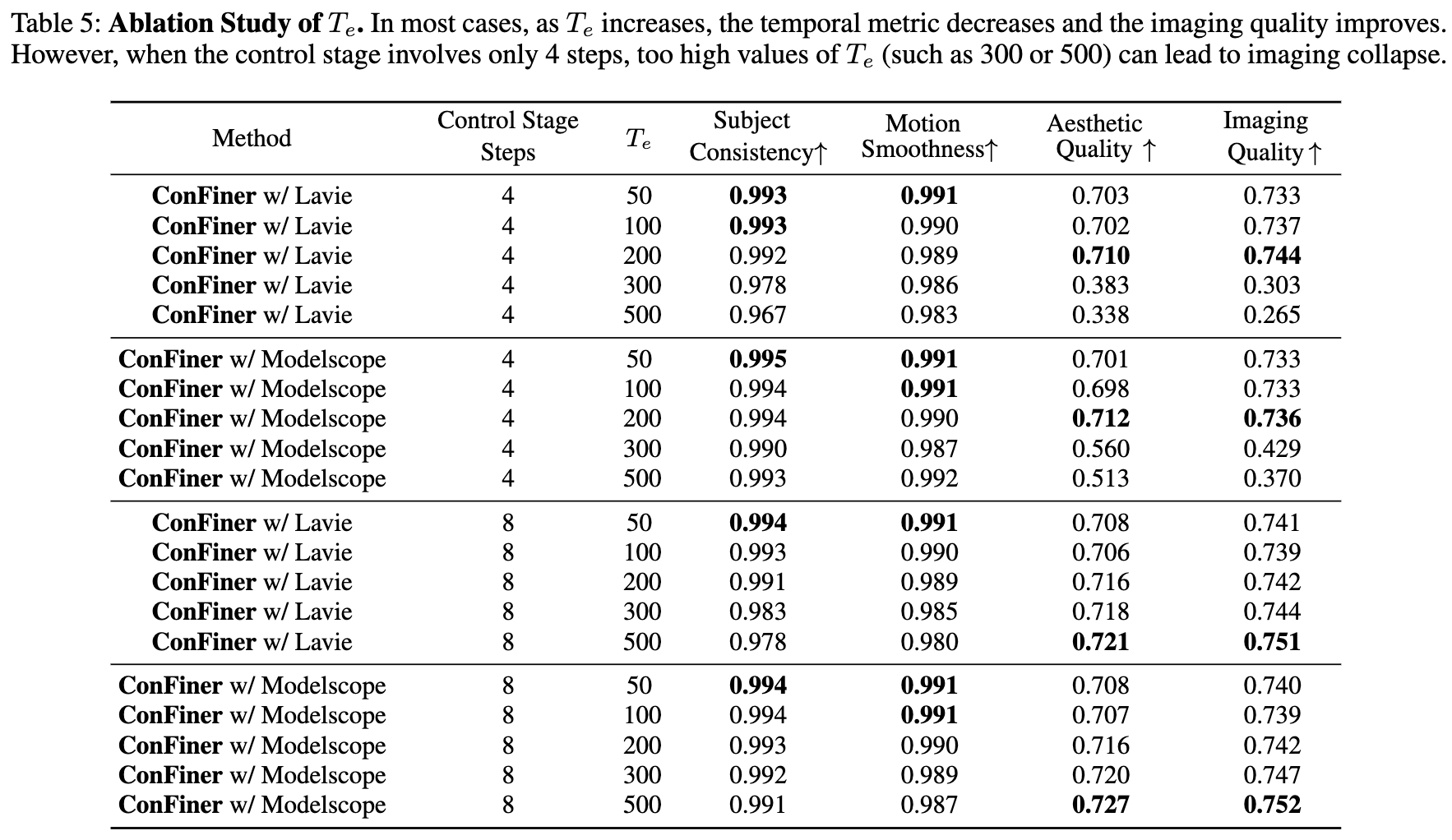
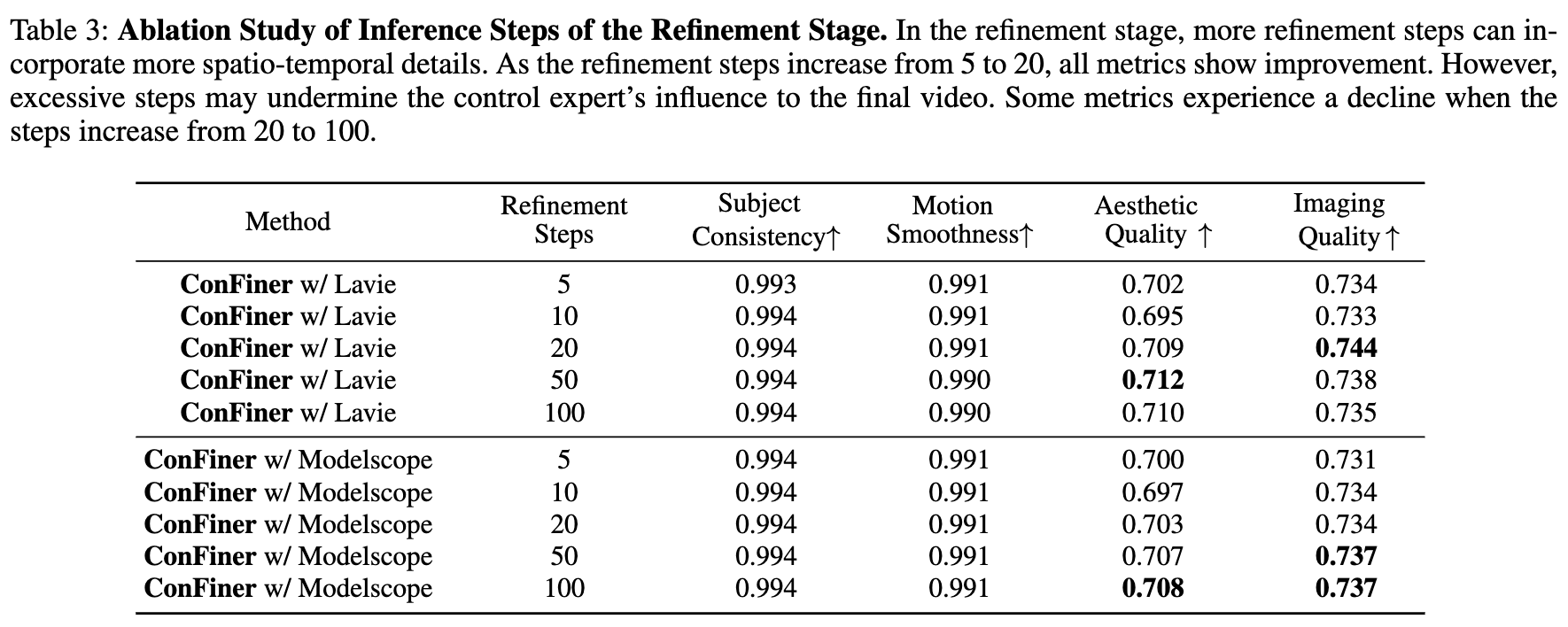
此外,在之前的实验中,当控制阶段使用了 4 步快速采样时,细化阶段始终使用了 5 步推理。为了检查细化步骤数量的影响,同时保持为 100,使用 Modelscope T2V 和 Lavie 作为时间专家,选择了 5、10、20、50 和 100 步的总推理步骤。结果的性能指标展示在下表 3 中。
ConFiner-Long 策略的消融研究
研究者们对 ConFiner-Long 框架中的三种策略进行了消融实验。使用相同的前段视频段生成后续的视频段,比较了使用所有三种策略与仅使用两种策略的结果。四个视频段与前一个视频段的视觉比较结果展示在下图 3 中。

创新性及应用领域
ConFiner这个创新框架,旨在生成高质量的视频,而无需额外的训练过程。ConFiner 将视频生成任务分解为三个核心组件:结构控制、空间细化和时间细化。每个组件由专门的现成扩散专家处理,这些专家在各自领域内具有优势。此外,还提出了一种协调去噪的方法,允许两个专家在去噪过程中进行有效协作。
为了进一步提升生成视频的长度和连贯性,论文中还设计了 ConFiner-Long 框架,该框架能够生成最长达 600 帧的连贯视频。实验结果表明,ConFiner 在提升视频美学和连贯性的同时,显著减少了采样时间。ConFiner-Long 框架的成功应用为电影制作、动画创作和视频编辑等领域开辟了成本效益更高的新可能性。
更多精彩内容,请关注公众号:AI生成未来



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









