










文章链接:https://arxiv.org/pdf/2503.16795
亮点直击
精确语义定位策略,用于在源图像中进行准确的语义定位;
插拔式双层控制机制,通过语义定位增强编辑效果;
RW-800,一个用于评估基于扩散 transformer 的编辑方法的挑战性基准。
在广泛使用的PIE-Bench和RW-800基准上评估了DCEdit。评估结果表明,与以往的方法相比,DCEdit在背景保留和编辑性能方面具有优越性。

效果展示



在PIE-Bench上与基于UNet的扩散方法和基于DiT的方法进行的定性对比
总结速览
解决的问题
文本引导图像编辑任务面临的关键挑战是精确定位和编辑目标语义,而以往的方法在这方面存在不足。
提出的方案
本文提出了一种新颖的方法,通过基于扩散模型的文本引导图像编辑进行改进。具体包括:
-
引入精确语义定位策略,通过视觉和文本自注意力增强交叉注意力图,以提高编辑性能。
-
提出双层控制机制,在特征层和隐空间层同时融入区域线索,以提供更精确的编辑控制。
应用的技术
-
精确语义定位策略
-
双层控制机制
-
基于扩散模型的文本引导图像编辑
-
RW-800基准的构建,用于评估编辑方法
达到的效果
在流行的PIE-Bench和RW-800基准上的实验结果表明,所提出的方法在背景保留和编辑性能方面表现优越。
方法
给定源图像 和一对文本提示 ,它们描述了源图像和目标图像的内容,目标是生成一幅编辑图像,使其与 提供的描述对齐,同时保持与 的结构和语义一致性。所需的语义编辑由差异词 定义,而其余内容应保持不变。为此,提出了精确语义定位策略,该策略提取并精炼交叉注意力图,以通过本研究的双层控制机制指导编辑图像的采样过程。下文中,首先展示了PSL策略如何使从MM-DiT层提取的交叉注意力图得到精炼。然后,将这些精炼的图作为区域线索融入FLUX模型的特征空间和扩散过程中的隐空间。最后,构建了一个名为RW-800的真实世界基准,并将其与最近的编辑基准进行比较。
精确语义定位
最近的DiTs,如FLUX,完全由最近先进的MM-DiT层构建。FLUX结合了联合文本-图像自注意力,在每个MM-DiT层中对齐多模态信息。此外,FLUX将CLIP文本编码器与T5进行补充,赋予其显著增强的文本理解能力。接下来,介绍如何从MM-DiT中提取文本到图像的交叉注意力特征图。
MM-DiT层采用联合注意力机制来整合文本和视觉信息。首先,文本 embedding 和视觉 embedding 被投影到一个共享空间中:
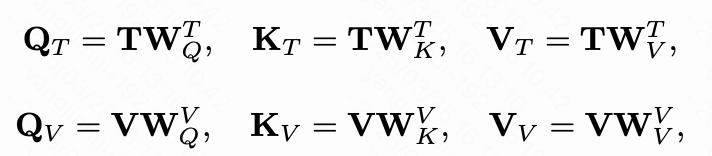
其中 和 是投影矩阵, 是共享维度。之后,通过结合来自两种模态的查询和键来计算联合注意力得分 :
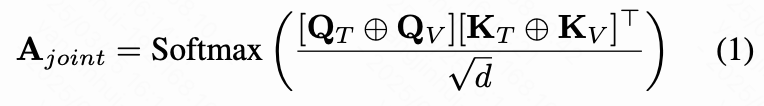
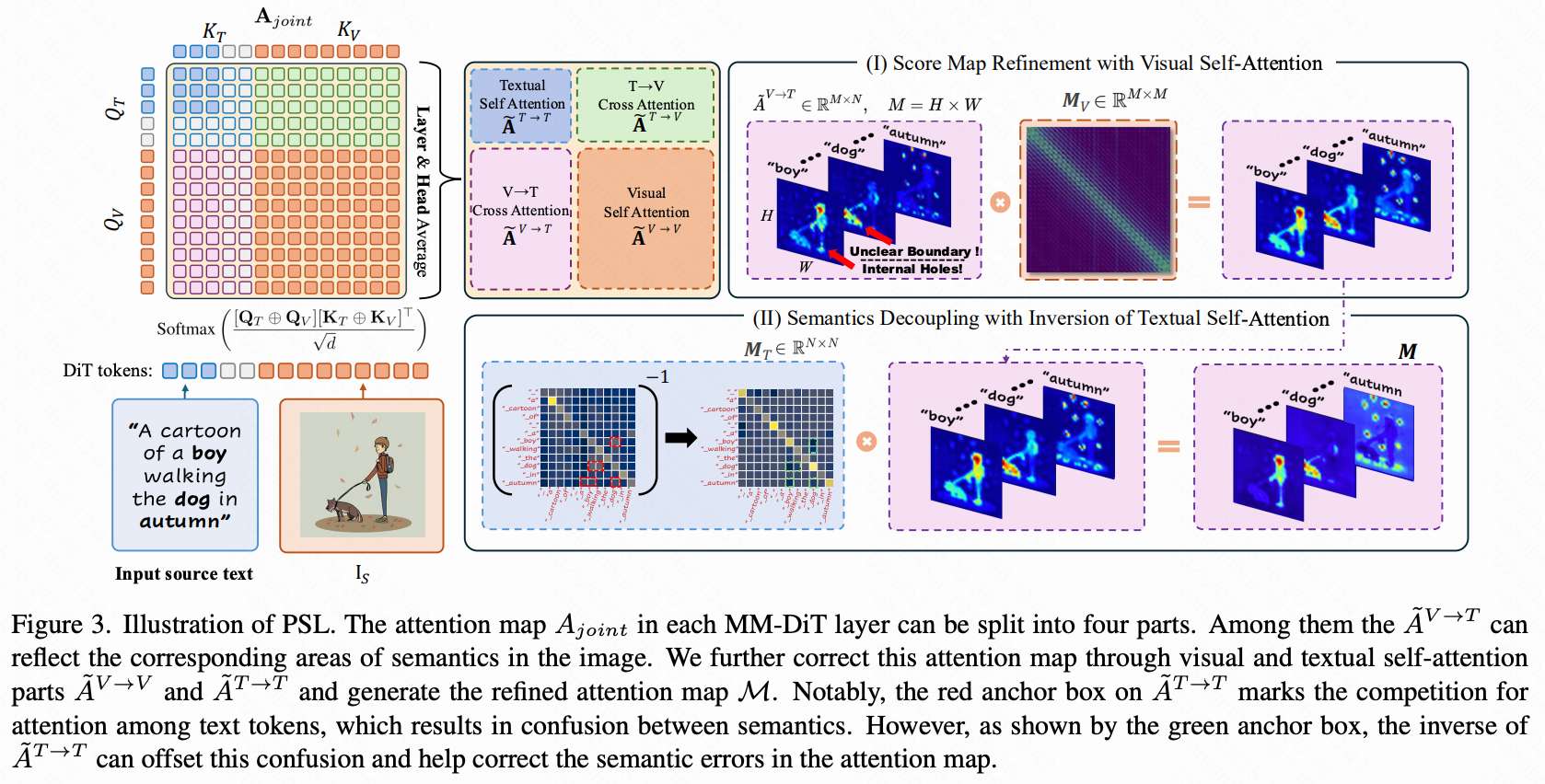
其中 表示文本和视觉 embedding 的逐 token 级连接。如下图 3 所示, 可以分为四个部分,即文本自注意力、 交叉注意力、 交叉注意力和视觉自注意力图。在这些部分中,本研究主要关注 交叉注意力图(交叉注意力在以下内容中特指这一部分),因为它们最直观地反映了视觉和文本 token 之间的对应关系。
首先融合每一层和每个头以获得交叉注意力得分图 :
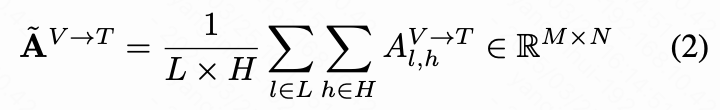
其中 表示 交叉注意力图, 和 分别是 FLUX 模型的总层数和头数。 和 是视觉和文本 token 的数量。然而,如上图 3 所示, 存在两个显著的缺点:(1)激活区域不完整,存在内部空洞且缺乏明显边界。(2)出现语义纠缠,导致错误语义的激活。为了解决这些问题,本研究通过利用来自 的视觉和文本自注意力组件来优化 。本研究将视觉自注意力图融合为:
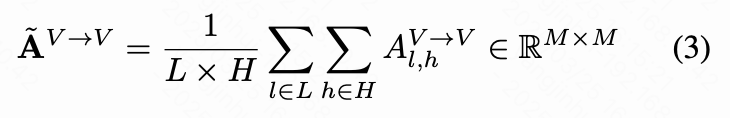
并对其进行重加权以获得一个行随机矩阵 ,该矩阵捕捉了视觉 token 之间的亲和关系[50]。此外,注意到文本自注意力矩阵记录了语义之间的纠缠。这种无关语义的纠缠导致了 中的冗余激活。本研究提出通过利用融合的文本自注意力矩阵 的逆来减轻这种纠缠,其中 是以与 相同的方式获得的。总的来说, 的优化策略可以表示为:
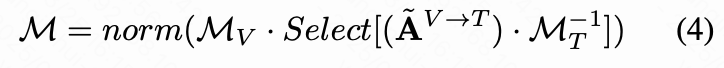
这里的 表示用于提取与特定语义相关的 token 的文本 token 选择操作,而 是一种常规的最小-最大归一化,用于映射缩放。乘以 和 的关键思想在于 隐式反映了文本提示中给出的语义之间的耦合关系,因此采用 的逆来抵消这种纠缠。

图2. 语义定位能力改进。(1) 基于UNet的扩散模型(如SD-1.5和SD-XL)由于架构限制难以捕捉细节语义;(2) 基于MM-DiT的模型(如FLUX)能感知这些语义但存在定位缺陷;(3) 本研究的PSL方法实现了精准的语义定位
双层控制
通过利用 PSL,获得了针对特定语义的优化交叉注意力图 ,该图提供了指示编辑效果应发生位置的区域线索。提出了一种控制机制,称为双层控制(Dual-Level Control),将这些线索融入到 FLUX 模型中的特征和扩散过程中的隐空间变量中,从而实现对编辑过程的细粒度控制。
反演过程。图像编辑需要反演过程以推导出与源图像对应的初始噪声:
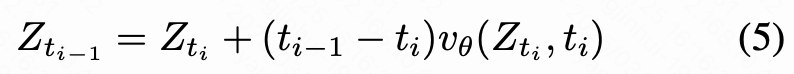
其中 表示噪声隐空间变量,时间步 以长度为 的离散序列给出。 是采样的高斯噪声,而 是源图像 的编码隐空间变量。这里的 表示预训练的 FLUX 模型。PSL 在反演的开始阶段(通常是 )应用,以识别与源图像中替换语义相关的区域。在反演过程中,本研究还存储最后 层中的特征 和用于后续采样过程的中间隐空间变量 。
特征级控制与软融合。 以往的方法在反演过程中从时间步 收集特征,并直接将其替换到采样过程中,以增强编辑结果与源图像之间的一致性,弥补基于反演的重建的局限性。然而,这种方法显著妨碍了编辑效果,因为不加区分的特征替换丢弃了早期目标语义。为了解决这个问题,本研究引入了一种独特的软融合机制,该机制由优化的注意力图 引导:
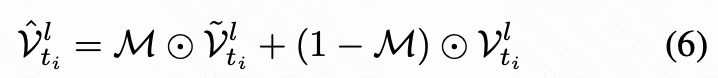
如下图 4 所示, 和 是第 层 MM-DiT 中的投影值。 以头部广播的方式适应通道。该机制在采样过程中选择性地保留由编辑文本激活的特征,有效避免了编辑效果的抑制。
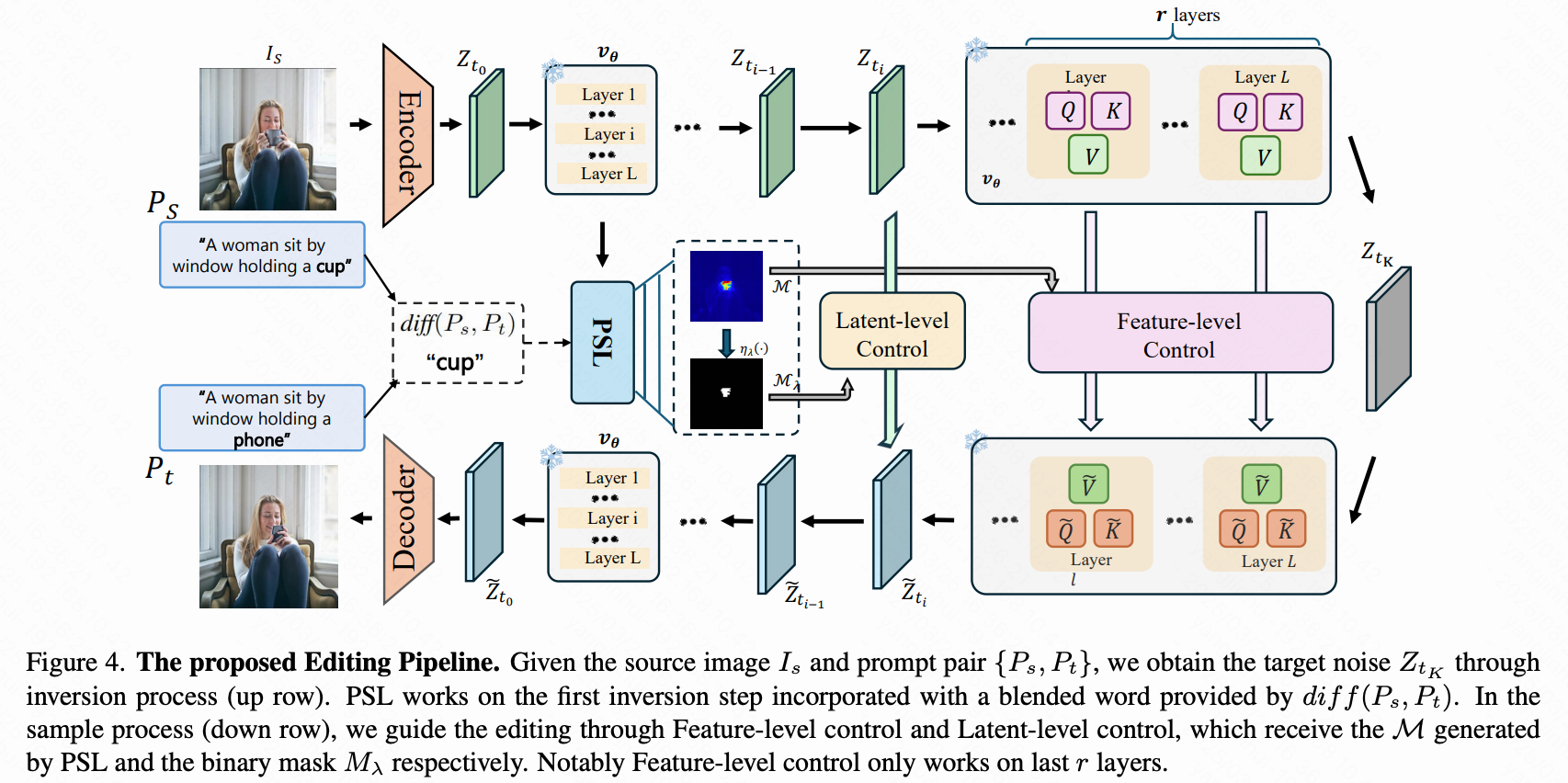
隐空间变量级控制以增强保留效果。 此外,考虑到当前修正流反演方法在重建原始图像方面的局限性,引入了隐空间变量级控制,以进一步提高图像一致性。本研究采用扩散融合方法将反演和采样过程中的隐空间变量进行融合:
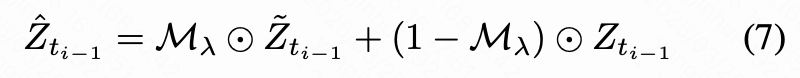
其中 是采样步骤 中的隐空间变量。使用 分位数对 进行二值化:
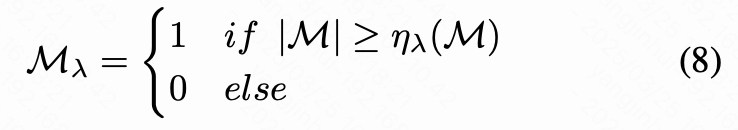
其中 表示 分位数, 是一个预设阈值。此操作旨在防止 中的背景噪声影响 ,从而保持背景区域的一致性。
真实世界图像编辑基准
基准构建。 受到 PIE Bench 的启发,开发了一种新基准,专门用于评估基于 DiT 的图像编辑方法。为了构建一个全面的评估框架,本研究首先从可用来源中整理了一组高分辨率的真实世界图像,确保数据集多样且复杂,适合测试 DiT。然后,本研究采用一种先进的视觉-语言模型 [16] 生成详细的源提示 ,这些提示经过人工注释者的修正,以纠正错误,随后由一个开源的 LLM 处理,去除冗余描述,仅保留客观的视觉细节。为了创建目标提示 ,从 中抽取关键语义词,并用预定义语义库中的相应术语替换,DeepSeek-V3 确保语言的流畅性和连贯性。为了进行定量评估,为每对提示 (, ) 生成精确的掩膜,其中差异内容 首先使用 Grounded-SAM 处理以获得初始掩膜,随后通过交互式分割管道进行精细化。这种结构化的方法确保了高质量数据的生成,并促进了对基于 DiT 的编辑方法的严格评估。
与现有基准的比较。 如下表 1 所示,本文基准在多个方面超越了现有的图像编辑数据集 [18, 23, 33, 58]。本研究的数据集具有最大的平均图像大小,最大限度地保留视觉信息而不进行裁剪或降采样。本文数据集中的源提示显著更长且更详细,捕捉了图像的全面语义表示。
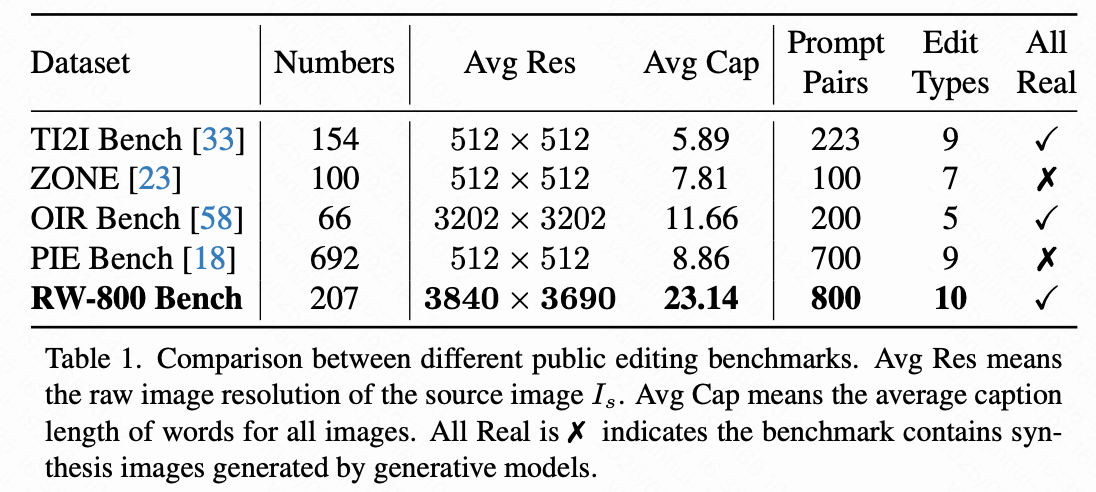
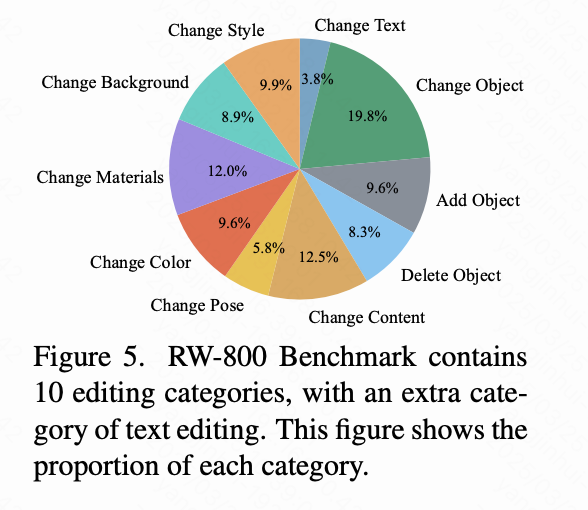
还包含了最多的编辑对,涵盖 10 种不同的编辑类型。这些类型的分布如下图 5 所示。除了 PIE-Bench 中存在的 9 种编辑类型外,引入了一个新的“文本编辑”类别。这个新增类别是由于 DiT 在图像中准确生成和修改文本的能力日益增强,本研究希望通过本研究的 RW-800 进行评估。
实验
在下文中,首先评估了该方法在广泛使用的编辑基准以及本研究的 RW-800 上的编辑能力。然后,定量比较了 PSL 的语义定位能力与基于 UNet 模型的方法。最后,讨论了编辑pipeline 中各个组件的有效性。
图像编辑的比较
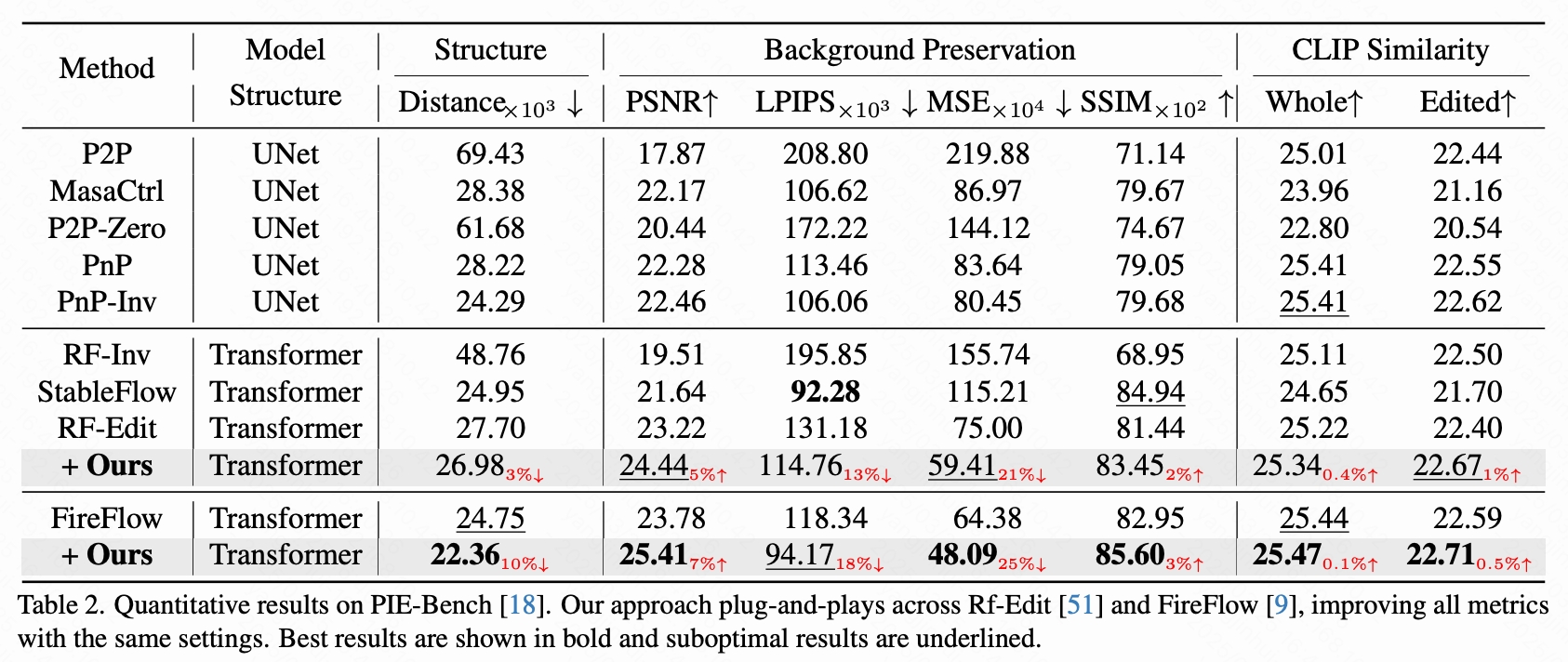
在 PIE-Benchmark 上的定量比较。 为了全面评估本研究提出的方法的性能,本研究首先在广泛采用的 PIE-Bench上进行实验。为了进行比较,本研究选择了一系列基线方法,包括基于扩散 UNet 的经典无训练编辑方法,如 P2P、MasaCtrl、P2P-zero、PnP 和改进的 DDIM 反演方案 PnP-Inv。此外,还将本研究的方法与最新的基于 DiT 的编辑技术进行比较,包括 RF-Inv、Stable Flow 、RF-Edit和 Fireflow。结果如下表 2 所示。值得注意的是,本研究的方法在 RF-Edit 和 Fireflow 上以即插即用的方式运行,同时增强了背景一致性和编辑质量,而没有引入额外的计算开销。这证明了本研究的方法在改善现有最先进框架方面的多功能性和效率。
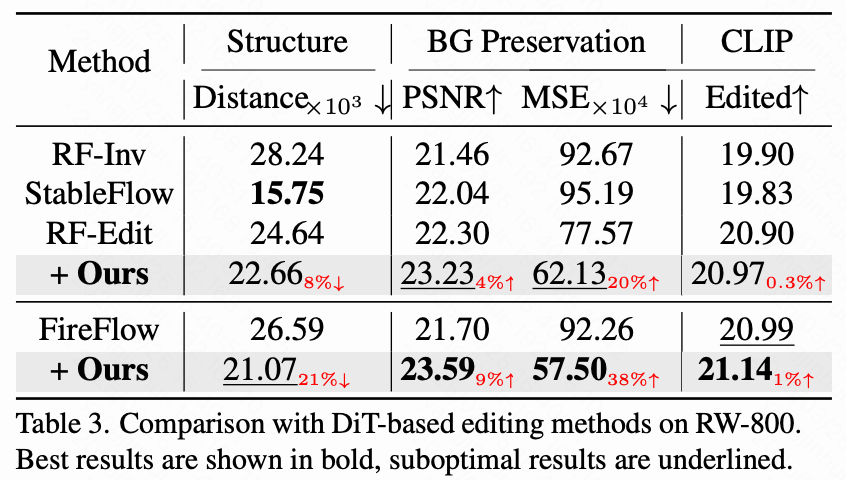
在 RW-800 基准上的定量比较。 为了进一步验证本研究方法的鲁棒性和泛化能力,本研究在具有挑战性的 RW-800 基准上进行了广泛评估,并将其与最先进的基于 DiT 的编辑方法 [3, 9, 41, 51] 进行比较。实验结果表明,本研究的方法显著增强了 RF-Edit 和 Fireflow 的性能。具体而言,在下表 3 中,本研究的方法在结构相似性 [48] 上取得了显著改善,分别将 RF-Edit 和 Fireflow 的背景均方误差(MSE)降低了 20% 和 38%。此外,它同时增强了目标区域的可编辑性,在多个评估指标上保持了平衡的改进。Stable Flow 通过在关键层中注入注意力实现了与原始图像的内容保留,从而相比源图像获得了更接近的结构距离和更好的 SSIM 分数。然而,即使在有限的关键层数下,这种强控制机制显著妨碍了其编辑能力,反映在较低的 CLIP 分数上。
定性比较。 在 RW-800 基准上与其他基于 DiT 的编辑方法进行了定性比较。如下图 6 所示,RF-inv 的编辑会对原始图像带来较大差异,而 Stable Flow 的编辑效果不明显。本研究的方法比 RF-Edit 和 Fireflow 具有更明显的编辑效果,并在背景区域保持了原始图像。

语义定位评估
设置。 为了评估 PSL 的语义定位能力,在两个编辑基准上进行实验:PIE-Bench和 RW-800 基准。这两个基准提供了配对的图像-文本数据以及手动标注的编辑区域 mask ,使得对背景保留和前景编辑性能的全面评估成为可能。利用这些 mask,本研究通过计算注意力图与真实 mask 之间的均方误差(MSE),以及对这些注意力图进行二值化后的交并比(IoU)分数,定量分析模型的性能。
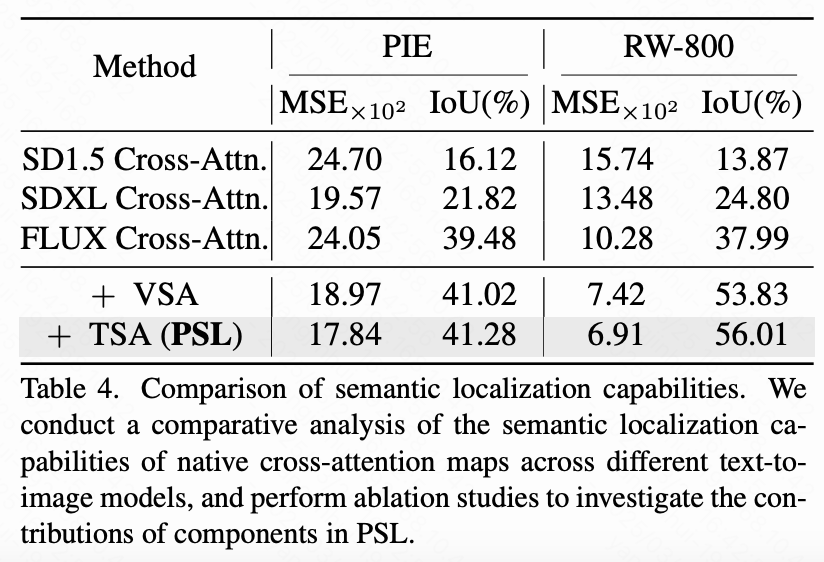
在编辑基准上的定量比较。 作为比较,选择基于扩散 UNet 的文本到图像的扩散模型作为基线,包括 SD-1.5 和 SD-XL ,这两者都允许从其交叉注意力层中提取注意力图。此外,系统地比较了直接利用 Flux 的联合自注意力机制 与本研究结合视觉自注意力和文本自注意力部分的改进的性能。下表 4 的第 1 行至第 3 行显示,基于 MM-DiT 架构的 FLUX 在语义定位方面显著优于基于 UNet 的 SD-1.5 和 SD-XL,获得了明显更高的交并比(IoU)分数。这一改进突显了 FLUX 在将语义信息与视觉内容对齐方面的卓越能力。此外,将视觉自注意力和文本自注意力组件集成到 FLUX 的交叉注意力机制中,显著提高了定位准确性。这些结果强调了本研究提出的架构修改在实现精确和稳健的语义定位方面的有效性,这对于高质量的图像编辑任务至关重要。
消融研究与分析
消融研究以评估各种组件对模型编辑性能的影响,使用真实图像。所有实验均在 RW-800 基准上进行,基于 8 步 Fireflow 方法。如下表 5 的第 1 行至第 3 行所示,在仅进行特征级控制的情况下,本研究测试了使用 PSL 的二值 mask 来引导模型,这可以改善编辑,但也可能增加结构距离,可能是由于分割不准确造成的。使用基准的真实 mask 并未带来显著改善。相反,采用得分图 进行控制则减少了结构距离,同时保持了较高的编辑能力。此改进归因于二值 mask 的局限性,在混合过程中破坏了特征表示,导致偏差。使用 的软融合方法保留了特征完整性,确保了一致和高质量的编辑。此外,与二值 mask 相比,连续图提供了更丰富的信息和更精确的编辑过程指导。
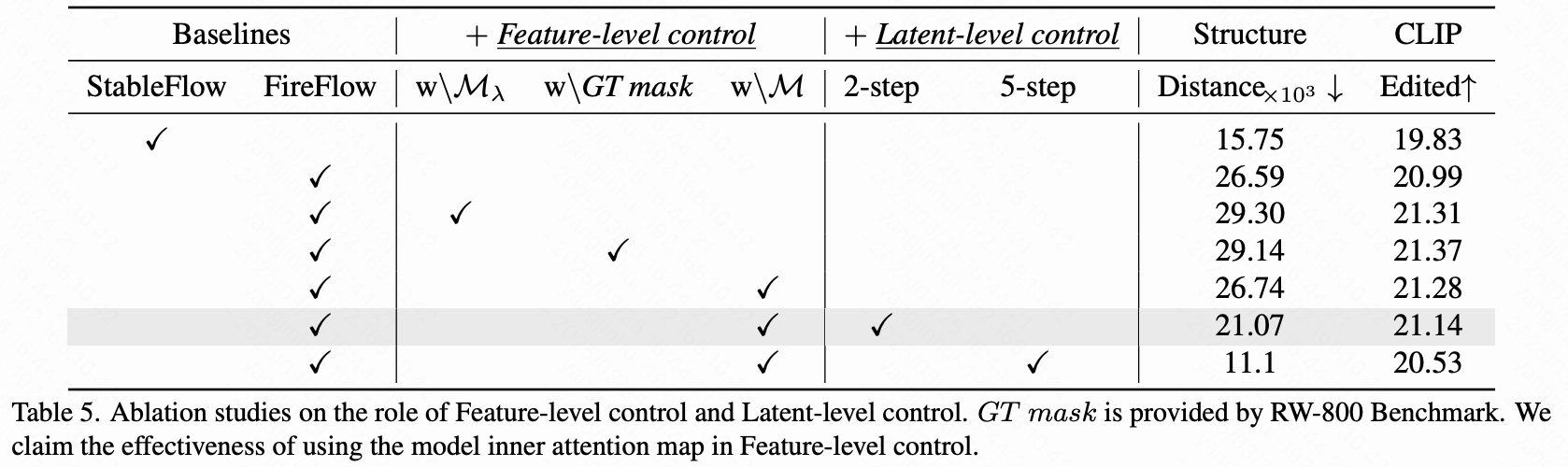
然后,进一步将隐空间级控制机制集成到框架中。如第 4 行至第 5 行所示,在前两个采样步骤中应用二值化 mask 进行隐空间混合,通过绕过早期去噪阶段来保留背景信息。该机制显著提高了编辑图像与原始图像之间的一致性,且对可编辑性的损失最小。将控制扩展到更多采样步骤进一步增强了一致性。当应用于 5 步时,方法实现了比 StableFlow 更低的结构距离,同时在 CLIP 分数上超越了近 4%。这些结果突显了隐空间级控制策略在平衡编辑质量和图像一致性方面的有效性。


PSL模块的消融实验定性对比。通过优化视觉自注意力(VSA)与文本自注意力(TSA)机制,PSL显著提升了FLUX模型中MM-DiT层生成的原始交叉注意力图质量。左列混合词汇激活了对应的注意力图(VSA代表视觉自注意力,TSA代表文本自注意力)。所有展示案例均来自我们的RW-800数据集。
结论
本文介绍了一种新颖的DCEdit,旨在进行文本引导的图像编辑。通过提出的精确语义定位策略,本研究增强了提取的交叉注意力图的质量,使其成为精确的区域线索,以辅助图像编辑。本研究的双级控制机制有效地在特征和隐空间级别上整合了区域线索,提升了基于 DiT 的编辑方法的性能。此外,RW-800 基准的构建提供了一个全面的评估工具,挑战现有方法,并突显了本研究方法在实际场景中的优越性。本研究的结果在背景保留和编辑质量方面相比于以前的方法有了大幅提升,使得 DCEdit 成为文本到图像编辑未来的有希望的解决方案。
参考资料
[1] DCEdit: Dual-Level Controlled Image Editing via Precisely Localized Semantics


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









