






点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

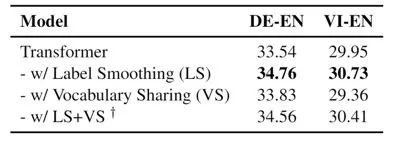
标签平滑和词汇共享是神经机器翻译模型中两种广泛使用的技术。然而,我们认为简单地应用这两种技术可能会产生冲突,甚至会导致次优性能。原因在于分配平滑概率时,原始的标签平滑策略将永远不会出现在目标语言中的源端词与真正的目标端词同等对待,这可能会使翻译模型产生偏差。
为了解决这个问题,我们提出了掩码标签平滑(MLS),一种将源端单词的软标签概率屏蔽为零的新机制。简单而有效,MLS 设法将标签平滑与词汇共享更好地结合起来。我们广泛的实验表明,MLS 在不同数据集上,从BLEU,chrF,模型校准等多个角度均相比原始标签平滑有显著的提升。
本期AI TIME PhD直播间,我们邀请到北京大学计算机学院计算语言所实习生——陈亮,为我们带来报告分享《基于掩码标签平滑的机器翻译模型训练方法》。

陈亮:
吉林大学本科生,北京大学计算机学院计算语言所准研究生,主要研究方向为语义分析,机器翻译,本工作为在计算语言所实习所作。
动机
●标签平滑(label smoothing)和词汇共享(vocabulary sharing)是神经机器翻译模型中广泛使用的两个技术
● 我们发现二者同时使用时会造成性能下降,导致不如单独使用某一技术,根据我们的分析,二者之间存在冲突
● 我们提出了一个简单有效的方法,掩码标签平滑,可以克服二者的冲突,将词汇信息引入标签平滑中,提升机器翻译的性能
标签平滑和词汇共享
● 标签平滑在MT模型训练过程中使用平滑的软标签代替硬标签,将部分目标概率(α)均匀地分配给不正确的标记。它被形式化为:
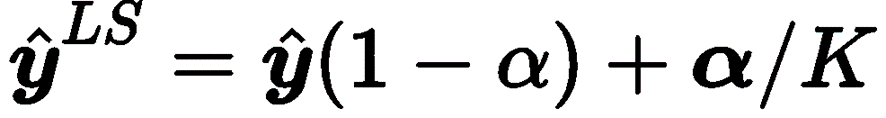
这个技术可以极大缓解模型的过拟合问题。
● 词汇共享为训练语料库中的所有语言建立了一个共同的词汇,将它们视为一种语言。它增强了语言之间的语义相关性,并能够对编码器和解码器的embedding进行权重绑定,从而使模型尺寸更小。
机器翻译中标签平滑和词汇共享冲突
● 我们可以使用维恩图来表示语言和语言之间词汇的关系,同时可视化Token之间的关系,如下所示。S、C、T分别代表每个方向上的源词汇、共享词汇和目标词汇。
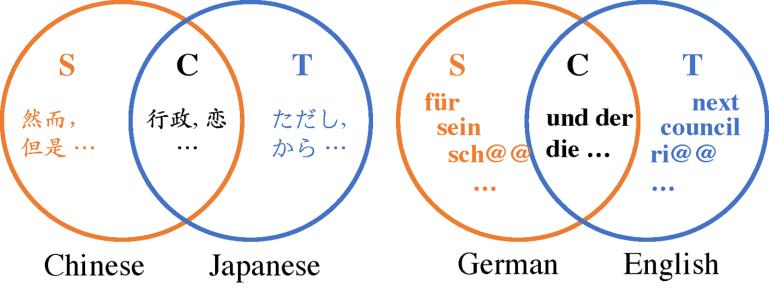
比如,我们在进行机器翻译的时候对词语进行再切分,部分的子词属于共享,部分子词属于源端或目标词汇。
● 当标签平滑尝试将平滑概率分配给从未出现在目标语言中的标记时,会发生冲突。这将误导模型并解释性能退化。
比如,我们在做中文到日语的翻译任务时,在做标签平滑的过程中会将部分概率分配给“然而”、“但是”这些不太可能在日语中出现的词。
机器翻译中标签平滑和词汇共享的冲突
下面我们又对语言之间词汇的关系做出了进一步的分析。
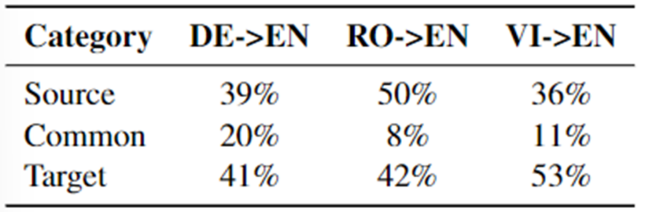
● 我们计算了标记在不同翻译方向上的词汇分布,如下所示。Source类中的token可能占很大比例,最高可达50%。
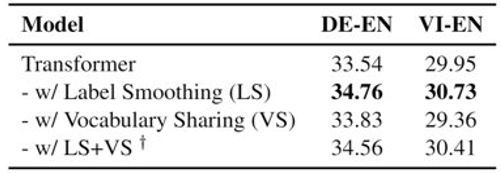
● 同时使用LS和VS可能会导致性能下降。
为了解决上述问题,我们提出了以下方法。
加权标签平滑 (Weighted Label Smoothing)
原始的标签平滑,采取的是均匀的分布来进行概率的分配。而我们提出的这种方法——加权标签平滑具有以下特性:
● 不使用统一的标签平滑。
● WLS采用三个附加参数来重新分配平滑概率。
● 三个参数的比率表示分配给目标类词汇、公共类词汇和源类词汇的平滑概率的比例,并且三个参数的和为1。
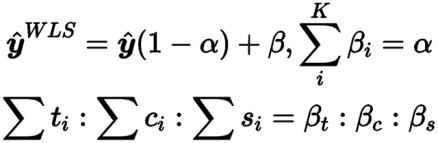
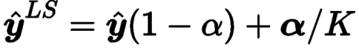
原始标签平滑
掩码标签平滑(Masked Label Smoothing)
之前的加权标签平滑提出了3个参数,我们在此基础之上思考能否采取更简洁的方法达到我们的目的。
● 通过将零概率分配给源端词汇,并将目标和共享词汇视为一个类别,我们现在有了MLS,这是WLS(加权标签平滑)的一个无参数版本。它隐式地向模型注入外部语言知识。
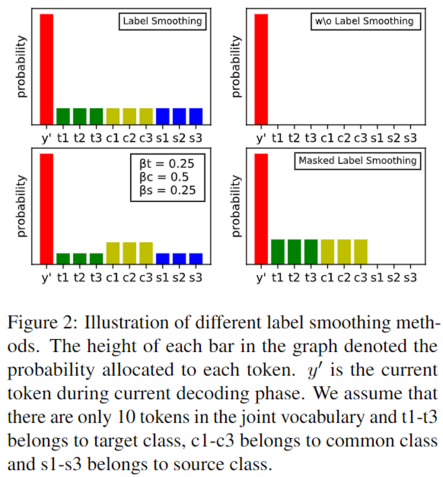
该方法可以帮助我们有效甄别哪些词汇来自源端,哪些词汇来自目标端。
如上图,我们可以看到在标签平滑、加权标签平滑、掩码标签平滑几种情况下的效果对比。
实验
● 我们在7个双语翻译任务上进行了实验。我们选择具有不同共同子词比例的语言对,如德语和英语。其中包括de-en,vi-en,ro-en,zh-en。
● 同时进行了多语言翻译任务ro,de->en
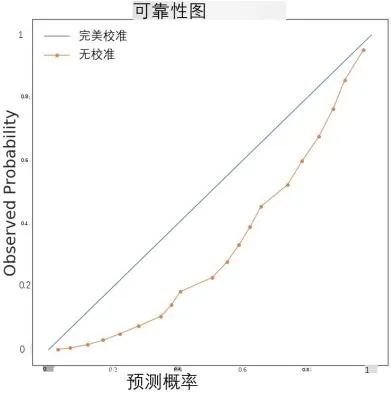
● 通过BLEU、chrF和模型校准(ECE评分)进行评估
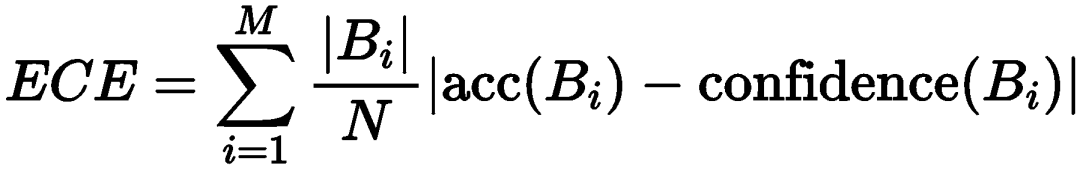
Kumar, Aviral, and Sunita Sarawagi. "Calibration of encoder decoder models for neural machine translation." arXiv preprint arXiv:1903.00802 (2019).
模型校准这个方法主要是在降低模型过拟合上发挥作用,使得模型在输出的时候不会过于自信,也不会过于不自信。
比较直观的认识就是,ECE评分体现了模型输出的可靠性。
实验结果(双语和多语)
在BLEU,chrF评分上,在不同的标签平滑α下,MLS在不同的MT方向上比原始的LS+VS有显著的改善。

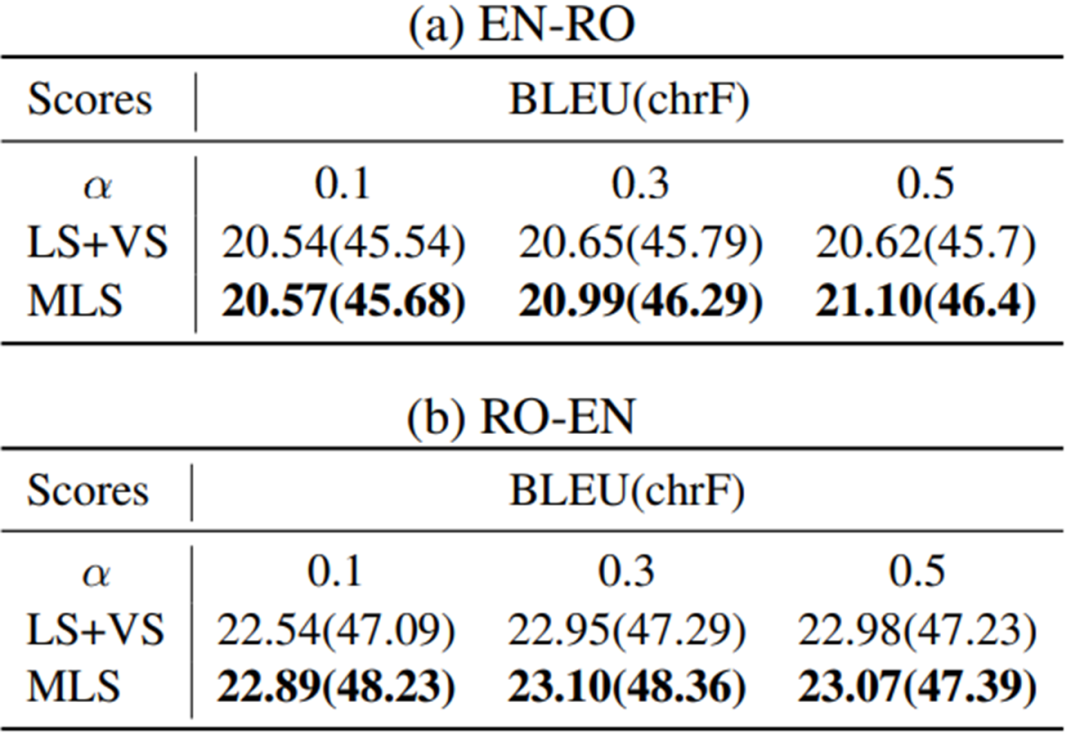
我们也对α这个值进行了进一步探究,看在不同的标签平滑概率下是否会相对之前有更高的效率提升。在进行标签平滑的过程中,不仅目标词汇中的概率增加,而且不同语言中的概率分配也很重要。
模型校准与模型困惑度
● 更少的ECE意味着更好的模型校准,这意味着模型既不会对输出过于自信,也不会过于不自信。
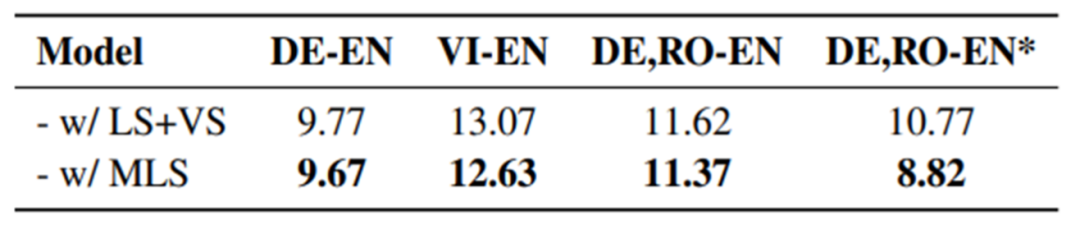
上表是我们将我们的方法和baseline方法的ECE评分进行了对比。我们可以发现掩码标签平滑MLS在不同方向上都降低了ECE分数。
● 在所有实验中,在训练的早期阶段,MLS有比LS低得多的困惑度。
● 这可能是模型更好的翻译性能的另一个原因,因为它提供了更好的训练初始化。
结论和未来展望
● 考虑到源语言和目标语言之间的词汇差异,我们提出了一种简单有效的标签平滑方法。
● 更好地将标签平滑与词汇共享相结合,提高了机器翻译的性能。
未来,我们主要做的是从词汇和语言的角度克服多语言机器翻译中语言之间的平衡问题。
提
醒
论文题目:
Focus on the Target's Vocabulary: Masked Label Smoothing for Machine Translation
论文链接:
https://arxiv.org/abs/2203.02889
点击“阅读原文”,即可观看本场回放
整理:林 则
作者:陈 亮
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了600多位海内外讲者,举办了逾300场活动,超210万人次观看。

我知道你
在看
哦
~

点击 阅读原文 查看回放!
















 53
53











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









