






点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
本文介绍的是一篇收录于 CVPR 2024 的论文。为了解决某个机构或边缘设备上数据缺乏的问题,一方面我们通过联邦学习获得来自所有参与设备的任务相关的共享知识;另一方面我们将该共享知识作为预训练生成模型(如 Stable Diffusion)的输入来生成任务相关的全局数据;最后我们将生成的数据传输到机构或边缘设备上并通过额外的有监督学习任务,将该全局数据注入到边缘模型中。
我们称这一过程为“知识迁移链路(KTL)”,并在每一轮联邦学习过程中进行一次知识迁移。此过程中生成模型只作推理不做训练,这种利用预训练模型的方式对资源的需求较少。

论文标题:
An Upload-Efficient Scheme for Transferring Knowledge From a Server-Side Pre-trained Generator to Clients in Heterogeneous Federated Learning
论文链接:
https://arxiv.org/abs/2403.15760
代码链接:
https://github.com/TsingZ0/FedKTL(含有PPT和Poster)
运行实验所需仓库-个性化联邦学习算法库:
https://github.com/TsingZ0/PFLlib
运行实验所需仓库-异构联邦学习算法库:
https://github.com/TsingZ0/HtFLlib

动机
随着新一轮 AI 时代的到来,模型的量级越来越大,对数据的需求也越来越大。不论是哪个领域,有效且高质量的数据一直是一种稀缺存在,甚至成为了一种数据资产。与此同时,互联网上也广泛存在着能力强劲的开源生成模型。如果能够利用这些生成模型中存储的知识,来生成具体任务所需的数据,便可以让小公司和边缘智能设备都能享受到大模型带来的丰富成果。
为了解决数据稀缺问题,有以下四种常见途径:
1. 利用来自公开数据集的数据,但这类数据很难做到与具体任务相关,且任务无关数据甚至会产生负面影响;
2. 由数据请求方上传数据生成需求(比如分类任务中的标签语义)到云端的生成模型来生成数据,但这种文本很容易导致隐私问题;
3. 利用云端大模型随机生成无标签数据,但这样做依旧存在与利用公开数据集同样的问题,甚至无标签数据的引入增加了模型训练的难度;
4. 利用预训练模型引入额外知识,但适用于具体任务的预训练模型稀少且其中的额外知识不一定匹配当前任务。
换言之,不管是引入额外数据还是引入额外知识,都尽量需要与当前任务相关,才能最大限度地起到正面作用。
考虑到联邦学习技术可以将需要实现相似任务的设备或机构联合起来,实现知识迁移和共享;我们便将任务相关知识的获取通过联邦学习实现。考虑到传统联邦在模型架构上的局限性,我们引入异构联邦学习技术,允许各个参与方采用不同架构的模型。
之后,我们将该任务相关知识作为输入,传递给预训练生成模型,并针对当前任务做了域对齐,从而生成任务相关的数据。为了有效利用该数据,我们将其传输到联邦学习参与方后,运行一个额外的有监督任务实现知识迁移。

异构联邦学习技术
传统联邦学习考虑了数据异质性,但依旧要求所有参与方训练同一个架构的模型,增加了寻找相似任务参与方的难度。于是我们考虑取消这一点要求,允许参与方采用各自的模型进行知识共享。然而,这样一来,传统联邦学习中基于模型参数共享的范式不再可用,对新型的知识共享机制提出了要求。其中包括:1)保护隐私,2)保护知识产权,3)轻量化,4)易于获得等。
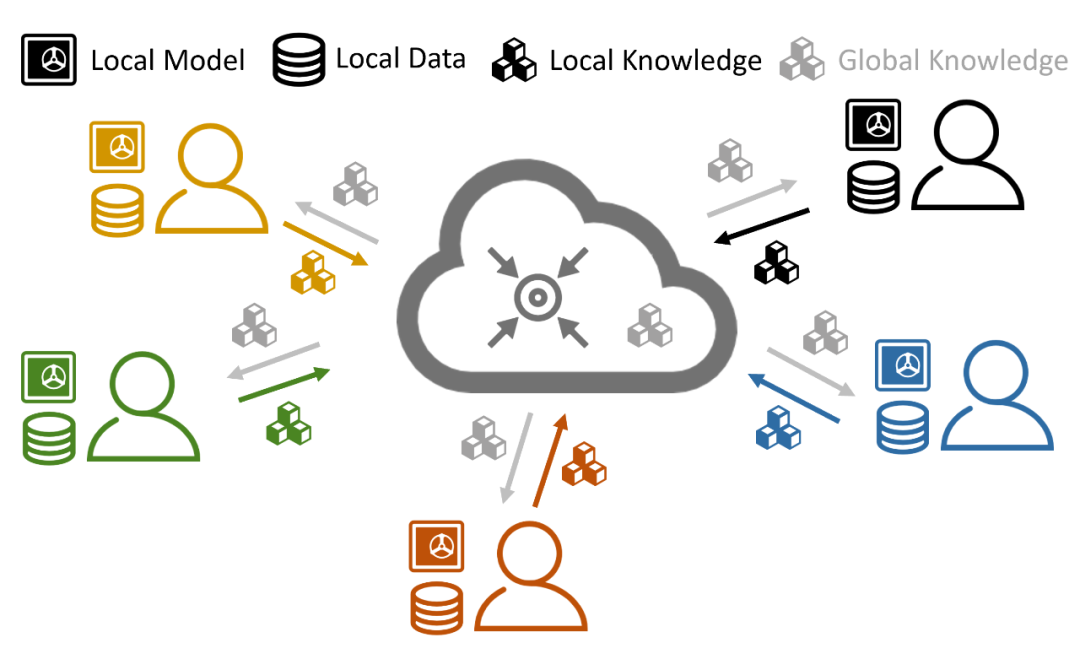
▲ 图1:异构联邦学习技术
目前异构联邦学习技术还未形成统一的知识共享机制,我们考虑一种轻量化且不需要额外数据的知识共享机制:共享 prototype。本文考虑的是面向图像的多分类任务,其 prototype 的定义就是每个类别的代表性特征向量,可通过平均该类所有的特征向量获得。我们将 prototype 当作共享知识,输入到生成模型后得到相应图片数据,并将图片-向量对(image-vector pairs)传回参与者,如下图。
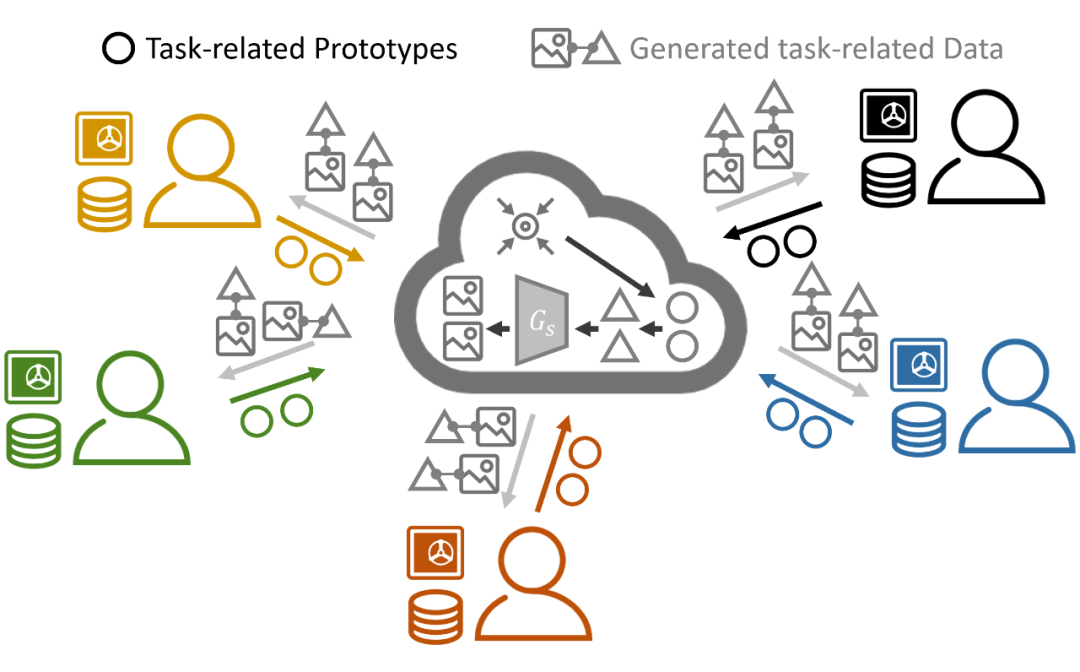
▲ 图2:异构联邦学习中使用prototype进行知识迁移

知识迁移链路(KTL)
上一节的最后已经简单描述了我们提出的知识迁移链路(KTL),但省略了很多细节,这里我们对重点步骤进行展开(其他步骤及细节详见论文)。下图是我们的整体框架,其中最重要的是步骤 3 和步骤 6。
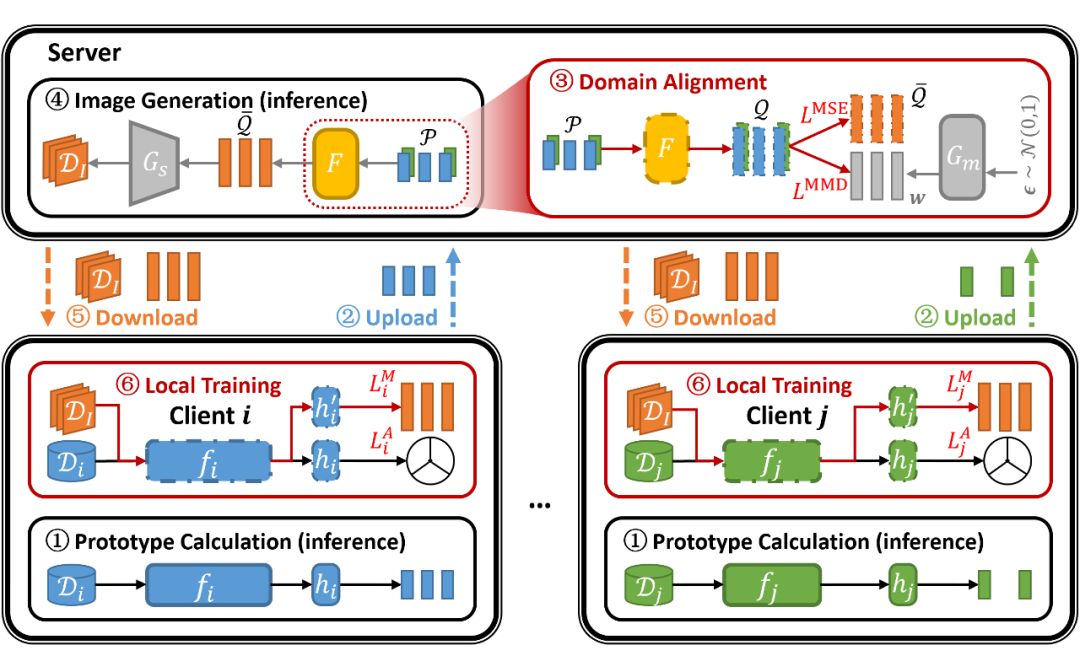
▲ 图3:Federated Knowledge-Transfer-Loop (FedKTL)
步骤3:当我们在生成模型的特征空间采样时,可以生成清晰图像,但这样的图像并非任务相关。根据我们的实验观察,如果直接将参与方上传的 prototype 输入到预训练生成模型,由于参与方模型的特征空间和生成模型的特征空间不匹配(通常连维度都不一致),导致生成的图像跟随机输入一样模糊不清。
所以我们需要先将 prototype 映射到高维的生成模型特征空间,并保证这些 prototype 依旧是任务相关的。因为我们考虑的是分类问题,任务相关指的就是 prototype 映射后得到的特征向量依旧保持类别可分离特性。我们称这一过程为域对齐(domain alignment),如下图可见,对齐后的特征向量可以使生成模型产生清晰图片。

▲ 图4:生成模型在不同输入下得到的图片
为了实现域对齐,我们在服务器端额外训练了一个轻量化的特征转换器(F),并定义其训练目标为对齐特征空间(使用 MMD 损失)和保证类别可分离性(使用 MSE 损失)。
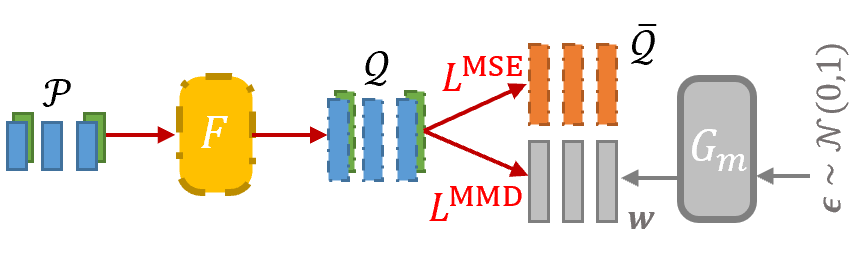
▲ 图5:域对齐实现方案
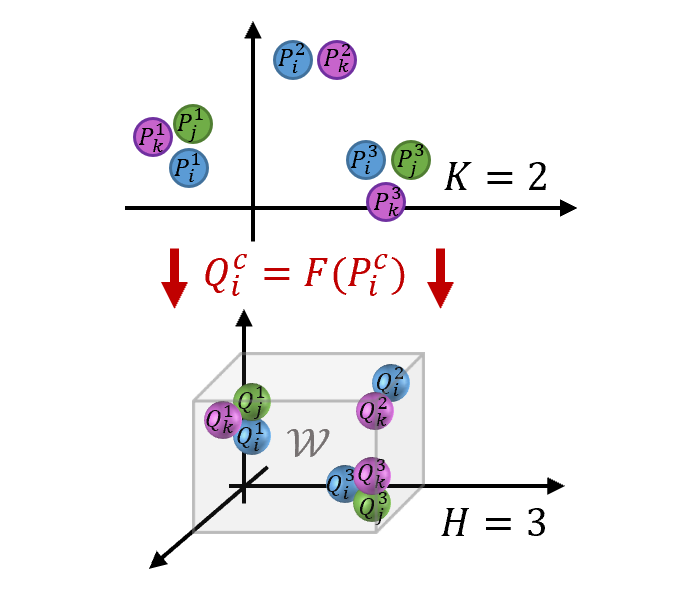
▲ 图6:域对齐的一个例子。这是一个三分类任务,其中参与方模型特征空间维度为 2,生成模型特征空间维度为 3,W 是生成模型的有效特征空间。
步骤6:在进行域对齐后,将映射后的向量输入到生成模型即可得到清晰的图片。我们将图片-向量对下载到各个参与方,而后通过一个额外的有监督任务实现知识迁移。图 3 中的 指的是原本的分类任务目标函数, 则指的是我们提出的额外有监督任务的目标函数。
由于我们只对参与方模型的特征提取器进行知识迁移,而特征提取器需要的正好是特征提取相关的通用知识,且预训练生成模型含有大量通用知识。所以只要是生成模型生成的且由任务相关的 prototype 诱导出的图片,都可以在 KTL 中发挥作用。
进一步地,我们不需要生成模型在特定数据集上进行预训练,在任意图像数据集上预训练的生成模型都可以在我们的框架中发挥作用。我们也通过实验证实了我们方法(FedKTL)的这一个能力。如下图表所示,在四种不同数据集上预训练的生成模型带来的表现几乎是类似的,且这些数据集并不与参与方本地的数据集重合。

▲ 图6:参与方本地数据样本和四种用于生成模型预训练的数据集样本。

▲ 表1:使用在不同预训练数据集上预训练的生成模型的效果。其中是与服务器端数据生成相关的超参数。

部分实验
由于篇幅有限,主体实验请查阅论文。这里仅讨论与我们方法特性相关的实验结果,包括“上传的通讯成本低”、“可扩展到 Stable Diffusion 等不同架构的生成模型模型”、“适用 cloud-edge 框架(不使用联邦学习)”。
上传的通讯成本低:由于我们只上传 prototype,且对特征空间进行了降维(详见论文),我们方法所需的上传通讯成本极低。在现实环境中,上传链路带宽往往比下载链路低好几个数量级。我们方法的这一特性使得它更能适应现实环境,且充分利用上传下载的带宽。
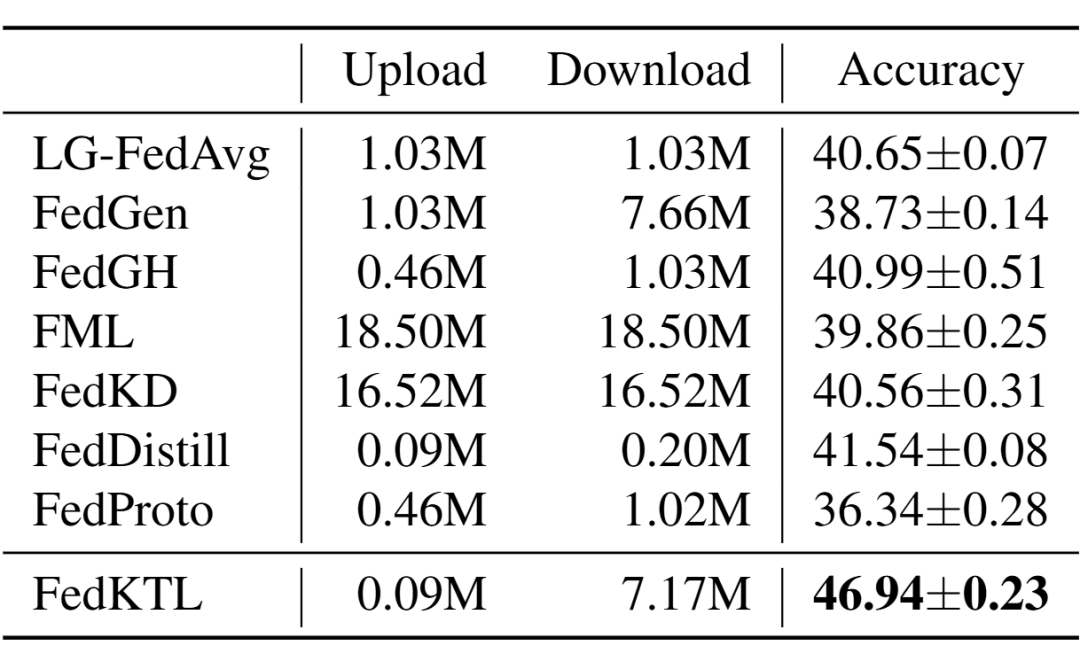
▲ 表2:每轮的通讯成本
可扩展到 Stable Diffusion 等不同架构的生成模型模型:论文展示了我们的知识迁移框架不但可以使用 StyleGAN 等较小的生成模型,也可以在不加修改的情况下使用当下最热门的基于 diffusion 技术的大型生成模型 Stable Diffusion。但由于 Stable Diffusion 的特征空间维度非常高,不加修改直接使用无法完全挖掘其生成能力,如何匹配高维特征空间是未来有待探索的方向。

▲ 表3:使用 StyleGAN 和 Stable Diffusion 的表现
适用 cloud-edge 框架(不使用联邦学习):在我们的知识迁移框架(KTL)中,我们引入了两种外来信息给到参与方,一种是来自其他参与方的任务相关知识(来自联邦学习),另一种是预训练生成模型中存储的知识。
在某些情况下,寻找其他运行相似任务的设备或机构参与到联邦学习中较为困难。这时候我们仅用第二种预训练生成模型中存储的知识,也可以实现知识迁移。而且这种无联邦学习的知识迁移范式,可以依托现有的 cloud-edge 框架实现。如下表,在只有一个参与者的情况下,参与者拥有的数据越少,我们的 KTL 方法效果越好。
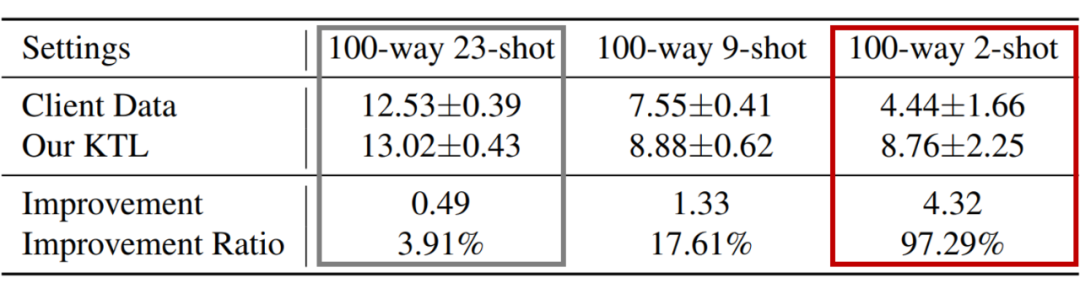
▲ 表4:Cloud-edge 场景(只有一个参与者)下的表现
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1800多位海内外讲者,举办了逾600场活动,超700万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 查看更多!
















 50
50











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









