






点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

讲者简介
黄宇坤:
香港大学IDS 博士后,2023年博士毕业于中国科学技术大学,导师为查正军教授。研究方向包括:3D内容生成、行人重识别,相关研究工作发表在IJCV、NeurIPS、CVPR、ICCV等期刊、会议。
项目主页:
https://idea-research.github.io/DreamWaltz/
GitHub(已开源):
https://github.com/IDEA-Research/DreamWaltz
arXiv链接:
https://arxiv.org/abs/2305.12529
ReadPaper链接:
https://readpaper.com/paper/1795359860282044672
Title
复杂且可驱动的3D数字人生成
DreamWaltz: Make a Scene with Complex 3D Animatable Avatars
Content
前言
该文章提出了一种新的文本到3D数字人生成方法——DreamWaltz,能够在给定文本提示下创建造型复杂并且可驱动的3D数字人。近年来,基于扩散模型和得分蒸馏采样(Score Distillation Sampling,SDS)的优化方法已经在通用3D物体生成上取得了显著的进展,但创建3D数字人仍然面临众多挑战,例如:生成质量不佳、难以驱动复杂角色等等。
为此,DreamWaltz从条件图像生成技术中得到启发,提出一种基于骨架条件的得分蒸馏优化方法,能够提升3D数字人生成质量,并且解决复杂角色的驱动难题。为了改善生成质量,DreamWaltz通过调整骨架条件来提供与渲染图像视角对齐的监督信号,避免了由于视角不一致导致的伪影和多脸问题。对于复杂角色驱动,DreamWaltz从人体姿态先验分布中随机采样骨架条件,使得未绑骨的3D数字人能够在任意姿态引导的图像监督信号中进一步获得关节驱动能力。广泛的实验评估表明,DreamWaltz是一种简洁有效的3D数字人生成方法,能够制作外观复杂、可自由驱动的3D角色,可进一步用于创建包含复杂人物交互的3D场景,例如:双人跳华尔兹舞蹈。
一、背景介绍
文本到3D数字人生成(Text-to-Avatar Generation)是一种跨模态AIGC技术,在游戏、影视、VR/AR、创意设计等领域有望带来生产力变革。用户仅仅需要提供一段文本描述,例如:“小丑装扮的哈利波特”,模型就能自动构建出对应的3D人物形象,如下图所示。

现有的文本到3D数字人生成方法一般基于2D Lifting方法,通过将来自预训练的文本-图像基础模型(如CLIP、Stable Diffusion)的2D图像先验蒸馏到可微分3D表示中,实现3D内容的生成,并且引入人体参数化模型(如SMPL)作为人体先验约束来保证生成质量。
基于扩散模型的文本到图像生成技术推动了3D内容生成领域的发展,包括了3D数字人。一些工作开始。以DreamFusion为代表的系列方法利用文图扩散模型中的2D图像先验作为监督信息优化NeRF、DMTet等3D表示,实现文本驱动的3D物体生成。
二、研究动机
2D Lifting方法只能提供当前渲染图像的监督信号,缺乏对全局3D结构的理解。因此,现有方法引入了人体参数化模型SMPL,直接为3D表示提供几何结构上的约束。给定相同的文本描述“奇异博士”,我们对比了不同文本到3D数字人生成方法的结果,如下图所示。

其中,AvatarCLIP和AvatarCraft方法都采用了较强的SMPL结构约束,因此在几何结构生成上相对稳定且容易驱动,但是会导致过度简化的人物外观(例如,紧身的衣物效果);而DreamAvatar则相反,放松了对SMPL结构约束的依赖,因此能够生成复杂的人物外观,但是通常伴随着严重的伪影,并且生成的复杂衣物也很难直接被现有的关节运动模型驱动。
考虑到上述问题,DreamWaltz从可控图像生成工作ControlNet中得到启发,将人体结构先验以骨架(Skeleton)条件图像的形式注入到扩散模型中,而不是直接约束3D表示。这样做的好处在于:
- 提供更稳定的、视角一致的SDS监督,避免不同相机视角下生成内容冲突造成的伪影和模糊;
- 通过随机采样骨架姿态,增强复杂3D数字人对不同动作驱动的泛化性;
- 采用稀疏的骨架图像作为人体结构先验,最小化对生成形状的限制。
三、方法介绍
DreamWaltz的简化流程图如下所示。首先,我们从建模了人体姿态分布的VPoser模型中随机采样SMPL姿态参数,并通过SMPL模型得到随机姿态下3D人体的mesh表示以及关键点坐标;结合当前的相机视角,可以进一步导出遮挡剔除(Occlusion Culling)后的2D骨架图像。接着,将获得的骨架图像和文本描述一起输入到ControlNet中,得到对应的SDS梯度用于优化可驱动的NeRF表示。
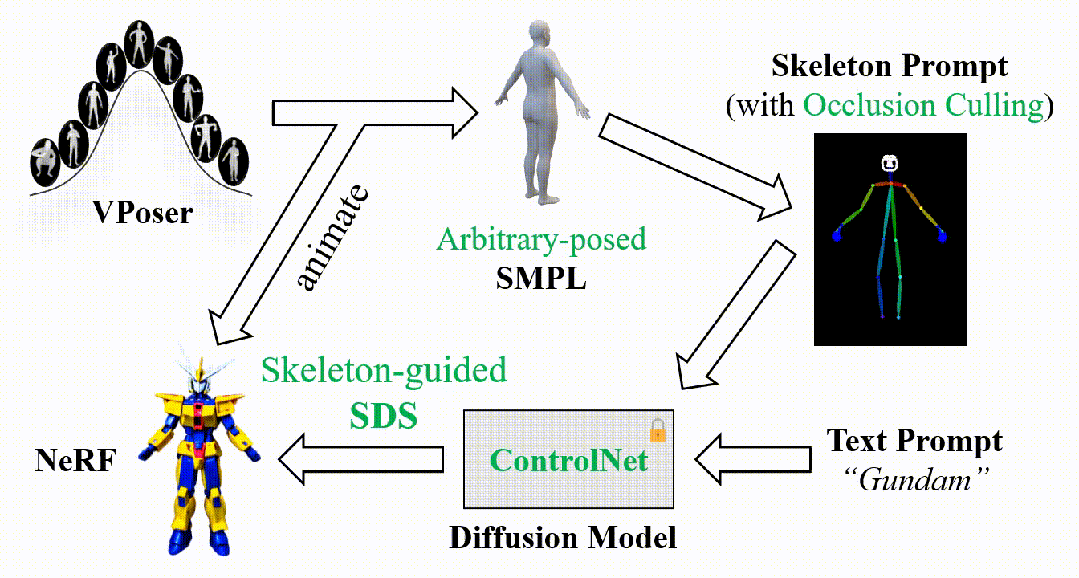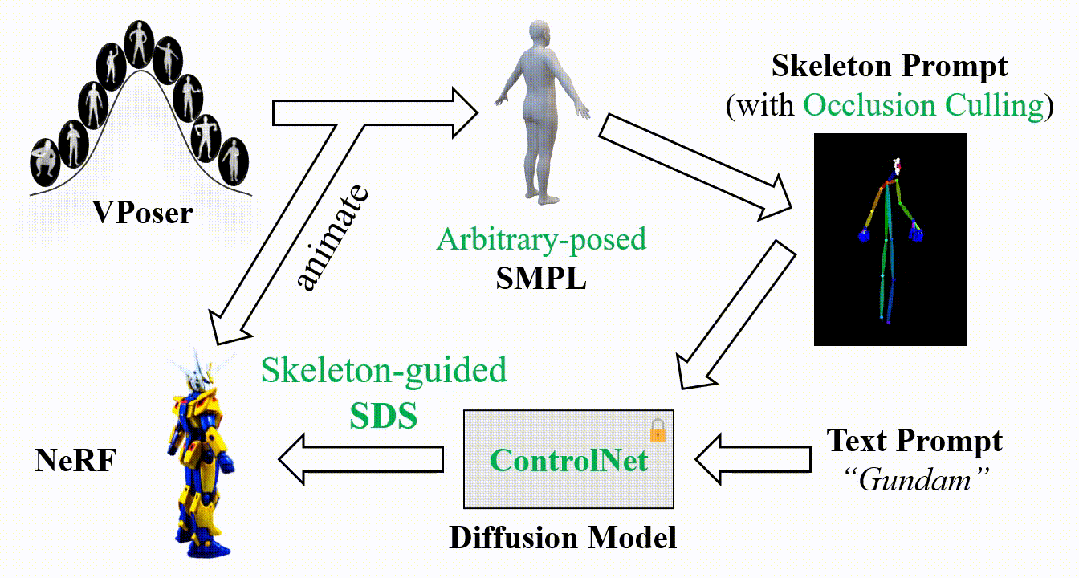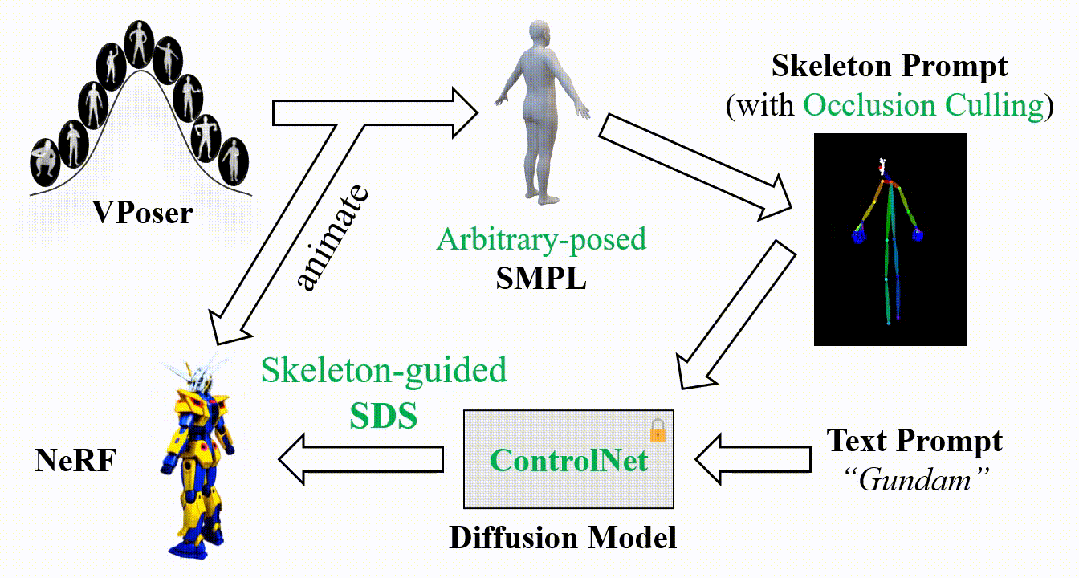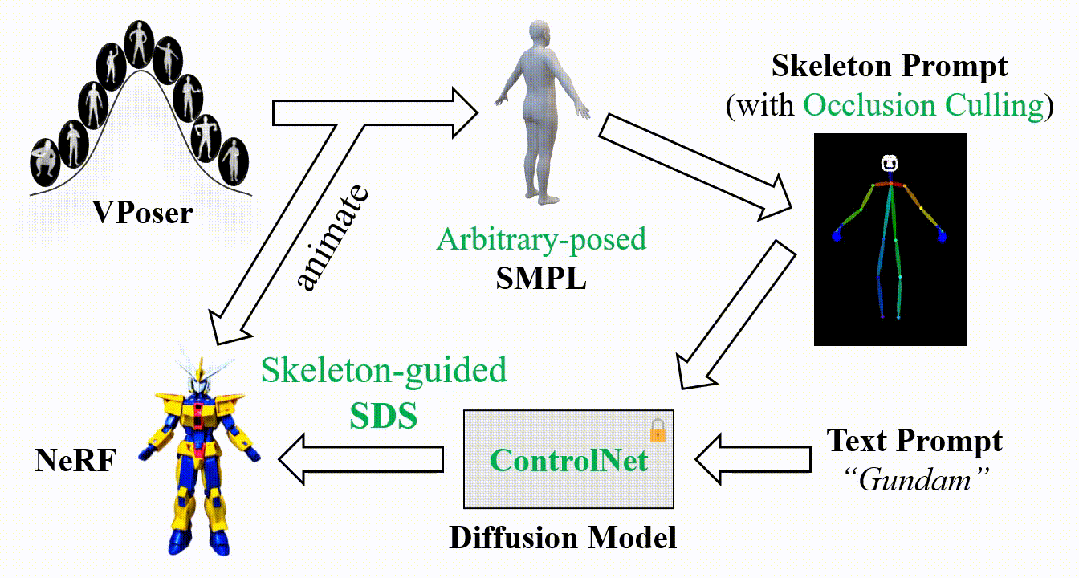
该方法的关键在于两个闭环的对齐:
- 渲染视角的对齐。从NeRF表示中渲染的数字人图像和从SMPL网格表示中渲染的骨架图像总是保持视角同步,这在一定程度上实现了SDS监督的跨视角一致性,从而改善3D生成质量并提升优化效率。
- 人体姿态的对齐。从可驱动的NeRF表示和SMPL网格表示中分别渲染的数字人图像和骨架图像总是保持姿态同步,使得可驱动的NeRF在不同姿态空间的SDS监督下学习到完整的、跨姿态可泛化的数字人表征和动态特性。
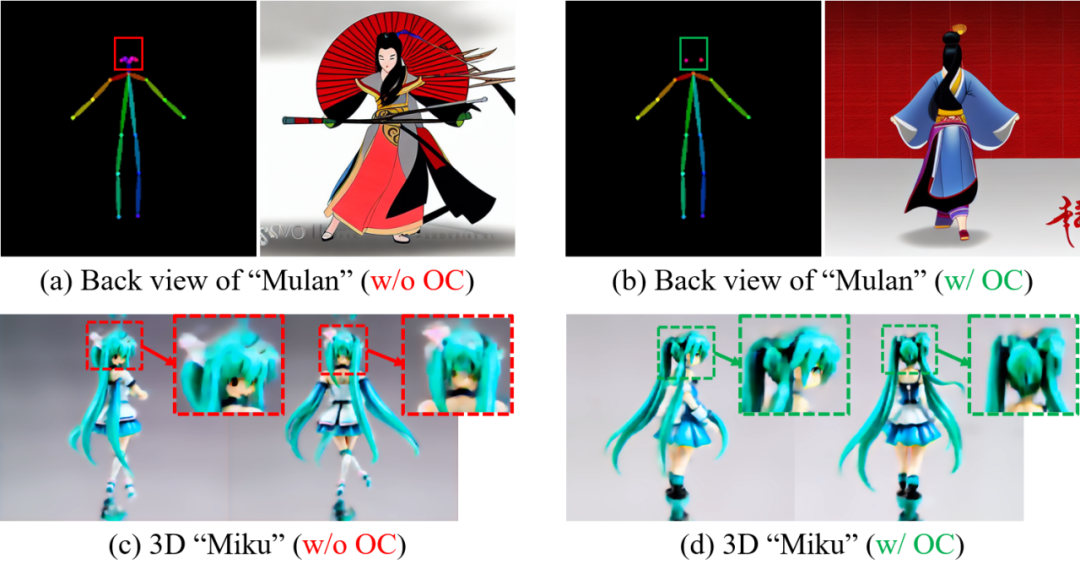
此外,我们注意到ControlNet对骨架图像的语义感知能力有限,如下图(a)所示,尽管给定背面视角的骨架图作为条件,ControlNet仍然错误地生成了正面视角的木兰图像。而如果将骨架图中实际上被遮挡的关键点进行剔除,则可以获得正确的生成结果,如下图(b)所示。基于该观察,我们将遮挡剔除(Occlusion Culling,OC)技巧引入到骨架图的2D渲染过程中,以帮助ControlNet更好地理解骨架条件图像。如下图(c, d)的消融实验结果所示,该技巧能够有效解决3D生成中常见的多脸问题。
在具体实现上,DreamWaltz采用了两阶段的训练策略:1. 规范姿态下的3D数字人生成;2. 任意姿态下的3D数字人驱动学习。该策略的动机在于先进行简单的固定姿态训练,再进行复杂的任意姿态训练,有助于更稳定的训练过程。
四、实验结果
3D数字人生成
只要提供文字描述,DreamWaltz就可以在一小时内生成相应的规范姿态下的3D数字人,并且不会受到多脸问题或者紧身着装的限制。
我们的方法可以直接拓展到更高分辨率的NeRF表示中,得到更高质量的3D数字人:
3D数字人驱动
给定骨架动作序列,DreamWaltz生成的3D数字人可以进一步被驱动以执行相应的动作。根据3D表示的不同,我们提供了两种3D数字人驱动方式。
第一种驱动方式是DreamWaltz原生实现,直接基于NeRF表示进行动作驱动。由于使用了任意姿态下的扩散图像先验进行驱动学习,因此能够基于具体生成人物的3D结构进行自适应校正。驱动结果如下所示:
第二种驱动方式兼容传统3D制作管线,首先用Marching Cube算法将NeRF表示转换为Mesh表示,再使用Mixamo平台进行骨骼绑定和动作驱动:
构建3D场景
基于DreamWaltz生成的数字人,我们进一步探索了具有不同交互类型的3D场景构建,包括数字人-物体、数字人-场景和数字人-数字人间的交互。
五、总结
我们提出了DreamWaltz,这是一种新颖的学习框架,能够将文本描述转换成和复杂且可驱动的3D数字人。为了创建高质量的3D数字人,我们采用SMPL人体参数化模型作为先验,并通过跨视角一致的骨架条件化的得分蒸馏采样对NeRF进行优化训练。生成的3D数字人基于可形变的NeRF表示,并且在随机姿态空间中进行自适应学习,因此能够被任何姿势驱动而无需重新训练。借助DreamWaltz,我们可以发挥想象力,通过文本描述制作3D虚拟人物并构建出多样化的动画场景。
提醒
点击“阅读原文”跳转到01:09:01
可以查看回放哦!
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1400多位海内外讲者,举办了逾600场活动,超600万人次观看。

我知道你
在看
哦
~

点击 阅读原文 观看回放!


















 216
216

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









