






点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

讲者简介
王子泰
个人简介:
中国科学院信息工程研究所19级直博生,导师为黄庆明教授,研究方向为数据挖掘与机器学习,尤其关注复杂场景下模型评价与优化。在 IEEE TPAMI、NeurIPS、AAAI、ACMMM 等国际期刊/会议上发表 CCF-A 类论文 8 篇,其中第一作者 6 篇,Oral/Spotlight论文 4 篇。
Title
面向不平衡学习的细粒度泛化分析
A Unified Generalization Analysis of Re-Weighting and Logit-Adjustment for Imbalanced Learning
Content
内容简介
针对不平衡学习,一类简单且有效的方法是修正原始损失函数,使学习过程更多关注少数类。当前损失修正方法,包括重加权与得分调整两类,虽已取得显著性能提升,但其理论分析仍然粗糙,无法解释部分实验结果。针对该问题,首先将局部化技术引入不平衡学习泛化分析,提出局部利普西茨性质及其压缩引理,构造得到依赖损失函数局部性质的细粒度泛化误差上界。其次,将上述泛化误差上界应用于已有不平衡学习损失函数,不仅揭示了重加权、得分调整、延迟加权等机制与泛化性能的联系,还为已有损失函数提供了理论依据。进一步,根据理论分析结果,改进了已有不平衡学习方法,提出了对齐重加权机制与截断得分调整机制,尽可能压缩模型泛化误差上界。在多个基准数据集上结果表明所提学习方法显著改善了已有不平衡学习方法的性能。
论文链接:
https://arxiv.org/abs/2310.04752
代码链接:
https://github.com/wang22ti/DDC
谷歌学术主页:
https://scholar.google.com/citations?user=45qZ_LcAAAAJ&hl=zh-CN
1.研究背景
传统机器学习方法通常假设样本数量在类别间分布均衡,然而真实数据集分布往往呈现显著不平衡态势。在此场景下,经验风险最小化框架(ERM)将偏向学习多数类,使得模型在少数类上泛化变得更为困难。鉴于此,一类简单且有效的不平衡学习方法是修正原始损失函数,促使学习过程更加关注少数类。当前损失修正方法,可分为重加权与得分调整两类,其中前者提高少数类样本损失权重以鼓励平衡学习,后者通过类别相关的得分调整项以改善每个类别间隔。常见的损失修正方法可形式化为如下形式,又名VS损失[1]:

同时,为准确评估模型性能,通常使用平衡准确率作为模型性能评价指标,即分别计算各类准确率,并以各类准确率均值作为性能评估指标。那么,现有损失修正方法是否能够保证模型在平衡准确率上的泛化性能?针对该问题,现有理论分析仍然粗糙,无法解释部分实验结果。具体而言,已有工作[5, 6]将各类别泛化误差上界的均值直接作为整体泛化界,如下图所示:

虽然简单易懂,该泛化界存在两方面问题:
理论层面,该泛化界粒度较粗且不够紧致。具体而言,不同损失函数间差异在于选择不同的类别相关项,但证明唯一涉及的损失函数性质,即利普西茨连续性,是全局的,无法衡量这一差异。同时,由于求和项的上界小于各项上界的求和,若能够直接约束整体泛化误差,可获得更为紧致的泛化界:
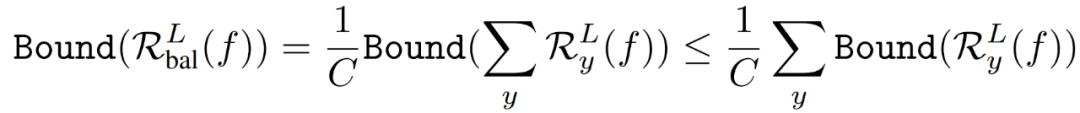
经验层面,虽然该泛化界诱导的LDAM损失优于CE损失,但效果并不显著。而结合[5]中提出的延迟重加权机制(DRW),性能提升则更为显著。然而,上述泛化误差上界误差解释该经验结果。
2. 理论分析
针对上述问题,首先提出直接约束整体泛化性能的引理,其中等式右侧分母包含了最小类在训练集占比,直接揭示了不平衡学习泛化性能与数据不平衡程度的关联:

进一步,为约束复合函数簇G,建模损失中类别相关项对泛化界的影响,提出局部利普西茨连续性及其诱导的压缩引理:

综合上述引理,并将之应用至VS损失,有如下定理:

其中,B_y(f)是各类样本最小得分,与各类的最小间隔紧密相关。基于该泛化误差,进一步有如下理论结果,详见论文:(1)重加权与得分调整均可通过消除该泛化界中不平衡项改善模型泛化性能;(2)延迟重加权是必要的;(3)已有重加权项与得分调整项[2,3,4]均可改善模型泛化性能;(4)乘法调整可能与重加权存在不兼容问题,而加法调整项不存在该问题。
3. 所提方法
基于上述理论结果,本文改进了已有学习方法:(1)需综合使用重加权、乘法得分调整、加法得分调整;(2)将重加权项直接与泛化界中不平衡项对齐,即Aligned DRW(ADRW);(3)在使用重加权时取消使用乘法得分调整,即Truncated LA(TLA)。整体算法如下图所示:

4. 实验结果
首先通过一系列实验验证理论分析结果,其中下左图验证了DRW机制的必要性,下有图验证了乘法调整与重加权存在不兼容问题。
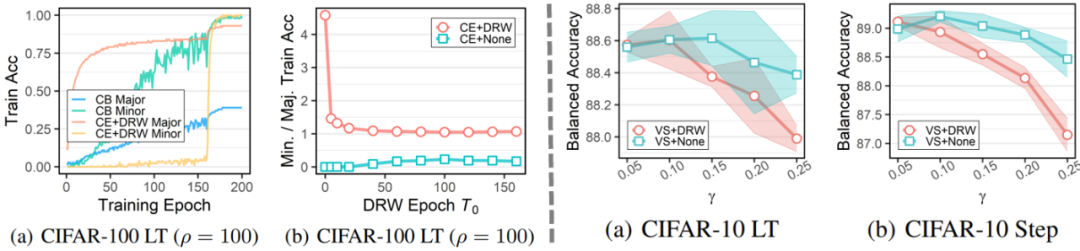
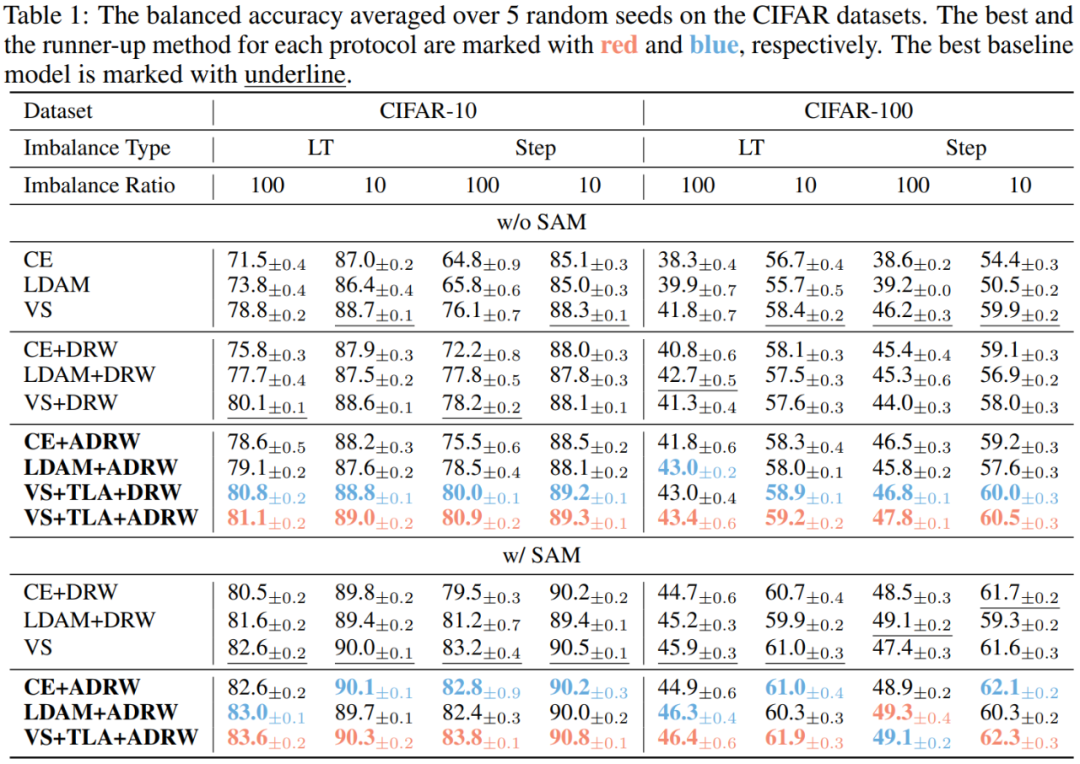
进一步,在CIFAR10 LT、CIFAR-100 LT、ImageNet-LT、iNaturalist等多个基准数据集验证了所提方法的有效性:
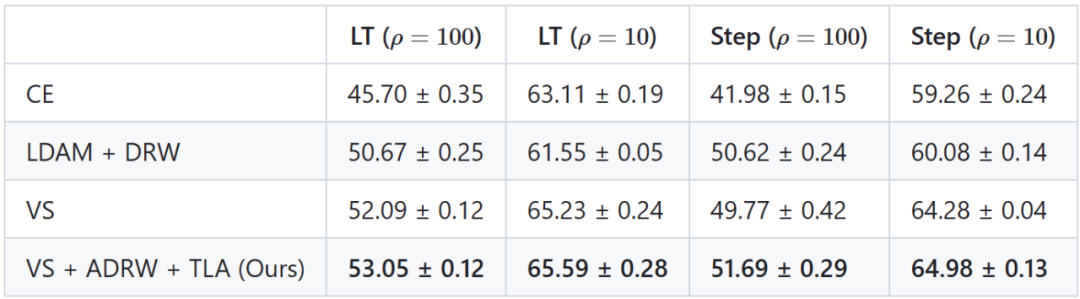
若加入更多增强技术,如延长训练轮数至400、精调weight decay、使用randaug技术,可取得更优性能,如在CIFAR-100数据集上结果如下,更多结果详见代码链接。
参考文献
[1] Label-imbalanced and group-sensitive classification under overparameterization, NeurIPS 2021.
[2] Class-balanced loss based on effective number of samples, CVPR, 2019.
[3] Long-tail learning via logit adjustment, ICLR, 2021
[4] Identifying and compensating for feature deviation in imbalanced deep learning, Arxiv, 2020.
[5] Learning imbalanced datasets with label-distribution-aware margin loss, NeurIPS 2019.
[6] Balanced meta-softmax for long-tailed visual recognition, NeurIPS 2020.
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1400多位海内外讲者,举办了逾600场活动,超600万人次观看。

我知道你
在看
哦
~

点击 阅读原文 关注我们!


















 246
246

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









