






 清华大学和智谱AI团队提出RelayDiffusion,通过模糊扩散和块状噪音优化级联模型,降低高分辨率图像合成的成本和复杂性,提升生成性能并达到SoTA指标。
清华大学和智谱AI团队提出RelayDiffusion,通过模糊扩散和块状噪音优化级联模型,降低高分辨率图像合成的成本和复杂性,提升生成性能并达到SoTA指标。
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
作者简介
腾嘉彦,清华大学知识工程实验室本科生
论文标题
RELAY DIFFUSION: UNIFYING DIFFUSION PROCESS ACROSS RESOLUTIONS FOR IMAGE SYNTHESIS

论文链接:
https://arxiv.org/abs/2309.03350
代码链接:
https://github.com/THUDM/RelayDiffusion
论文内容
扩散模型(Diffusion)在图像合成方面取得了巨大的成功,显著提升了图片合成的质量。然而,扩散模型在合成高分辨率图片时仍面临较大挑战,一是低分辨率的噪声调度很难直接用于高分辨率,研究者们需要为高分辨的场景谨慎地调节噪声调度表,且仍难以获得良好的结果;二是高分辨的训练过程需要大量资源,计算成本较高。
一种流行的解决方案是latent (stable) diffusion提出的在隐空间内训练,再映射回像素空间,但不可避免地会受到底层伪影(low-level artifacts)的影响;另一种方案是训练一系列不同分辨率的超分扩散模型构成级联,现有的级联方法是有效的,但它需要每个阶段的从噪音开始完整采样,效率较低,且效果严重依赖于条件增强等训练技巧。
为了更好地解决上述问题,清华大学和智谱AI的研究团队提出了一个新型的级联模型--Relay Diffusion(RDM),该模型在具备原有级联方法的优点的同时,借助模糊扩散过程(blurring diffusion)和块状噪音(block noise)可以在任意不同分辨率间无缝衔接,像“接力赛”一样,极大地减少了训练和采样的成本。
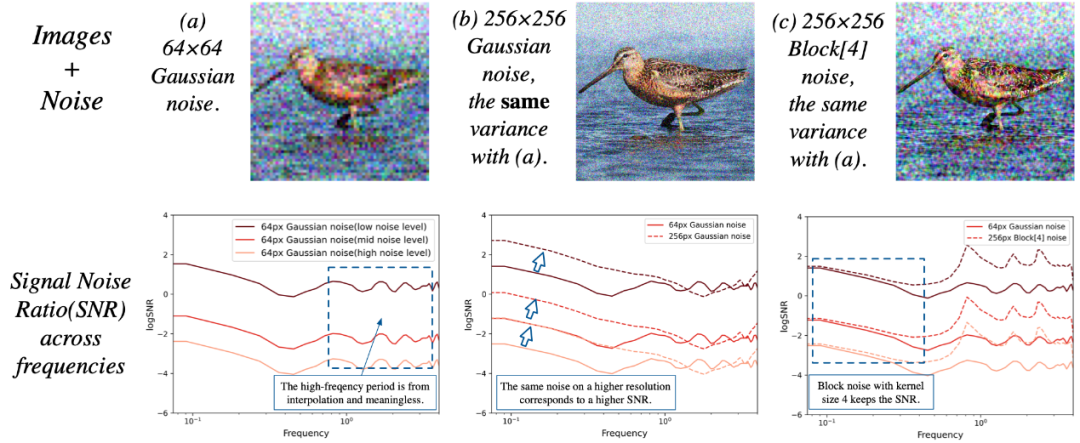
RDM通过离散余弦变换频谱分析发现,相同噪声强度在更高的分辨率下对应于频率空间的信噪比(SNR)在低频部分更高,这意味着自然图像的低频信息没有被很好的破坏掉。为此,RDM提出了一种像素点间具有相关性的块状噪音--block noise,它在高分辨率下对应的SNR在低频部分和高斯噪音在低分辨率下的SNR相当。
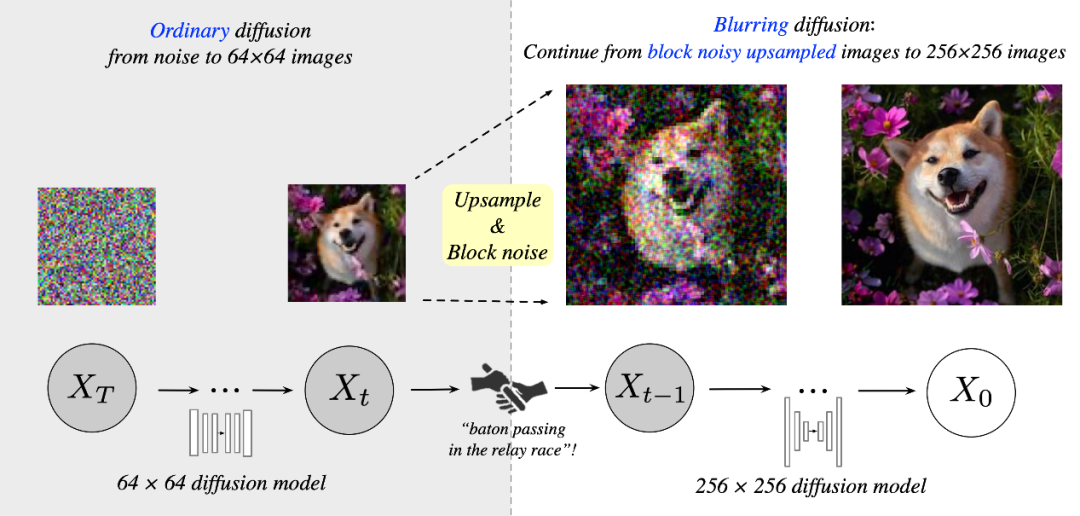
以64->256为例,RDM的整体流程为:先通过标准扩散过程生成低分辨率图片,再将其上采样为每个4x4网格具有相同像素值的模糊高分辨率图片,之后对每个4x4的网格独立进行模糊扩散过程(blurring diffusion)。这样使得前向过程的终态和上采样的模糊图片对齐,因此RDM的第二阶段可以直接以模糊图片为起始点,而不是现有级联方法中的纯高斯噪音。
RDM相比传统的级联扩散模型,在生成高分辨率图片时,省去了生成低频信息的部分,极大地节约了计算成本,同时更加简单,不需要以低分辨率图片为条件和各种条件增强技巧,而且不需要重新设计或调节噪声调度表。
RDM在节省成本的同时,可以更快地达到更好的生成性能,在无条件数据集CelebA-HQ-256、512、1024上达到了SoTA的FID,在条件数据集ImageNet-256上达到了SoTA的sFID以及具有竞争力的FID,大幅超过了ADM、LDM、DiT等模型。
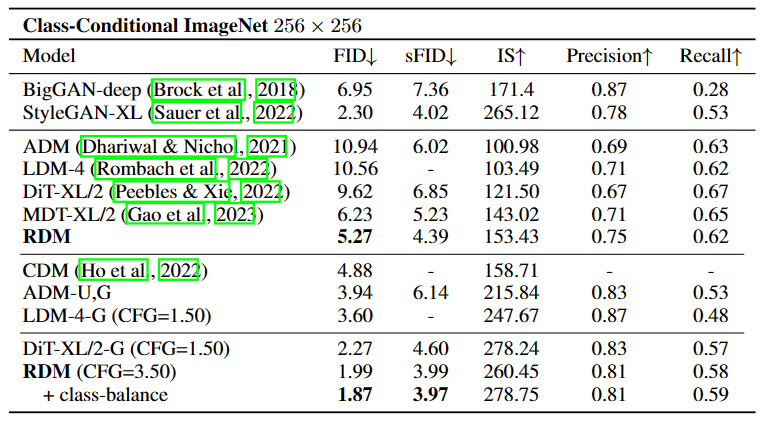
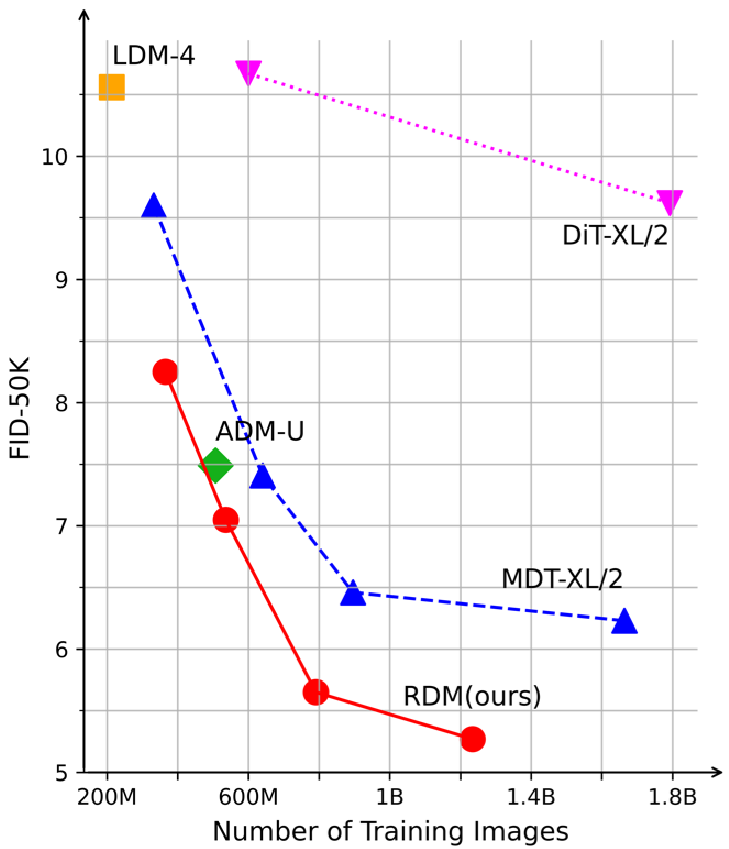
当不使用无分类器指导(CFG)时,RDM也显示出强大的性能优势
最近,我们团队还将Relay的相关思想用于Text-to-Image领域,欢迎大家同时关注我们的最新工作:
CogView3: Finer and Faster Text-to-Image Generation via Relay Diffusion
https://arxiv.org/abs/2403.05121
往期精彩文章推荐
记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1700多位海内外讲者,举办了逾600场活动,超700万人次观看。

我知道你
在看
哦
~

点击 阅读原文 观看回放!


















 71
71

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









