






点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

李明晗
李明晗,香港理工大学博士生,博士生导师张磊。
在这之前,她跟随孟德宇老师在西安交通大学数学院取得硕士学位。他的研究兴趣是视频复原,分割和生成任务。李明晗以第一作者在CVPR发表4篇文章,在TIP发表一篇文章。同时她也是很多CCF会议和期刊的审稿人,包括CVPR,ICCV,ECCV,AAAI和信号处理。

内容简介
尽管统一图像分割取得了很不错的进展,但开发统一视频分割模型仍然是一个挑战。这主要是因为不同视频分割任务的侧重点不同,这使得使用相同架构处理不同任务变得异常困难,尤其在保持物体时序一致性方面。
具体来说,类别为导向的视频分割任务更侧重检测并跟踪视频中特定类别的对象,而以提示为导向的VS任务侧重于在根据视觉/文本提示在视频中重新识别目标。
近日,由香港理工大学和OPPO研究院提出了一种新颖且简洁的统一视频分割架构,名为UniVS,旨在通过使用视觉和文本提示作为查询来明确地解码物体的掩码。对于每一个目标物体,UniVS取先前帧中的提示特征的平均值作为其初始查询,从而明确地解码出目标物体的掩码。同时,本文在掩码解码器中引入了一个目标感知的提示交叉注意力层,以传递内存池中的提示特征到当前帧中。在推理阶段,通过将先前帧中预测的物体掩码作为它们的视觉提示,UniVS将不同的视频分割任务转化为以提示为导向的目标分割,消除了启发式的帧间匹配过程。本文提出的框架不仅统一了不同的视频任务,还自然地实现了统一的训练和测试,确保在不同场景下具有稳健的性能。在视频实例、语义、全景、对象和文本指代分割任务的10个具有挑战性的VS基准测试上,UniVS取得了非常不错的视频分割性能,并且在多个场景下展示了其强大的通用能力。
论文标题
UniVS: Unified and Universal Video Segmentation with Prompts as Queries
论文链接:
https://arxiv.org/abs/2402.18115
代码链接:
https://github.com/MinghanLi/UniVS/
项目主页:
https://sites.google.com/view/unified-video-seg-univs
论文内容
1. 引言
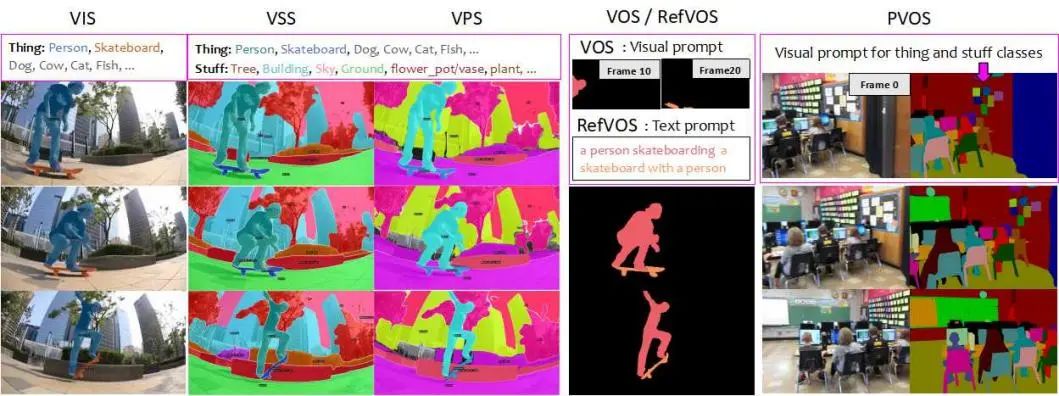
视频分割(VS)将视频序列划分为不同的区域或片段,为视频理解、区域引导的视频生成、交互式视频编辑和增强现实等许多应用提供了便利。视频分割的任务可以分为两组:类别指定的视频分割和提示指定的视频分割。前者侧重于从预定义的类别集合中分割和跟踪实体。典型的任务包括视频实例分割 (VIS)、语义分割 (VSS) 和全景分割 (VPS),其中需要指定对象类别信息。另一组任务侧重于在整个视频中识别和分割特定目标,需要提供目标的视觉提示或文本描述。提示导向的VS任务包括视频对象分割(VOS)、全景视频对象分割 (PVOS) 和引用式视频对象分割 (RefVOS)。每种VS任务都有自己的数据集注释和模型评估协议。
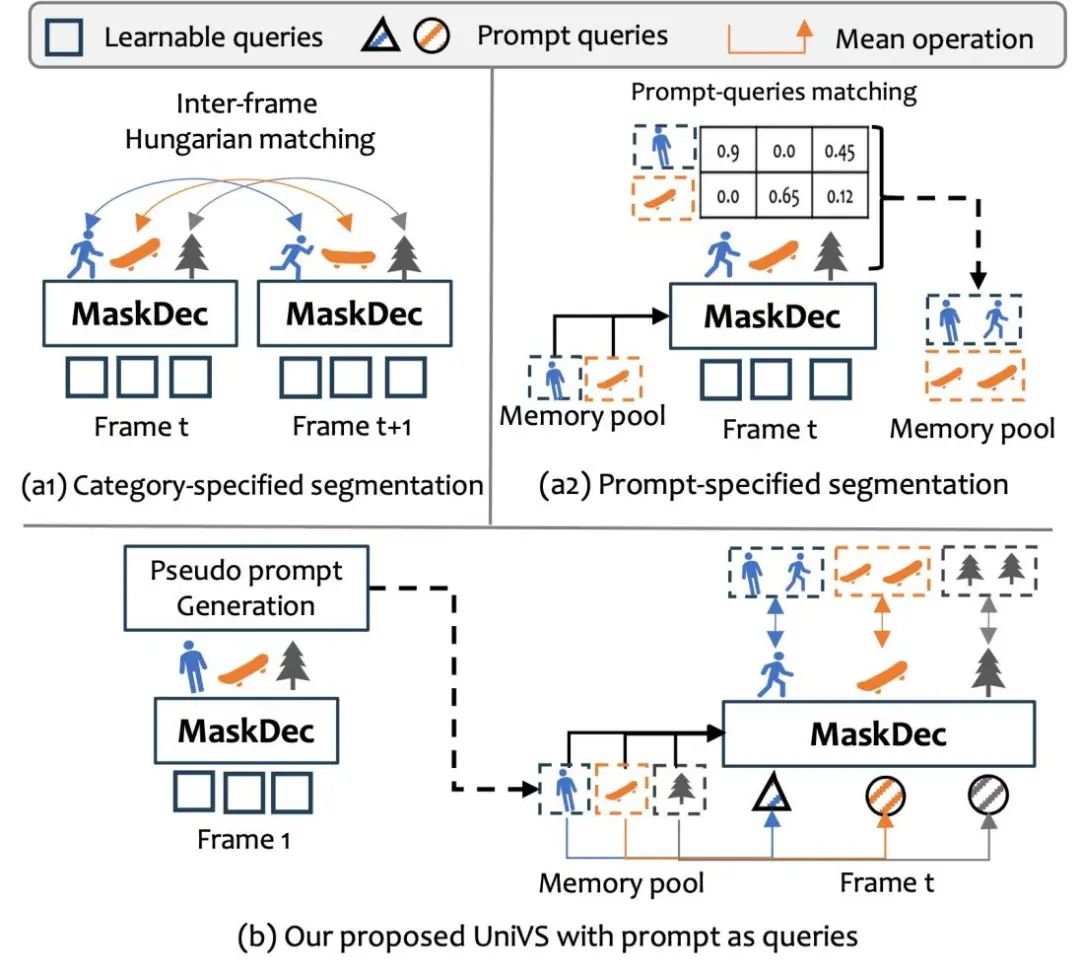 图1. 比较现有的视频分割方法和UniVS。在现有的类别指定分割任务方法中(a1),需要首先在每帧中检测实体,然后在帧间进行匹配;而在提示指定分割任务方法中(a2),需要从预测的掩码中识别目标物体。相比之下,本文提出的UniVS (b) 使用预测的掩码作为伪视觉提示以在后续帧中解码掩码,避免了启发式后处理。
图1. 比较现有的视频分割方法和UniVS。在现有的类别指定分割任务方法中(a1),需要首先在每帧中检测实体,然后在帧间进行匹配;而在提示指定分割任务方法中(a2),需要从预测的掩码中识别目标物体。相比之下,本文提出的UniVS (b) 使用预测的掩码作为伪视觉提示以在后续帧中解码掩码,避免了启发式后处理。
现有的统一VS模型大多受到统一图片分割模型的启发。它们逐帧分割视频序列,然后使用相似性匹配步骤来关联多帧间的共同的对象或找到类别/提示指定的目标物体。然而,现有模型在处理VS任务时仍然存在一些限制,例如无法在不同VS任务中保持物体的时序一致性,或者无法在同一个框架中兼容可数(如人,车)和不可数的物体(如天空,草地),或者无法很好地编码语言信息来解决以语言为导向的目标物体分割。究其根本,这主要是因为类别指定和提示指定的VS任务有不同的侧重点导致的。详细来说,类别指定的分割主要关注每帧的精确检测和共同对象的帧间关联,而提示指定的分割则侧重于在视频序列中使用文本/视觉提示准确跟踪目标,其中目标可以是不常见的对象或对象的一部分。这两种类型的VS任务的不同重点使得在单个框架内集成它们并取得令人满意的结果变得具有挑战性。
为了缓解上述问题,本文提出了一种新颖的统一VS架构,即UniVS,它使用提示作为查询。对于每个感兴趣的目标,UniVS将先前帧的提示特征平均作为其初始查询。在掩码解码器中引入了一种目标导向提示交叉注意力(ProCA)层,以整合存储在内存池中的全面提示特征。初始查询和ProCA层在显式和准确解码掩码中起着关键作用。另一方面,通过将先前帧的实体预测掩码作为它们的视觉提示,UniVS可以将不同的VS任务转化为以提示为导向的目标分割任务,消除了启发式的帧间匹配。UniVS的整个过程如图所示。UniVS不仅统一了不同的VS任务,还自然地实现了通用的训练和测试,在不同场景下表现出稳健的性能。它在10个具有挑战性的VS基准测试中展现了出色的性能和通用性,涵盖了VIS、VSS、VPS、VOS、RefVOS和PVOS任务。据我们所知,UniVS是第一个成功将所有现有的VS任务统一在一个模型中的工作。
2. 方法介绍
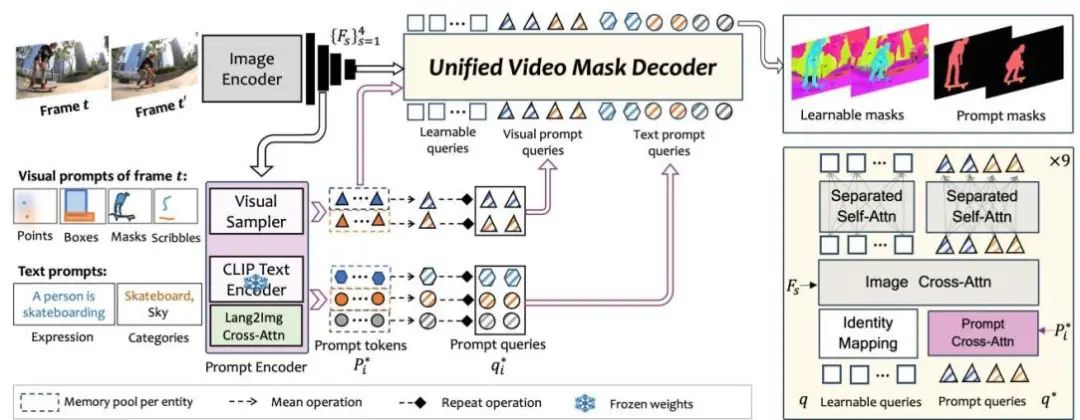
UniVS包含三个主要模块:图像编码器、提示编码器和统一视频掩码解码器,如图所示。图像编码器将输入的RGB图像转换为图片令牌,而提示编码器将原始的视觉/文本提示转换为提示嵌入。统一视频掩码解码器明确地解码视频中任何实体的掩码或以提示为导向的目标的掩码。
2.1 图像编码器和提示编码器
图像编码器包含一个主干网络和一个像素解码器。主干网络将RGB图像映射为多尺度特征,像素解码器进一步融合不同尺度的特征以增强表示能力。多尺度特征图的分辨率分别是输入图像的1/32、1/16、1/8和1/4。
提示编码器将输入的视觉/文本提示转换为提示嵌入。视觉提示可以是点击点、框、掩码和涂鸦等。为了将视觉提示转换为图像嵌入,采用了SEEM中提出的Visual Sampler策略。它从每个目标的指定像素中随机采点,并从图像编码器输出的图像特征图中提取对应点的特征作为其视觉提示嵌入。语言提示可以是类别名称(如“人”)或文本表达式(如“一个人正在滑板”)。将类别名称或表达式输入分词器以获取其字符串令牌,并将其输入到CLIP文本编码器中获取文本嵌入。然后使用单个交叉注意力层实现语言-图像嵌入的交互,其中查询是文本嵌入,键和值是扁平化的多尺度图像嵌入。最后,使用一个映射矩阵将文本嵌入从文本维度映射到视觉维度的特征空间。注意,为了利用CLIP强大的开放词汇能力,本文冻结了CLIP文本编码器的权重。
2.2 统一视频掩码解码器


3. 统一的训练和推理
训练阶段: UniVS的训练过程包括三个阶段:图像级训练、视频级训练和长视频微调。在第一阶段,UniVS在多个图像分割数据集上进行训练,使用图像级注释对模型进行预训练,以获得良好的视觉表示。在第二阶段,作者将一个包含三帧的短视频剪辑输入预训练模型,并在视频分割数据集上进行微调,以感知短时间内的物体运动轨迹的变化。在第三阶段,作者使用包含超过五帧的长视频序列进一步微调统一视频掩码解码器,鼓励其在更长的时间范围内学习更具区分性的特征和轨迹信息。为了优化内存使用,作者在最后两个阶段冻结了主干网络的权重,并在最后一个阶段进一步冻结像素解码器。在每次迭代中,批次中的所有样本来自同一个数据集。与从不同数据集中混合采样相比,本文发现这种采样策略可以使训练更加稳定。具体的训练数据集和训练策略请查看文章正文及补充材料。
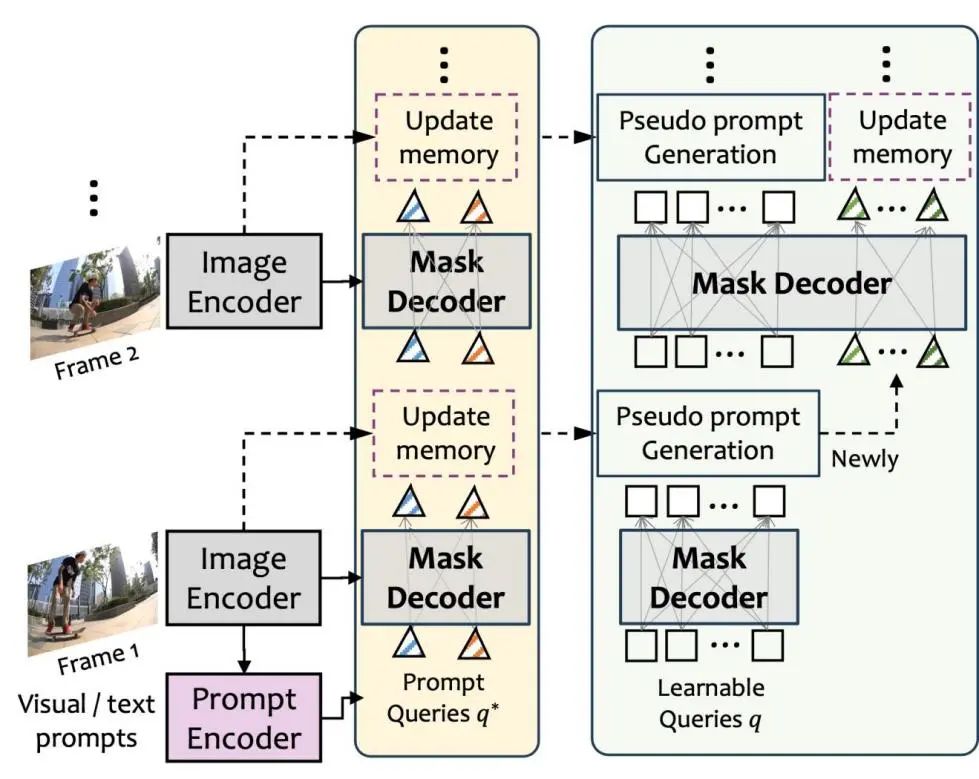
统一流式推理过程: 在UniVS中,模型的输入可以是单帧或多帧的视频剪辑。本文以单帧作为输入为例,阐述了用于通用类别指定和提示指定的统一推理过程。对于提示指定的VS任务,UniVS以视频帧和视觉/文本提示作为输入,推理过程如图3中的黄色框所示。UniVS可以同时处理多个目标。首先,图像编码器将第一帧转换为多尺度图像嵌入。随后,提示编码器将目标的视觉/文本提示转换为提示标记。在本文的设计中,每个目标都有其专用的内存池,用于存储相关的提示标记,并通过求平均来获得其提示查询。这些查询被掩码解码器用于预测当前帧中目标的掩码,然后将其作为目标的视觉提示反馈给提示编码器,从而使用新的提示信息更新目标的内存池。简而言之,UniVS利用存储在内存池中的目标对象的提示信息来识别和分割后续帧中的目标,消除了其他统一模型(如SEEM 和 UNINEXT)中繁琐的后处理匹配步骤,其需要从所有预测的实体中过滤出目标物体。
针对类别指定的VS任务,UniVS采用周期性目标检测策略,并将分割转化为基于提示的目标分割问题。详细过程如图3中的浅绿色框所示。首先,UniVS使用可学习的查询来识别出第一帧中的所有实体掩码,然后使用非极大值抑制(NMS)和分类阈值来过滤掉冗余的掩码和分类置信度较低的掩码。剩余的目标对象也作为它们的视觉提示,UniVS利用基于提示的目标分割流来直接预测它们在后续帧中的掩码,消除了以前方法中跨帧实体匹配的需求。此外,为了识别出后续帧中出现的新对象,UniVS使用可学习的查询对每隔几帧进行目标检测,并将其与存储在内存池中的先前检测到的对象进行比较。作者使用BiSoftmax方法来区分视频中的旧对象和新对象。
现有的VS方法大多假设短视频剪辑中的目标运动平滑,以实现跨帧关联实体。然而,对于包含复杂轨迹或大场景变化的视频,这种假设不成立导致跟踪精度下降。相比之下,本文提出的UniVS通过使用提示作为查询来实现显式的掩码解码,这种可学习的追踪策略可以在复杂场景中性能更好也更鲁棒。
4. 实验和可视化
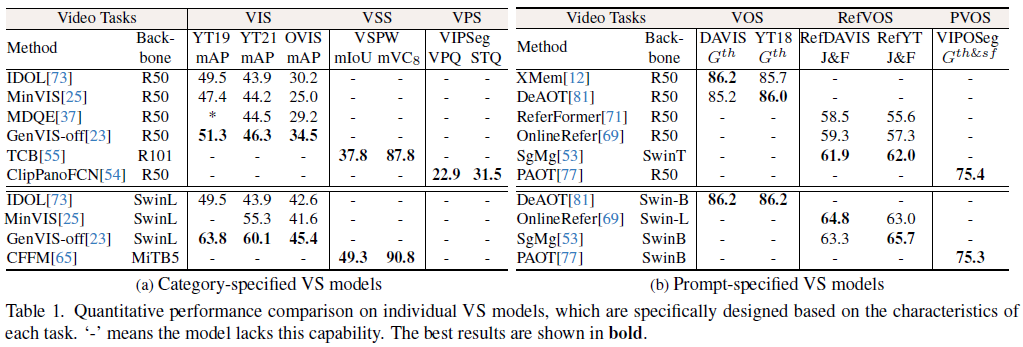
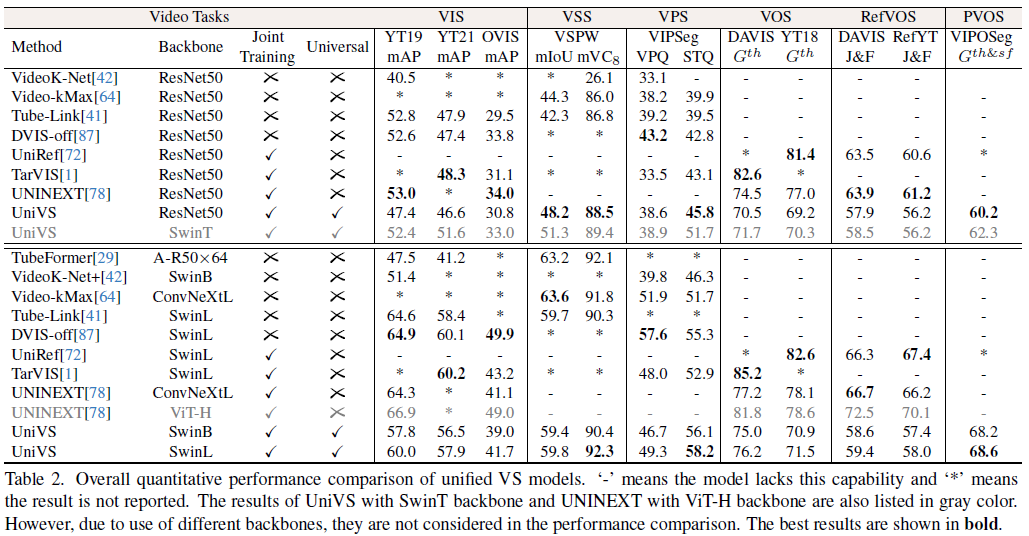
在表1和表2中,本文提出的UniVS在六个VS任务的10个基准测试上进行了定量性能比较,包括VIS、VSS、VPS、VOS、RefVOS和PVOS。表1展示了针对特定单个VS任务设计的分割模型的结果,表2展示了可以同时处理多个任务上的统一模型的结果。总的来说,在最近的高性能VS模型中,单独模型在特定任务上取得了很高的性能,但缺乏泛化能力。相反,联合训练的统一模型可以处理多个任务,但在某些任务上可能存在性能下降。更多实验分析,消融实验,和可视化结果请参见原文及附加材料。
下图展示了UniVS在六个视频分割任务上的分割结果。可以观察到,UniVS在这些任务中实现了令人满意的分割结果,展示了其出色的泛化能力。UniVS不仅适用于类别引导的分割,还在几乎所有的视觉提示引导的物体和物体实体分割任务中表现出色。与此同时,UniVS展示了在表达引导的跨模态对象分割任务中的能力。其多模态融合能力和一致的分割性能使UniVS在整合语言和视频信息方面具有很高的潜力。



本篇文章由陈研整理
点击“阅读原文”,
可以查看回放哦!
往期精彩文章推荐
论文解读 | CVPR2024:知识感知注意力的动态图表示用于组织病理学全幻灯片图像分析
记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1800多位海内外讲者,举办了逾600场活动,超700万人次观看。

我知道你
在看
哦
~

点击 阅读原文 观看回放!


















 505
505

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









