






点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
作者简介
卫昱西,上海交通大学硕士生
概述
Editable Scene Simulation for Autonomous Driving via Collaborative LLM-Agents
场景模拟在自动驾驶领域得到了广泛关注,因为它具有生成定制数据的巨大潜力。然而,现有的可编辑场景模拟方法在用户交互效率、多摄像头逼真渲染以及外部数字资产集成方面存在局限性。为了解决这些挑战,本文介绍了ChatSim,这是第一个通过自然语言命令实现可编辑的逼真3D驾驶场景模拟的系统,并能集成外部数字资产。为了实现高度命令灵活性的编辑,ChatSim采用了大型语言模型(LLM)代理协作框架。为了生成逼真的输出,ChatSim采用了一种新颖的多摄像头神经辐射场方法。此外,为了发挥高质量数字资产的潜力,ChatSim采用了一种新颖的多摄像头光照估计方法,以实现场景一致的资产渲染。在Waymo开放数据集上的实验表明,ChatSim能够处理复杂的语言命令并生成相应的逼真场景视频。
论文地址:https://arxiv.org/pdf/2402.05746.pdf
代码地址:https://github.com/yifanlu0227/ChatSim
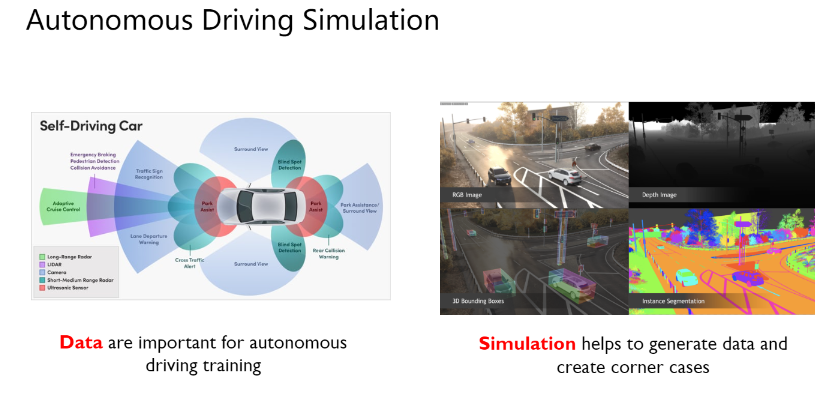
Autonomous Driving Simulation
近年来,自动驾驶技术在学术界和工业界得到了广泛关注并逐渐商业化。当前的自动驾驶系统,特别是感知模块,依赖于大量高质量数据进行训练。然而,系统训练受到“corner cases”或“长尾问题”的限制,即少见但关键情况的数据获取困难。为了解决这一问题,数据仿真技术近年来在自动驾驶领域受到热议,它能有效模拟复杂驾驶场景,包括少见的corner cases,为系统训练提供了一种有效且经济的解决方案。
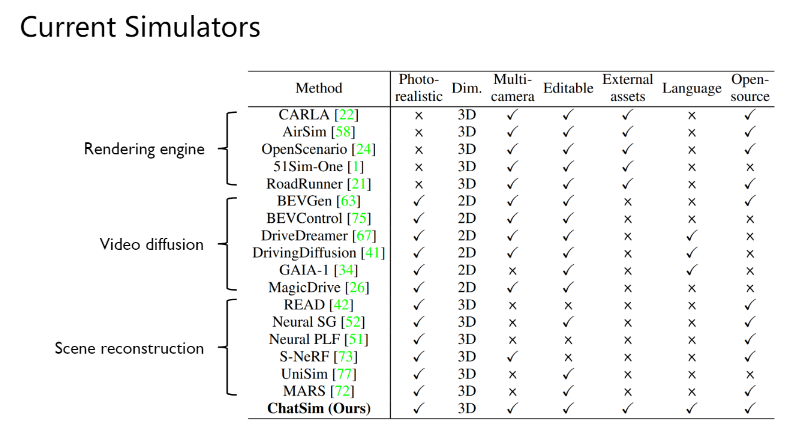
Current Simulators
作者首先对当前常见的几种自动驾驶场景模拟器进行了总结。目前,这些模拟器大致可以分为三类:基于渲染引擎的仿真器、基于视频生成的仿真器,以及基于场景重建的仿真器。第一类基于渲染引擎的仿真器已广泛应用于数据生成和系统检验过程中。第二类基于视频生成的仿真器则通过直接生成自动驾驶相关的视频数据来进行仿真。而第三类基于场景重建的仿真器则是通过使用真实照片重建整个三维场景,并生成全新视角的数据。这些不同类型的模拟器各具优势和特点,作者在文中也对它们的多个方面特征进行了总结。
· Rendering engine
首先,最常见和直接的仿真方法是使用渲染引擎进行渲染,其中一个常用的仿真器是名为CARLA的工具。这种方法允许设计各种场景和物体,用户可以高度自由地进行编辑,并根据需要放置不同的场景和创建不同的模型。
然而,由于渲染引擎的仿真通常需要通过艺术家手动建模,很难确保最终的渲染效果达到足够的真实感,即所谓的“photorealistic”。这意味着与真实场景相比,生成的图像可能存在一定的差异,不易直接用作高质量的训练数据。
此外,渲染引擎的操作通常比较复杂和繁琐,需要专业人员进行操作,这会导致较高的人力成本。因此,总体来看,基于渲染引擎的渲染方法既不简单易用,也难以达到理想的渲染效果。

· Video Diffusion Models
近年来,随着diffusion model和AIGC技术的发展,基于video diffusion model进行自动驾驶场景的视频数据生成已经涌现了许多相关工作。这类方法通常通过人为指定输入信号,如BBMAX3 DBOX或驾驶行为如加速、减速和转向等,来引导视频数据的生成。尽管diffusion model是由真实数据训练得到的,能在一定程度上达到photorealistic效果,但其输出结果的随机性较大,缺乏足够的可控性,有时可能生成质量较差的结果。
特别是在时间和空间上的一致性,即视频数据的special和temporal consistency方面,video diffusion model仍面临挑战。此外,diffusion model的输入信号通常较为粗略,难以精确地预测最终生成结果,无法满足细致的生成需求。作为示例,文中展示了来自工作“drive Dreamer”的video diffusion model生成的数据。尽管整体上看起来较为真实,但其中许多细节仍然不够理想。

值得注意的是,这个样本是由官方主页发布的,实际使用中可能会产生更多质量不佳的结果。由于video diffusion直接生成最终视频像素,缺乏对整个三维空间的显示建模,因此无法保证在special和temporal方面的一致性。可能会出现某些位置出现的摇摆或突变为其他物体的情况。
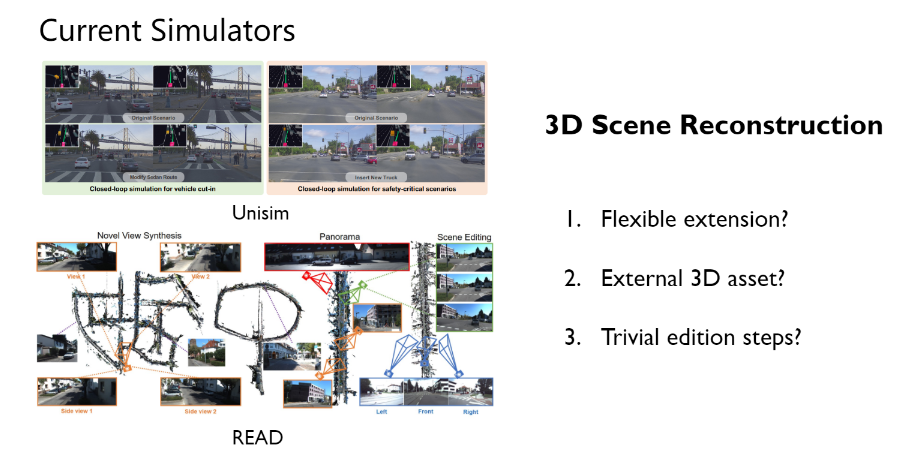
· 3D Scene Reconstruction
近年来,基于神经渲染的场景重建技术也在迅速发展,并在自动驾驶场景中得到了广泛应用。这种场景重建方法能够几乎完全还原原始场景,保持高度的photorealistic效果,并在合理的动态范围内实现几乎完全的Multi video consistency,即在不同视角下的观察一致性。
然而,场景重建生成的数据往往难以实现灵活的数据拓展,通常只能简单地还原输入场景,无法引入其他数字资产作为场景的参与者。此外,场景重建也难以直接实现对场景的灵活编辑,通常需要大量的工程代码支持。因此,许多这类工作并不能直接用作当前自动驾驶场景下的仿真器。
What is ChatSim
ChatSim是第一个实现了language-controled photorealistic multi-view consistent driving scene simulation的系统。ChatSim有如下几个特点:首先,ChatSim可以实现通过自然语言进行细致的场景编辑,无需进行繁琐复杂的代码实现,用户只需要根据需求输入包含各种定制化信息的自然语言就能够直接输出相应的结果;其次,对于背景的渲染,ChatSim使用了提出的McNeRF进行多摄像机的场景重建,实现了广泛视角下高度一致真实的场景渲染;对于前景物体的渲染,ChatSim还使用了所提出的McLight对场景的光照信息进行提取,并将场景光照应用于待加入场景数字资产上,对前景的物体也实现了photorealistic的渲染。

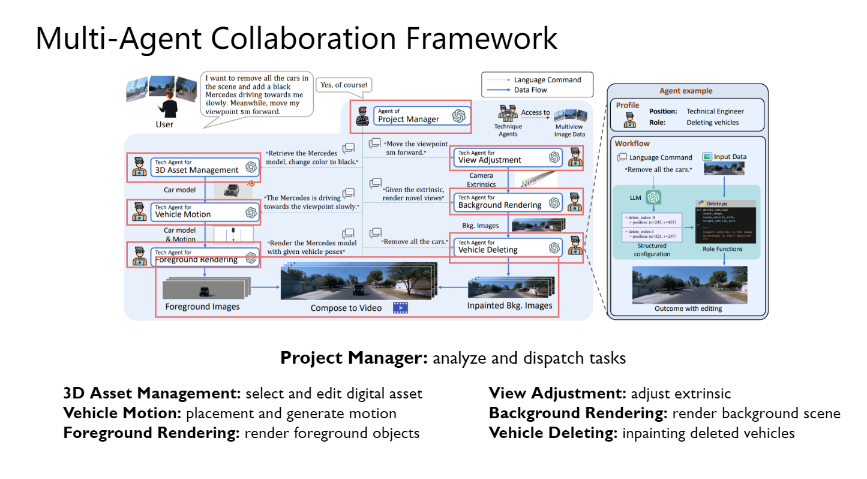
· Multi-Agent Collaboration Framework
ChatSim使用了如图所示的多智能体协同工作流进行仿真数据的生成。如下图所示的每个agent都能够完成特定的某些任务并最终得到输出。首先,用户的指令会被交给Project manager,该agent会对该指令进行理解和拆分,得到相应的可被执行的具体指令,并交给对应的后续technical agent进行处理。对于前景物体的渲染流程由左侧所示,首先由3D assets management agent根据用户的添加需求挑选出合适的数字资产并会编辑数字资产相应的信息,挑选得到的数字资产会被再交给Vehicle motion agent根据放置的需求为该物体生成相应的位置与motion即轨迹,最终数字资产和对应的轨迹会被交给foreground rendering agent进行前景渲染,得到前景物体和对应阴影的渲染效果。对于背景场景的渲染流程由右侧所示,首先会先根据用户的需求交给view adjustment agent进行视角调整生成最终背景渲染需要的外参,外参会被交给background rendering agent进行背景场景的渲染,背景渲染的结果最后由vehicle deleting agent对需要删除的车辆部分进行inpainting,即图像修复,以达到删除的目的。最终前景背景的渲染结果会组合起来形成提供给用户的输出。
· Agent Design Sample
如下图所示是单个Agent的内部设计,此处以view adjustment agent为例。每个agent都由其对应的LLM部分和功能部分组成。LLM部分会由prompt定义其需要进行的任务,并依据接收到的自然语言指令得到相应的关键信息,生成具体的参数字典。而功能部分则会通过LLM部分输出的参数字典进行执行,调用相应的function模块,并将输出的结果交给工作流中其他agent进行后续处理。如左图所示,是一个agent的LLM部分输入的prompt,会先进行任务的大致定义,描述任务需求,再对任务进行细致的解释,随后定义最终需要返回的格式,在使用过程中所有agent都返回为json字典,最终提供一些few-shot examples供LLM学习。所有agent的prompt都按照类似的格式进行组织。

· Background Rendering
对于背景的渲染,chatsim中使用了在文中提出的mcnerf进行,mcnerf的全程是multi-camera nerf,也就是对于多摄像机情况下设计的神经渲染。相较于常规的神经渲染,mcnerf主要考虑了以下两点改进:首先,作者在工程实践中发现自动驾驶数据集中对于多个摄像机相对位姿的标定是不够准确的,尤其对于渲染重建任务而言精确的位姿非常重要,作者采用了经典的sfm方式对于现有的位姿进行了矫正以得到更加准确的位姿标定,这一步虽然比较工程化,但在实验部分可以看出能够显著地提升最终的渲染效果。其次,作者发现多个摄像机由于曝光时间不一致,导致在照片重叠区域中存在一定的色差,为了考虑曝光带来的色差影响,文中将曝光时间编码在了nerf的渲染过程中,实现了在重叠处更加一致的渲染效果。
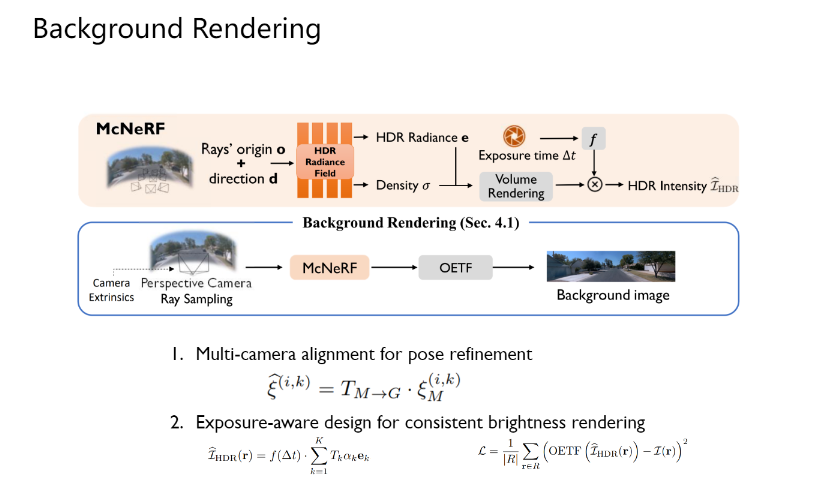
· Foreground Lighting Estimation
对于前景物体的渲染,作者会先进行光照估计得到环境的光照信息并应用在提供的数字资产上。光照估计部分,文中使用了自己提出的McLight。McLight能够仅依据输入的照片,估算出场景中的环境光照贴图,从而能够让前景中的数字资产应用到更加贴合场景的光照实现photorealistic的渲染。McLight同样为多摄像机输入的情况设计,在latent code层面融合了多个相机的信息从而实现对环境光照的更加全面的感知。同时,McLight能够借助McNeRF,生成上半球面范围内具体位置处的环境物体光照,进一步提高了光照的准确程度和渲染的真实性。
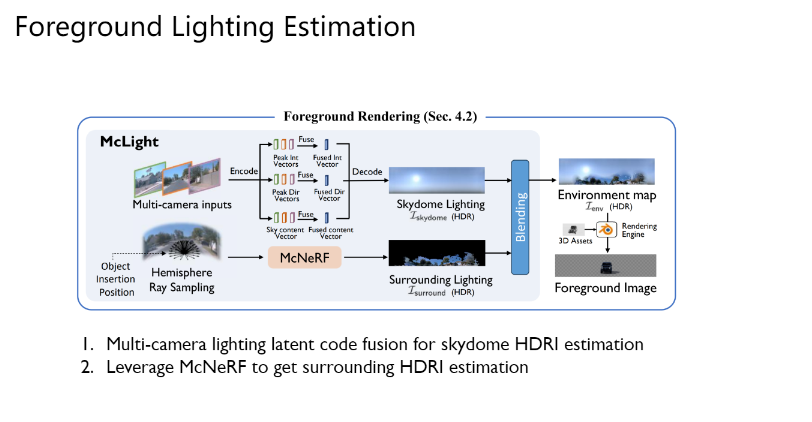
· Foreground Lighting Estimation Details
天空光照估计的实际过程分为两步。首先第一步,是训练一个网络进行LDR到HDR的恢复。大多数情况下的图片输入都是LDR的,即图片像素的范围有所限制,通常为0-255,准确的环境光照贴图需要的是HDR信息,因此需要网络进行LDR到HDR的转换。LDR图片先编码得到sky vector,peak direction vector和peak intensity vector,再由这些信息组合得到最终的输出。第二部则由多视角的输入得到最终的HDR贴图,不同相机的图片同样编码得到三种向量,再通过不同方式聚合得到唯一的向量,经由预训练好的LDR到HDR网络得到最终的输出。
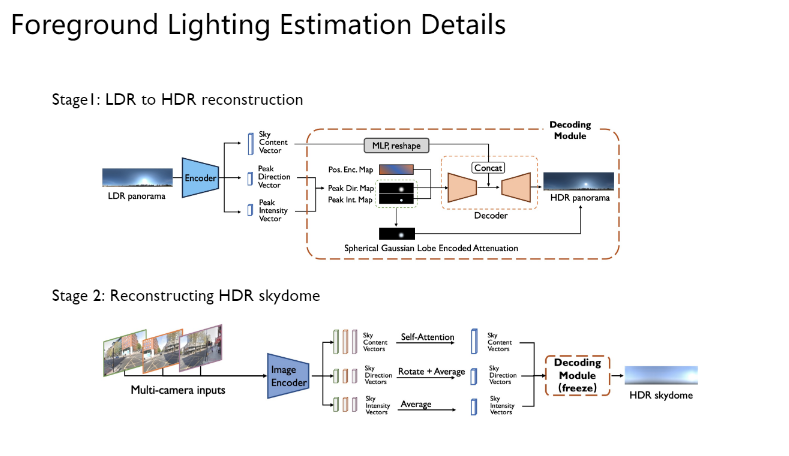
· Foreground Rendering Process
如图展示了文中使用环境贴图渲染最终前景物体的流程,使用渲染软件blender进行。总体而言,会将得到的环境贴图作为光照信息输入,并由blender内部支持的相关操作生成对应的阴影。渲染得到的物体和阴影会被用于最终与背景渲染的结果进行组合。
Placement and Motion
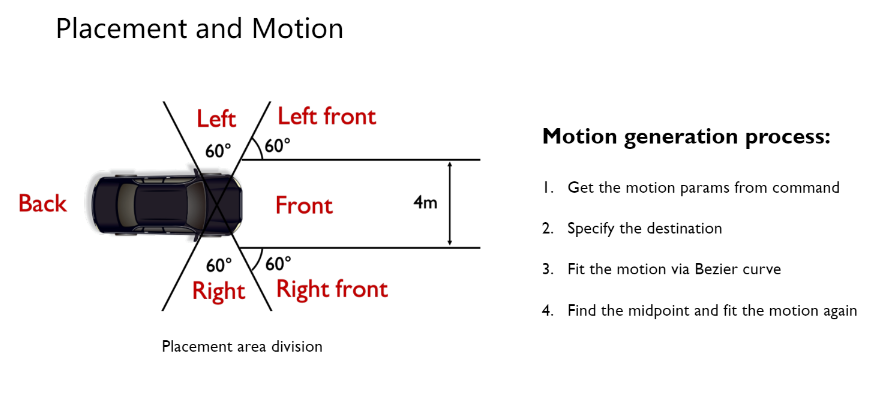
上图是本文所采用的placement和motion的生成部分,文中的placement与motion都是基于地图信息的,placement过程中将自身车辆划分为了几个不同的方向,并根据用户自然语言中的信息找到对应方向,在方向内找到合适的地图节点并按照地图朝向进行放置。Motion的部分,则通过指令中得到的定义的不同参数信息(包括速度和行驶方向),同样寻找合适的丢他节点作为终点,由贝塞尔曲线拟合轨迹。考虑到轨迹可能驶出道路,还会将轨迹中点改变为最近的地图节点并分为两段贝塞尔曲线分别拟合。
Complex and mixed command
作者还展示了ChatSim在复杂且混合的指令下的生成效果。非常冗长、复杂的指令中包含了大量需要执行的细节,包括删除,增加,视角调整等等,并且两辆车的轨迹也有非常具体的信息指定,而ChatSim非常精确地捕捉了指令中所有的需求,并且支持对场景多种灵活的编辑操作以满足用户的各种需求,助力生成更加多元且关键的数据,满足生成corner cases的初衷。

Abstract Command
这是ChatSim在比较抽象的指令作为输入的情况下的执行结果。抽象的指令中并未指定具体需要被执行的操作是什么,但ChatSim准确地把握了实际的需求,将其解耦成了多个可以被直接执行的操作,并且在这个场景中,motion规划的部分也为每辆车规划出了合适的轨迹,以达到模拟拥堵场景的效果。

Multi-round interaction
这是ChatSim在多轮指令下的生成效果。ChatSim可以在已有指令的基础上继续输入指令,以便于在已有的生成结果中进行进一步的调整。此处的多轮指令并非相互独立的,而是相互之间有一定的依赖关系,而chatsim的设计中考虑了对场景的记忆,能够依据场景信息进行调整,从而根据不同的需要多轮次调节生成结果。

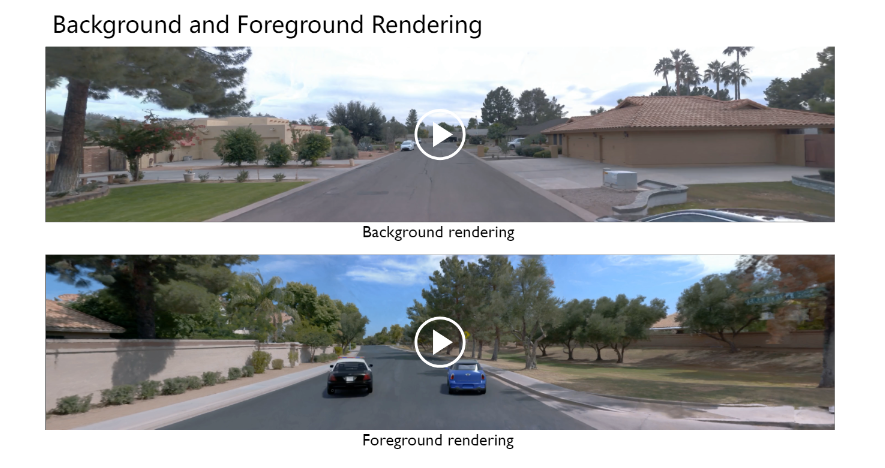
Background and Foreground Rendering
此外,作者也展示了ChatSim中所使用的背景与前景渲染的效果,分别使用文中提出的McNeRF与McLight进行。可以看到,McNeRF实现了多视角输入下对更大范围场景的高质量重建渲染,并在多摄像机的overlap处保持了高度的一致性,有效地抑制了阴影和色车问题。下图中的McLight则准确地提取了场景的光照信息,能够对引入的数字资产添加与场景高度贴合的光照使其更加符合场景,在合适的数字资产介入下生成了高度真实的光泽与阴影效果。
Background Rendering Comparison
这里展示的是McNeRF的相关对比结果。可以看出,McNeRF在可视化结果中显著优于其他方法,并在多个相机的overlap区域保持了高度的一致性,而其他方法由于不精确的位姿和未能考虑曝光时间,而在overlap处产生了重影、色差等问题。同时在量化的结果上,McNeRF也能够在所有指标上一致地提升性能表现并优于其他方法,同时对两个不同的设计进行了消融,验证了他们在量化结果上的表现。

Background Rendering Ablation
这里进一步展示了McNeRF消融实验的可视化结果。可以看出来在没有pose alignment的情况下,相机输入的重叠处出现了严重的模糊、重影,而在没有exposure的情况下,相机输入的重叠处处都出现了明显的色彩不一致,这与量化的实验结果是完全符合的。而完整的McNeRF则能够一致地渲染整个场景,在overlap处依然保持了良好的效果。

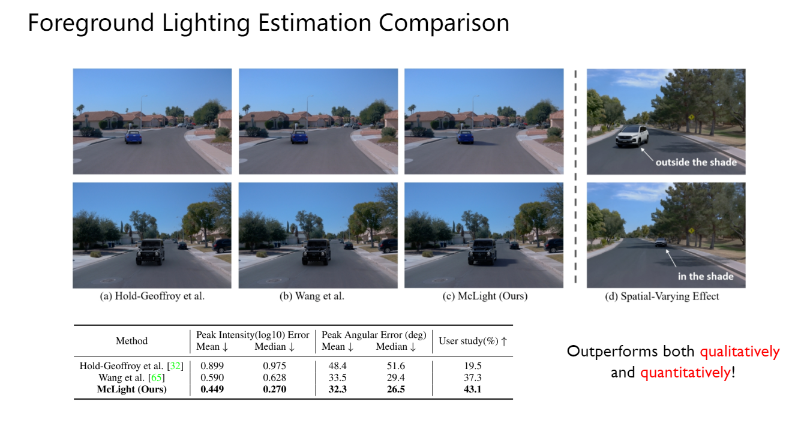
Foreground Lighting Estimation Comparison
这是McLight的相关结果。在可视化结果中,McLight与其他baseline相比能够为物体生成最真实的光照与影子效果,高度贴合场景本身。右侧的可视化中能看出,由于McLight考虑了McNeRF提供的具体位置处的周围物体的光照信息,McLight能够实现对场景内其他物体光照影响的感知,从而在同一场景下的阴影处的光照更加暗淡,阳光处更加明亮。量化的结果也显示,McLight在所有指标上都显著领先其他baselines,实现了最新的SoTA。
· Foreground Rendering with Occlusion
这里展示了文章在添加前景物体时采用的遮挡处理策略。对3D场景编辑的遮挡处理是无法回避的问题,场景中部分位置的添加需要考虑其他物体的遮挡。作者首先用SAM找到放置车辆位置附近的物体patch,随后使用了点云的稀疏深度对patch的深度进行了估计,并依据最终的估计结果按patch level计算遮挡。可以看到最终能够取得不错的遮挡处理效果,高度贴合场景。

· Other Objects
ChatSim在提供了合适数字资产的情况下,可以模拟更多道路场景,能够向场景中添加推土机、混凝土挡板、挖掘机等各种其他在道路中可能可以见到的物体。这些情况虽然可见,但在实际生活中可能并不方便采集,而这些少见的情况往往就是自动驾驶系统表现不佳的情况。这样的生成过程可以帮助生成更多道路中可见但相对难以采集的情况,提供更加有价值的数据。

Other Experiments
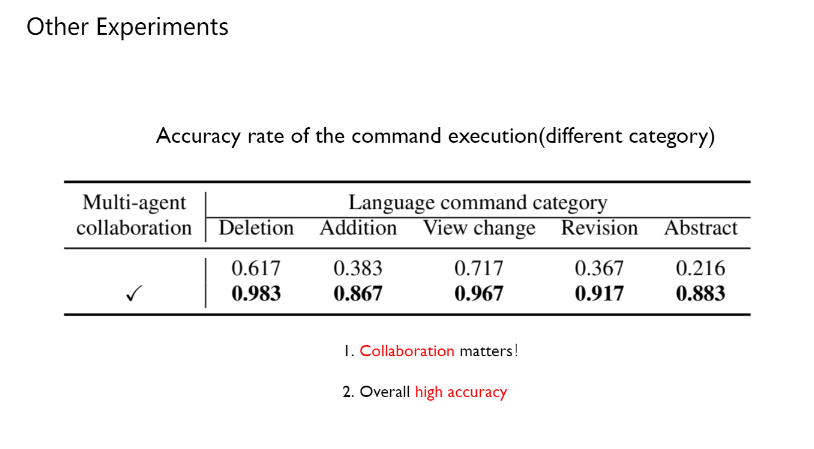
首先作者验证了ChatSim中多智能体协作对于指令完成准确度的影响,可以看到借助协作,ChatSim能以极高的准确率完成各种指令,并且相对于没有协作的情况有显著的提升。总体而言在表达清晰合理的情况下,ChatSim都能准确地理解需求并得到相应的操作加以执行。由此验证了多智能体协作设计的必要性以及chatsim整体的可靠性。
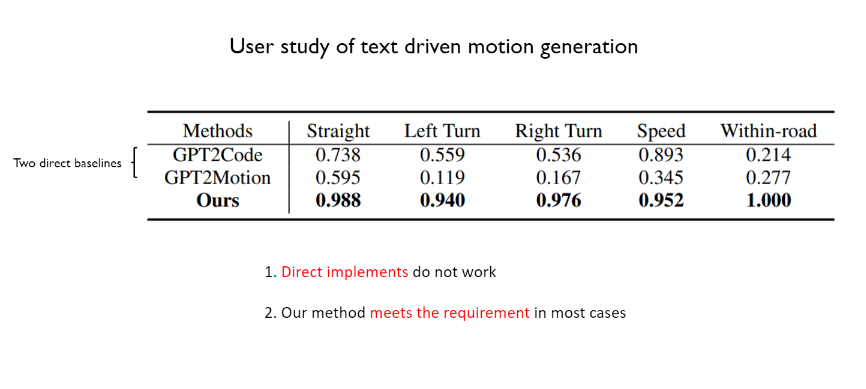
同时,文章也对自然语言驱动的motion generation进行了用户调研,可以看出作者采用的motion generation方案在多数情况下都能极大程度让用户人为符合自然输入,并显著优于其他两种直接的baselines,分别是由GPT生成代码再指定代码得到motion和由GPT直接得到motion。这两种直接的方式并不是非常有效。
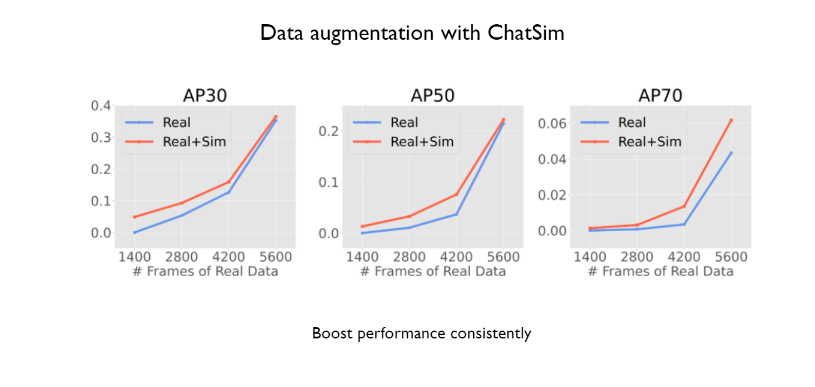
最后作者还使用ChatSim进行了数据增强的验证,通过使用ChatSim生成了部分数据与真实的数据混合对同样的检测模型进行训练,可以看到ChatSim的帮助下,在数据量不足时能够获得一致的性能增益。
本篇文章由陈研整理
点击“阅读原文”跳转到02:08:16
可以查看回放哦!
往期精彩文章推荐

论文解读 | CVPR2024:统一且通用的视频分割大模型
记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1800多位海内外讲者,举办了逾600场活动,超700万人次观看。

我知道你
在看
哦
~
提出观点,表达想法,欢迎
留言
哦
~

点击 阅读原文 查看回放!


















 315
315

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









