






点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
01
Mixture of A Million Experts
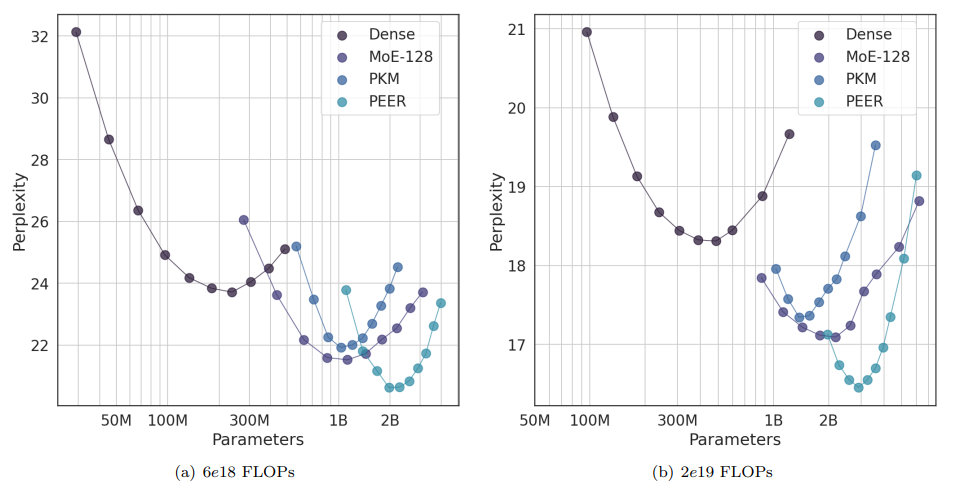
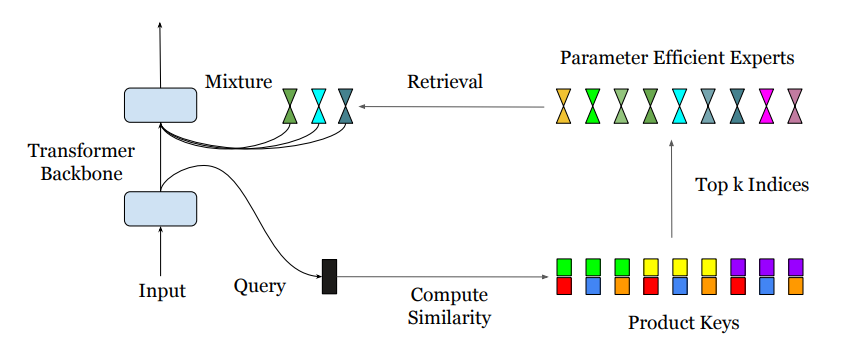
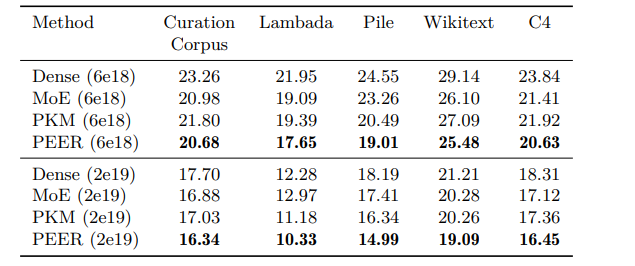
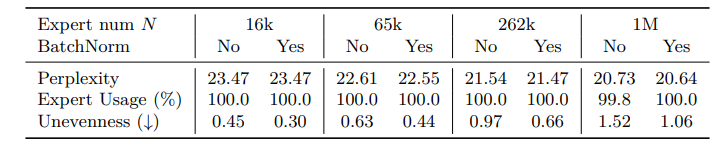
这篇论文探讨了稀疏的混合专家(MoE)架构,旨在解决传统图自注意力模型在隐藏层宽度增长时计算成本和激活记忆呈线性增加的问题。通过使用产品键技术,论文提出了PEER层设计,可以在大规模专家池中实现高效的检索,而不受到计算资源和优化问题的限制,这为大型模型进一步扩展和提高性能发挥了潜力。PEER层在语言建模任务上证明了与密集的前馈层和粗糙的MoE层相比,在性能和计算效率之间取得了更好的权衡。

文章链接:
https://arxiv.org/pdf/2407.04153
02
SoftDedup: an Efficient Data Reweighting Method for Speeding Up Language Model Pre-training
本文针对大型语言模型(LLMs)在广泛预训练数据集中的有效性受到重复数据影响的问题,进行了一项研究。当前方法主要集中在检测和删除重复数据,这可能导致有价值信息的丢失,并忽略了复制的不均匀程度。基于此,该论文提出了一种软去重方法,该方法在不破坏数据完整性的同时,通过选择性地减少高度重复数据的采样权重,有助于减少所需的训练步骤。该论文引入了“数据重复度”这一度量,通过n-gram模型来衡量样本的出现概率,该方法在实验上显示了显著的训练效率提高,相较于传统方法至少节省了26%的训练步骤,同时在训练等时长的情况下游程准确率提高了1.77%。本文方法的一致性在严格去重数据集上也有表现,表明其潜力成为大型语言模型标准预训练过程的补充。

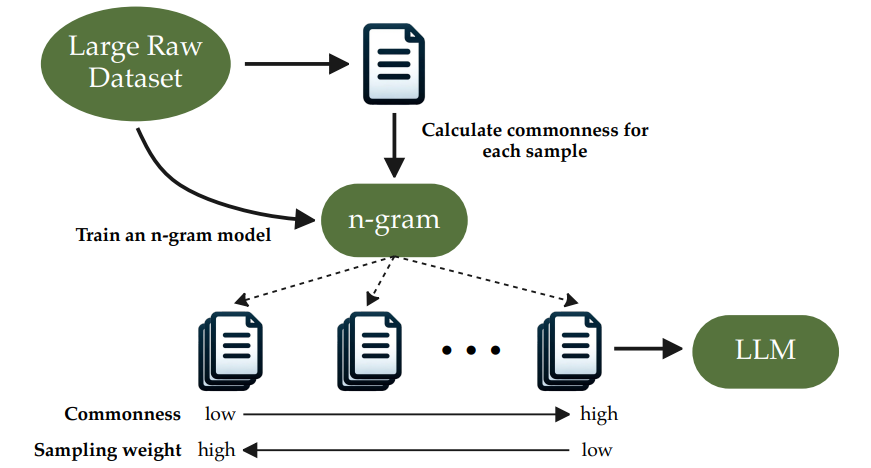



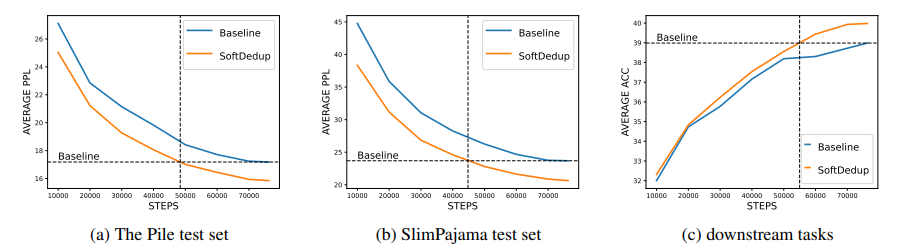
文章链接:
https://arxiv.org/pdf/2407.06654
03
Progress or Regress? Self-Improvement Reversal in Post-training
通过后训练方法(如迭代偏好学习)进行自我提升被认为能够在无需人类干预的情况下增强大型语言模型(LLMs)的问题解决能力(例如,数学推理)。然而,随着探索的深入,评估这些改进是否真正意味着在解决更具挑战性的问题方面取得了进展,或者是否可能导致意外的退步,变得至关重要。为此,本文提出了一个全面的评估框架,不仅仅依赖于表面的 pass@1 指标,而是深入审视后训练范式的自我提升的潜在改进。通过在各种问题解决任务上进行严格的实验和分析,实证结果指出了自我提升逆转的现象,即模型在基准测试中表现出改进,但在更广泛和重要的能力(如输出多样性和超出分布(OOD)泛化)上却出现了矛盾的下降。这些发现表明,当前通过后训练进行的自我提升实践不足以使模型能够应对更复杂的问题。此外,它们还强调了关键评估指标的重要性,以区分自我提升的 LLMs 是在进步还是退步。

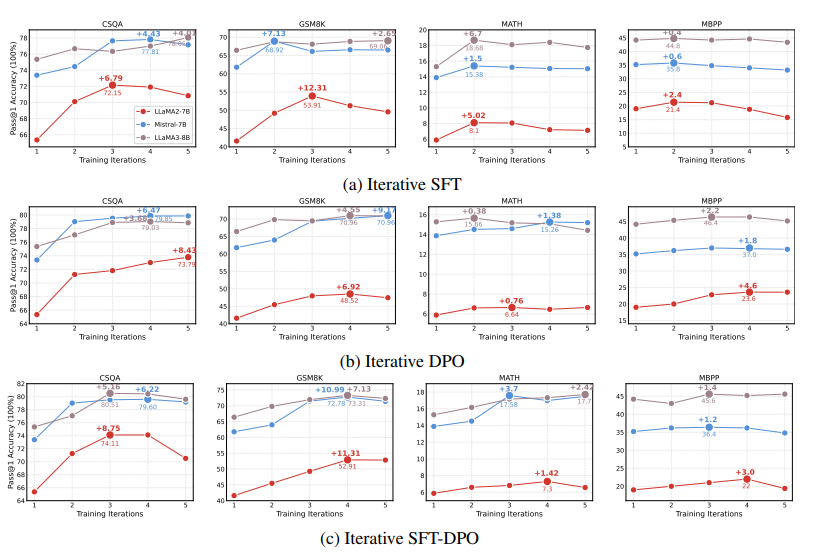
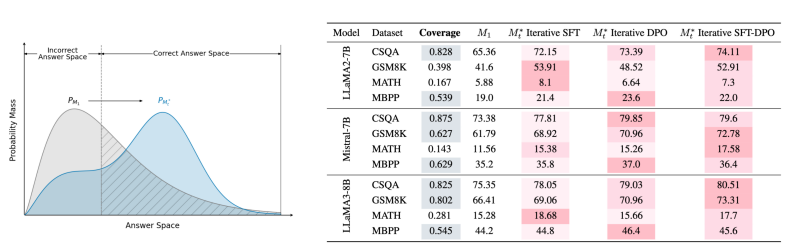
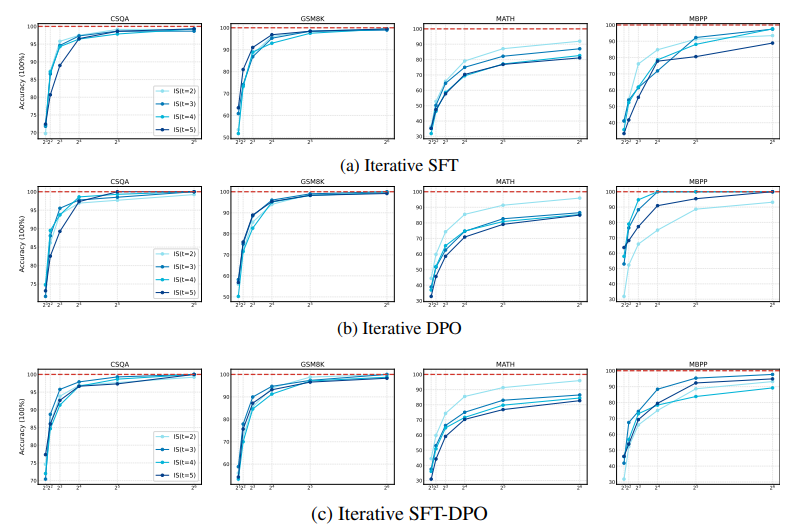
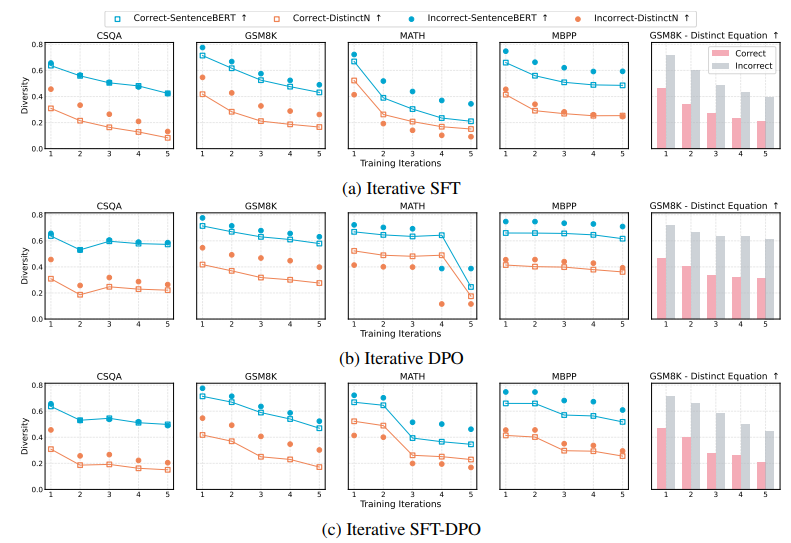

文章链接:
https://arxiv.org/pdf/2407.05013
04
RodinHD: High-Fidelity 3D Avatar Generation with Diffusion Models
本文介绍了RodinHD,这是一种能够从肖像图像生成高保真3D头像的方法。现有方法难以捕捉诸如发型等复杂细节,而本论文中解决了这一问题。首先,作者识别出在对多个头像依次拟合三平面时,由于MLP解码器共享方案而产生的灾难性遗忘问题。为了解决这个问题,本文提出了一种新颖的数据调度策略和一个权重巩固正则项,以提升解码器渲染更细锐细节的能力。此外,文章通过计算更细粒度的层次化表示来优化肖像图像的指导效果,这种表示捕捉了丰富的2D纹理线索,并通过交叉注意力将其注入到3D扩散模型的多个层中。在对46,000个头像进行训练并针对三平面优化噪声调度后,所得到的模型能够生成比以往方法更好细节的3D头像,并能推广到自然环境中的肖像输入。

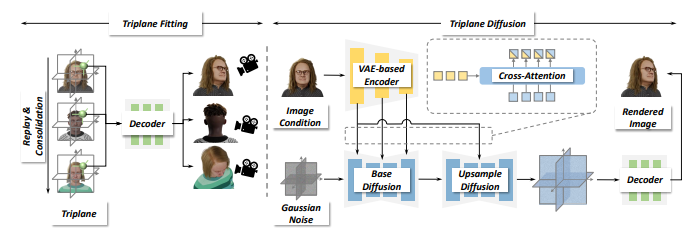
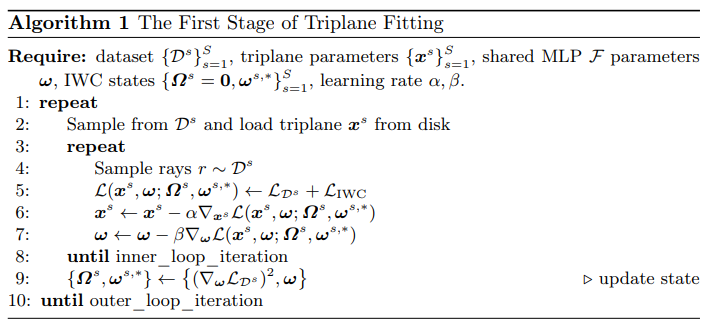
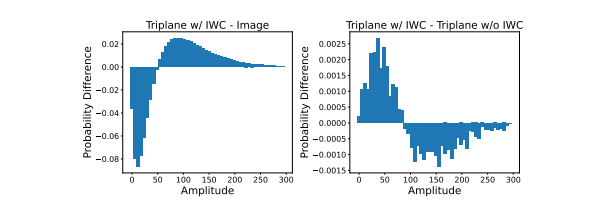

文章链接:
https://arxiv.org/pdf/2407.06938
05
Re-Tuning: Overcoming the Compositionality Limits of Large Language Models with Recursive Tuning
本文提出了一种用于大型语言模型解决组合任务的新方法。尽管大型语言模型在传统语言理解任务中表现出色,但在解决组合任务时却存在困难,这些任务的解决依赖于解决同一问题的更小实例。文章提出了一种自然的方法来递归地解决组合任务。Re-Tuning,通过调整模型将问题分解为子问题,解决这些子问题,并结合结果。本文展示了该方法在三个具有代表性的组合任务(整数加法、动态规划和奇偶性)上显著提高了模型性能。与保留问题解决中间步骤的最先进方法相比,Re-Tuning 在准确性上有显著提升,并且更加节省GPU内存。
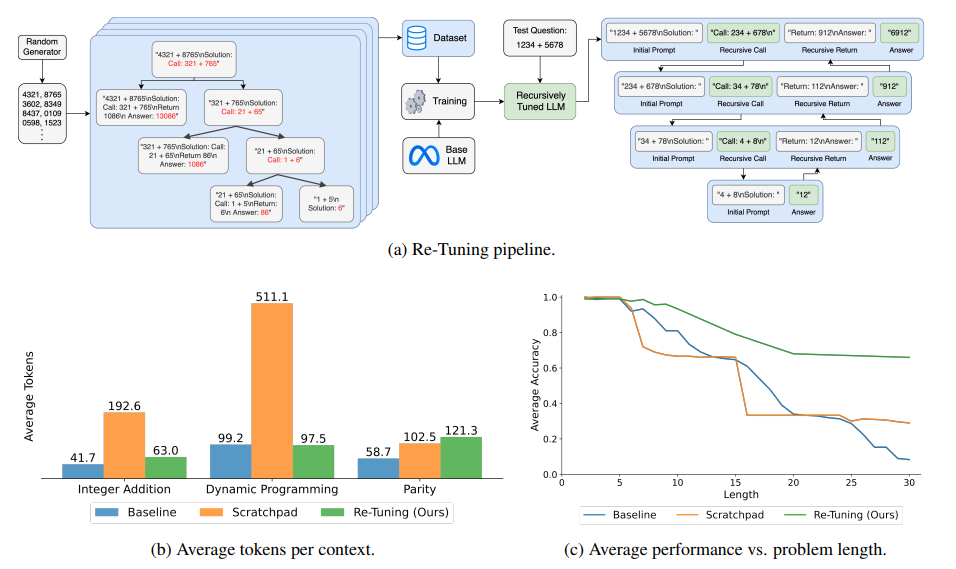
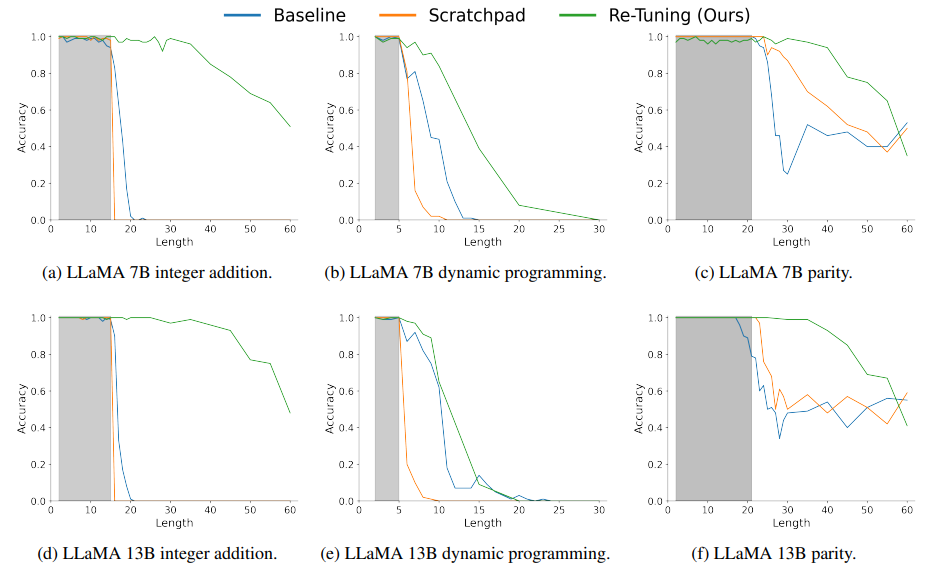

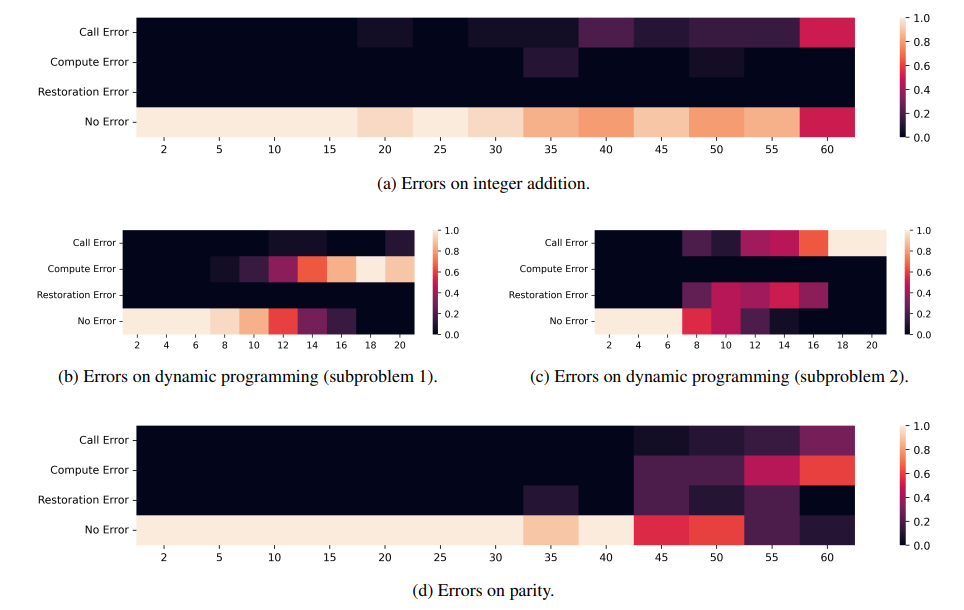
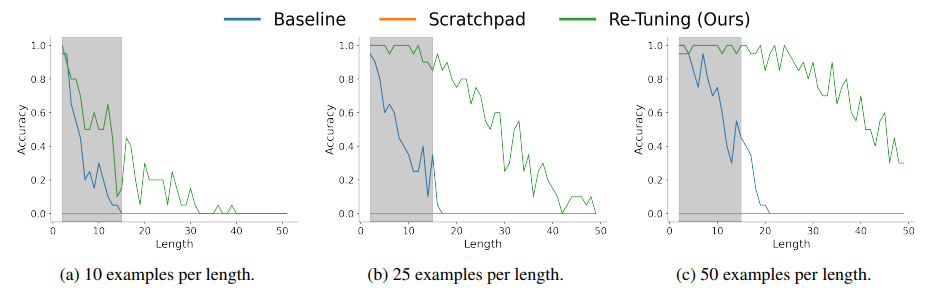
文章链接:
https://arxiv.org/pdf/2407.04787
06
MAPO: Boosting Large Language Model Performance with Model-Adaptive Prompt Optimization
提示工程作为一种高效利用大型语言模型(LLM)的方式,引起了研究界的广泛关注。现有研究主要强调将提示适配于特定任务的重要性,而非特定的LLM。然而,一个好的提示不仅仅由其措辞定义,还与所用LLM的性质紧密相关。这项工作首先定量证明了不同的提示应适应不同的LLM,以增强它们在各种自然语言处理下游任务中的能力。然后,本文新提出了一种模型自适应提示优化器(MAPO)方法,该方法针对每个特定的LLM优化原始提示以用于下游任务。大量实验表明,所提出的方法能够有效优化LLM的提示,从而在各种下游任务中实现显著的性能提升。
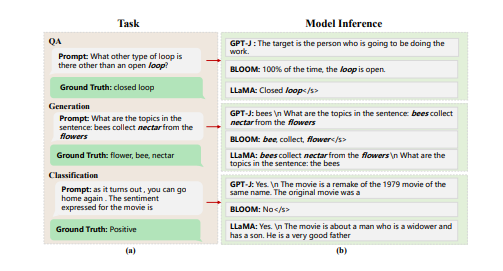
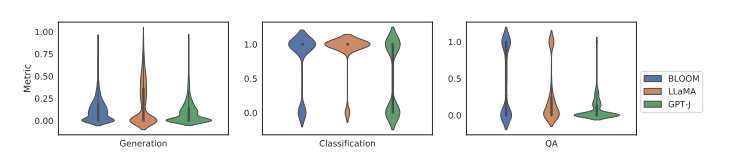
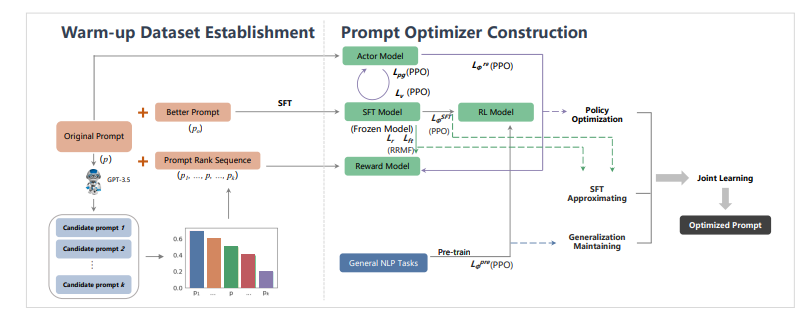


文章链接:
https://arxiv.org/pdf/2407.04118
07
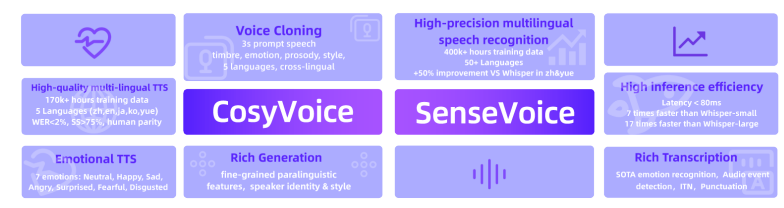
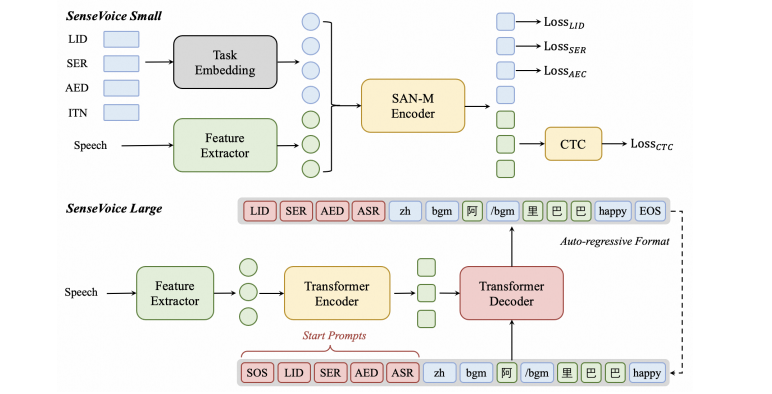
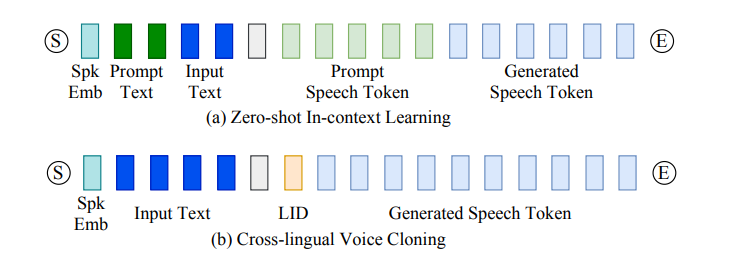
FunAudioLLM: Voice Understanding and Generation Foundation Models for Natural Interaction Between Humans and LLMs
提示工程作为一种高效利用大型语言模型(LLM)的方式,引起了研究界的广泛关注。现有研究主要强调将提示适配于特定任务的重要性,而非特定的LLM。然而,一个好的提示不仅仅由其措辞定义,还与所用LLM的性质紧密相关。这项工作首先定量证明了不同的提示应适应不同的LLM,以增强它们在各种自然语言处理下游任务中的能力。然后,作者新提出了一种模型自适应提示优化器(MAPO)方法,该方法针对每个特定的LLM优化原始提示以用于下游任务。大量实验表明,所提出的方法能够有效优化LLM的提示,从而在各种下游任务中实现显著的性能提升。



文章链接:
https://arxiv.org/pdf/2407.04051
本期文章由陈研整理
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1800多位海内外讲者,举办了逾600场活动,超700万人次观看。

我知道你
在看
欢迎讨论,期待你的
留言

点击 阅读原文 查看更多!
















 622
622











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









