







点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
点击阅读原文观看作者直播讲解回放!
作者简介
孙洲浩,哈尔滨工业大学SCIR实验室博士生
概述
尽管大语言模型(LLMs)展现出了非常强大的能力,但它们仍然面临与各种偏见相关的挑战。传统的自动去偏见方法主要针对判别式模型,在应对生成式LLMs固有的复杂偏见方面存在困难。为了解决这些局限性,作者设计了因果指导的主动学习方法来自动自主地识别LLMs的偏见模式并减轻LLMs的偏见。具体来说,首先通过因果不变理论揭示了语义信息和偏见信息的本质区别,然后据此自动识别有偏数据并归纳可解释的偏见模式,最终利用这些识别出的有偏数据和偏见模式通过上下文学习的方法来减轻LLMs的偏见。实验结果表明,所提出的因果主动学习方法能够有效地识别有偏数据并归纳可解释的偏见模式,并利用有偏数据和偏见模式对LLMs进行去偏。
论文地址:https://www.arxiv.org/abs/2408.12942
代码地址:https://github.com/spirit-moon-fly/CAL
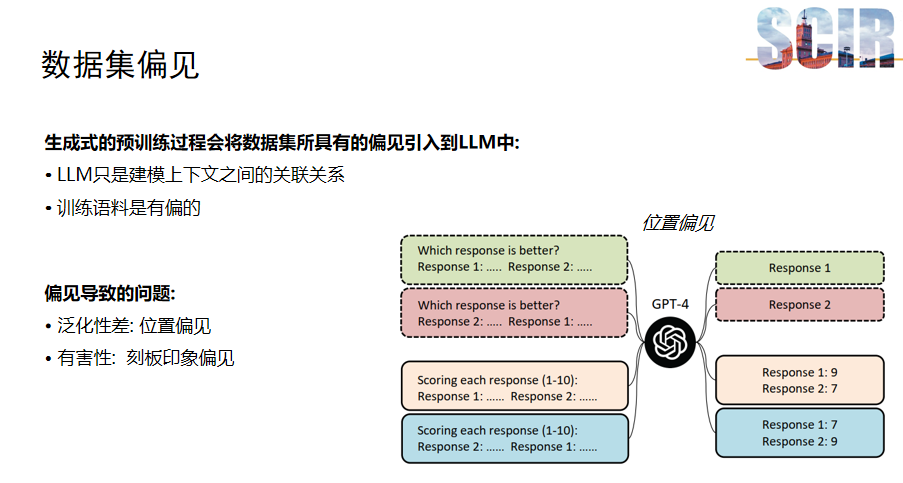
数据集偏见
生成式大模型近年来因其强大的能力而广受欢迎。然而,这些模型在预训练过程中可能会吸收数据集中的偏见。由于生成式大模型通过预测上下文中下一个词的概率来进行训练,因此大模型仅仅被动地捕捉上下文之间的关联性。如果训练数据存在偏见,这种关联性也会被模型所学习,从而导致模型泛化能力下降,并可能对社会造成负面影响。
例如,如果模型存在位置偏见,它可能会错误地认为问题中的第一个选项总是正确的,即使在某个数据集中正确答案通常位于第二个位置。这种偏见会影响模型的泛化能力。此外,刻板印象偏见,如性别或种族偏见,也可能通过模型的输出反映出来,对社会造成潜在的负面影响。
前人工作与动机
去偏化研究主要分为两大类方法:基于先验知识的去偏方法和自动去偏方法
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 461
461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









