







点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
01
REInstruct: Building Instruction Data from Unlabeled Corpus
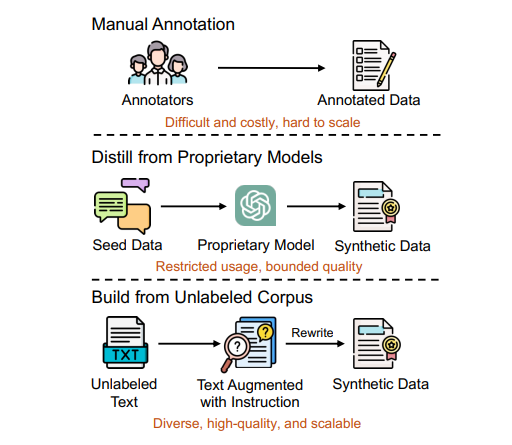
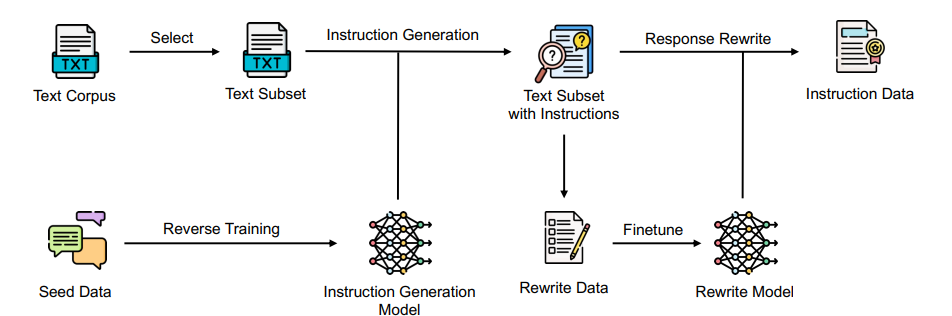
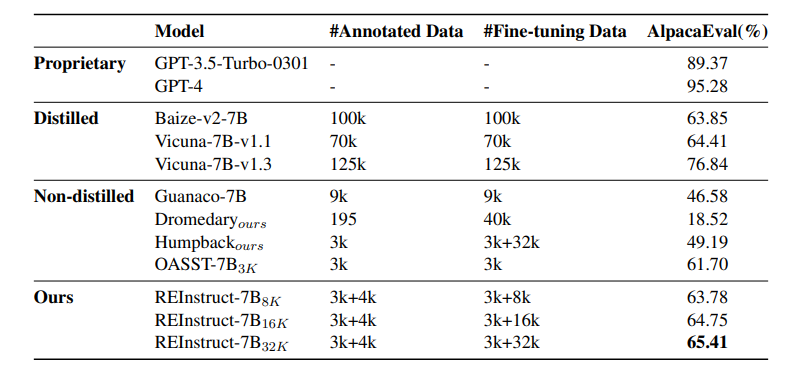
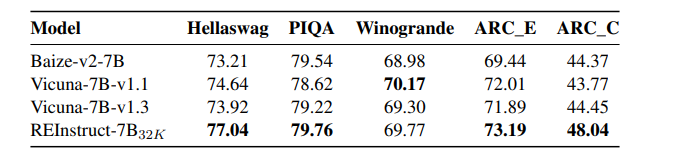
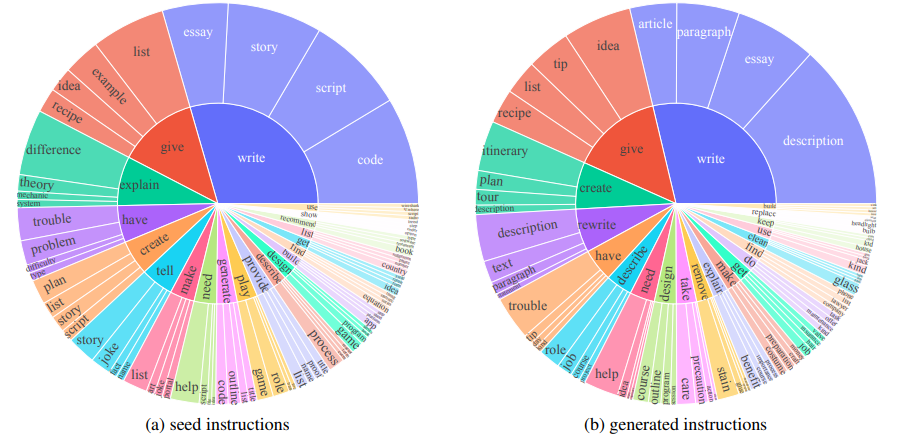
手动为大语言模型标注指令数据既困难又昂贵,而且难以扩展。同时,当前的自动标注方法通常依赖于从专有LLMs提炼合成数据,这不仅限制了指令数据质量的上限,还可能引发潜在的版权问题。本文提出了REInstruct,这是一种简单且可扩展的方法,用于从未标注语料中自动构建指令数据,而无需过度依赖专有LLMs和人工标注。具体而言,REInstruct首先选择一部分未标注文本,这些文本可能包含结构良好、有帮助且有见解的内容,然后为这些文本生成指令。为了生成准确且相关的响应以进行有效和稳健的训练,REInstruct进一步提出了一种基于重写的方法,以提高生成的指令数据的质量。通过将Llama-7b在3k种子数据和32k来自REInstruct的合成数据上进行训练,微调后的模型在AlpacaEval排行榜上对抗text-davinci003时达到了65.41%的胜率,优于其他开源、非蒸馏的指令数据构建方法。

文章链接:
https://arxiv.org/pdf/2408.10663
02
LongVILA: Scaling Long-Context Visual Language Models for Long Videos
长上下文处理能力对于多模态基础模型,特别是长视频理解至关重要。本文介绍了LongVILA,这是一种为长上下文视觉语言模型提供的全栈解决方案,通过共同设计算法和系统实现。在模型训练方面,LongVILA通过引入两个额外的阶段,即长上下文扩展和长监督微调,将现有的视觉语言模型(VLMs)升级,以支持长视频理解。然而,长视频的训练在计算和内存上都非常密集。为此,作者提出了长上下文多模态序列并行(MM-SP)系统,该系统高效地并行化了长视频的训练和推理,支持在256个GPU上进行2M上下文长度的训练,无需任何梯度检查点。LongVILA有效地将VILA的视频帧数从8扩展到1024,将长视频字幕评分从2.00提高到3.26(满分为5),并在1400帧(274k上下文长度)的视频“针找稻堆”任务中实现了99.5%的准确率。LongVILA-8B在VideoMME基准测试中,随着视频帧数的增加,在长视频上的准确率也持续提升。此外,MM-SP比环序列并行快2.1倍至5.7倍,比Megatron的上下文并行+张量并行快1.1倍至1.4倍。而且,它可以无缝集成到Hugging Face Transformers中。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 505
505

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









