






点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
01
A Teacher Is Worth A Million Instructions
大型语言模型(LLMs)正日益在包含自然语言和非语言数据(例如源代码)的语料库上进行训练。除了辅助编程相关任务,还有轶事证据表明,在预训练语料中加入代码可能提升模型在其他不相关任务上的性能,但迄今为止,尚无研究能够通过控制语言和代码数据之间建立因果联系。本文正是为了解决这一问题。作者在两种不同的设置中对语言模型进行了预训练:竞争性设置,其中预训练期间看到的数据总量保持不变;以及累加性设置,其中语言数据的体积保持不变。本研究探讨了预训练混合对以下方面性能的影响:(a)BigBench基准测试中包含的多种任务的集合,以及(b)通过语义解析和句法转换上的泛化准确率来衡量的组合性。研究发现,较高比例的代码预训练能够提升涉及结构化输出(如语义解析)和数学的组合任务的性能。相反,增加代码混合可能会损害其他任务的性能,包括那些需要对语言结构敏感的任务,如句法或形态学,以及测量现实世界知识的任务。
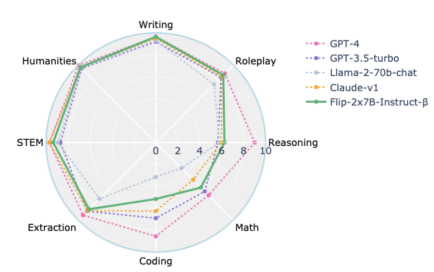
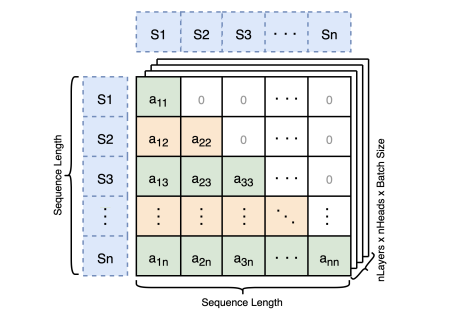
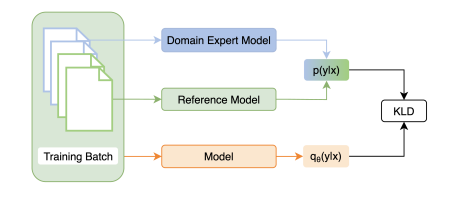
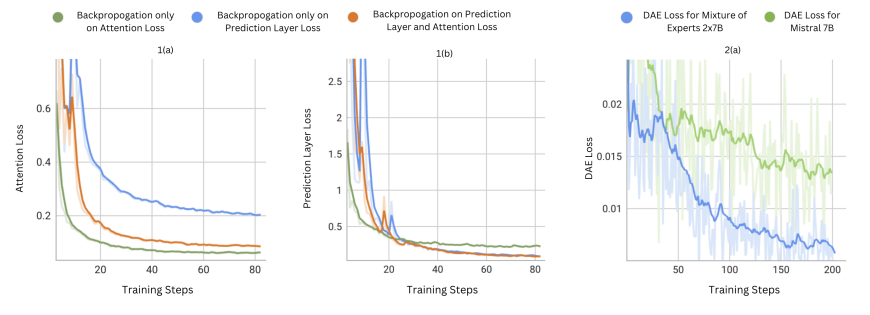
文章链接:
https://arxiv.org/pdf/2406.19112
02
Unlocking Continual Learning Abilities in Language Models
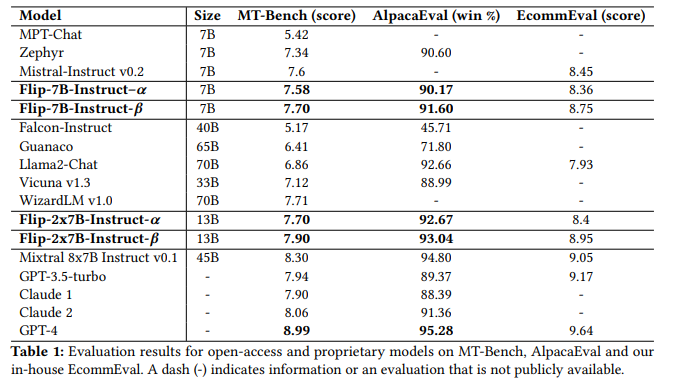
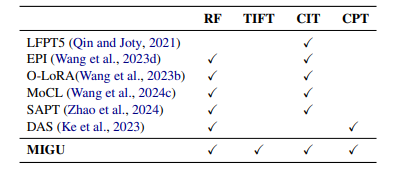
语言模型(LMs)展现出了令人印象深刻的性能和泛化能力。然而,LMs在持续学习(CL)中长期可持续性面临着灾难性遗忘这一持久挑战。现有方法通常通过将旧任务数据或任务内归纳偏好整合到LMs中来解决这一问题。然而,旧数据和准确的任务信息往往不可用或收集成本高昂,这阻碍了当前CL方法在LMs中的应用。为了解决这一局限性,本研究介绍了“MIGU”(基于幅度的梯度更新方法,用于持续学习),这是一种无需复习和无需任务标签的方法,它只更新LMs线性层中输出幅度较大的模型参数。MIGU基于作者的观察,即当LM模型处理不同任务数据时,LMs线性层输出的L1归一化幅度分布是不同的。通过对梯度更新过程施加这一简单约束,本研究利用了LMs的固有行为,从而解锁了它们固有的CL能力。实验表明,MIGU普遍适用于所有三种LM架构(T5、RoBERTa和Llama2),在四个CL基准的持续微调和持续预训练设置中提供了最先进的或相当的性能。例如,在15个任务的CL基准中,MIGU带来了比传统参数高效的微调基线平均准确率提高了15.2%。MIGU还可以与所有三种现有的CL类型无缝集成,以进一步提高性能。
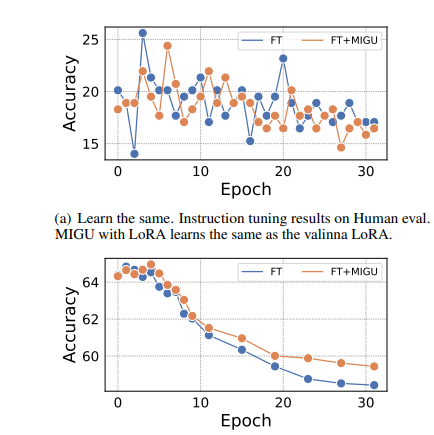
文章链接:
https://arxiv.org/pdf/2406.17245
03
Efficient Continual Pre-training by Mitigating the Stability Gap
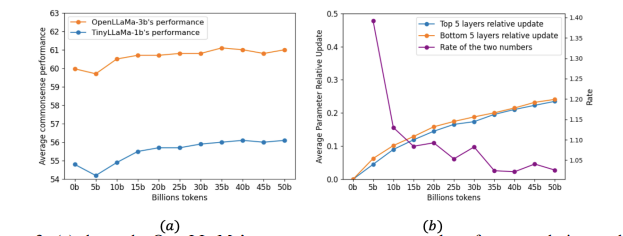
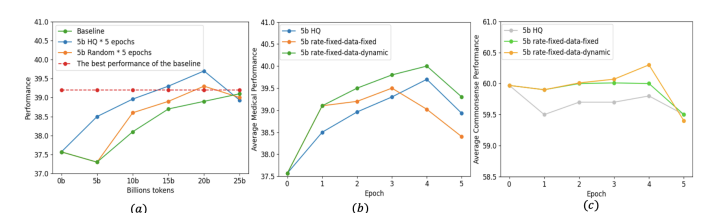
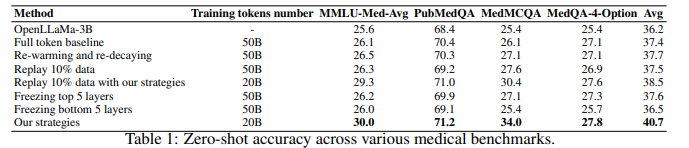
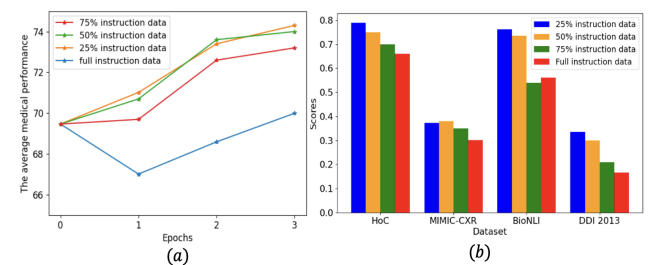
持续预训练已成为使大型语言模型(LLMs)适应新领域的主导方法。这一过程涉及使用新领域的语料库更新预训练的LLM,导致训练分布发生转变。为了研究LLMs在这一转变期间的行为,作者测量了模型在整个持续预训练过程中的表现。观察到在开始时会出现暂时性的表现下降,随后是恢复阶段,这种现象被称为“稳定性差距”,在视觉模型对新类别进行分类时已经有所注意。与这一差距相关的显著表现下降和缓慢恢复导致了领域表现提升的预训练效率低下,以及对一般任务知识的遗忘。为了解决这个问题并在固定的计算预算内提高LLM性能,作者提出了三种有效的策略:(1)持续预训练LLM在适当大小的子集上进行多个周期,比在单个周期内对大型语料库进行预训练能够更快地恢复表现;(2)只对高质量的子语料库进行预训练,这可以迅速提升领域表现;以及(3)使用与预训练数据类似的数据混合来减少分布差距。作者在Llama家族模型上进行了各种实验,以验证这些策略在医学持续预训练和指令调整中的有效性。例如,这些策略将OpenLlama-3B模型在医学任务上的平均表现从36.2%提高到40.7%,仅使用了原始训练预算的40%,并在不引起遗忘的情况下提高了平均一般任务表现。此外,作者将这些策略应用于持续预训练和指令调整Llama-3-8B模型。由此产生的模型Llama3-Physician在当前开源模型中实现了最佳的医学表现,并在几个医学基准测试中与GPT-4相比表现相当甚至更好。
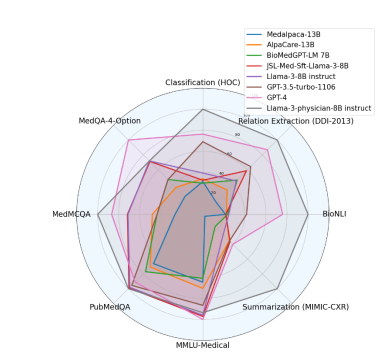
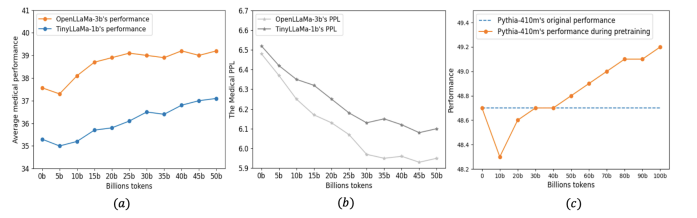
文章链接:
https://arxiv.org/pdf/2406.14833
04
Following Length Constraints in Instructions
与未对齐的模型相比,对齐指令遵循模型能更好地满足用户的请求。然而,已有研究表明,在评估这类模型时存在长度偏见,而且训练算法倾向于利用这种偏见通过学习更长的回答来实现。这项工作展示了如何训练可以在推理时通过包含期望长度约束的指令进行控制的模型。这样的模型在长度指导评估中表现更优,超过了标准指令遵循模型,如GPT-4、Llama 3和Mixtral。

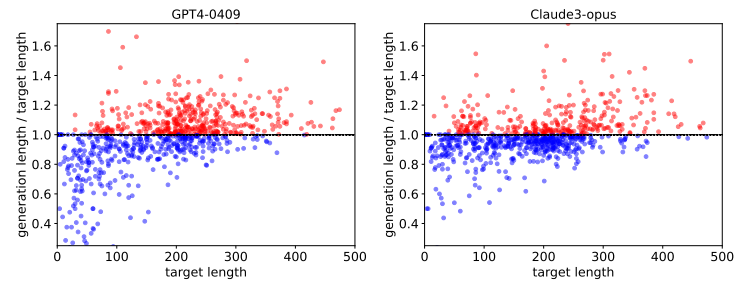
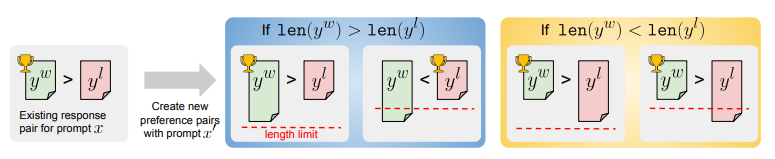
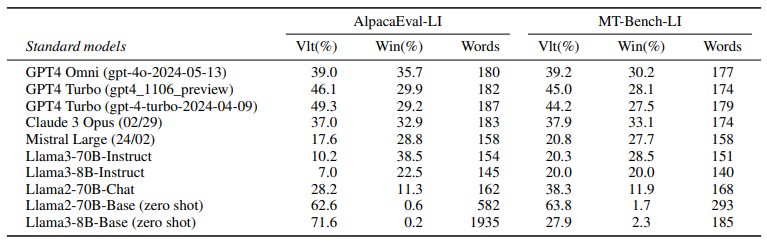
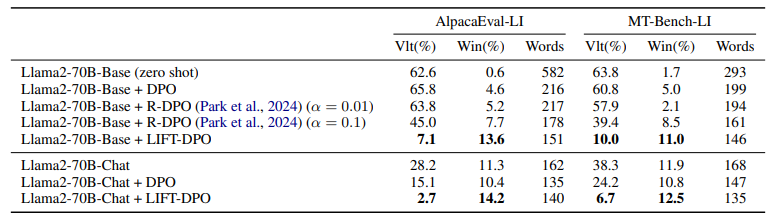
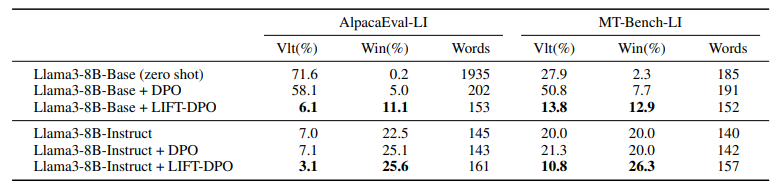
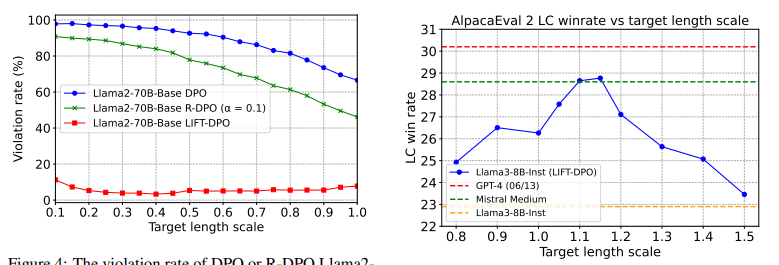
文章链接:
https://arxiv.org/pdf/2406.17744
05
Recite, Reconstruct, Recollect: Memorization in LMs as a Multifaceted Phenomenon
在语言模型中,记忆通常被视为一个单一的现象,忽略了所记忆数据的具体特征。相反,本文将记忆建模为一系列复杂因素的效应,这些因素描述了每个样本并将其与模型和语料库联系起来。为了围绕这些因素建立直观的理解,作者将记忆分解为一个分类体系:高度重复序列的背诵、固有可预测序列的重建,以及既不重复也不可预测序列的回忆。通过使用这个分类体系构建预测记忆的模型,本文展示了其有用性。通过分析依赖关系并检查预测模型的权重,本研究发现不同的因素根据不同的分类类别以不同的方式影响记忆的可能性。
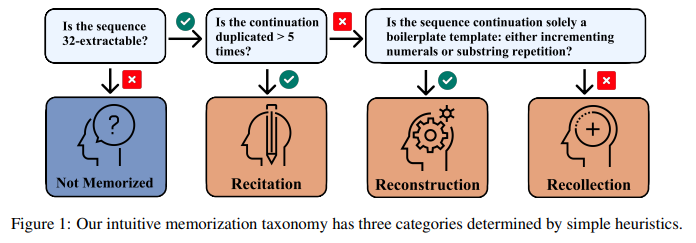
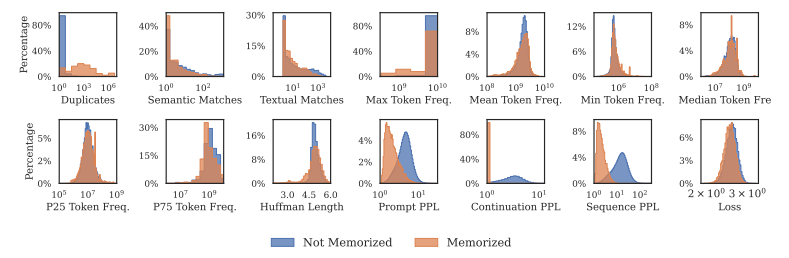
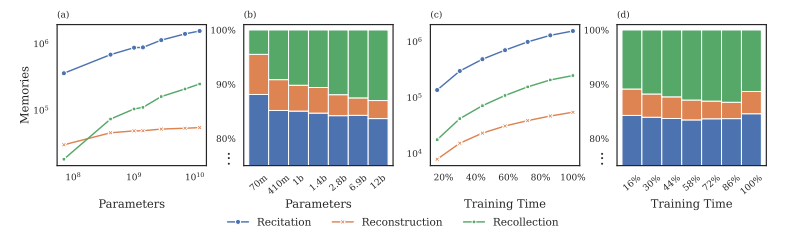
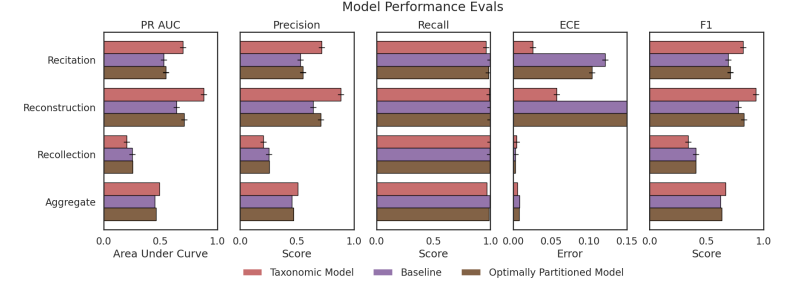
文章链接:
https://arxiv.org/pdf/2406.17746
06
Data curation via joint example selection further accelerates multimodal learning
数据策划是大规模预训练的一个关键组成部分。在本研究中,作者展示了联合选择数据批次对于学习比独立选择示例更有效。多模态对比目标揭示了数据之间的依赖性,因此自然地提供了衡量批次联合可学习性的准则。本文推导出一个简单且可行的算法来选择这样的批次,这显著加速了训练,超越了单独优先级数据点。随着从更大的超级批次中选择可以提高性能,作者还利用了模型近似的最新进展来减少相关的计算开销。结果,本研究的方法——多模态对比学习与联合示例选择(JEST)——以多达13倍更少的迭代和10倍更少的计算量超越了最先进的模型。JEST性能的关键是通过预训练的参考模型将数据选择过程引导到较小、策划良好的数据集的分布,从而将数据策划的水平作为神经网络规模法则的一个新维度。
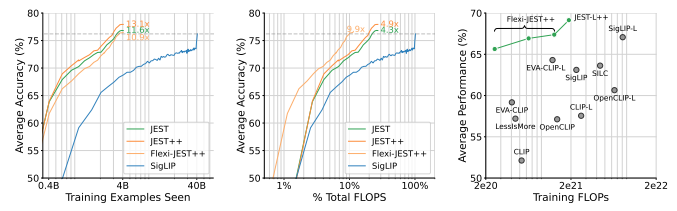

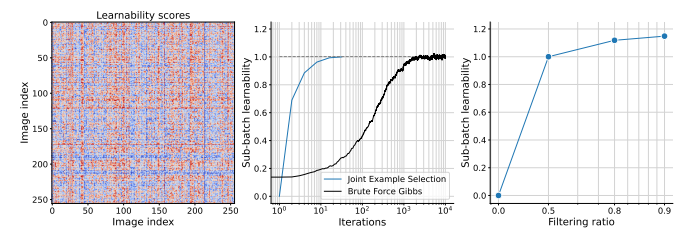
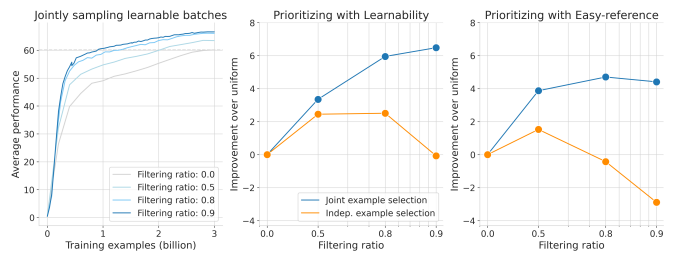
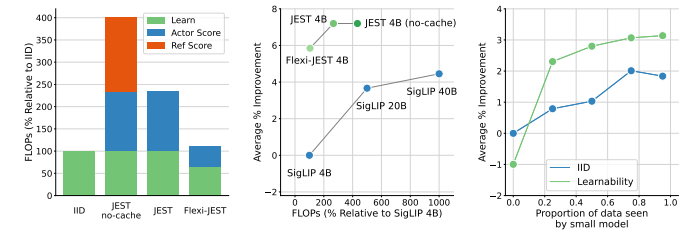
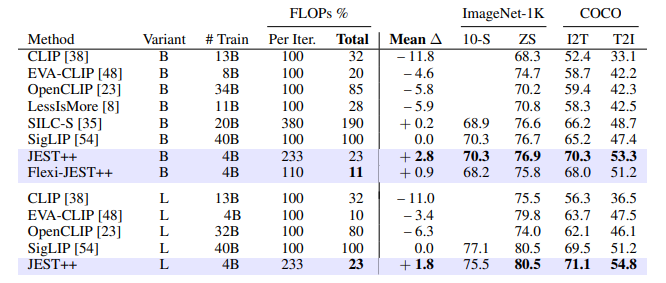
文章链接:
https://arxiv.org/pdf/2406.17711
07
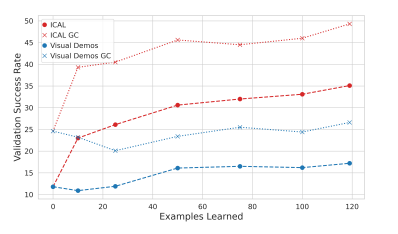
ICAL: Continual Learning of Multimodal Agents by Transforming Trajectories into Actionable Insights
大规模生成性语言和视觉-语言模型(LLMs和VLMs)在决策制定和指令遵循的少样本上下文学习中表现出色。然而,它们需要高质量的示例性演示才能包含在它们的上下文窗口中。在本研究中,作者提出了一个问题:LLMs和VLMs能否从通用的、次优的演示中生成自己的提示示例?本研究提出了上下文抽象学习(ICAL),这是一种从次优演示和人类反馈中构建多模态经验洞察记忆的方法。在新的领域中给定一个嘈杂的演示,VLMs通过修正效率低下的行动并注释认知抽象来将轨迹抽象成一个通用程序:任务关系、对象状态变化、时间子目标和任务构建。这些抽象通过人类反馈在代理尝试在类似环境中执行轨迹时进行交互式细化和调整。当这些抽象用作提示中的示例时,可以显著提高检索增强型LLM和VLM代理中的决策制定。ICAL代理在TEACh中的基于对话的指令遵循、VisualWebArena中的多模态网络代理以及Ego4D中的动作预测方面超越了最先进的水平。在TEACh中,本研究实现了目标条件成功率提高了12.6%。在VisualWebArena中,任务成功率从14.3%提高到22.7%。在Ego4D动作预测中,本研究超越了少样本GPT-4V,并保持与监督模型的竞争力。作者展示了对检索增强型上下文代理进行微调可以带来额外的改进。本研究的方法显著减少了对专家精心制作示例的依赖,并在缺乏此类洞察的行动计划中一致性地超越了上下文学习。

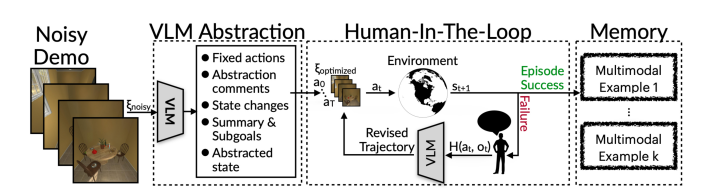
文章链接:
https://arxiv.org/pdf/2406.14596
本期文章由陈研整理
往期精彩文章推荐

关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了2000多位海内外讲者,举办了逾700场活动,超800万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 查看更多!


















 23
23

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









