






点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

点击 阅读原文 观看作者讲解回放!
作者及单位
作者:张中健,王啸,周辉池,于越,张梦玫,杨成,石川
单位:北京邮电大学,北京航空航天大学,帝国理工学院,中国电信翼支付
摘要
图神经网络(Graph Neural Networks, GNNs)对对抗攻击,尤其是针对图结构的扰动,具有较高的脆弱性。近年来,许多增强GNNs鲁棒性的方法得到了广泛关注。同时,我们也见证了大语言模型(Large Language Models, LLMs)的显著成功,这使得许多人开始探索LLMs在GNNs领域的潜力。然而,现有研究主要聚焦于通过LLMs提升节点特征,从而改进GNNs的性能。因此,我们提出一个问题:LLMs强大的理解和推理能力能否同样提升GNNs的鲁棒性?通过实证结果,我们发现尽管LLMs确实可以在一定程度上提高GNNs的鲁棒性,但在面对拓扑攻击时,GNNs的准确率仍然平均下降了23.1%,这表明GNNs在拓扑攻击下依然非常脆弱。因此,我们进一步提出另一个问题:如何扩展LLMs在图对抗鲁棒性上的能力?为了解决这一问题,本文提出了一种基于LLMs的鲁棒图结构推理框架——LLM4RGNN。该框架将GPT-4的推理能力蒸馏至一个局部的LLM,用于识别恶意边,同时使用一个基于语言模型的边预测器来寻找缺失的重要边,以恢复鲁棒的图结构。大量实验表明,LLM4RGNN在不同的GNNs上都能持续提升其鲁棒性。即使在扰动比例高达40%的一些情况下,GNNs的准确率甚至优于其在干净图上的表现。
论文链接:
https://arxiv.org/pdf/2408.08685
代码链接:
https://github.com/zhongjian-zhang/LLM4RGNN
1. 背景与动机
GNNs 作为图机器学习领域的代表方法,通过其消息传递机制高效提取有用信息,并从图数据中学习高质量表示。尽管取得了巨大成功,大量研究表明,GNN对对抗攻击极为脆弱,特别是针对图结构的攻击,仅需对图结构进行轻微扰动,就可能导致模型性能显著下降。这种脆弱性为GNNs在真实世界中的应用带来了重大挑战,尤其是在安全关键场景中,例如金融网络或医疗网络。
面对对抗攻击的威胁,研究者提出了多种增强GNN鲁棒性的方法,主要可分为模型中心的防御方法和数据中心的防御方法。从模型中心的视角来看,防御方法可以通过鲁棒训练方案或新的模型架构来提升模型的鲁棒性。相比之下,以数据为中心的防御方法通常关注于灵活的数据处理,以增强GNNs的鲁棒性。这类方法将被攻击的图结构视为噪声,通过计算节点嵌入之间的各种相似性来净化图结构。上述方法在增强GNNs鲁棒性方面都得到了广泛关注。
近年来,如以GPT-4为代表的LLMs在理解和推理复杂文本方面展现出了卓越的能力,革新了自然语言处理、计算机视觉和图领域。通过利用LLMs增强节点特征,GNN的性能得到了极大的提升。然而,一个问题仍然未被深入研究:考虑到LLMs强大的理解和推理能力,LLMs是否会在一定程度上增强或削弱GNNs的对抗鲁棒性?回答这一问题不仅有助于探索LLMs在图领域的潜在能力,还能为图对抗鲁棒性问题提供新的研究视角。
本文通过实证研究,考察了六种代表性的LLMs+GNNs的方法(OFA-Llama2-7B、OFA-SBert、TAPE、GCN-Llama-7B、GCN-e5-large和GCN-SBert)在Cora和PubMed数据集上,针对20%扰动率的Mettack的鲁棒性表现。如图1所示,结果显示这些模型的准确率最高下降37.9%,平均下降23.1%,对比Vanilla GCN的准确率最高下降39.1%,平均下降35.5%。这表明这些模型在面对拓扑扰动时仍然非常脆弱。因此,这里自然引出了另一个问题:如何扩展LLMs的能力以提高图对抗鲁棒性?回答这个问题并不简单,因为图对抗攻击通常通过扰动图结构实现,而LLMs的能力通常集中在文本处理上。考虑到图结构涉及大量节点之间的复杂交互,如何高效利用LLMs在扰动结构上的推理能力是一个重要的挑战。
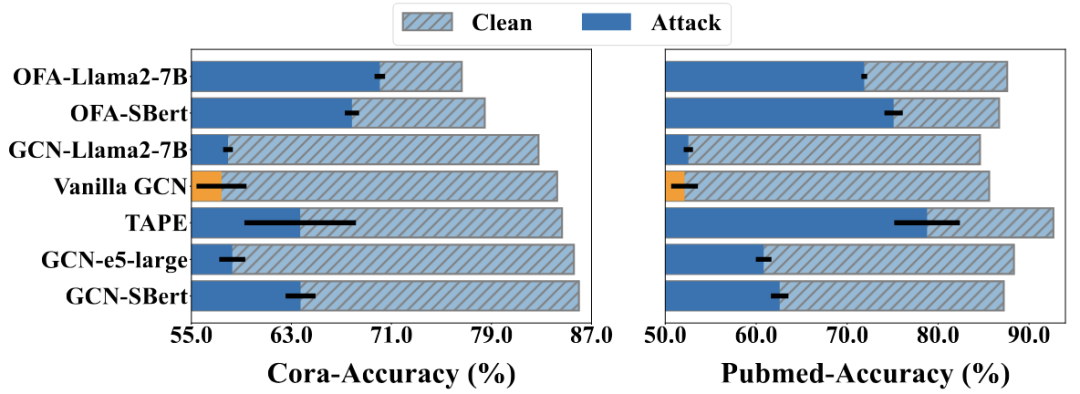
图1:不同LLMs+GNNs针对扰动率为20%的Mettack的准确性。
为此,本文提出了一种基于LLMs的鲁棒图结构推理框架LLM4RGNN,该框架高效利用LLMs净化被扰动的图结构,从而提高GNNs的对抗鲁棒性。具体而言,在一个开源且干净的图结构基础上,我们设计了一个提示模板,使GPT-4能够推断边的恶意程度并提供分析,来构建一个指令数据集。该数据集用于微调一个本地LLM(如Mistral-7B),从而将GPT-4的推理能力蒸馏至本地LLMs。当面对未知的被攻击的图结构时,我们首先利用本地LLMs识别恶意边。通过将识别结果视为边的标签,我们进一步将本地LLMs的推理能力蒸馏至一个基于语言模型的边预测器中,以寻找缺失的重要边。最后,通过移除恶意边并添加缺失的重要边来净化图结构,使各种GNNs更加鲁棒。我们的贡献可以总结为以下四点:
1. 据我们所知,本文是首次探索LLMs在图对抗鲁棒性上的潜力。此外,我们也验证了现有LLMs+GNNs的方法即便结合了LLMs强大的理解和推理能力,面对对抗攻击仍然非常脆弱。
2. 我们提出了一种新颖的基于LLMs的鲁棒图结构推断框架LLM4RGNN,该框架高效利用LLMs增强GNNs鲁棒性。此外,LLM4RGNN是一个通用框架,适用于不同的LLMs和GNNs。
3. 大量实验表明,LLM4RGNN面对拓扑攻击时一致地提高了各种GNNs的鲁棒性。即使在扰动率高达40%的一些情况下,采用LLM4RGNN的GNNs的准确率甚至优于在干净图上的表现。
4. 我们利用GPT-4构建了一个指令数据集,包括GPT-4对26,518条边的恶意性评估及分析。该数据集将被公开发布,可用于微调其它LLMs,使其具备GPT-4的鲁棒图结构推理能力。
2. 符号与预备知识
2.1. 文本属性图(Text-attributed Graphs, TAGs)

2.2. 图的对抗鲁棒性

3. LLM4RGNN的实现
在本节中,我们提出了一种基于大语言模型的鲁棒图结构推理框架LLM4RGNN。如图2所示,LLM4RGNN包含三个主要部分:(a) 对本地LLMs进行指令微调,将GPT-4的推断能力蒸馏到一个本地LLM,用于识别恶意边;(b) 训练基于语言模型的边预测器,将本地LLMs的推理能力进一步蒸馏到边预测器中,以寻找缺失的重要边;(c) 净化图结构,通过移除恶意边并添加缺失的重要边,使各种GNNs更鲁棒。
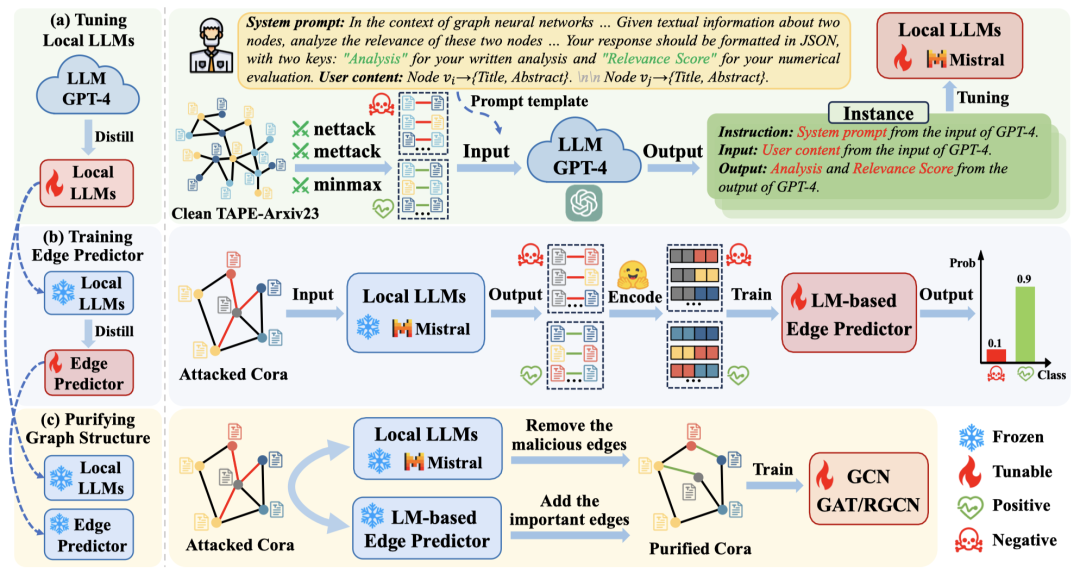
图2: LLM4RGNN的总体框架。
3.1. 指令微调本地LLMs


在"System prompt"中,我们提供了关于任务的背景知识以及LLMs在提示中所扮演的具体角色,这能够更有效地利用GPT-4的推理能力。此外,我们要求GPT-4对边的恶意程度进行细粒度评分,评分范围为1到6,其中较低的分数表示更恶意,而较高的分数表示更重要。"Analysis"这一概念尤为关键,因为它不仅有助于GPT-4在预测结果上的推理过程,还为将GPT-4的推理能力蒸馏到本地LLMs中提供了关键支持。最后,指令数据集的output由GPT-4生成,其格式如下:

事实上,GPT-4很难实现完全准确的预测。为了构建更干净的指令数据集,我们设计了一种后处理筛选操作。具体来说,对于GPT-4的输出,我们仅保留负样本集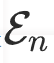 中相关性评分
中相关性评分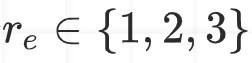 的边,以及正样本集
的边,以及正样本集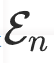 中
中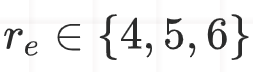 的边。经过筛选的指令数据集被用于微调本地LLMs,例如Mistral-7B或Llama3-8B。经过微调后的LLMs能够拥有GPT-4推理边的恶意程度的能力。我们也在论文附录中提供了GPT-4与本地LLM(Mistral-7B)的案例研究。
的边。经过筛选的指令数据集被用于微调本地LLMs,例如Mistral-7B或Llama3-8B。经过微调后的LLMs能够拥有GPT-4推理边的恶意程度的能力。我们也在论文附录中提供了GPT-4与本地LLM(Mistral-7B)的案例研究。
3.2. 训练基于语言模型的边预测器


3.3. 净化被攻击的图结构

4. 实验
4.1. 实验设置
数据集:为了验证所提出的LLM4RGNN的有效性,我们在四个跨数据集的引文网络(Cora 、Citeseer、Pubmed、OGBN-Arxiv)和一个跨域的产品网络(OGBN-Products)上进行了实验。基于10个不同的随机种子,我们报告了每项实验结果的均值和标准差。
Baseline:首先,LLM4RGNN是一个通用的基于LLM的框架,用于增强GNNs的鲁棒性。因此,我们选择了经典的GCN和三个鲁棒GNN模型(GAT、RGCN和Simp-GCN作为基线模型。此外,为了更全面地评估LLM4RGNN,我们还将其与现有的SOTA鲁棒GNNs框架进行比较,包括ProGNN、STABLE、HANG-quad和GraphEdit(仅提供Cora、Citeseer和Pubmed数据集的提示)。其中,GCN被选作增强鲁棒性的目标模型。
4.2. 主实验
4.2.1. 针对Mettack攻击的防御性能
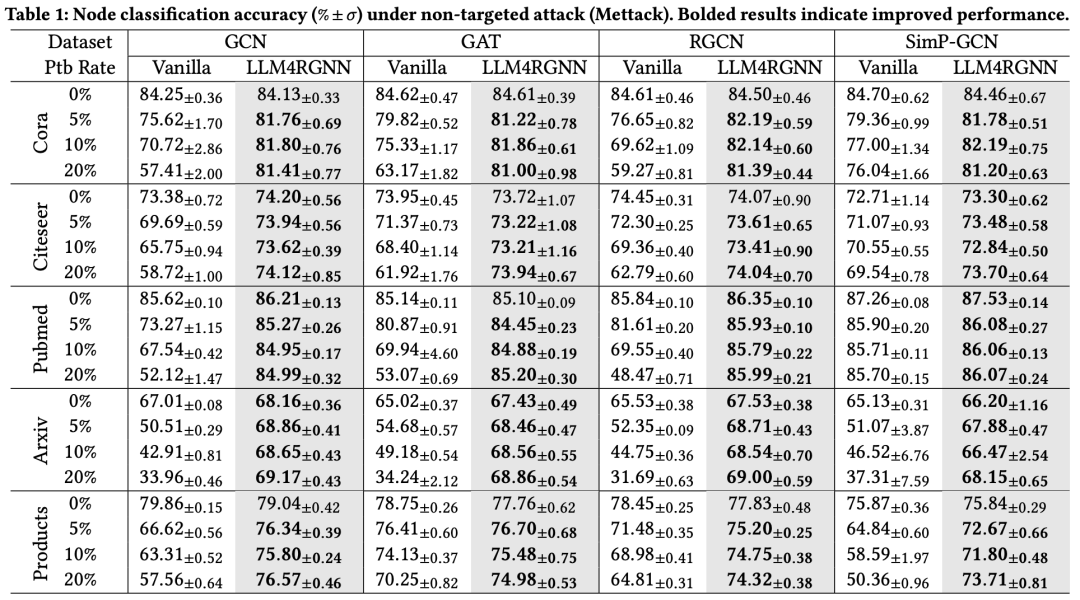
非目标攻击旨在破坏整个图的拓扑结构,从而降低GNN在测试集上的性能。我们采用了SOTA非目标攻击方法Mettack,并将扰动率从0逐步增加到20%,步长为5%。我们有以下观察结果:
1. 从表1可以看出,LLM4RGNN在各种GNN中均显著提升了鲁棒性。对于GCN,在五个数据集上的平均准确率提升为24.3%,最大提升达103%。对于鲁棒GNN(包括GAT、RGCN和Simp-GCN),LLM4RGNN的准确率平均相对提升分别为16.6%、21.4%和13.7%。值得注意的是,尽管在TAPE-Arxiv23数据集上对本地LLM进行了微调,而该数据集并不包含任何医疗或产品样本,但是LLM4RGNN在Pubmed和OGBN-Products数据集上的准确率仍分别相对提升了18.8%和11.4%。
2. 参考表3,与现有鲁棒GNN框架相比,LLM4RGNN实现了SOTA鲁棒性,这得益于LLM强大的理解和推断能力。
3. 结合表1和表3,即使在某些情况下,扰动比例增加至20%,使用LLM4RGNN对图结构进行净化后,GNNs的准确率甚至优于在干净图上的表现。一个可能的原因是,本地LLM能够有效识别恶意边作为负样本,这有助于训练更有效的边预测器,从而找到缺失的重要边。
4.2.2. 针对DICE攻击的防御性能
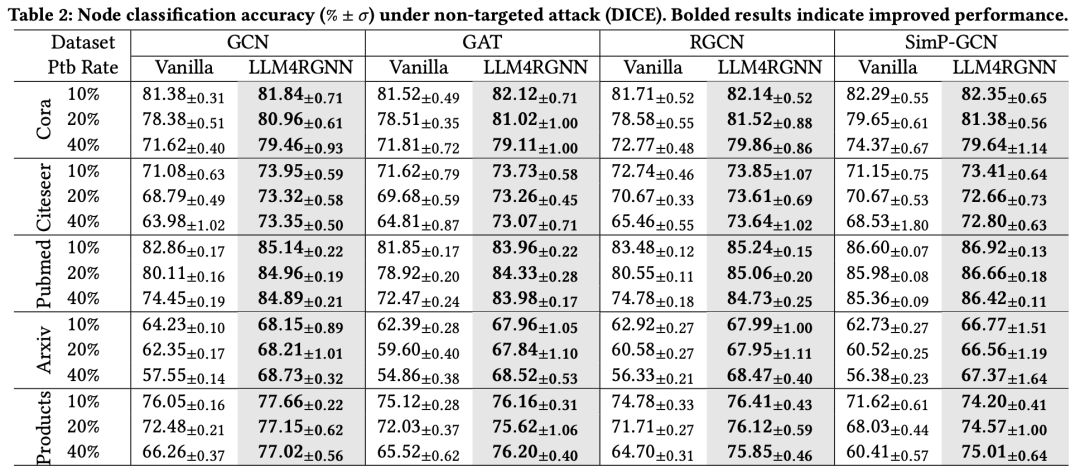
为验证LLM4RGNN的防御泛化能力,我们还评估了其在另一种非目标攻击DICE下的效果。值得注意的是,DICE并未参与指令数据集的构建过程。鉴于DICE的攻击效果不如Mettack,我们设置了更高的扰动率,分别为10%、20%和40%。结果如表2和表4所示。与Mettack下的结果类似,LLM4RGNN在各种GNN上始终提升了鲁棒性,并优于其他鲁棒GNN框架。对于GCN、GAT、RGCN和Simp-GCN,LLM4RGNN在五个数据集上的平均准确率相对提升分别为8.2%、8.8%、8.1%和6.5%。值得注意的是,即使在扰动比例高达40%的一些情况下,使用LLM4RGNN后,GNN的准确率甚至优于在干净图上的表现。
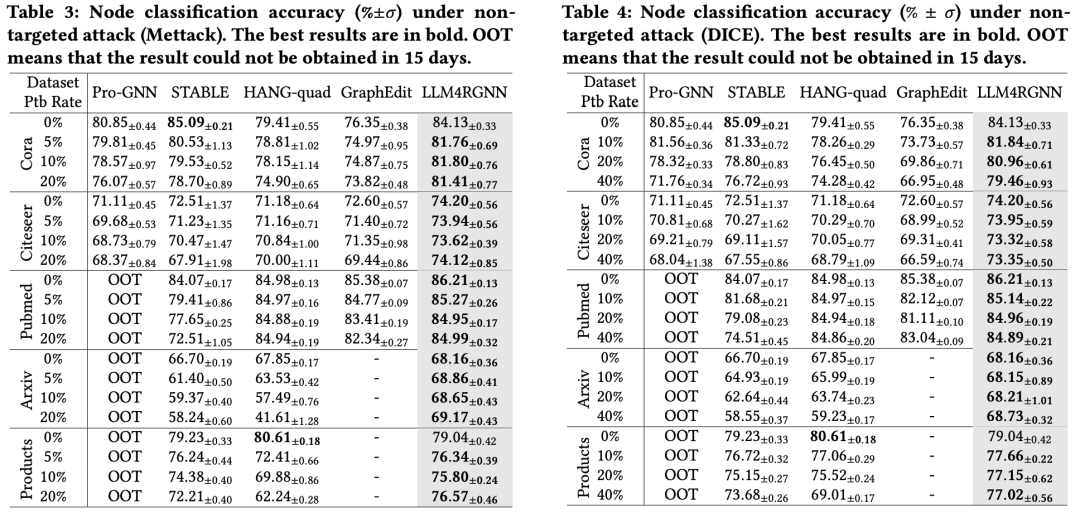
4.2.3. 针对Nettack攻击的防御性能
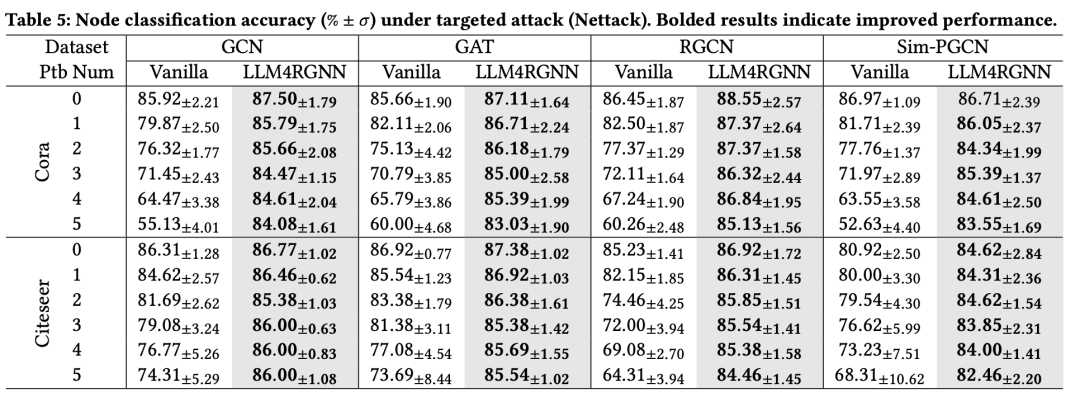
与非目标攻击不同,目标攻击专注于特定节点v,旨在误导GNN对v进行错误分类。我们采用了SOTA目标攻击方法Nettack。参考现有工作设置,我们选择度大于10的节点作为目标节点,并将施加于目标节点的扰动次数从0到5逐步增加,步长为1。结果如表5所示。结果表明,LLM4RGNN不仅始终提升了各种GNN的鲁棒性,而且优于现有的鲁棒框架,对Nettack表现出卓越的抵抗能力。
4.3. 模型分析
4.3.1. 消融实验
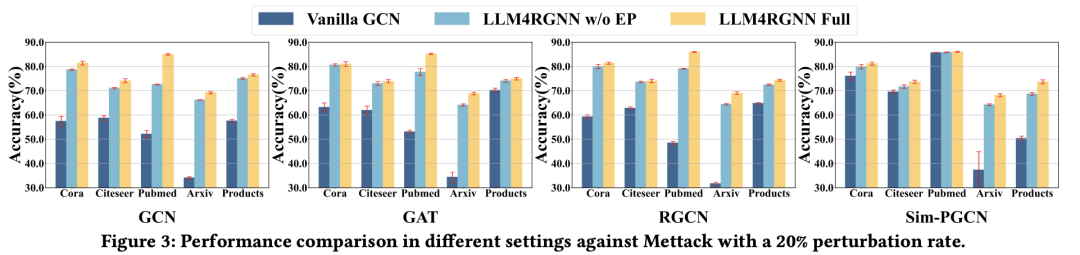
为了评估LLM4RGNN关键组件的作用,我们在Mettack 20%扰动率下进行了消融实验。实验中选择经典的GCN作为训练GNN。实验结果如图3所示,其中“Vanilla”表示在受攻击的拓扑结构上未进行任何修改的设置;“w/o EP”表示仅通过本地LLM移除恶意边的变体;“Full”则同时包括移除恶意边和添加缺失的重要边的完整设置。在所有设置中,LLM4RGNN Full始终优于其他设置。具体来说,利用本地LLM识别并移除大多数恶意边,可以显著减轻对抗性扰动的影响,从而提升GNN的准确率。进一步通过边预测器为每个节点找到并添加重要的邻居节点,可以为中心节点提供额外的信息增益,进一步提高GNN的准确率。
4.3.2. 不同LLMs的比较
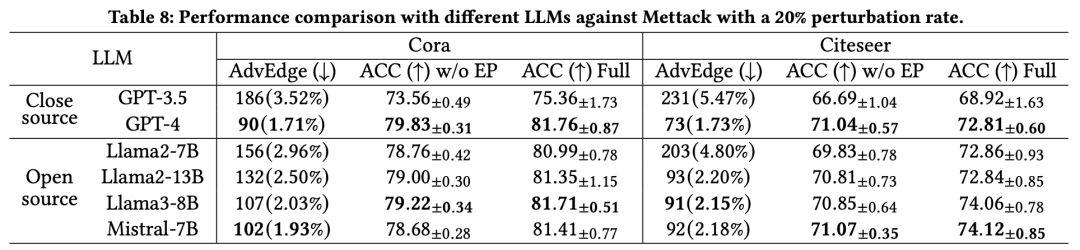
为了评估LLM4RGNN在不同LLM上的泛化能力,我们选择了四个流行的开源LLM,包括Llama2-7B、Llama2-13B、Llama3-8B和Mistral-7B,作为LLM的初始检查点。同时,我们引入了封闭源模型GPT-3.5和GPT-4作为直接对比。此外,我们引入了指标AdvEdge(↓),用于衡量在LLM执行过滤操作后剩余的恶意边数量和比例。我们在Mettack 20%扰动率下报告了GCN在Cora和Citeseer上的结果(分别为Cora生成1053条恶意边,Citeseer生成845条恶意边)。如表8所示,我们有以下观察:
1. 微调后的本地LLM在识别恶意边方面显著优于GPT-3.5,训练后的基于LM的边预测器也持续提升了准确率。这表明GPT-4的推断能力被有效地蒸馏到了不同的LLM和边预测器中。
2. 更强的开源LLM带来了更好的整体性能。其中,微调后的Mistral-7B和Llama3-8B的性能与GPT-4相当。我们在论文附录中提供了它们之间更详细的对比。
除了上述实验外,我们还在论文中还提供了Inductive设置下的节点分类性能、模型效率分析、超参数分析、节点文本质量的影响、防御自适应攻击、扩展到大规模图数据集、净化边的统计信息等更详细的实验结果与分析。
5. 结论
在本文中,我们首次探讨了LLMs在图对抗鲁棒性中的潜力。具体来说,我们提出了一种新颖的基于LLM的鲁棒图结构推断框架LLM4RGNN,该框架将GPT-4的推理能力蒸馏到一个本地LLM中,用于识别恶意边,同时通过基于语言模型的边预测器寻找缺失的重要边,从而高效地净化受攻击的图结构,使GNN更鲁棒。大量的实验结果表明,LLM4RGNN显著提升了各种GNNs的对抗鲁棒性,并取得了SOTA防御效果。鉴于某些图缺乏文本信息,一个未来的计划是将LLM4RGNN扩展到无文本信息的图中。
往期精彩文章推荐

关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了2000多位海内外讲者,举办了逾700场活动,超800万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 观看作者讲解回放!


















 412
412

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









