






点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
01
Task-Circuit Quantization: Leveraging Knowledge Localization and Interpretability for Compression
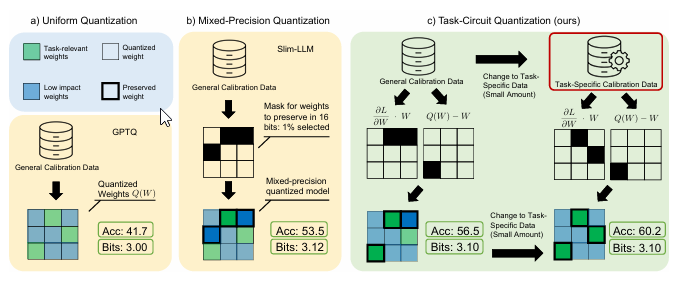
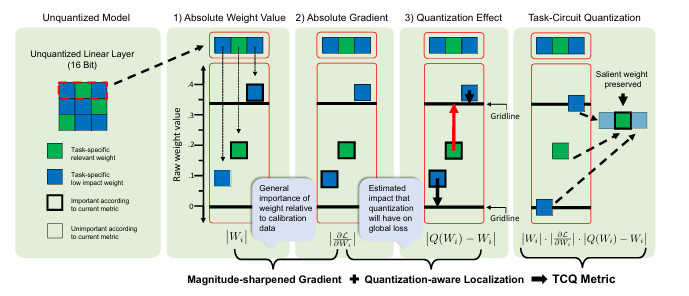
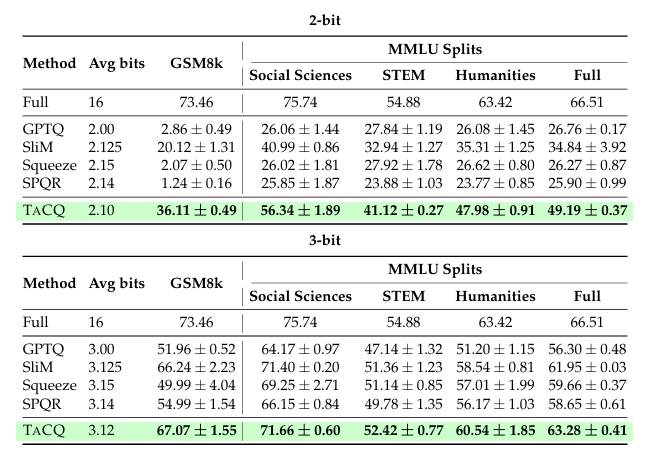
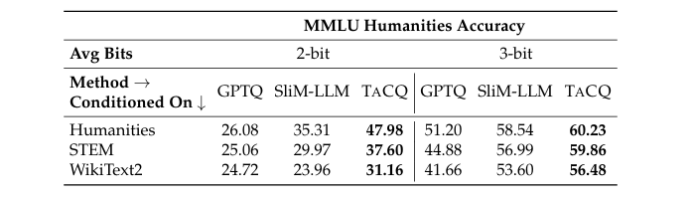
后训练量化(PTQ)通过将全精度权重映射到低比特权重来减少模型的内存占用,而无需昂贵的重新训练,但在低比特(2到3比特)设置中可能会降低下游性能。本文开发了一种新的混合精度PTQ方法,任务电路量化(TACQ),它借鉴了自动化电路发现的方法,直接根据特定权重电路对量化过程进行条件约束,这些权重电路被定义为与下游任务性能相关的权重集合。这些权重被保留为16比特权重,而其他权重则被量化,从而在仅增加边际内存成本的情况下保持性能。具体而言,TACQ通过对比未量化模型权重与均匀量化模型,估计由于量化导致的权重变化,并利用梯度信息预测对任务性能的影响,从而保留任务特定权重。本文在多个任务(包括问答、数学推理和文本到SQL转换)上将TACQ与其他混合精度量化方法进行了比较,涉及Llama-3和Qwen2.5模型。结果表明,在使用相同的校准数据和较低权重预算的情况下,TACQ在2比特和3比特设置中显著优于基线方法。仅用3.1比特,本文就能恢复Llama-3-8B-Instruct未量化16比特性能的96%,比SPQR高出5.25%的绝对改进。此外,本文还在2比特设置中观察到与最强基线SliM-LLM相比平均有14.74%的增益。即使不针对特定任务进行条件约束,TACQ也能实现7.20%的增益,表明其识别重要权重的能力不仅限于任务条件设置。
文章链接:
https://arxiv.org/pdf/2504.07389
02
SlimSpeech: Lightweight and Efficient Text-to-Speech with Slim Rectified Flow
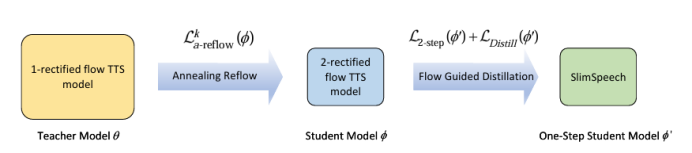
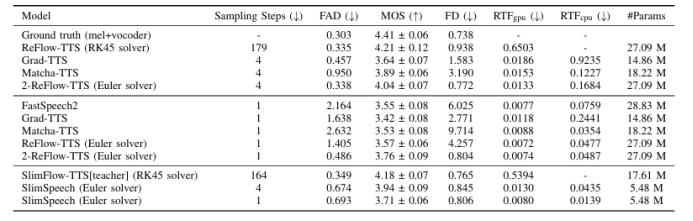
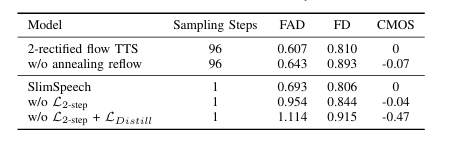
近年来,基于流匹配的语音合成技术在减少推理步骤的同时,显著地提高了合成语音的质量。本文介绍了SlimSpeech,一个轻量级的,高效的语音合成系统的基础上整流。我们已经建立在现有的语音合成方法,利用整流模型,修改其结构,以减少参数,并作为一个教师模型。通过改进回流操作,作者直接从较大的模型中导出具有更直的采样轨迹的较小模型,同时利用蒸馏技术进一步提高模型性能。实验结果表明,本文提出的方法,与显着减少的模型参数,通过一步采样,实现了较大的模型相当的性能。
文章链接:
https://arxiv.org/pdf/2504.07776
03
Enhancing Time Series Forecasting via Multi-Level Text Alignment with LLMs
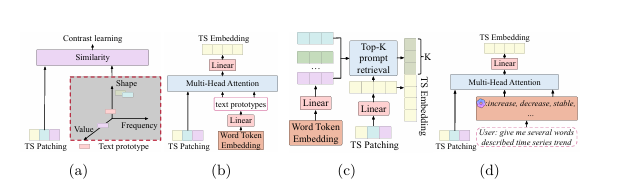
将大型语言模型(LLMs)应用于时间序列预测面临独特挑战,因为时间序列数据是连续的,而LLMs基于离散的标记进行操作。尽管LLMs在自然语言处理(NLP)和其他结构化领域取得了成功,但将时间序列数据与基于语言的表示对齐,同时保持预测准确性和可解释性,仍然是一个重大障碍。现有的方法尝试将时间序列数据重新编程为基于文本的形式,但这些方法往往无法提供有意义且可解释的结果。本文提出了一种利用LLMs进行时间序列预测的多级文本对齐框架,该框架不仅提高了预测准确性,还增强了时间序列表示的可解释性。该方法将时间序列分解为趋势、季节性和残差成分,并将这些成分重新编程为特定于成分的文本表示。本文引入了一种多级对齐机制,将特定于成分的嵌入与预训练的词标记对齐,从而实现更可解释的预测。实验结果表明,本文提出的方法在显著减少模型参数的同时,通过单步采样实现了与较大模型相当的性能。
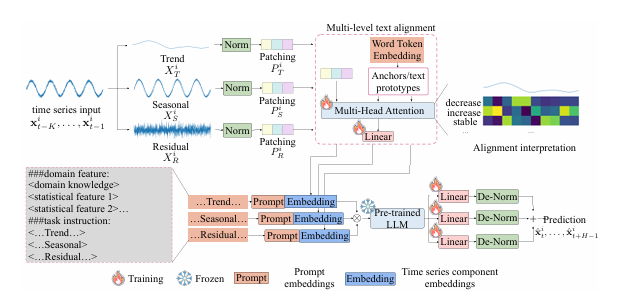
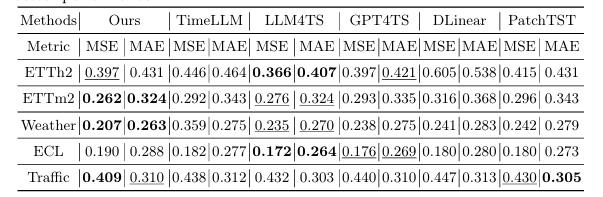
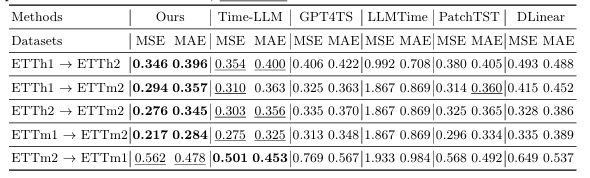
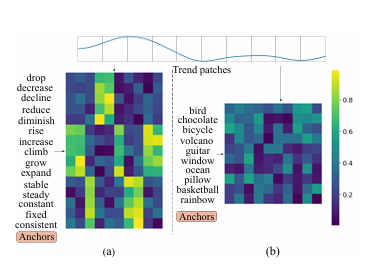
文章链接:
https://arxiv.org/pdf/2504.07360
04
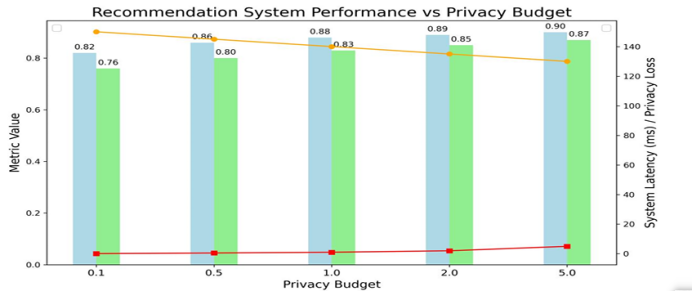
Research on the Design of a Short Video Recommendation System Based on Multimodal Information and Differential Privacy
随着短视频平台的快速发展,推荐系统已成为提升用户体验和增强平台参与度的关键技术。然而,尽管短视频推荐系统利用多模态信息(如图像、文本和音频)来提高推荐效果,但也面临着用户隐私泄露的严峻挑战。本文提出了一种基于多模态信息和差分隐私保护的短视频推荐系统。首先,利用深度学习模型对多模态数据进行特征提取和融合,有效提高了推荐精度。然后,设计了一种适用于推荐场景的差分隐私保护机制,在保持系统性能的同时确保用户数据隐私。实验结果表明,本文提出的方法在推荐精度、多模态融合效果和隐私保护性能方面优于现有的主流方法,为短视频平台推荐系统的设计提供了重要的见解。
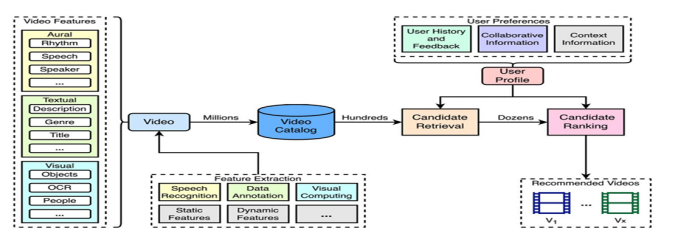
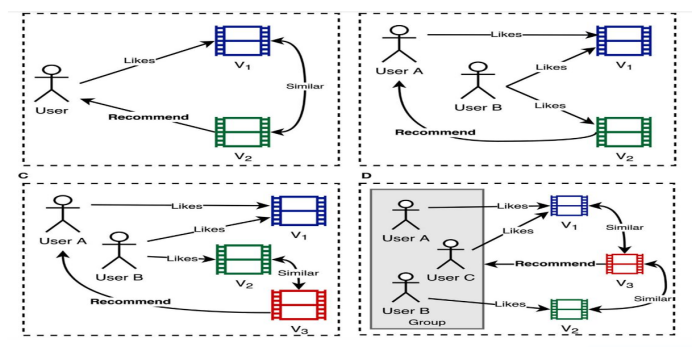
文章链接:
https://arxiv.org/pdf/2504.08751
05
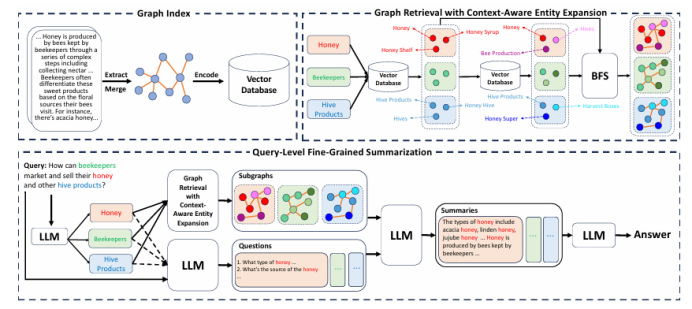
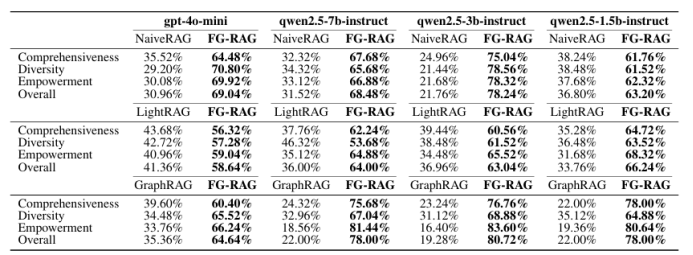
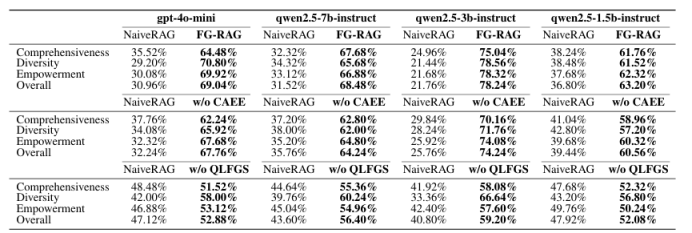
FG-RAG: Enhancing Query-Focused Summarization with Context-Aware Fine-Grained Graph RAG
检索增强生成(RAG)通过整合外部知识,使大型语言模型能够提供更精确和相关的回答。在查询聚焦摘要(QFS)任务中,基于图的RAG方法显著提高了生成回答的全面性和多样性。然而,现有的基于图的RAG方法主要关注粗粒度信息摘要,缺乏对特定查询的感知能力,且检索到的内容缺乏足够的上下文信息来生成全面的回答。为了解决当前RAG系统的不足,本文提出了一种上下文感知的细粒度图RAG(FG-RAG)方法,以增强QFS任务的性能。FG-RAG在图检索中采用上下文感知的实体扩展,扩展图中检索到的实体覆盖范围,从而为检索到的内容提供足够的上下文信息。此外,FG-RAG利用查询级细粒度摘要,在回答生成过程中纳入细粒度细节,增强生成摘要的查询感知能力。评估结果表明,FG-RAG在处理QFS任务时,在全面性、多样性和赋能等多个指标上优于其他RAG系统。
文章链接:
https://arxiv.org/pdf/2504.07103
06
VCR-Bench: A Comprehensive Evaluation Framework for Video Chain-of-Thought Reasoning
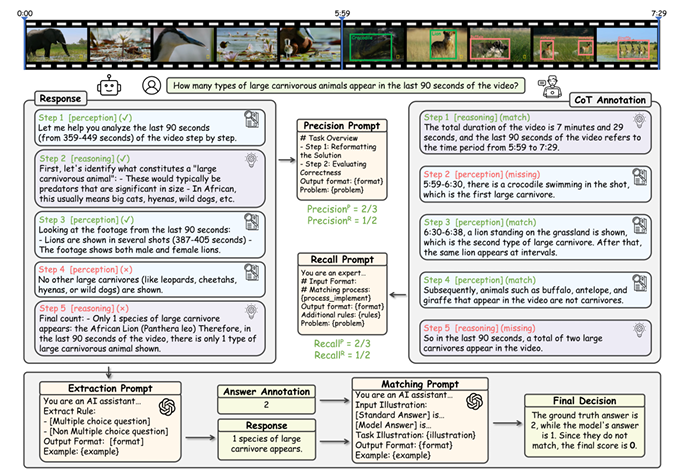
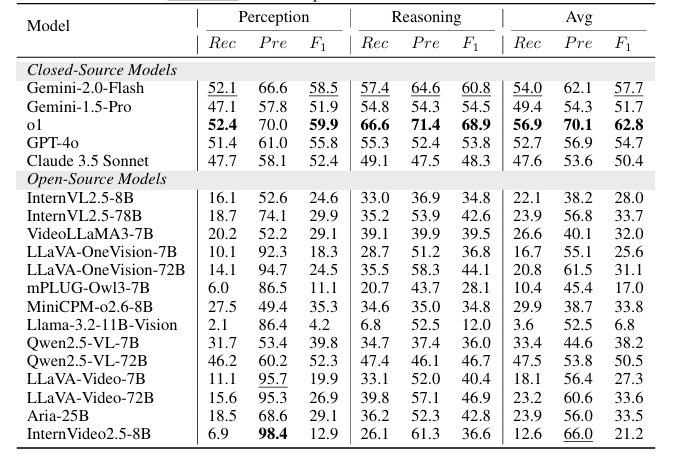
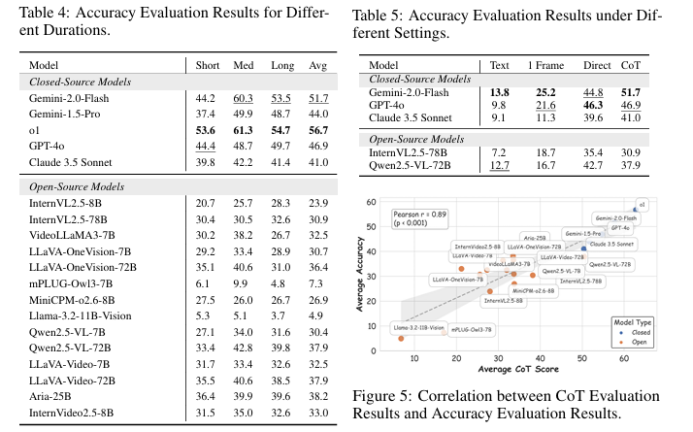
链式思考(CoT)推理的发展显著提升了大型语言模型(LLMs)和大型视觉语言模型(LVLMs)的能力。然而,目前缺乏对视频CoT推理的严格评估框架。现有的视频基准测试未能充分评估推理过程,也未能揭示失败是由于感知能力还是推理能力的不足。因此,本文提出了VCR-Bench,这是一个旨在全面评估LVLMs视频链式思考推理能力的新基准测试。VCR-Bench包含859个视频,涵盖多种视频内容和时长,以及1034个高质量的问答对。每个问答对都手动标注了逐步的CoT理由,每一步都标记以表明其与感知或推理能力的关联。此外,本文设计了七个不同的任务维度,并提出了CoT评分,基于逐步标注的CoT理由来评估整个CoT过程。广泛的实验表明,当前的LVLMs存在显著的局限性。即使是表现最好的模型o1,也仅实现了62.8%的CoT评分和56.7%的准确率,而大多数模型的得分低于40%。实验表明,大多数模型在感知步骤上的得分低于推理步骤,揭示了LVLMs在复杂视频推理中处理时空信息的关键瓶颈。CoT评分与准确率之间的强正相关性证实了本文评估框架的有效性,并强调了CoT推理在解决复杂视频推理任务中的关键作用。作者希望VCR-Bench能够作为一个标准化的评估框架,揭示复杂视频推理任务中的实际不足。


文章链接:
https://arxiv.org/pdf/2504.07956
07
SpecReason: Fast and Accurate Inference-Time Compute via Speculative Reasoning
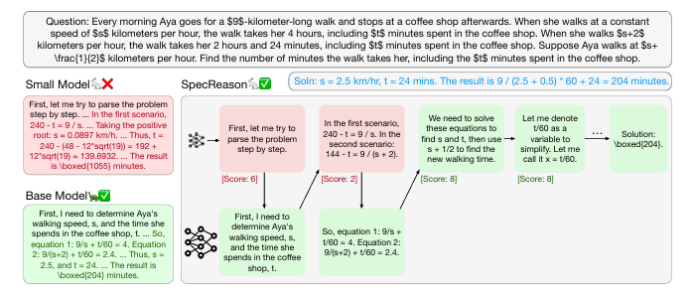
最近在推理时计算方面的进展通过使用大型推理模型(LRMs)生成长推理链(CoTs)显著提升了复杂任务的性能。然而,这种提升的准确性是以高推理延迟为代价的,因为生成的推理序列较长,且解码的自回归性质导致延迟随序列长度线性增加。本文的关键见解是,LRM推理及其嵌入的推理对近似非常容忍:复杂任务通常被分解为更简单的步骤,每个步骤的价值在于为后续步骤提供语义洞察,而不仅仅是生成的确切标记。因此,本文提出了SpecReason,一个通过使用轻量级模型(推测性地)执行更简单的中间推理步骤来自动加速LRM推理的系统,并仅保留成本较高的基础模型来评估(并可能纠正)推测的输出。重要的是,SpecReason专注于利用思考标记的语义灵活性来保持最终答案的准确性,这与之前的推测技术(尤其是推测性解码)形成互补,后者要求每个步骤的标记级别等价。在多种推理基准测试中,SpecReason实现了比传统LRM推理快1.5–2.5倍的速度提升,同时将准确性提高了1.0–9.9%。与不使用SpecReason的推测性解码相比,它们的组合进一步降低了19.4–44.2%的延迟。
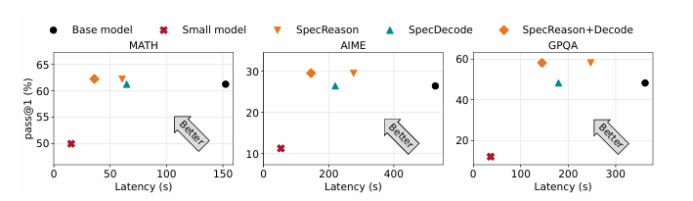
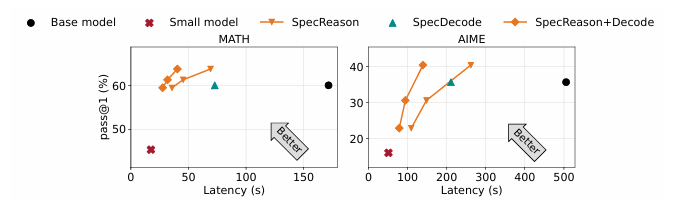
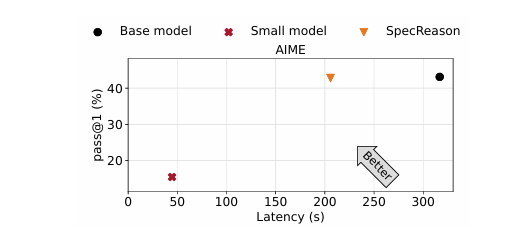
文章链接:
https://arxiv.org/pdf/2504.07891
本期文章由陈研整理
近期活动分享

CVPR 2025一作讲者招募中,欢迎新老朋友来预讲会相聚!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了2000多位海内外讲者,举办了逾700场活动,超800万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 查看更多!


















 319
319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









