







 超级会员免费看
超级会员免费看
大语言模型原理与工程实践:数据瓶颈问题分析和解决方法原理与应用
关键词:大语言模型, 数据瓶颈, 数据质量, 数据增强, 迁移学习, 预训练, 微调, 自监督学习, 数据标注, 数据治理
文章目录
- 大语言模型原理与工程实践:数据瓶颈问题分析和解决方法原理与应用
- 大语言模型原理与工程实践:数据瓶颈2
1. 背景介绍
1.1 问题的由来
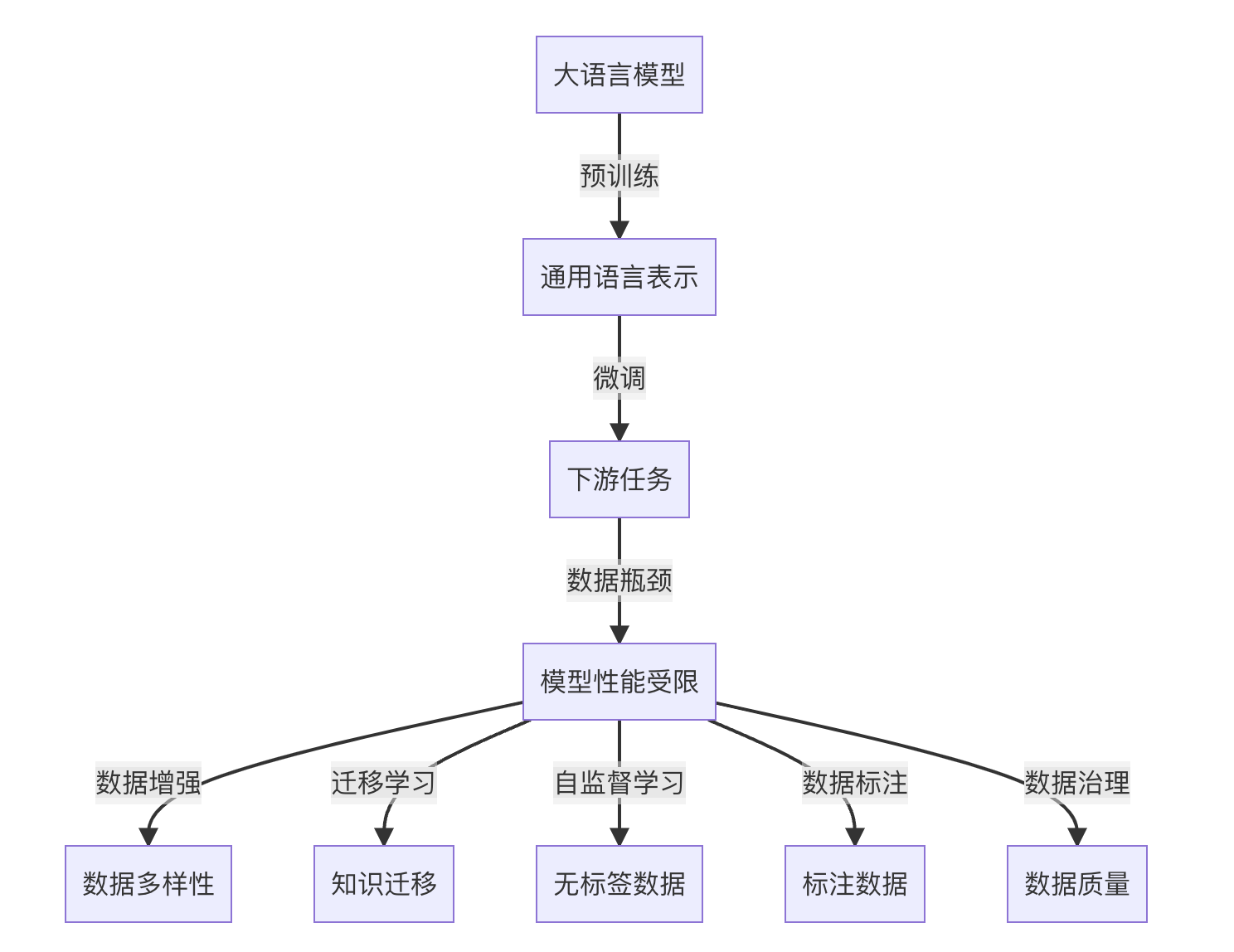
在过去的几年里,随着深度学习技术的飞速发展,大规模语言模型(Large Language Models, LLMs)在自然语言处理(Natural Language Processing, NLP)领域取得了显著的进展。这些模型通过在大规模无标签文本数据上进行预训练,学习到了丰富的语言知识和常识,并在各种NLP任务中表现出色。然而,随着模型规模的不断扩大和应用场景的不断拓展,数据瓶颈问题日益凸显,成为制约大语言模型进一步发展的关键因素。
1.2 研究现状
当前,大语言模型的研究和应用主要集中在以下几个方面:
- 预训练和微调

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











