







7.1 决策树
在现实生活中,我们每天都会面对各种抉择,例如根据商品的特征和价格决定是否购买。不同于逻辑回归把所有因素加权求和然后通过Sigmoid函数转换成概率进行决策,我们会依次判断各个特征是否满足预设条件,得到最终的决策结果。例如,在购物时,我们会依次判断价格、品牌、口碑等是否满足要求,从而决定是否购买。决策的流程,如图7-1所示。
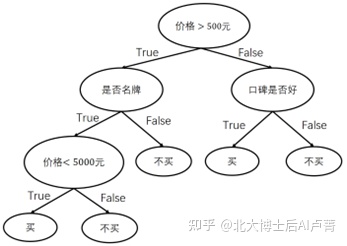
图7-1
可以看到,决策过程组成了一棵树,这棵树就称为决策树。在决策树中,非叶子节点选择一个特征进行决策,这个特征称为决策点,叶子节点则表示最终的决策结果。在上例中,我们只是根据经验主观建立了一棵决策树,这棵决策树在数据量和特征维度较小且逻辑简单时是可以使用的。然而,在数据量和特征维度较大时,仅凭主观观察建立决策树显然是不可行的。在实际应用中,训练集中的样本往往有上万个,样本的特征通常有上百维,该怎么处理呢?在实际建立决策树的过程中,每次选择特征都有一套科学的方法。下面就详细讲解如何科学地建立决策树。
不难发现,建立决策树的关键在于选取决策点时使用的判断条件是否合理。每个决策点都要有区分类别的能力。例如,在电商场景中,将发货的快递公司作为决策点的选取条件就是一个很差的选择,其原因在于快递公司和购买行为没有必然联系,而将商品价格作为决策点的选取条件就是合理的,毕竟大部分消费者对商品价格比较敏感。
一个好的决策点可以把所有数据(例如商品)分为两部分(左子树和右子树),各部分数据所对应的类别应尽可能相同(例如购买或不购买),即两棵子树中的数据类别应尽可能“纯”(这种决策点有较高的区分度)。和逻辑回归类似,用已知数据(例如用户的购买记录、商品信息)求解决策树的形状和每个决策点使用的划分条件,就是决策树的训练过程。
首先看一下如何量化数据的纯度。假设在一组数据中有P和N两类样本,它们的数量分别为 n_1 个和 n_2 个。P类样本出现的概率为
P(y=P类)=n_1/(n_1+n_2 )
N类样本出现的概率为
P(y=N类)=n_2/(n_1+n_2 )
我们可以直观地发现:当数据只有一个类别(P(y=N类)=1 或 P(y=P类)=1)时,数据最纯;当两类数据“平分秋色”(P(y=N类)=P(y=P类)=0.5)时,数据最混乱。
可以使用基尼(Gini)系数来量化数据的混乱程度。基尼系数的计算公式如下。
Gini=1-〖P(y=N类)〗^2-〖P(y=P类)〗^2
可见,基尼系数越小,数据就越纯(P(y=N类)=1,Gini=0)。当数据最混乱时,P(y=N类)=P(y=P类)=0.5,也就是说,基尼系数的最大值为0.5。
基尼系数和概率 P(y=N类) 的关系,如图7-2所示。
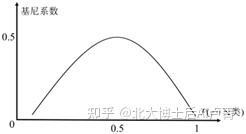
图7-2
决策树有一些常用的构建方法,在这里我们详细讲解一下最为流行的CART树。CART树是一棵二叉树,它不仅能完成分类任务,还能完成数值预测类的回归任务。下面先介绍分类树,再介绍回归树。在构建CART树时,可以使用基尼系数来度量决策条件的合理性。
假设有 N 个训练样本,特征一共有 m 维,即 x=[■(x_1@⋮@x_m )]。和逻辑回归中特征 x_i 是连
续值不同,在这里,x_i 既可以是连续值(例如价格、好评数、销量等,x_i∈(-∞,+∞)),也可以从集合中“多选一”(例如学历,x_i∈{专科,本科,硕士,博士,其他})。决策树的构建(训练)过程是一个不断生成决策点的过程,每次生成的决策点都要尽可能把训练样本中的两类数据分开。
例如,x_1 为价格,划分条件为 x_1>500,将训练数据分成两类(如果某个样本在划分条件上有特征缺失,就随机分配该样本),如图7-3所示。

图7-3
Data1 中有 M_1 个样本,它们对应于不同的类别,基尼系数为 Gini1。Data1 中的数据越纯(类别越单一),Gini1 就越小。同理,Data2 中有 M_2 个样本,基尼系数为 Gini2。
此次划分的基尼系数为
G
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 658
658











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









