






《速通深度学习数学基础》适读人群 :高校学生,深度学习入门学习者
以线性代数、微积分、概率论为逻辑主线,讲解了与深度学习有关的大部分数学内容,并结合作者多年工作经验介绍了工程实践和实际应用中的技巧。
长文预警,(由于知乎平台稿件格式问题,公式格式不能正确写上;如若读写困难可後台私信我要完整电子版),感兴趣想要全文的,本书已出版可自行购买阅读。
内容简介:本书以线性代数、微积分、概率论为逻辑主线,讲解了与深度学习有关的大部分数学内容。本书以理论结合实际的方式讲解,使数学知识不再是冰冷的公式堆砌,而变成一个个真实的案例,同时对案例背后的原理进行理论上的升华,希望达到一通百通的效果。读者通过阅读本书,不仅能够提升阅读学术论文中的数学公式的能力,还能加深对深度学习本身的理解。
本书面向入门级读者,摒弃复杂的数学推导和证明,重视逻辑推理和简单的表达,特别适合数学基础不足的读者阅读。
作者简介:卢菁,北京科技大学博士,北京大学博士后流动站出站。工作于腾讯、爱奇艺等知名互联网公司,主要从事人工智能技术的应用研发工作。主要研究方向为机器学习、自然语言处理、知识图谱、推荐系统等,有丰富的理论和实践经验。
精彩书评:正如本书的书名,本书能让读者放下对数学基础不足的担忧,快速对机器学习的基础技术和应用进行全景式的理解。作者从互联网实践应用的角度,对枯燥的理论进行了深入浅出的讲解,让读者在了解理论背景的同时掌握实际业务场景中的应用方法。
刘俊晖 爱奇艺AI高级总监
人工智能行业的高速发展,与之相关的算法工程师等岗位也成为高薪和快速发展的代名词,让无数学子为之向往。但是,数学作为人工智能技术的核心工具,却让很多同学感到非常棘手,高等数学、概率、线性代数等高难度学科压得人喘不过气。卢老师以自身深厚的学养,辅以多年的实践以及教学经验,将人工智能行业所需的数学知识条分缕析地展现在读者面前,帮助读者用最短的时间、最高效的方法掌握必备的数学基础知识,是进入人工智能行业的必备参考书。
陈川 千锋教育集团副总裁
本书写得通俗易懂,没有过于复杂的公式,非常适合数学基础薄弱的同学快速入门机器学习。本书内容贴合实际工作,很多企业中的真实例子可以作为就业面试辅导和项目技术参考。
肖阳 百度副总裁
本书的作者卢菁是我的老同学。本书介绍了业内广泛使用的机器学习算法和模型,既包含核心概念、算法原理、行业应用等方面的详尽介绍,也包含作者多年的实践经验总结。本书内容深入浅出、清晰透彻,相信有志于人工智能领域的从业者都能从中获益。
贺海波 网易传媒技术副总经理
这是一本非常适合读者快速入门的机器学习教程,是适合普通人修炼的秘籍。作者用通俗易懂的语言,结合很多真实的案例进行讲解——就像大学课程的讲义一样。推荐希望快速了解机器学理论和实践的技术和产品人员阅读。
王栋 小米互联网业务部副总经理兼电视与视频业务部总经理

序
深度学习从感知器诞生至今已有近70年的历史。目前深度学习逐渐发展成以大模型加精调的迁移学习新范式。深度学习从实验室走向商业化应用,赋能于民用、工业等领域,深刻地影响着人们的生活。每个深度学习算法的背后,是无数科学家、研究员、工程师用智慧探索算法的原理并结合实际场景落地,每一项复杂工作的背后,蕴藏着深刻的数学原理。
国内与深度学习有关的书籍多如繁星,但似乎缺乏专门讲解深度学习背后的数学原理的著作。这本《速通深度学习数学基础》的出现,为相关领域的读者提供了学习上的便利。
本书作者长期从事深度学习项目实践,对相关理论和方法有深刻的心得体会。本书力求精简,在有限的篇幅里,以线性代数、微积分、概率论三条主线,讲解了与深度学习有关的数学知识。参考本书,读者可以大幅提升深度学习领域的文献阅读能力。
本书针对数学知识在深度学习中的应用,精心挑选了相关内容进行深入浅出的讲解,文字轻松有趣,别开生面。本书特别适合以下读者阅读:大学生;想进入深度学习行业,但是担心数学底子不好的技术人员;在算法上缺乏足够基础的工程师。相信本书能帮助这些读者系统地了解深度学习模型背后的常用数学原理。
周 明
2022年7月
前言
在我们享受人工智能带来的便利背后,是无数科学家、研究员、工程师的辛勤工作。他们用智慧探索智能化的原理,并结合实际场景落地——这项复杂工作的背后往往蕴藏着深刻的数学原理。如果说社会需求是人工智能的第一驱动力,那么数学就是最为重要的燃料。
写作背景
在目前国内的图书市场上,深度学习数学相关书籍,要么是纯粹的数学内容,要么是深度学习各类模型的汇总,缺乏专门将数学和人工智能结合起来讲解的著作。本书恰好填补了此处的市场空白,希望能为相关领域的学生、工作人员提供学习上的便利。
本书内容
本书力求精简,因此很薄,但内容一点也不少。
本书以线性代数、微积分、概率论为逻辑主线,讲解了与深度学习有关的大部分数学内容。读者通过阅读本书,不仅能够提升阅读学术论文中的数学公式的能力,还能加深对深度学习本身的理解。相比于现行的数学教材理论较多、偏向严谨的证明、容易让人望而生畏,本书把焦点放在了数学知识在深度学习中的应用上。
本书精心挑选深度学习相关知识进行深入浅出的讲解,对所涉及的数学结论给出相应的落地应用。和同类深度学习书籍相比,本书面向入门级读者,摒弃复杂的数学推导和证明,重视逻辑推理和简单的表达,特别适合数学基础不足的读者阅读。和国内外经典书籍相比,本书以数学知识为主线带出深度学习知识。读者可以将本书当作对同类书籍中数学知识的二次提炼。
本书作者长期奋战在深度学习一线,对自然语言处理、推荐系统等有深入的研究和应用心得。本书以理论结合实际的方式讲解,使数学知识不再是冰冷的公式堆砌,而变成一个个真实的案例,同时对案例背后的原理进行理论上的升华,希望达到一通百通的效果。
人工智能不仅是一个前沿领域,也是一个接地气的工程学科。人工智能越来越多地渗透到我们的日常工作和生活中,不仅极大提升了我们的工作效率,还在衣、食、住、行等方面改变着我们的生活。
当然,从总体看,人工智能仍然有很长的路要走,还有巨大的潜能没有释放。让我们共同奋斗吧!
卢 菁
2022年6月
第1章 线性代数的基本概念
1.1 向量和深度学习
在开展人工智能相关工作时,我们面临的业务大都是客观世界中的问题,例如图片、视频、文本的识别及推荐系统的设计等。这些业务包含各式各样的数据——图片对应的是像素值,文本对应的是字符串,语音对应的是声波,推荐系统则包含大量的用户行为数据——五花八门、无奇不有。但是,机器学习模型作为一个数学函数,接受的输入一般是浮点数数组。这个数组用专业术语表述,叫作特征向量,数组的长度叫作特征向量的维度。例如,
x=[■(1.1@2.3@3.2)]
在这里,x 为一个向量,它对应的维度是3(有3个数),因为这3个数是竖着排成一列,因此 x 也被称为列向量。向量也可以写成如下形式:
y=[1.1,2.3,3.2]
这种写法,3个数横着排成一行,因此 y 也被称为行向量,我们一般可以使用转置符号T写在向量的右上角,表示对向量旋转90°,即行向量变成列向量,列向量变成行向量,例如上述向量 x 和 y,有如下关系。
x^T=y
y^T=x
行向量和列向量本质上没有差别,都可以用来描述事物的特征。为了后续的运算方便,一般来说,机器学习大都采用列向量作为特征描述,即
x=[■(1.1@2.3@3.2)]
但是,这样书写公式占用的面积较大,所以有时也写成转置的形式:
〖x=[1.1,2.3,3.2]〗^T
在本书中,如果表示向量中具体维度的数值,采用下角标形式,即
〖x=[x_1,x_2,x_3]〗^T
x_1=1.1
x_2=2.3
x_3=3.2
在机器学习中,特征向量的某个具体位置的数值表示真实世界中某个属性的强度。因此,无论何种业务,都需要将业务特征表示为向量 x,这个过程叫作特征提取,如图1-1所示。

图1-1
如果各类业务特征统一以向量表示(不同的特征提取方法),后续的模型设计环节就可以与业务解耦。模型本身可以部分脱离业务(但不能完全脱离),仅需要针对特征向量进行研发,而这些特征向量可能来自完全不同的业务场景。
一些业务特征天然就是数值化的。例如,一个年龄30岁、身高175厘米的人,可以直接表示成特征向量 〖[30,175]〗^T。另一些业务特征不太容易直接表示成特征向量。例如,“我喜欢机器学习”这句话对应的是一个字符串,需要使用特征提取技术对其进行向量化(如转换成向量 〖[-0.1,0.3,0.2,0.4]〗^T)。特征提取有很多方法,并且往往和业务有关。即使是同一客观事物,在面向不同的业务时关注的目标也是不一样的。因此,特征的关注点千差万别。
下面介绍一些常用的特征提取方法。
在做图像识别时,首先会对输入的图片进行尺寸归一化,即将不同尺寸的图片缩放至同一尺寸,例如200像素×200像素。我们知道,图片是由大量像素点以二维方式排列而成的。在彩色图片中,每个像素点由一个3维数组组成,分别表示R、G、B(红、绿、蓝)颜色的强度,每种颜色的取值范围为0~255。例如,[255,0,0] 表示红色,[0,125,125] 则对应于黄色。因此,彩色图片对应于 200×200 的矩阵,矩阵中的每个元素都使用一个3维向量来表示颜色信息,彩色图片可以表示为 200×200×3 的向量,其中的“3”也称作通道数。黑白图片每个像素点的取值范围为0~255,0表示白色,255表示黑色,其他数值则表示从白色到黑色的渐变色(灰色)。黑白图片对应的是 200×200×1 的向量(黑白图片为单通道图片)。彩色图片和黑白图片的特征,如图1-2所示。在一些颜色不是特别重要的场景中会将彩色图片转换成黑白图片,这时特征维度只有原来的 1/3,计算量和模型复杂度有所降低。

图1-2
一段视频其实是由多幅有序图片组成的,一幅图片称为一帧。常见的帧频是30帧/秒,即一段1秒的视频其实是快速播放30幅有序图片形成的。视频特征和图片特征类似,只不过加上了时间维度。例如,一段5秒的彩色视频(5秒×30帧/秒=150帧)所对应的特征向量的长度为 200×200×3×150。长视频往往会对应非常多的帧,这对计算来说负担很重。为了减轻计算压力,通常会使用关键帧技术,从视频中抽取一些视觉效果发生了急剧变化的帧作为特征,其他帧则会被舍弃。
除图像外,文本处理也是人工智能的一个重点领域。与文本处理相关的技术和应用主要包括文本内容理解、信息提取、智能聊天对话等,这些技术和应用称为自然语言处理(Nature Language Process,NLP)。假设词库中有a、b、c、d、e、f、g、h、i、j共10个词(实际词库中的词往往在20万个以上),每个词可以表示为一个10维向量,a~j分别对应于特征向量的1~10位,那么词a可以用10维向量 〖[1,0,0,0,0,0,0,0,0,0]〗^T 来表示,这种向量化方法叫作one-hot。
如何对文章进行向量化呢?如果在一篇文章中,词a、b、e、f各出现了一次,则对应的特征向量为 〖[1,1,0,0,1,1,0,0,0,0]〗^T。而如果在一篇文章中,词a出现了两次,就可以进一步用词频来表示,即 〖[2,1,0,0,1,1,0,0,0,0]〗^T。这种对文章进行向量化的方法叫作multi-hot。
one-hot和multi-hot比较粗糙,有很多缺点,列举如下。
汉语的常用词有约20万个,但在一篇文章中可能仅出现几百个,因此,特征值会出现大量的0,向量稀疏,信息不紧凑,造成了存储资源的浪费。
没有考虑词的顺序问题。例如,“我借给你钱”和“你借给我钱”这种意思相反的句子的multi-hot向量是一样的。
中文的语义歧义问题。例如,“苹果手机”和“吃苹果”中的“苹果”是完全不同的事物,但这两个“苹果”所对应的one-hot和multi-hot向量是一样的。
在使用one-hot对文本进行编码时,无法体现语义的相似度。例如,“手机”“互联网”“红烧肉”三个词,在语义上,“手机”和“互联网”比较近,“红烧肉”和它们没有关系。采用one-hot编码,这三个词的对应向量为 〖[1,0,0]〗^T、〖[0,1,0]〗^T、〖[0,0,1]〗^T。从向量的角度看,这三个词彼此之间的夹角都为90°,表达不出语义上的相似性。
尽管one-hot方法有以上缺点,但在2014年之前,做自然语言处理的人基本上都在使用它——毕竟方法简单,在要求不高的场景中效果也能达标。在深度学习得到广泛应用之后,one-hot式微。目前流行的方法是让每个词对应于一个稠密低维(常见128维、256维,远低于one-hot中动辄几十万维)向量,例如词“苹果”对应于向量 〖[-0.1,1.2,3.3,2.1,4.3]〗^T。这类向量也称为词向量或Word embedding。词向量的生成方法,一般是先进行随机初始化,再进行任务驱动(例如文本分类、情感分析),从而训练模型以改变稠密向量,其经典方法是Word2vec。在使用稠密向量时,每个词所对应的embedding将会不同,具体表现为:近义词的embedding之间的夹角很小,语义无关的词的embedding之间的夹角很大。
对于包含多个词的文本,可以把每个词所对应的词向量相加作为文本向量。不过,相加(求和)忽略了词出现的顺序。为了解决这个问题,可以把词向量按顺序串联起来。例如,词向量有128维特征,一共10个词,那么该文本对应的就是 128×10 维的特征向量。可以使用配套的时序模型(例如RNN、LSTM、Transformer),将这个 128×10 维的向量转换成低维(例如128维)向量来表示文本语义。特别地,一词多义问题也可以通过BERT之类的模型来解决。从整体看,人工智能处理文字的难度远高于处理图像。目前,图像处理技术已经比较成熟了,有很多固定的方法和模式,但文字处理的难度仍然很大,技术仍然很不成熟。
除了图像、文字、语音等自然特征,还有很多业务特征需要向量化。例如,电商场景需要对每个用户进行用户画像。用户画像的一个维度是性别,而性别这个特征可以用以下两种方式表达。
男:〖[0]〗^T。女:〖[1]〗^T。
男:〖[0,1]〗^T。女:〖[1,0]〗^T。
第一种方式只有1维特征,男、女用数值来区分,但这样做是有问题的:同一位置具有可比性,从数值上看女大于男,但实际上男、女只是两个状态而已,没有大小关系。第二种方式其实就是one-hot。这样看来,第二种方式更合适——虽然存在冗余问题,但保证了男、女的平等性。在机器学习中通常会采用第二种方式。由此可见,虽然one-hot在NLP领域不适用,但并非一无是处,仍然有其适合的场景。这也说明,在机器学习领域,方法本身没有好坏之分,关键在于方法和场景是否契合。
再举个例子。在电商场景中,将年龄的取值范围设置为0~100,最简单的方法是用1维特征来表示,例如将32岁表示成 [32]。但是,在电商场景中,单纯的年龄数据并不重要,我们更关心“小孩”“年轻人”“中年人”“老年人”这种能够反映消费能力和消费习惯的特征。因此,用1维特征来表示的方法欠妥——单纯的数值特征,尽管具有数值的含义(例如,20岁和50岁的均值是35岁,而在实际的电商场景中不会这样使用),但没有将业务的特点明确表示出来。
作为改进,我们可以把0~100岁分成四段,用一个4维向量来表示。不同年龄段有如下特征。
小孩:〖[1,0,0,0]〗^T,0<age≤18。
年轻人:〖[0,1,0,0]〗^T,18<age≤40。
中年人:〖[0,0,1,0]〗^T,40<age≤60。
老年人:〖[0,0,0,1]〗^T,60<age。
通过这种方法提取的特征能更好地反映用户的消费能力和购物特点,例如小孩喜欢为游戏充值、年轻人愿意购买新奇的商品、中年人容易购买贵重商品、老年人经常购买保健品,与场景的贴合度很高。
从机器学习的角度看,这个方法的一个好处就是特征较为稳定。例如,25岁和26岁其实没有本质的差别,因为它们在同一区间内。这个方法的缺点在于对分段点附近的年龄过于敏感,例如17岁和19岁会被划分到两个区间。因此,这个方法对划分区间提出了较高的要求。为了缓和边界点的敏感性,可在划分时令相邻区间有交集,例如“0~18、15~40、35~60、55~100”,这样,36岁的人所对应的特征为 〖[0,1,1,0]〗^T,即同时具备中年人和年轻人的特点。
还有一个特点值得研究。电商网站一般会在后台存储用户的消费能力数据,例如:16~40岁的人购买能力比较强,消费能力为 10;女性的购买欲望比较强,消费能力为 15;若两者同时满足,例如“25岁的女性”,则其消费能力可能会飙升到100——不是简单的 10+15。因此,除了直接特征,还需要一些组合特征。例如,对一位26岁的女性,原来表示为性别 [1,0]^T、年龄 [0,1,0,0]^T,拼接后得到一个6维特征向量 x=〖[1,0,0,1,0,0]〗^T;而现在需要引入第7维作为组合特征,当第1维和第4维同时为1时将其置1,即 x_7=x_1 x_4,x_7 代表“年轻女性”这种更高层次的特征,特征向量为 〖[1,0,0,1,0,0,1]〗^T。
一些资讯类App会提供视频、图片和文字等内容。对于视频,可以考虑的特征有时长、清晰度、完成率等;对于图片,涉及的特征有清晰度、敏感信息等;对于文章,主要特征有篇幅、关键字、作者等。各种特征组合起来,数量巨大且具有较强的业务性。这些特征的具体组合方式,需要代码编写者和策略产品经理共同确定。随着机器学习的发展,现在也出现了很多能够进行特征自动组合的模型。
在二手汽车交易平台中,汽车的颜色是一个很重要的特征。能否用数组 [0~255,0~255,0~255] 表示颜色?答案是:不能。因为在汽车交易领域,颜色只代表购买者的审美倾向,并无大小之分。同时,汽车颜色种类有限,如果有20种颜色,就用一个20维的one-hot向量表示即可。
总之,特征向量的定义方式要根据具体的业务场景确定,特征要能尽量客观地描述实际问题。
综上所述,机器学习的步骤如图1-3所示。
图1-3
在使用非深度学习(传统)模型时,对特征工程的要求比较高。而深度学习模型与非深度学习模型相比,对特征工程的要求大幅降低,它通过计算机的运算能力对所处场景进行理解,模型可以根据目标任务自动提取特征,减轻了人的工作量——尽管模型复杂度增加、运算量增大,但对人的要求降低了。同时,硬件的迅速发展使机器成本不断降低——这也是近年来深度学习流行的原因之一。
1.2 向量距离计算
前面详细讲解了如何使用向量来表示各类特征。除了将向量 x 作为特征输入模型,我们有时也需要通过向量之间的距离来衡量特征之间的差异。
有多种方法可以度量向量之间的距离,每种方法都有其应用场景和优缺点。这些方法有一些共性,列举如下。
同一性:d(x,y)=0,同一点到自身的距离为0。此时,也可写成 x=y。
非负性:d(x,y)≥0,距离不能小于0。
对称性:d(x,y)=d(y,x)。
直递性:d(x,y)≤d(x,z)+d(z,y),即三角形法则(由3个点组成的三角形,两边长之和大于等于第三边)。
很明显,多种函数可以同时满足上述条件,理论上,这些函数都可用于度量距离。但是,这些函数中的大部分在机器学习中并不常用。下面介绍机器学习中的常用距离。
欧氏距离(Euclidean Distance)是机器学习中最为常见的距离之一,它源自两点之间的距离公式。两个特征向量分别为 〖〗x=[x1,x2,⋯,xn]Ty=〖[y1,y2,⋯,yn]〗T
欧氏距离的计算公式如下: ▒〖〗dEuclidean(x,y)=√(∑(i=1)n▒〖(xi−yi)〗2)=√((x−y)T(x−y))
d_Euclidean (x,y) 常写作 ‖x,y‖。特别地,‖x‖ 表示 x 距离原点的欧氏距离,‖x‖=√(∑_(i=1)^n▒〖(x_i)〗^2 )。
曼哈顿距离(Manhattan Distance)也可用于度量两点之间的距离。想象一下:你在曼哈顿街头,要开车从一个十字路口到另一个十字路口,实际驾驶距离是这两个十字路口之间的直线距离吗?显然不是——除非你能穿越大楼。这里的实际驾驶距离就是曼哈顿距离。曼哈顿距离也称为城市街区距离(City Block Distance),其计算公式如下。
d_Manhattan (x,y)=∑_(i=1)^n▒|x_i-y_i |
d_Manhattan (x,y) 也常写作 |x,y|。特别地,|x| 表示 x 距离原点的曼哈顿距离,即 |x|=∑_(i=1)^n▒|x_i | 。
在国际象棋棋盘上,国王可以朝8个方向移动。国王移动到目标点所需的步数就是切比雪夫距离(Chebyshev Distance)。切比雪夫距离用于计算各维度数值差中的最大值,计算公式如下:
▒dManhattan(x,y)=∑(i=1)n▒|xi−yi|
切比雪夫距离和曼哈顿距离的区别在于:在斜向移动时,曼哈顿距离所需的距离为2,切比雪夫距离所需的距离为1。
广义圆可以定义为到圆心距离相等的点的集合。分别使用以上介绍的三种距离画出来的“圆”,如图1-4所示。

图1-4
闵可夫斯基距离(MinkowskiDistance)的计算公式如下。
▒〖〖〗〗d(Minkowski)(x,y)=(∑(i=1)n▒〖〖|x〗i−yi|〗p)(1/p)
其中,p 是一个变参数。
闵可夫斯基距离公式其实是一个通项公式。以上介绍的三种距离其实都是闵可夫斯基距离的特例。
当 p=1 时,就是曼哈顿距离。
当 p=2 时,就是欧氏距离。
当 p→∞ 时,就是切比雪夫距离。
以上三种距离都有一个缺点,就是容易受特征量纲的影响。例如,用一个2维特征表示人的体重和身高,体重的单位为千克,身高的单位为毫米,如 〖[60,1700]〗^T。此时,体重的数量级远小于身高,这会导致在计算距离时放大身高的作用。
我们以欧氏距离为例,讨论如何解决这个问题。对数据进行归一化,即将各个维度的均值和方差分别归一至 (0,1),以消除量纲不同带来的差异。归一化在各个维度独立进行,公式如下: x_i^'=x_i/σ_ix_i^'=x_i/σ_i
σ_i 为第 i 维特征所对应的标准差。修正后的距离计算公式如下。
d_(Standardized Euclidean) (x,y)=√(∑_(i=1)^n▒〖(x_i^'-y_i^')〗^2 )d_(Standardized Euclidean) (x,y)=√(∑_(i=1)^n▒〖(x_i^'-y_i^')〗^2 )
上述方法称作标准化欧氏距离(Standardized Euclidean Distance)。
在提取特征时,特征之间并不是独立的,维度之间往往存在冗余的问题。例如,体重和身高之间就存在较强的相关性。特征冗余带来的影响是:某些因素在各个维度重复出现,在计算距离时会被重复计算,从而使其影响被放大。为了降低特征冗余带来的影响,可以使用马氏距离(Mahalanobis Distance)进行计算,公式如下:
dMahalanobis(x,y)=√((x−y)TΣ(−1)(x−y))
这里使用了向量的表示方式。Σ 为各维度的协方差矩阵,其中,对角线元素表示各维度自身的方差,非对角线元素表示各维度之间的相关性。可以看出,对于马氏距离,如果不考虑特征之间的相关性(非对角线元素为0),就会退化为标准欧氏距离。在使用标准欧氏距离或马氏距离时,因为涉及估计方差(协方差矩阵),所以需要一定的数据量,且数据量越大,方差(协方差矩阵)的估计结果越准。
我们用one-hot向量来表示所观看的电影的特征。假设有五部电影,那么向量的维度为5维。在看过的电影的特征位置写1,在没看过的电影的特征位置写0。我们是否可以通过one-hot向量的距离来度量两个人观影习惯的差异呢?答案是:不可以。因为我们无法确定这两个人是否全部看过这五部电影——如果没有观影,那么自然无法提供关于喜好的信息,而在都为0的位置计算出来的距离是没有意义的。假设有三个人,user1和user2共同观看了两部电影,user1和user3共同观看了一部电影,则他们观看电影所对应的向量分别为
user1=[1,0,0,1,0]
user2=[1,0,1,1,0]
user3=[0,0,0,1,0]
而我们的期望是 user1 和 user2 的距离更近。使用欧氏距离计算 user1 和 user2、user1 和 user3 的距离,公式如下。
d_Euclidean (user1,user2)=1
d_Euclidean (user1,user3)=1
user1 和 user2、user1 和 user3 的欧氏距离相等,与我们的期望不符。因此,欧氏距离不能在此场景中有效度量观影习惯的差异。
然而,对于两个人都看过的电影,即两个人都为1的位置,却能反映出两个人的喜好相同。可以使用Jaccard距离度量两个集合之间的差异,计算公式如下。
d_Jaccard (user1,user2)=1-|A∩B|/|A∪B|
在这里,A 和 B 分别为这两个人看过的电影的集合,A∩B 为这两个人看过的电影的交集,A∪B 为这两个人看过的电影的并集。使用Jaccard距离进行计算,公式如下。
d_Jaccard (user1,user2)=1-2/3=1/3
d_Jaccard (user1,user3)=1-1/2=1/2
显然,此时 d_Jaccard (user1,user2)<d_Jaccard (user1,user3),user1 和 user2 之间的距离比较近,而这也符合我们的认知。Jaccard距离的用途很广,可用于度量购物偏好的差异、文章内容的差异等具有同质集合属性的特征。
在机器学习中,除了距离,也常使用相似度来度量两个向量。顾名思义,两个向量的相似度越高,说明它们越相似。因此,相似度和距离成反相关。
余弦相似度(CosineSimilarity)是一种常见的相似度,其计算公式如下:
▒〖〗cos(x,y)=(∑(i=1)n▒〖xiyi〗)/‖x‖‖y‖
余弦相似度的值域是 [-1,+1]。它用于衡量两个向量的夹角,夹角越小,两个向量越相似。+1 表示两个向量的相似度相同,即两个向量的方向完全相同(cos0=1)。-1 则表示两个向量的方向完全相反(cosπ=-1),此时两个向量呈高度负相关。当余弦相似度为0时,两个向量是互相垂直的(cos π/2=0),称作正交。相互正交的向量彼此线性无关。
余弦相似度,如图1-5所示。

图1-5
可以看出,余弦相似度和向量的长度无关,它是用来衡量各个维度比例的相似性的。当两个向量各维度的比例相同时,它们的夹角为0,相似度为1。
∑_(i=1)^n▒〖x_i y_i 〗 称为向量 x 和 y 的内积,记作 〈x,y〉=∑_(i=1)^n▒〖x_i y_i 〗=x^T y。
内积可以理解成
未归一化的余弦相似度,值域为 (-∞,+∞),有时也用于度量向量的相似性。‖x‖ 为归一化因子,用于将向量 x 的长度归一至1。相比较而言,cos(x,y) 只考虑了 x 和 y 的角度差,〈x,y〉 则综合考虑了 x 和 y 的角度差与长度差。
有时需要将余弦相似度转换为余弦距离,公式如下。
d_cos (x,y)=1-cos(x,y)
特别地,当 ‖x‖=1、‖y‖=1 时,d_cos (x,y) 和 d_Euclidean (x,y) 有如下关系。
d_Euclidean (x,y)=√(2d_cos (x,y)))=√(2(1-cos(x,y)))
即欧氏距离和余弦相似度之间存在单调关系。
1.3 向量的基本性质
1.3.1 向量的基本运算
向量可以看作一个矢量,即既有大小,又有方向的量。例如,x=[■(1@3)] 在2维坐标系中,
如图1-6所示。

图1-6
向量之间可以进行数学运算,例如对于2维向量 x=[■(1@3)] 和 y=[■(2@4)],加法运算为 x+y=[■(1+2@3+4)]
上式的几何意义,如图1-7所示。
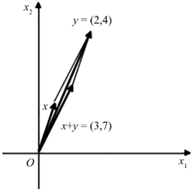
图1-7
向量也可以和一个常数相乘,例如 kx=[■(k@3k)]
几何意义相当于对把向量进行 k 倍的缩放。如果 k<0,就相当于把向量的朝向取反,如图1-8所示。

图1-8
如果一个向量可以由其他的向量加权求和表示,如
α_1=k_2 α_2+⋯+k_m α_m
则称 α_1 可以由 α_2~α_m 线性表示。
在Attention模型中,模型输出其实也是将输入的特征向量组 α_1,⋯,α_m 进行线性加权求和,即
h_1=k_11 α_1+⋯+k_1m α_m
⋮
h_m=k_m1 α_1+⋯+k_mm α_m
只不过上式的权重 k 也是通过模型计算产生的。
当使用多层Attention模型时,第二层的输出 q_i 为 h_1,⋯,h_m 的线性组合,即
q_i=w_i1 h_1+⋯+w_im h_m
=w_i1 (k_11 α_1+⋯+k_1m α_m )+⋯+w_im (k_m1 α_1+⋯+k_mm α_m )
=(∑_(j=1)^m▒〖w_ij k_j1 〗) α_1+⋯+(∑_(j=1)^m▒〖w_ij k_jm 〗) α_m
可以发现,从效果看,q_i 可以直接是 α_1,⋯,α_m 的线性组合,从而中间层 h_1,⋯,h_m 就显得有些多余。这说明Attention模型一定要对输出进行非线性变换,否则深度就丧失了意义。这也是Transformer模块必须有前馈层FFN的原因之一。
1.3.2 线性相关和线性无关
如果有一组向量 α_1,⋯,α_m 存在不全为0的数 k_1,⋯,k_m,使得
k_1 α_1+⋯+k_m α_m=O
其中 O 为各个元素都为0的向量,就称 α_1,⋯,α_m 是线性相关的,否则称 α_1,⋯,α_m 是线性无关的。如果 α_1,⋯,α_m 线性相关,并且 k_j≠0,那么
α_j=k_1/k_j α_1+⋯+k_(j-1)/k_j α_(j-1)+k_(j+1)/k_j α_(j+1)+⋯+k_m/k_j α_m
即在这组向量中,存在向量 α_j 可以由其他向量来表示。
例如,对于向量 α_1=[■(4@1@-1)],α_2=[■(1@2@-1)],α_3=[■(2@-3@1)],因为 α_1=2α_2+α_3,即
α_1 可以由 α_2 和 α_3 线性表示,所以这组向量则是线性相关的。
线性相关意味着这组向量中在方向上存在冗余。例如,有两个地方A和B,A在B的东边1千米、南边1千米,这时A在B东南 √2 千米就是冗余信息,因为通过东边和南边已经完全可以推断出东南方向的信息了,如图1-9所示。

图1-9
如果去除这组向量中的 α_1,仅保留 α_2 和 α_3,那么有且仅有 k_2=k_3=0 时 〖k_2 α〗_2+k_3 α_3=0,其他情况都不为0,因此 α_2 和 α_3 线性无关。
如果有一组向量 α_1,⋯,α_m 线性无关,那么它们之中的任何一个向量都不能由其他的向量进行线性表示,这组向量也就不存在冗余的情况。有一个结论:在n维向量中,一组线性无关的向量最多有n个向量。但是,我们可以找到无数组线性无关的向量。
1.3.3 向量的投影和正交
如果有两个向量 x 和 y,它们在空间中各自表示一个方向,就把 x^T y 称为 x 在 y 上的投影,也可以称为 y 在 x 上的投影,如图1-10所示。

图1-10
投影的意义在于 y 中有多少 x 的信息,就好比从东南 √2 千米可以推断方向“南”的里程为1千米。
特别的,如果两个向量在空间中是垂直的,我们就称它们之间正交,此时投影长度为0。例如,东和南就是正交。如果两个向量 x 和 y 正交,就说明 y 中不包含任何 x 的信息,如图1-11所示。
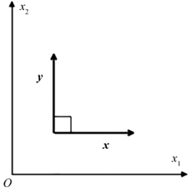
图1-11
两个非0向量正交的充要条件为
x^T y=0
且 x≠0 和 y≠0。特别的,如果 ‖y‖=1,则称为标准投影。
在 n 维空间中,最多可以找到 n 个相互正交的向量 v_1,〖⋯,v〗_n,v_i≠0。例如,在2维空间中东和南相互正交,在3维空间中东,南和上相互正交。
一组相互正交的向量,它们必然是线性无关的。我们使用反证法进行证明。
一组向量 v_1,〖⋯,v〗_n(v_i≠0)相互正交,它们之间线性相关,例如 v_1 可以由其他向量表示,即
v_1=k_2 v_2+⋯+k_n v_n
两边都乘以 v_1^T,可得
v_1^T v_1=k_2 〖v_1^T v〗_2+⋯+k_n 〖v_1^T v〗_n=k_2 0+⋯+k_n 0=0
但是,因为 v_1≠0,所以 v_1^T v_1≠0,这就出现了矛盾。因此,假设不成立,即 v_1,〖⋯,v〗_n 是线性无关的。
如果这 n 个相互正交的向量 v_1,〖⋯,v〗_n 满足 ‖v_i ‖=1,i=1,⋯,n,那么称 v_1,〖⋯,v〗_n 为标准正交基。如果我们通过一组标准正交基 v_1,〖⋯,v〗_n 对向量 x 进行投影,就可以得到一个新的向量:
y=[■(x^T v_1@⋮@x^T v_n )]
例如,在2维空间中,x=[■(2@3)],v_1=[■(1/√2@1/√2)],v_2=[■((-1)/√2@1/√2)],投影如图1-12所示。
可以看出,使用标准正交基进行投影,其实就是同样的一个数据在新坐标系下的新坐
标,而 x 其实就是在标准正交基下 [■(1@0)] 和 [■(0@1)] 的投影。

图1-12
但是需要注意,标准正交基并不是唯一的,例如以下都是标准正交基的投影。

使用不同的标准正交基,相当于选择了不同的坐标系,同一个数据点在不同坐标系下对应于不同的坐标。
如果一组向量为标准正交基,那么它们一定是一个线性无关组,但是,反过来并不成立。不过,施密特正交化可以将一个线性无关组转换成正交向量组,再将正交向量组的每个向量进行单位化,最终得到一个标准正交基。例如,有线性无关向量组 α_1,⋯,α_m,我们先构建正交向量组 β_1,⋯,β_m,施密特正交化的具体方法如下。
β_1=α_1
β_2=α_2-kβ_1
为了使 β_1 和 β_2 正交,即
〈β_1,β_2 〉=〈α_1,α_2-kβ_1 〉=〈α_1,α_2 〉-k〈α_1,β_1 〉=0
可以得到
k=〈α_1,α_2 〉/〈α_1,β_1 〉 =〈β_1,α_2 〉/〈β_1,β_1 〉
所以
β_2=α_2-〈β_1,α_2 〉/〈β_1,β_1 〉 β_1
同理,我们可以构造向量 β_3=α_2-k_1 β_1-k_2 β_2,满足
〈β_3,β_1 〉=0
〈β_3,β_2 〉=0
从而求得
β_3=α_2-〈β_1,α_3 〉/〈β_1,β_1 〉 β_1-〈β_2,α_3 〉/〈β_2,β_2 〉 β_2
依此类推:
β_j=α_j-∑_(i=1)^(j-1)▒〖〈β_i,α_j 〉/〈β_i,β_i 〉 β_i 〗
通过上述公式,我们就可以的得到正交向量组:
β_1,⋯,β_m
最后,将向量组中的每个向量进行单位化,就能得到标准正交基,具体如下。
β_1/‖β_1 ‖ ,⋯,β_m/‖β_m ‖
1.4 矩阵的基本概念
1.线性变换
对于向量 x,出于不同的需求,我们可能需要从一个新角度进行观测,这个新角度有可能会对某些特征进行放大,同时会忽略一些无关因素。例如,一个学生有语文、数学、外语三门课的成绩,不同的专业对各科成绩及它们之间的组合的要求是不一样的,如学习翻译需要语文和外语成绩好,学习计算机需要数学和外语成绩好。因此,不同的专业在招生时需要考察成绩的不同方面,即观测角度不同,从数学的角度看,就是对考试成绩进行了坐标变换。那么,具体怎么做呢?我们可以构建一个新的坐标系,y 为 x 在新坐标系下的坐标。例如,在2维空间中,使用向量 w_1 和 w_2 构建新的坐标系,这里注意 w_1 和 w_2 不需要正交,y 就是新坐标系下的坐标,即
y=[■(w1Tx@w2Tx)]
例如,有 x=[■(2@1)],w_1=[■(1@2)],w_2=[■(2@1)],那么 y=[■(4@5)],坐标变换如图1-13所示。
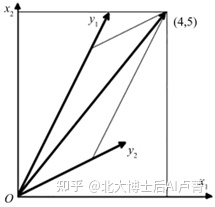
图1-13
我们一般把这种坐标变换写成
W=[■(w1T@w2T)]=[■(w11,w12@w21,w22)]
W 称为矩阵,表示特定的坐标变换形式。使用矩阵 W 对向量 x 进行坐标变换,得到结果 y,一般写成矩阵乘法,即
y=Wx
上述运算也称为线性变换。
更一般的,向量变化前后的维度不一定需要相等。例如,对于 n 维向量 x,选用 m 个坐标轴进行重新观测,那么

坐标变换就为

n 维向量 x,通过 W 进行变换,得到 m 维向量 y。
矩阵 W 一共有 m 行 n 列,记为 W∈R^(m×n)。特别的,如果 m=n,即 W 的行列数相等,我们就称 W 为方阵。
需要注意的是,矩阵的列数要和向量的行数相等,这样线性变换才有意义,即 W∈R^(m×n),x∈R^(n×1)。
特别的,对于2维向量,如果 w_1=[■(1@0)],w_2=[■(0@1)],W=[■(1&0@0&1)],对任意 x 都有
x≡Wx
坐标不会发生变换,也就是说,我们默认向量所在的坐标系为 [■(1@0)][■(0@1)]。一般来说,我
们把对角线元素为1,其他位置元素都为0的矩阵称为单位矩阵,用 E 表示。
从坐标变换的角度理解矩阵,有以下三点需要注意。
新坐标系下的原点并不发生变化。
新坐标系的坐标轴不一定相互垂直。
新坐标系的坐标刻度未必是1,也就是说,并不要求 ‖w_i ‖=1,坐标变换就会起到伸缩向量的作用,即向量到原点(原点本身不变)的距离会发生变化。
y=Wx
‖y‖≠‖x‖
2.线性变换的几何意义
我们也可以从几何的角度看向量。例如,对于2维向量 x=[■(x_1@x_2 )],它对应于2维坐标
系中的一个点,如图1-14所示。

图1-14
在机器学习中,为了数据之间更加有区分度,以便后续处理,我们往往需要对数据点进行一些基本操作,具体如下。
伸缩,即 x^'=[■(ax_1@bx_2 )]x^'=[■(ax_1@bx_2 )] ,在两个坐标轴的方向进行放缩,如图1-15所示。

图1-15
旋转,如图1-16所示,坐标点围绕坐标轴,逆时针旋转 θ,即

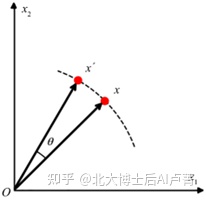
图1-16
如果对一个向量依次进行旋转和伸缩操作,就可以写成

我们重新整理一下,上式可以写成

其中
w_11=acosθ
w_12=-asinθ
w_21=bsinθ
w_22=bcosθ
因此,w_11、w_12、w_21、w_22 对应于一套旋转缩放操作。因此,可以写成
W=[■(w_11,w_12@w_21,w_22 )]
x^'=Wx
所以说,对向量进行旋转和缩放也是一种线性变换。
对向量常见的操作还有平移,即 x^'=[■(x_1+〖w0〗_1@x_2+〖w0〗_2 )]=x+w0,w0=[■(〖w0〗_1@〖w0〗_2 )],如图1-17所示。
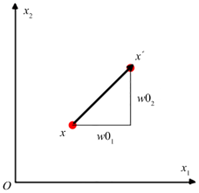
图1-17
对向量的平移也可以写成线性变换的形式,不过这里需要对原向量 x=[■(x_1@x_2 )] 进行改造,
增加一个维度并取值为1,再进行线性变换,即
x^'=[■(1&0&〖w0〗_1@0&1&〖w0〗_2 )][■(x_1@x_2@1)]
我们可以看到,在低维空间的平移操作,等价于高维空间中的线性变换。在线性回归、逻辑回归和神经网络中,经常可以看到如下写法。
y=Wx
这里并非没有偏置,只不过是把偏置隐藏写入 W,并且 x 增加了取值为1的维度。
3.矩阵的乘法
对于向量 x,我们可以依次使用矩阵 W 和 S 对它进行连续两次线性变换,即
z=Wx
y=Sz
所以,有
y=SWx
但是,必须注意这里 W 的列数和 S 的行数是相等的,即当 W∈R^(m×n) 时,S∈R^(n×k)。
上述操作也可以换一个角度理解。将矩阵 W 和矩阵 S 相乘,即 M=WS,再用 M 对向量 x 进行线性变换,即 y=Mx。例如

这里可以发现,如果对矩阵进行连续两次线性变换,在效果上其实等价于一次,这也是深度神经网络中必须使用激活函数的原因。
如果 W∈R^(n×n) 和 S∈R^(n×n) 为同尺寸的方阵,那么 WS 和 SW 都可以进行运算。但是,一般来说,WS≠SW,即进行多次线性变换时,顺序也很重要。
在机器学习中,线性变换是常见的操作,可以进行升维,也可以进行降维,它们有不同的作用。例如,x∈R^(n×1),W∈R^(m×n),那么 x^'=Wx∈R^(m×1)。如果 m>n,就相当于把向量映射至高维空间,虽然产生了特征冗余,但合理的线性变换可以使数据在空间中排列更利于分类。如果 m<n,就是进行特征降维,特征降维一般是为了去除噪声,例如主成分分析(PCA)、神经网络自动特征筛选。
4.转置矩阵
把矩阵 W∈R^(m×n) 行列对调,得到的矩阵记为 W^T∈R^(n×m),W^T 称为 W 的转置矩阵,

如果 A∈R^(m×n),B∈R^(m×n),那么
(A+B)^T=A^T+B^T
如果 A∈R^(m×n),B∈R^(n×k),那么
(AB)^T=B^T A^T
如果对于方阵 W∈R^(n×n),满足 W=W^T,那么称 W 为对称矩阵。
W=[■(w_11&…&w_1n@…&…&…@w_n1&…&w_nn )]为对称矩阵的充要条件是对于任意 i 和 j 均满足 w_ij=w_ji。
对于任意矩阵 W∈R^(m×n),有
〖(WW^T)〗^T=〖(W^T)〗^T W^T=WW^T
因此,WW^T 为对称矩阵。同理,W^T W 也为对称矩阵。
5.矩阵的迹
对于方阵 W∈R^(n×n),我们把它对角线上各个元素之和称为矩阵 W 的迹,一般记作tr(W),例如矩阵

那么
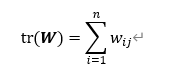
如果有两个方阵 A∈R^(n×n) 和 B∈R^(n×n),那么它们的迹有如下关系。
tr(AB)=tr(BA)。
tr(mA+nB)=m tr(A)+n tr(B)。
1.4.2 矩阵和神经网络
在神经网络中,一般对向量 x^((1)) 进行一次线性变换后,会再进行平移,即
x^((2))=W^((1)) x^((1))+〖w0〗^((1))
这就是一层神经网络,W^((1)) 称作权重,〖w0〗^((1)) 称作偏置。特征可以经过多层神经网络,不断的变换,最终使得特征便于分类。例如,我们把 x^((1)) 经过两层神经网络变成 x^((3)),具体如下。
x^((2))=W^((1)) x^((1))+〖w0〗^((1))
x^((3))=W^((2)) x^((2))+〖w0〗^((2))
但是,这样的多层变换其实等价于一层变换,达不到想要多层效果,原因在于
x^((3))=W^((2) ) (W^((1) ) x^((1) )+〖w0〗^((1) ) )+〖w0〗^((2) )
=W^((2) ) W^((1)) x^((1))+W^((2) ) 〖w0〗^((1))+〖w0〗^((2))
令 W^((2) ) W^((1))=A,W^((2) ) 〖w0〗^((1))+〖w0〗^((2))=B,那么
x^((3))=Ax^((1))+B
这说明,虽然 x^((1)) 经过了两层神经网络,但效果其实和经过一层神经网络是一样的。为了解决这个问题,一般在经过一层神经网络后会进行一次非线性激活,即
x^((2))=f(W^((1) ) x^((1) )+〖w0〗^((1) ) )
f 为非线性函数,常见的如sigmoid、Tanh、ReLU等。以ReLU为例,如图1-18所示,公式如下。


图1-18
例如:

因此,我们对特征向量进行“线性变换+坐标平移+非线性激活”,称为一层神经网络。
神经网络的特征变换,可以将无法进行分类的特征经过转换,变成有利于分类。例如,
有4个数据点 x1=[■(0@0)]、x2=[■(0@1)]、x3=[■(1@0)]、x4=[■(1@1)],其中 x1 和 x4 是一类,x2 和
x3 是一类,它们的分布如图1-19所示。

图1-19
我们不可能找到一条直线,将两类数据完全分开,这种问题称作线性不可分。但是,我们可以让特征经过一层神经网络并使用ReLU函数来激活,即


这样,线性不可分的数据就会变成线性可分的数据,如图1-20所示。

图1-20
数据变换完成后,就可以使用逻辑回归等较为简单的模型进行分类。这样做也能达到不错的效果。
1.4.3 矩阵的秩
对于矩阵 W∈R^(m×n),我们可以把它看成是由 m 个 n 维行向量组成的,即
W=[■(v1@⋮@vm)]
如果这 m 个向量 v_1,⋯,v_m 至多能找到 r 个向量,它们彼此线性无关,r 就是 W 的行秩,显然 r≤m。
例如:
W=[■(4,1,−1,3@1,2,−1,1@2,−3,1,1)]
对应的行向量 v_1=[4,1,-1,3],v_2=[1,2,-1,1],v_3=[2,-3,1,1],所以,有 v_1=2v_2+v_3,而 v_2≠kv_3,因此,在 v_1、v_2、v_3 中最多能找出2个线性无关的向量,矩阵 W 的行秩为2。
同样,我们也可以从列向量的角度分析,得到类似的列秩,可以证明矩阵的行秩=列秩,因此后文统一用秩作为统一表达。并且,对于 W∈R^(m×n) 的矩阵,秩 r≤min(m,n),当 r=min(m,n) 时,称 W 为满秩矩阵。
秩有什么意义呢?例如 W∈R^(m×n),它的秩为 r,通过 W 进行线性变换的向量 Wx 虽然是m维度向量,但是真实的维度却是 r 维。举个极端的例子加深下印象,例如:
W=[■(1&0&0@0&2&0@0&0&0@0&0&0)]
W 的秩 r=2。那么,对于向量 x=[■(x_1@x_2@x_3 )],y=Wx=[■(x_1@〖2x〗_2@0@0)],尽管 W 映射完后 y 是4
维向量,但它始终被束缚在2维空间内。
再如,使用
W=[■(4,1,-1,3@1,2,-1,1@2,-3,1,1)]=[■(v_1@v_2@v_3 )]
进行线性变换。因为
v_1=2v_2+v_3
所以,W 的秩为2。
我们如果进行线性变换 y=Wx,尽管结果是3维向量,但是 W 的秩为2,y 始终束缚在 v_2 和 v_3 构建的平面上,推导如下。
因为
v_1=2v_2+v_3
所以
y=[■(y_1@y_2@y_3 )]=[■(v_1@v_2@v_3 )]x=[■(2v_2+v_3@v_2@v_3 )]x=[■(2v_2 x+v_3 x@v_2 x@v_3 x)]
也即 y_1=2y_2+y_3。
这就好比,我们平时看到的一些风景图片,虽然能产生3维立体的视觉效果,但是它本质仍然是2维的平面。
综上所述,神经网络中各层使用 W∈R^(m×n) 进行特征变换时,变换的结果未必真的是 n 维向量,它其实是被束缚在r维的空间中,r≤min(m,n)。
1.5 一些特殊的矩阵
1.5.1 矩阵的逆和广义逆
在矩阵的乘法中,有一种矩阵起着特殊的作用,如同数的乘法中的1,这种矩阵被称为单位矩阵。它是个方阵,从左上角到右下角的对角线(称为主对角线)上的元素均为1。除此以外全都为0。我们一般记为 E,即
E=[■(1&0&⋯&0@0&1&⋯&0@⋮&⋮&⋱&⋮@0&0&⋯&1)]
可以看出,E 的列向量相互正交,行向量有同样的结论。
E 不会对任何向量进行有效果的变换,即
Ex=x
如果 A 是方阵,则满足
AE=EA=A
如果有两个 n 阶方阵 A 和 B,它们之间符合性质
AB=BA=E
那么我们称 A 和 B 互为逆矩阵。逆矩阵类似于实数里面的倒数。
我们一般把 A 的逆矩阵记为 A^(-1),即 〖B=A〗^(-1),〖A=B〗^(-1),因此可以写成
AA^(-1)=A^(-1) A=E
逆矩阵类似于倒数,相比于0不存在倒数,A 的逆矩阵存在条件为,A 为满秩方阵。
如果有 A∈R^(n×n) 和 B∈R^(n×n),且 A、B、AB 都存在逆矩阵,那么有如下结论。
〖(AB)〗^(-1)=B^(-1) A^(-1)
通过逆矩阵的定义可以知道,因为 AA^(-1)=E,所以可以得到
AA^(-1) x=x
即矩阵和它的逆矩阵其实对应的是一对相反线性变换。但是,逆矩阵的定义要求 A 必须为方阵,这极大的限制了使用场景。
其实,如果仅根据 AA^(-1) x=x 定义 A 的逆矩阵,其实并不是要求 A 为方阵,如果 A∈R^(m×n),那么满足 A^(-1)∈R^(n×m) 即可。因此,我们从更加广义的角度定义 A∈R^(m×n) 的逆矩阵,记为 A^+∈R^(n×m),满足
AA^+ x=x
A^+ 被称作矩阵的广义逆矩阵或者伪逆矩阵。我们不加证明给出如下结论:
A^+=〖〖(A〗^T A)〗^(-1) A^T
可以发现,当 A 为方阵且存在逆矩阵时,A^(-1)=A^+,即逆矩阵是伪逆矩阵的一个特例。
在线性回归中,y=x^T w,对于训练集 〖{x_((i) ),y_((i) )}〗_(i=1)^N,我们可以知道
Xw=Y
其中
X=[■(x_((1))^T@⋮@x_((N))^T )],Y=[■(y_((i) )@⋮@y_((N) ) )]
那么根据广义逆矩阵的定义,可得
w=X^+ Y=〖〖(X〗^T X)〗^(-1) X^T Y
因此,在数据量不大,维度不高的时候,线性回归的 w 可以由上式直接求出,不需使用梯度下降法。
1.5.2 正交矩阵
如果一个 n 阶方阵 A=[v_1,〖⋯,v〗_n],并且 v_1~v_n 彼此组成标准正交基,即
v_i^T v_j=0,i≠j
且
‖v_j ‖=1,j=1,⋯,n
那么我们称 A 为正交矩阵。
在实数范围内,正交矩阵也称为酉矩阵。正交矩阵有如下性质。

根据上述性质和逆矩阵的定义,很容易得到 A^T=A^(-1)。这是正交矩阵一个非常重要的性质——正交矩阵的转置矩阵和逆矩阵相等。
如果矩阵 A 为正交矩阵,对向量 x 进行线性变换,即
y=Ax
我们称之为正交变换。如果我们从坐标系变换的角度看正交变换,那么在新坐标系中,坐标轴之间都相互垂直且不进行长度缩放,如图1-21所示。

图1-21
我们知道,向量到原点的欧氏距离
‖x‖=x^T x
那么
‖y‖=y^T y=(Ax)^T Ax=x^T A^T Ax=x^T x=‖x‖
也就是说,使用正交矩阵进行线性变换,不会改变向量到原点的距离。从旋转的角度理解正交变换,正交变换只让向量相对原点进行旋转,且不会对长度进行改变。
另一方面,我们使用正交矩阵 A 对两个向量进行线性变换,即
y=Ax
z=Av
那么 y 和 z 之间的 cosine 相似度为
cosine(y,z)=(y^T z)/‖y‖‖z‖ =(x^T A^T Av)/‖x‖‖v‖ =(x^T v)/‖x‖‖v‖ =cosine(x,v)
也就是说,正交变换不会改变向量之间的夹角。
我们知道矩阵的迹有如下性质 tr(AB)=tr(BA),那么对于正交矩阵 A 和一个矩阵 W,有如下性质。
tr(AWA^T )=tr(AWA^(-1) )=tr(WA^(-1) A)=tr(WE)=tr(W)
即 AWA^T 和 W 的主对角线元素之和相等。
第2章 线性代数在深度学习中的应用
2.1 特征值和特征向量
2.1.1 特征值和特征向量的定义
通过前面的学习,我们知道线性变换可以看成对向量进行坐标系的切换,但是在切换坐标系的时候,存在某些向量的方向不会被改变,只是坐标发生了拉伸缩放,这就是旋转不变性。例如:
W=[■(1,2@3,4)]
那么,对于向量 [■(0.4160@0.9094)] 和向量 [■(-0.8246@0.5658)] 是不会进行旋转的,只会在长度进行缩放,即

需要注意的是,只有在 W 为方阵时,讨论旋转不变性才有意义。当 W 不为方阵时,线性变换会使特征维度发生变化,自然就不存在所谓的“方向不变”——就像我们无法在二维平面讨论三维空间的事情。
我们把这种方向不变的特殊向量叫作特征向量,根据上述分析,方阵 W 的特征向量的定义如下。
Wv=λv
v≠0
即 v 的方向不被改变,但是会产生 λ 倍的缩放,λ 也被称作特征值。需要注意的是,特征值和特征向量是成对出现的。
矩阵一般有多个特征值和特征向量。例如,对于矩阵
W=[■(1,2@3,4)]
它有两组特征向量和特征值,分别为

同一个方向的特征向量通过缩放可以有无数个。例如,下面都是特征向量和对应的特征值。

但是,上述特征向量,都是通过对 v_1 和 v_2 的线性缩放得到的,并不是真正独立的特征向量。那么,我们怎么求特征值和特征向量呢?根据定义,求特征值其实就是解方程
|λE-W|=0
特征值求完之后,我们将其带入
Wv=λv
可以解出对应的特征向量 v。
方程 |λE-W| 是一个 n 阶方程,因此有且仅有 n 个解,那么 n 阶方阵就有 n 个特征值。但是,这 n 个解可能存在重根,例如方程
(λ-1)^2 (λ-3)=0
的3个解为
λ_1=3,λ_2=λ_3=1
λ_2=λ_3=1 为重根。
因此,一个 n 阶方阵有且只有 n 个特征值,这 n 个特征值有可能存在重根。不同特征值(非重根)对应的特征向量线性无关。重根对应的特征向量相关性比较复杂,下面我们看下重根对应的特征向量之间的关系。

在这里,λ_2=λ_3=2 就是重根,但是它们对应的特征向量 v_2 和 v_3 线性无关。
另外,由于 λ_1≠λ_2≠λ_4,λ_1≠λ_3≠λ_4,因此 v_1、v_2、v_3、v_4 线性无关。

λ_2=λ_3=1 为重根,但是它们对应的特征向量线性相关(相等)。在这里,v_1 和 v_2、v_1 和 v_3 都线性无关。
下面我们给出关于特征值和特征向量的一般性结论,对于方阵 W∈R^(n×n),有如下结论。
特征值的个数为 n,这里包括重根。
不同特征值对应的特征向量之间线性无关。
如果特征值为 r 重根,它最多对应 r 个线性无关的特征向量。
可以看出,如果矩阵的特征值都不相等,即不存在重根,那么它所对应的特征向量一定是线性无关的。即使矩阵存在 r 重根,r 重根对应的 r 个特征向量是否线性无关也没有定论。
如果 W 的特征值 λ 为 m 重根,那么对应于特征向量 v_1~v_m,向量 v 为 v_1~v_m 的线性表示,即
v=k_1 v_1+⋯+k_m v_m
那么
Wv=k_1 Wv_1+⋯+k_m 〖Wv〗_m=k_1 λv_1+⋯+k_m λv_m=λ(k_1 v_1+⋯+k_m v_m )=λv
即 v 也是 W 的特征向量,对应的特征值也是 λ。
特征值还有两个常用的性质。
如果 〖A∈R〗^(m×n),〖B∈R〗^(n×m),那么
tr(AB)=tr(BA)
如果方阵 W∈R^(n×n) 的秩为 m,那么它有 m 个特征值 λ_1~λ_m,特征值和迹有如下关系。
tr(W)=∑_(i=1)^n▒w_ii =∑_(i=1)^m▒λ_i
2.1.2 一般矩阵的特征分解
n 阶矩阵 W∈R^(n×n) 有一组线性无关的特征向量 v_1,⋯,v_n,可以将它们写成矩阵形式 P=[v_1,〖⋯,v〗_n],P 也是一个 n 阶方阵。根据特征向量和特征值的定义,我们可以知道:
[Wv_1,⋯,〖Wv〗_n ]=[λ_1 v_1,⋯,λ_n v_n]
出于习惯,一般让 λ_1≥λ_2≥⋯〖≥λ〗_n,即特征值按降序排列。
上面的等式也可写成
WP=PΛ
Λ=[■(λ_1&⋯&0@⋮&⋱&⋮@0&⋯&λ_n )] 为对角矩阵。
因为 v_1~v_n 线性无关,所以 P 存在逆矩阵 P^(-1),容易推理出
W=PΛP^(-1)
这种分解称为特征分解。
需要注意的是,矩阵 W∈R^(n×n) 能进行特征分解的前提条件是 W 有 n 个线性无关的特征向量。
在RNN这类循环神经网络中使用梯度下降法时,会出现项 W^K,即 W 自乘 K 次。我们可以进行如下分解。
W^K=PΛP^(-1) PΛP^(-1)⋯PΛP^(-1)=PΛ^K P^(-1)
Λ^K=[■(λ_1^K&⋯&0@⋮&⋱&⋮@0&⋯&λ_n^K )]
下面,我们分析一下 K 较大(网络较深)时,λ_i^K 对最终结果的影响。
如果 λ_i<1,那么 λ_i^K→0,这时 W^K 会在某一个方向上的收缩至0,最终导致梯度在该方向趋于0,这就是梯度消失。这时使用梯度下降法几乎学不到任何有用的信息。
如果 λ_i>1,那么 λ_i^K→∞,这时 W^K 会在某一个方向上的膨胀至无穷,最终导致梯度在该方向趋于无穷,这就是梯度爆炸。
更为复杂的是,特征值之间可能会出现例如 λ_1<1 和 λ_2>1 的情况,那就会同时发生梯度消失和爆炸,给模型的学习带来严重困扰。这也是使用RNN模型时序列长度(K)不能太大的原因。
2.1.3 对称矩阵的特征分解
当 n 阶方阵 W 为对称矩阵时,即 W=W^T,它一定有 n 个线性无关的特征向量(无论是否有重根),并且相互正交。这是对称矩阵在特征值和特征向量中的一个特殊性质,和一般矩阵比较,如表2-1所示。

表2-1
下面我们证明一下对称矩阵特征向量的正交性。W 为对称矩阵,它的特征值和特征向量,有两种情况。
第一种情况是,如果有两个特征值 λ_i≠λ_j,它们对应的特征向量分别为 v_i 和 v_j,即
Wv_i=λ_i v_i
Wv_j=λ_j v_j
我们易得
〖〖(λ_i v_i)〗^T=(Wv_i)〗^T
即
λ_i v_i^T=v_i^T W^T
那么,两边都右乘 v_j,可得
λ_i v_i^T v_j=v_i^T W^T v_j=λ_j v_i^T v_j
也即
λ_i v_i^T v_j-λ_j v_i^T v_j=(λ_i-λ_j ) v_i^T v_j=0
因为 λ_i≠λ_j,所以 v_i^T v_j=0,即 v_i 和 v_j 正交。
第二种情况是,对于同一特征值 λ 对应的特征向量组,例如 v_1~v_m,它们之间一定线性无关(证明过程较为复杂,略去)。根据前面的分析,它们之间的线性组合也是该特征值对应的特征向量,因此,可以通过施密特正交化将 v_1~v_m 变成彼此正交,并且仍然是特征向量。
综上所述,对称矩阵 W 对应的特征向量有如下结论。
不同特征值对应的特征向量,彼此正交。
同一特征值对应的特征向量,可以通过施密特正交变换转为彼此正交,转换后的结果仍然是特征向量,并且对应的特征值不变。
结合上面两点,如果方阵 W∈R^(n×n) 为对称矩阵,我们总能找到 W 的 n 个线性无关的特征向量 v_1,〖⋯,v〗_n,并且它们之间彼此正交。因为特征向量可以进行任意缩放,所以我们总能保证 ‖v_i ‖=1(i=1,⋯,n)。
因此任意对称矩阵 W∈R^(n×n) 的都可以进行如下特征分解。
W=QΛQ^(-1)
Q=[v_1,〖⋯,v〗_n ]
‖v_i ‖=1,i=1,⋯,n
v_j^T v_i=0,i≠j
Λ=[■(λ_1&⋯&0@⋮&⋱&⋮@0&⋯&λ_n )] 为对角矩阵,λ_1~λ_n 为特征值,λ_1≥λ_2≥⋯〖≥λ〗_n,v_1~v_n 为对应的特
征向量,并且彼此正交。因为 Q 为正交矩阵,正交矩阵 Q 满足
Q^(-1)=Q^T
所以,特征分解也可写成
W=QΛQ^T=QΛQ^(-1)
如果我们使用线性变换 y=Wx=QΛQ^(-1) x,就可以换一个角度理解。
用 Q^(-1) 对 x 进行旋转,即 〖z=Q〗^(-1) x。需要注意的是,因为是正交变换,所以 ‖x‖=‖z‖。
用 Λ 对旋转后的各个维度进行缩放,即 h=Λz,因为 Λ 为对角矩阵,所以相当于对 z 的各个维度独立进行缩放。
使用 Q 旋转回原来的角度 z=Qh。
具体变换如图2-1所示。

图2-1
2.2 奇异值分解
在前面对特征值和特征向量的讲解中,我们知道对称方阵 W 有如下分解。
W=QΛQ^(-1)
或者
W=QΛQ^T
Q=[v_1,〖⋯,v〗_n],v_i(i=1,⋯,n)为 W 的特征向量,Λ=[■(λ_1&⋯&0@⋮&⋱&⋮@0&⋯&λ_n )],λ_1~λ_n 为对应
的特征值且 λ_1≥λ_2≥⋯〖≥λ〗_n。
但是,当矩阵 A 不是方阵或者不是对称矩阵时,就不存在上述分解了。我们能否找到类似的方法呢?这时候奇异值分解(Singular Value Decomposition,SVD)就派上用场了。我们可以对任意矩阵 A∈R^(m×n) 做如下分解。
A=UΣV^T
其中,U∈R^(m×m)、V∈R^(n×n) 均为正交矩阵。Σ∈R^(m×n) 除主对角线上的元素外全为0,主对角线上的每个元素都称为奇异值,具体如下。
当 m≥n 时
Σ=[■(σ_1&⋯&0@⋮&⋱&…@⋮&⋯&σ_n@⋮&⋯&⋮@0&⋯&0)]
σ_i≥0(i=1,⋯,n)且满足 σ_1≥σ_2≥⋯〖≥σ〗_n。
当 m≤n 时
Σ=[■(σ_1&⋯&0&⋯&0@⋮&⋱&⋯&⋯&0@0&⋯&σ_m&⋯&0)]
σ_i≥0(i=1,⋯,n)且满足 σ_1≥σ_2≥⋯〖≥σ〗_m。
奇异值分解可以看成是特征分解在非方阵上的扩展版本。
奇异值分解和特征分解有什么内在的联系吗?我们以 A∈R^(m×n)(m>n)为例。A 的奇异值分解为 A=UΣV^T∈R^(m×n),那么
A^T=VΣ^T U^T

可以发现 σ_i=√(λ_i ),即奇异值和特征向量之间的对应关系。这里需要注意的是,严格来说,σ_i=±√(λ_i ) 为约定,一般令 σ_i>0。另外,根据对应关系可以发现 λ_(n+1)~λ_m=0。
同理,U=Q,即 A 奇异值分解对应的 U 为对称矩阵 AA^T 的特征向量组成的正交矩阵 Q。
类似的,对对称矩阵 A^T A∈R^(n×n) 进行特征分解,可得
A^T A=PΛP^T
其中,P 为 AA^T 的特征向量组成的正交矩阵。
使用奇异值分解,可得
A^T A=VΣ^T U^T UΣV^T=VΣ^T ΣV^T=V[■(σ_1^2&0&…&0@0&σ_2^2&…&0@…&…&…&…@0&0&…&σ_n^2 )] V^T
其中,V=P,即 A 奇异值分解对应的 V 为对称矩阵 A^T A 的特征向量组成的正交矩阵 P。
如果 A 本身是对称矩阵,即 A=A^T,则 AA^T=A^T A,也即 U=V,奇异值分解就是
A=UΣU^T=UΣU^(-1)
其实就是特征分解。因此,我们可以认为,特征分解其实是奇异值分解的特例。
那么,奇异值分解的物理意义是什么呢?我们知道,矩阵代表着线性变换,即旋转和缩放操作,这是一套组合拳。有些时候一整套动作过于复杂,所以,通过奇异值分解对动作进行分解,更能看清楚这套组合拳的每一步。例如:
Ax=UΣV^T x
y=V^T x 表示先对向量 x 进行旋转。因为 V^T 是正交矩阵,所以只是单纯的旋转,并没有进行缩放。又因为 Σ 是对角矩阵,所以 z=Σy 相当于对 y 的各个方向进行缩放,并没有进行旋转。最后,通过正交矩阵 U 对 z 进行无缩放旋转。整个流程如图2-2所示。
通过上面的分析,我们可以发现 U 和 V^T 并没有对向量进行缩放,也没有改变向量之间的相对位置,只是改变了向量的方向。而 Σ 在第一次旋转后的方向上,以不同强度对向量进行缩放,并改变他们之间的相对位置。因此,奇异值是矩阵的本质特征,它们的大小决定了矩阵进行线性变换的真正方向和缩放大小。如果某方向的奇异值过小,就可以认为该方向的重要性不高。
因此,在神经网络中,各层神经元的线性变换可以通过奇异值分解 W=UΣV^T 进行更加详细的分析,我们可以发现,正交变换 U 和 V^T 只是改变特征 x 的方向,但不会改变特征的相对位置和距离。真正起作用的其实是 Σ,它通过对特征的缩放,使同类的向量的距离更近、异类的向量距离更远。

图2-2
在深度学习中,为了防止过拟合,也会对模型参数 W 进行正则化。例如,使用L2正
则时,对参数 W∈R^(m×n) 进行限制,即缩小 ∑_(i=1)^m▒∑_(j=1)^n▒w_ij^2 。我们知道:
tr(WW^T)=∑_(i=1)^m▒∑_(j=1)^n▒w_ij^2
而 WW^T=UΣV^T VΣ^T U^T=U〖ΣΣ〗^T U^T。根据正交矩阵的性质,可得
∑_(i=1)^m▒∑_(j=1)^n▒w_ij^2 =tr(WW^T )=tr(U〖ΣΣ〗^T U^T )=tr(〖ΣΣ〗^T )=∑_(i=1)^(mi n(m,n))▒σ_i^2
所以,L2正则限制 ∑_(i=1)^m▒∑_(j=1)^n▒w_ij^2 ,其实就是限制 W 奇异值的平方和 ∑_(i=1)^(min(m,n))▒σ_i^2 。
因此,在神经网络中,对线性变换进行L2正则的限制,本质就是限制缩放能力。例如,W 在 σ_i 过大,那么对该方向数据的微小变化会过于敏感,从而造成了过拟合。
在机器学习中,SVD分解也经常用于特征压缩,例如对矩阵 A∈R^(m×n),如果要直接进行存储,那么需要存 m×n 个参数,如果将其进行SVD分解,即
A=UΣV^T
那么 U∈R^(m×r),Σ∈R^(r×r),V∈R^(r×n)。如果我们只取矩阵最重要的 r 个奇异值,如图2-3所示,对于矩阵,我们只需存储截取后的 U、Σ、V,共计 m×r+r×r+r×n 个参数,远小于 m×n 个。这种有损压缩不仅能节省存储空间,而且损失的是最不重要的信息。

图2-3
2.3 正定矩阵
如果有一个实对称方阵 A∈R^(n×n),对于任意非0向量 x∈R^(n×1) 都有
x^T Ax>0
那么称 A 为正定矩阵。
相应的,如果对于任意非0向量 x∈R^(n×1) 都有
x^T Ax<0
那么称 A 为负定矩阵。例如,单位矩阵 E 就是一个典型的正定矩阵。
x^T Ex=x_1^2+⋯+x_n^2>0
在机器学习中,训练样本 〖{x_((i))}〗_(i=1)^N,x_((i))∈R^(n×1),组成如下矩阵。
A=1/N ∑_(i=1)^N▒〖x_((i)) x〗_((i))^T
A∈R^(n×n)
对于任意向量 y∈R^(n×1),都有
y^T Ay=1/N y^T (∑_(i=1)^N▒〖x_((i) ) x〗_((i))^T )y=1/N ∑_(i=1)^N▒〖(x_((i))^T y)^T x_((i))^T y〗=1/N ∑_(i=1)^N▒‖x_((i))^T y‖ ≥0
对于 y^T Ay≥0,把 A 称作半正定矩阵。同理,如果 y^T Ay≤0,把 A 称作半负定矩阵。
如果 A 是正定矩阵,那么通过它对 x 进行线性变换,即
y=Ax
计算 x 和 y 的 cosine 相似度:
cosine(x,y)=(x^T y)/‖x‖‖y‖ =(x^T Ax)/‖x‖‖y‖ >0
这就表明,使用正定矩阵对向量 x 进行旋转时,转过的角度不会超过 π/2。
如果 A 是正定矩阵,λ 是它的一个特征值,u 是对应的特征向量,即
Au=λu
那么
u^T Au=λu^T u
即 λ=(u^T Au)/(u^T u)>0。
因此,正定矩阵的特征值一定是大于0的。同理,负定矩阵的特征值 λ<0,半正定矩阵的特征值 λ≥0,半负定矩阵的特征值 λ≤0。
2.4 矩阵的范数和神经网络
对于向量 x,我们有时候需要衡量它的长度。长度一般是指向量和原点之间的距离,例如使用欧氏距离的时候 x∈R^(n×1) 对应的长度为
‖x‖=√(∑_(i=1)^n▒x_i^2 )
用更加专业的说法,长度叫作范数。例如上面的式子,就是最常见的2范数。使用闵氏
距离时对应的 p 范数为 (∑_(i=1)^n▒〖〖|x〗_i |〗^p )^(1/p),也可以写成 ‖x‖_p。出于习惯,2范数 ‖x‖_2 可以直接
写成 ‖x‖。
如果说范数是对向量的长度的度量,我们把这个概念拓展到矩阵,那么矩阵的范数定义就是对向量长度进行拉伸的能力。矩阵的范数越大,它拉伸向量的能力就越强。因此,矩阵 A 的 p 范数为矩阵的最强拉伸能力,即
‖A‖_p=max┬x〖‖Ax‖_p/‖x‖_p 〗
在机器学习中,矩阵用的较多的为2范数,2范数 ‖A‖_2 默认写成 ‖A‖,即
‖A‖=max┬x〖‖Ax‖/‖x‖ 〗
略去证明,我们给出
‖A‖=σ_max
σ_max 为 A 最大的奇异值。
除了2范数,矩阵 A∈R^(m×n) 的Frobenius范数在机器学习中也经常使用,具体如下。
‖A‖_F=√(∑_(i=1)^m▒∑_(j=1)^n▒〖(a_(i,j))〗^2 )
A=[■(a_1,1&⋯&a_(1,n)@⋮&⋱&⋮@a_(m,1)&⋯&a_(m,n) )]
在2.2节我们证明了,神经网络中使用L2正则优化矩阵 W,其实就是缩小 ‖W‖_F。在这里,略去证明过程,对于 A∈R^(m×n),给出如下结论。
‖A‖≤‖A‖_F≤√n ‖A‖
当 A 为方阵并存在逆矩阵时,有如下关系。
y=Ax,x=A^(-1) y
A^(-1) 的范数为
‖A^(-1) ‖=max┬y〖‖A^(-1) y‖/‖y‖ 〗=1/min┬y〖‖y‖/‖A^(-1) y‖ 〗=1/min┬x〖‖Ax‖/‖x‖ 〗
min┬x〖‖Ax‖/‖x‖ 〗 即为矩阵 A 的压缩能力,越小表示压缩能力越强。也就是说,矩阵 A 的压缩能
力越强,那么它的 ‖A^(-1) ‖ 越大。略去证明,可得 min┬x〖‖Ax‖/‖x‖ 〗=σ_min,即 ‖A^(-1) ‖=1/σ_min ,σ_min
为 A 最小的奇异值。
因此,我们定义条件数 κ 用来综合表示矩阵 A 的压缩能力和拉伸能力,即
κ(A)=‖A‖‖A^(-1) ‖=σ_max/σ_min
κ(A) 越大,表明 A 的拉伸和压缩的能力越强,变换结果越丰富。因此,用 A 做线性变换,得到的结果的可能性比较多。显然
κ(A)=σ_max/σ_min ≥1
在神经网络中,使用矩阵 A 对特征 x 进行线性变换,具体如下。
y=Ax
如果输入 x 引入了噪声,即输入变为 x+δx,那么输出的变化 δy=Aδx,两边同时取范数,可以得到
‖δy‖=‖Aδx‖
根据范数的定义,可知 ‖A‖≥‖Aδx‖/‖δx‖ ,即 ‖Aδx‖≤‖A‖‖δx‖,可以得到
‖δy‖≤‖A‖‖δx‖
另一方面,‖A^(-1) ‖=1/min┬x〖‖y‖/‖x‖ 〗,可以得到
‖x‖≤‖A^(-1) ‖‖y‖
将上面两个不等式左右相乘,可以得到
‖δy‖‖x‖≤‖A‖∙‖A^(-1) ‖∙‖δx‖∙‖y‖=κ(A)‖δx‖‖y‖
即
‖δy‖/‖y‖ ≤κ(A) ‖δx‖/‖x‖
同理,我们也可以推导出
1/κ(A) ‖δx‖/‖x‖ ≤‖δy‖/‖y‖
综上可得
1/κ(A) ≤(‖δy‖/‖y‖ )/(‖δx‖/‖x‖ )≤κ(A)
我们把 Δ=(‖δy‖/‖y‖ )/(‖δx‖/‖x‖ ) 作为矩阵敏感性指标,用 ‖δx‖/‖x‖ 表示输入的变化比,用 ‖δy‖/‖y‖ 表示输出的
变化比,用 Δ 表示 x 按比例变化时 y 的变化率(Δ 为 y 对 x 的敏感程度),可以得到
1/κ(A) ≤Δ≤κ(A)
κ(A) 越大,Δ 的上限越高,表明 y 对 x 越敏感——只要 x 有一点风吹草动,y 就会剧烈变化,神经网络处于不稳定状态。换一个角度,κ(A) 越大,1/κ(A) 就越小,y 对 x 越麻木——x 的改变对 y 几乎起不到作用。
我们一般希望的神经网络满足这两种状态:特征变化大时,输出发生变换,这就是分类能力强;特征仅发生微小变化时,输出尽可能保持未定,这就是泛化能力强。但是变换矩阵 A 的 κ(A) 过大,模型很容易走上过于敏感或者过于麻木两个极端,这对神经网络的性能是有害的。κ(A) 过大,就是 Δ 上下限差别极大,很容易出现“旱的旱死,涝的涝死”的情况,即有些特征分类效果很好但泛化能力很差,有些特征虽然对噪声不敏感但分类效果很差。因此,一个不错的神经网络,κ(A) 应尽可能接近1,也就是 σ_max 和 σ_min 尽可能接近,即所有 σ_i 都接近。与L1正则相比,使用L2正则的好处就是会驱使各 σ_i 均一同减小,最终差异不大。
2.5 主成分分析
在机器学习中,如果数据维度过高,我们一般需要对其进行降维,舍弃一些信息。对特征进行降维,不仅可以节约计算资源,也能提升数据的可区分度。
例如,数据特征 x1=[■(2@2@1@⋮@1)],x2=[■(3@3@1@⋮@1)],x3=[■(1@-1@1@⋮@1)],一共102维,其中第3~100维
都为1,显然不具备任何信息量,可以去除。我们先计算降维之前的相似度,这里采用 cosine 相似度:
cosine(x1,x2)=(<x1,x2>)/‖x1‖‖x2‖ =0.99
cosine(x1,x3)=(<x1,x3>)/‖x1‖‖x3‖ =0.95
可以看出,两组相似度并没有明显差异,即看不出 x2 和 x3 中的哪一个与 x1 更相似。
但是,我们知道第3~100维没有包含任何信息量,因此可以将它们去除。这样,向量就变成
x1=[■(2@2)],x2=[■(3@3)],x3=[■(1@-1)]
那么
cosine(x1,x2)=(<x1,x2>)/‖x1‖‖x2‖ =1
cosine(x1,x3)=(<x1,x3>)/‖x1‖‖x3‖ =0
可以明显看到,两组相似度拉开了差距,即 x1 和 x2 非常相似。因此可以看出,对于机器学习来说,降低特征维度是一个非常重要的优化方向。
下面讲解一种常见的降维方法——主成分分析(Principal Component Analysis,PCA)。
在机器学习中,我们拿到 N 个训练数据 〖{x_((i))}〗_(i=1)^N,x_((i))∈R^(m×1),x_((i))=[■(x_((i),1)@⋮@x_((i),m) )],数
据分布如图2-4所示。

图2-4
为了便于后续处理数据,一般要对数据进行去中心化的操作,以便让数据围绕原点分布,具体操作如下。
x_((i))=x_((i))-x ̅
x ̅=[■(x ̅_1@⋮@x ̅_m )]=1/N [■(∑_(i=1)^N▒x_((i),1) @⋮@∑_(i=1)^N▒x_((i),m) )]
上述数据在去中心化后,数据分布如图2-5所示。

图2-5
去完中心化后,向量的均值为 x ̅=[■(0@⋮@0)]。
如果进行特征降维,我们肯定是希望信息损失的越小越好,那么如何定义信息量呢?在维度 j 上,我们可以用方差来度量信息,即
σ_j^2=1/N ∑_(i=1)^N▒(x_((i),1)-x ̅_j )^2
因为向量已经去中心化了,即 x ̅_1~x ̅_m 均为0,所以
σ_1^2=1/N ∑_(i=1)^N▒x_((i),1)^2
⋮
σ_m^2=1/N ∑_(i=1)^N▒x_((i),m)^2
σ_j^2 越小,表明在该维度的信息变化越小,维度 j 的区分能力就越弱,可以优先去除。σ_j^2 越大,则表明数据在该维度的信息越大,越应该优先保留。
假如我们用眼睛的个数作为特征来区分男女,所有人眼睛个数都是2,方差就是0,因此可以说此特征没有任何信息量,特征可以去除。假如我们用身高作为特征,身高对应的方差就会很大,因此身高是一个不错的特征。在图像上看,各维度方差和数据在各维度伸展量成正比,如图2-6所示。

图2-6
但是,我们通常不会直接计算各维度方差后保留最高再去除最低,因为我们发现,如果将坐标轴进行旋转,可以找到更大的方差,如图2-7所示。

图2-7
因此,我们需要先通过矩阵进行旋转到更合适的坐标系,旋转后的第一个维度的方差对应于最大方差。
因为旋转坐标系不能改变数据之间的相对位置和长度,所以,必须选择用正交矩阵进
行旋转。具体来说,我们使用矩阵 W=[■(v_1^T@⋮@v_m^T )] 进行旋转,v_1^T~v_m^T 为正交向量组,旋转后
对应的向量为
z_((i))=Wx_((i))
我们优化的目标就是求解最适合的 v_1^T~v_m^T,以便找到旋转后信息量(方差)最大的特征。
我们知道,对于旋转后得到的向量 z,它的第1维为 z_((i),1)=v_1^T x_((i)),对应的方差为
β_1=1/N ∑_(i=1)^N▒z_((i),1)^2 =1/N ∑_(i=1)^N▒〖v_1^T x_((i)) 〗 x_((i))^T v_1=v_1^T [■(s_1,1&s_1,2&⋯&s_(1,m)@s_2,1&s_2,2&⋯&⋯@⋯&⋯&⋯&⋯@s_(m,1)&⋯&⋯&s_(m,m) )] v_1=v_1^T Pv_1
P=[■(s_1,1&s_1,2&⋯&s_(1,m)@s_2,1&s_2,2&⋯&⋯@⋯&⋯&⋯&⋯@s_(m,1)&⋯&⋯&s_(m,m) )]
s_(i,j)=1/N ∑_(k=1)^N▒〖x_((k),i) x_((k),j) 〗
显然,s_(i,j)=s_(j,i),即 P∈R^(m×m) 为对称矩阵。那么,对 P 可以进行如下特征分解。
P=U^T ΛU
其中,U=[■(u_1^T@⋮@u_m^T )] 为正交矩阵,Λ=[■(λ_1&⋯&0@⋮&⋱&⋮@0&⋯&λ_m )],并且 λ_1≥λ_2≥⋯≥λ_m。
根据前面所学,λ_1~λ_m 为 P 的特征值,u_1~u_m 为对应的特征向量,那么 β_1=v_1^T U^T ΛUv_1=〖(Uv_1)〗^T ΛUv_1。令 n=Uv_1,因为 U 为正交向量组,v_1 为单位向量,所以
n=[■(n_1@⋮@n_m )] 也是单位向量,即 n_1^2+⋯+n_m^2=1。因此,有
β_1=[n_1,⋯,n_m][■(λ_1&⋯&0@⋯&⋯&⋯@0&⋯&λ_m )][■(n_1@⋯@n_m )]=∑_(i=1)^m▒〖n_i λ_i^2 〗
可以看出,当 n_1=1、n_2~n_m=0 时,β_1 取最大值 λ_1^2。此时,〖n=Uv_1=[■(u_1^T@⋮@u_m^T )]v〗_1=[■(1@⋮@0)],可以得到 v_1=u_1。同理,我们可以找到 v_2=u_2,方差 β_2 取最大值 λ_2^2。依此类推,
第 i 大方差 β_i=λ_i^2 对应的旋转向量为 v_i=u_i。
上述整个流程,我们总结如下。
使用中心化的数据集 〖{x_((i))}〗_(i=1)^N 构建矩阵 P=[■(s_1,1&s_1,2&⋯&s_(1,m)@s_2,1&s_2,2&⋯&⋯@⋯&⋯&⋯&⋯@s_(m,1)&⋯&⋯&s_(m,m) )],s_(i,j)=1/N ∑_(k=1)^N▒〖x_((k),i) x_((k),j) 〗。
求解矩阵 P 的所有特征值和特征向量,并将特征值从大到小排列,即 λ_1≥λ_2≥⋯≥λ_m。
最大的特征值 λ_1 对应的正规化特征向量 u_1 即为最大方差所对应的旋转方向。
同理,依次选取 u_2、u_3 作为第2大方差、第3大方差的旋转方向。
对于特征 〖{x_((i))}〗_(i=1)^N,x_((i))∈R^(m×1),将特征降维至 k 维,k<m,就可选取前 k 大特
征值对应的特征向量组成矩阵 W=[■(u_1^T@⋮@u_k^T )],降维操作为 z_((i))=Wx_((i))。
上面的步骤就称为主成分分析。主成分分析是一种常见的数据分析方式,通常用于高维数据的降维,也可用于提取数据的主要特征分量。在进行数据分析时,如果特征维度过高,不方便进行可视化,经常使用主成分分析将其降至2~3维,以便画出对应的图形。
Bert是目前效果公认最好和使用最广泛的自然语言处理深度模型。对它输入一句话,它就会输出一个高维向量 v。人们常拿这个向量 v 作为句子的表示。例如,有两个句子,对应的向量分别为 v1 和 v2,那么它们之间的相似度为 〈v1,v2〉/‖v1‖‖v2‖ 。但是,由于Bert训练的原因,实际情况是不同句子所对应的向量相差不大,并且,由于维度过高,向量之间的相似度计算出来都差不多,缺乏区分性。这就像考试题目过于简单,所有人得分都是99分以上,失去了甄别选拔的意义。因此,有人将Bert输出的特征向量通过主成分分析进行降维,将一些无关的因素去除,使特征向量更具区分性。这就好比在一场考试中,把大家都作对的题和大家都做错的题去除(这些题的得分对应的方差极小),剩下的就是区分度较高的题。
2.6 推荐系统中的矩阵分解
矩阵分解技术也经常用于推荐系统当中,用来对未发生的事情进行预测,例如预测用户对一部没有看过的电影的喜好程度。假设有4部电影,3个用户,它们之间组成的喜好矩阵 M0∈R^(3×4) 如下。
M0=[■(1&m&1&m@2&m&3&m@m&2&3&m)]
矩阵的第 i 行第 j 列表示第 i 个用户对第 j 部电影的评分。但用户并不是看过了全部电影,因此,对于那些没有评分的电影得分,统一用 m 表示,m 等于所有得分的平局值,即
m=(1+1+2+3+2+3)/6=2
其实,我们所做推荐任务的目的就是预测出 m 位置的取值,通过这个值给用户推荐他有可能打高分的电影。
我们先用 m=2 代替没有看过电影的评分,那么矩阵为
M1=[■(1&2&1&2@2&2&3&2@2&2&3&2)]
接着,对这个矩阵进行SVD分解:
M1=[■(-0.414&-0.91&0@-0.644&0.293&-0.707@-0.644&0.293&0.707)][■(7.1&0&0&0@0&1.27&0&0@0&0&0&0)][■(-0.421&-0.479&-0.602&-0.479@0.205&-0.508&0.665&-0.508@0.883&-0.11&-0.442&-0.11@0.0&-0.707&0.0&0.707)]
我们知道,矩阵 M1 其实是含有噪声的,噪声的主要来源如下。
对于用户没有观看的电影,统一用一个得分 m 进行估计,显然只是一种非常粗粒度的估计,会带来偏差。
用户对电影打分的时候,或多或少都有一些随机性,例如2分还是3分多少都有点临时起意。
可以看出,我们需要对 M1 去噪。在SVD分解中,去噪的方法就是取前 K 大的奇异值,奇异值较小的部分就作为噪声直接去掉。在本例种,我们设 K=1,那么矩阵就是
M2=[■(-0.414@-0.644@-0.644)][7.1][■(-0.421&-0.479&-0.602&-0.479)]=[■(1.239&1.41&1.772&1.41@1.923&2.19&2.751&2.19@1.923&2.19&2.751&2.19)]
因此,我们可以预测用户对电影的打分,即之前 m 替代的地方的数值为
[■(-&1.41&-&1.41@-&2.19&-&2.19@1.923&-&-&2.19)]
在推荐系统刚起步的阶段,因为SVD分解有明确的数学含义,所以得到了广泛的应用。但是,随着推荐系统的发展,用户数和商品数量越来越多,待分解的矩阵规模越来越大,SVD也显露了很多问题,主要为以下两方面。
例如电影库里有1万部电影,绝大多数电影用户并没有看过,因此待分解的矩阵非常稀疏,需要填充大量的 m,矩阵的噪声非常大——噪声甚至比有效信息还多——这对准确性影响极大。
SVD分解本身也比较耗费运算量,如此大规模的矩阵分解,在工程上是不可行的。而且,随时有新注册的用户和新上传的电影,而SVD无法做到增量更新,这极大限制了使用场景。
为了解决SVD的上述问题,Funk-SVD算法被提出来了。Funk-SVD算法仍然对矩阵进行分解,但是对矩阵 M0∈R^(m×n) 分解为 P∈R^(m×k) 和 Q∈R^(k×n),即
M0=PQ
其中,P=[■(p_1^T@⋮@p_m^T )],Q=[■(q_1&⋯&q_n )]。
p_i∈R^(k×1),q_j∈R^(k×1)
然后,定义一个损失函数,即对于已知的矩阵元素(用户看过的电影)定义
loss_((i,j))=〖(〖M0〗_(i,j)-p_i^T q_j)〗^2
因此,完整的损失函数为
Loss=∑_((i,j)∈A)▒loss_((i,j))
A 为所有已经观看过电影的集合。可以看出,优化 Loss 时并不包括用户未观看的电影,从而避免了噪声干扰。
类似于神经网络,我们通过梯度下降法求解 p_i 和 q_j,并最终用于观众未观看电影的评分预测。例如,用户 i 没有看过电影 j,那么预测得分为 p_i^T q_j。
Funk-SVD算法本身也有一些需要改进的地方,例如:有些人本身就喜欢看电影,所以会对所有电影都打高分;有些热门电影本身的评分就很高,所有人都会对它打高分。因为上述两种因素的存在,评分未必能完全准确反映用户的喜好,所以,我们可以加上三个需要训练的偏置项,user_i 和 item_j 分别表示第 i 个用户和电影 j 的个性化特征,b 表示预测的整体偏置,让模型更加灵活。因此,loss_((i,j)) 可以改写为
loss_((i,j))=(〖M0〗_(i,j)-(p_i^T q_j+user_i+item_j+b))^2
如果用户 i 没有看过电影 j,那么预测得分为
p_i^T q_j+user_i+item_j+b
FM模型经常被使用在点击率预测中,输入特征为 x=[■(x_1@⋮@x_n )],模型输出为 y,模型结
构如下。
y=1/(1+e^(-d) )
d=w_0+w_1 x_1+⋯+w_n x_n+∑_(i=1)^n▒∑_(j=i+1)^n▒〖v_i^T v_j x_i x_j 〗
在FM模型中,如果只有用户id和商品id作为特征,那么特征 x 中有且仅有两个特征不为0,我们记为 x_i=1 表示某个用户,用 x_j=1 表示某个商品,那么
d=w_0+w_i+w_j+v_i^T v_j
可以发现,这正是Funk-SVD分解,即
w_i=user_i
w_j=item_j
v_i=q_i
v_j=q_j
w_0=b
因此,在只使用用户和商品id作为特征时,Funk-SVD分解是FM模型的一个特例。
第3章 微积分的基本概念
3.1 导数的定义和几何意义
在进行数据分析和机器学习的时候,我们往往需要知道一个因素的变化对结果造成的影响。例如:
车费=3元×里程+起步价
那么里程增加1千米,那么车费就会增加3元,因此里程对车费造成的影响就是 Δ=3,Δ 表示里程(自变量)对车费(因变量)的影响程度。
我们可以把上面的分析用标准的数学语言进行描述。
对应的函数为
y=f(x)=kx+b
我们首先让 x 有一个微小的变动 Δx,它是一个无限接近于0的极小变量。Δy 则表示当 x 变为 x+Δx 时,y 对应的变化情况,即
Δy=f(x+Δx)-f(x)=k(x+Δx)+b-(kx+b)=kΔx
那么,x 的变化对 y 造成的影响可以记为 dy/dx=Δy/Δx,即
dy/dx=Δy/Δx=k
当函数只有一个变量 x 时,dy/dx=k 也可以简写成 y^'=k 或者 f^' (x)=k 。我们把 dy/dx 称为导数。简单来说,导数用来描述 x 发生变化时对 y 造成的影响。如果 k>0,那么 y 会随着 x 的增大而增大。如果 k<0,那么 x 增大,y 会减小,即 dy/dx<0。如果 k=0,那么 x 的变化对 y 没有任何影响。
如果一个函数是常函数,例如 y=3,它的导数又是什么呢?我们可以这样理解:x 的变化对 y 不会有任何影响,因此 dy/dx=0。也可以换一个角度分析这个问题:y=3 可以写成y=0x+b,即 k=0,那么 dy/dx=k=0。
函数 y=kx+b 是一个线性函数,也就是说,即使 x 在不同的地方(例如 x=3,x=4),它的变化对 y 的影响也是一样的,都是 k,即 dy/dx=k 和 x 的取值无关。我们其实可以发现,dy/dx=k 就是直线 y=kx+b 的斜率。如图3-1所示:当 k>0 时,f(x) 为增函数;当 k<0 时,f(x) 为减函数,并且 |k| 越大,直线越陡峭。

图3-1
对于曲线来说,函数的斜率其实就为各个点的切线。绝大多数函数并不具备唯一的斜率,斜率会随着 x 的变化而变化。例如,函数 y=x^2 的图像如图3-2所示。

图3-2
从图像就能看出,y=f(x)=x^2 有两个不同于 y=kx+b 的特点。
f^' (x) 不再和 x 无关,会随着 x 的变化而变化。
当 x>0 时,随着 x 的增大,y 的增幅会越来越大。当 x<0 时,随着 x 的减小,y 的增幅也会越来越大。
我们可以用同样的方法推导出 dy/dx,具体如下。
Δy=f(x+Δx)-f(x)=(x+Δx)^2-x^2=Δx(2x+Δx)
因此
f^' (x)=dy/dx=Δy/Δx=2x+Δx=2x
因为 Δx 无限接近0,所以上式将其忽略。可以看出,f^' (x)=dy/dx=2x 符合上述两个性质。
要计算 x=3 和 x=-2,将函数的导数代入上式,可得
f^' (3)=dy/dx |_(x=3)=6
f^' (-2)=dy/dx |_(x=-2)=-4
在这里,dy/dx |_(x=3) 表示当 x=3 时对应的导数取值。
同理,y=x^2+c,c 为任意常数。我们可以看到,x 的变化导致 y 的变化,即 dy/dx=2x,而 y 的变化和 c 毫无关系,dy/dc=0。
一言以蔽之,导数 f^' (x) 就是用来定量描述函数 f(x) 和自变量 x 之间的变化关系的。如果 f^' (x)>0,则表示 x 的增大 f(x) 也会增大,并且 f^' (x) 表示了增速。反之,如果 f^' (x)<0,则表示随着 x 的增大 f(x) 会减小。如果 f^' (x)=0,则表示 x 的变化不会对 f(x) 造成影响。
3.2 复杂函数求导
如果函数为组合函数时,对 f(x)=f_1 (x)+f_2 (x)+f_3 (x) 应该如何求导呢?例如
y=f(x)=x^2+3x+6
它的导数又为多少呢?我们可以把这个函数写成三部分:
y=f_1 (x)+f_2 (x)+f_3 (x)
f_1 (x)=x^2
f_2 (x)=3x
f_3 (x)=6
不加证明的给出,如果函数 f(x)=f_1 (x)+f_2 (x)+⋯+f_n (x),那么对应的导数就是
f^' (x)=f_1^' (x)+f_2^' (x)+⋯+f_n^' (x)
因此,上面的例子中
f^' (x)=dy/dx=f_1^' (x)+f_2^' (x)+f_3^' (x)=2x+3+0=2x+3
另一方面,当函数为如下形式时
f(x)=f_1 (x) f_2 (x)
对应的导数为
f^' (x)=f_1^' (x) f_2 (x)+f_1 (x) f_2^' (x)
例如,对于函数 f(x)=x^3,可以有如下分解。
f(x)=f_1 (x) f_2 (x)
f_1 (x)=x^2
f_2 (x)=x
那么
f^' (x)=f_1^' (x) f_2 (x)+f_1 (x) f_2^' (x)=2x⋅x+x^2⋅1=3x^2
函数的数量可以说是无穷无尽的,上述两个方法也不能对所有函数进行分解。这里我们总结出一些常用的函数对应的导数,如表3-1所示。

表3-1
函数名 原函数 导数
常数 f(x)=C f^' (x)=0
指数函数 f(x)=a^x f^' (x)=a^x lna
幂函数 f(x)=e^x f^' (x)=e^x
幂函数 f(x)=x^n f^' (x)=nx^(n-1)
对数函数 f(x)=log_ax f^' (x)=1/xlna
正弦函数 f(x)=sinx f^' (x)=cosx
余弦函数 f(x)=cosx f^' (x)=-sinx
但是在解决实际问题时,所遇到的函数会非常多,上面的几个显然无法满足需求。例如 y=ln(x^2+3) 并不在上面的公式内,我们又该如何求解 dy/dx 呢?仔细分析一下,如果把 〖z=x〗^2+3 作为一个整体,那么 y=lnz,根据导数的定义,可以写成
Δy=Δz dy/dz=Δx dz/dx dy/dz
即
dy/dx=Δy/Δx=dy/dz dz/dx
在上例中,dz/dx=2x,dy/dz=1/z,所以 dy/dx=2x 1/z=2x/(x^2+3)。
dy/dx=dy/dz dz/dx 称为链式法则。我们在对复杂函数求导时,会经常使用链式法则。在神经网络中,链式法则有广泛的应用。特别的,如果函数特别复杂,可以构建多级链式法则,像洋葱一样一层一层剥开,例如
y=ln(e^(x^2 )+3)
那么我们定义
y=ln z1
z1=e^z2+3
〖z2=x〗^2
其中
dy/dz1=1/z1
dz1/dz2=e^z2
dz2/dx=2x
因为
dy/dx=dy/dz1 dz1/dz2 dz2/dx
即
dy/dx=1/(e^(x^2 )+3) e^(x^2 ) 2x=(2xe^(x^2 ))/(e^(x^2 )+3)
3.3 导数的存在性
前面我们讲解了导数的意义以及常见的求解方法,但需要注意的是,函数 y=f(x) 并不是在所有 x 的定义域上都有导数,导数存在的必要条件是函数连续。例如函数
y={█(3 x≤0@4x x>0)┤
在 x=0 上并不连续,会存在突变,因此,函数的导数 dy/dx 在 x=0 上没有意义,即不存在导数。但是,该函数在其他点存在导数,即
dy/dx={█(0 x<0@4 x>0)┤
但是,连续性只是存在导数的必要条件,有一种情况函数连续但是不存在导数:
y=|x|
它的图像如图3-3所示。

图3-3
如果看左边,当 x≤0 时,这条线就是 y=|x|=-x,而当 x=0 时,导数是 dy/dx |_(x=0)=-1。如果看右边,当 x≥0 时,这条线就是 y=|x|=x,而当 x=0 时的导数是 dy/dx |_(x=0)=1。可以看出,当 x=0 时,从两个方向上得到的导数不一致,这违反了导数唯一性原则(导数反映了变化率,是唯一的)。因此,当 x=0 时,导数不存在。
我们总结一下 f(x) 的导数在 x=c 点存在需要满足的条件。
函数 f(x) 在 x=c 时连续。
函数 f(x) 在 x=c 时从两个方向分析导数,得到的结果一样。
在机器学习中,对于ReLU激活函数 f(x)=max(0,x):当 x>0 时,f^' (x)=1;当 x<0 时,f^' (x)=0;当 x=0 时,导数并不存在。但是,为了能顺利使用梯度下降法,一般会在工程上进行折中,即当 x=0 时,强制 f^' (x)=1。
3.4 多元函数求导
在机器学习中,函数一般都是多元函数,例如:
z=x^2+3xy+y^2
在多元函数中,一般使用 ∂z/∂x 和 ∂z/∂y 表示导数,它们也被称作偏导数。其实只是名字变
了,本质并没有变,∂z/∂x 仍然表示 x 的变化对 z 的影响。这具体怎么求偏导数呢?很简单,在求 ∂z/∂x 时,因为 x 和 y 是独立的两个变量,所以把 y 当作常数即可,可得
∂z/∂x=2x+3y
同理,在求 ∂z/∂y 时,把 x 当作常数,可得
∂z/∂y=3x+2y

3.5 二阶导数和高阶导数
对于函数 y=f(x)=x^2+3x+6,其导数 f^' (x)=dy/dx=2x+3 本身也是一个关于 x 的函数,因此我们可以对 f^' (x) 继续求导。对导数进行再次求导,就称为函数的二阶导数。二阶导数其实就是对 f^' (x)=2x+3 再次求导,记为
f^'' (x)=(d^2 y)/(dx^2 )=2
f^'' (x) 二阶导数的含义就是函数 f(x) 关于 x 变化率的变化率。怎么理解呢?例如,f(x) 表示房价,x 表示时间。希望房价下降,即需要 f^' (x)<0,随着时间的增长,房价降低。抑制房价过快上涨,就是指房价可以涨,但是不要增长太快,即希望 f^'' (x)<0。依此类推,我们可以得到三阶导数 f^''' (x),它表示抑制房价过快上涨的趋势。在机器学习中,一般最多用到二阶导数,高阶的导数很少使用。我们知道导数的几何意义是函数切线的斜率,那么二阶导数的几何意义是什么呢?
这里需要了解凸函数和凹函数。凸函数的数学定义如下:f 为区间 l 上的函数,对于区间上任意两个点 x_1 和 x_2,λ∈(0,1),满足
f(λx_1+(1-λ) x_2 )≤λf(x_1 )+(1-λ)f(x_2)
上面的式子应该怎么理解呢?令 x_3=λx_1+(1-λ) x_2,x_3 为 x_1 和 x_2 中间的点。上式其实想说明,x_3 在任意两点 x_1 和 x_2 上对应的函数值 f(x_3) 比 f(x_1 ) 和 f(x_2) 连线对应的值要小,即满足如图3-4所示的形状。
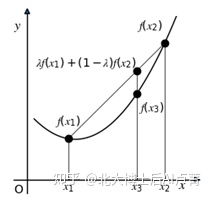
图3-4
从图形上可以看出,只要是向下凸,形状像碗一样的函数,都满足凸函数的条件。例如,函数 f(x)=x^2 就是典型的凸函数。这里不加证明的给出结论:如果函数的二阶导数 f^'' (x)≥0,那么函数就是凸函数。例如,当 y=f(x)=x^2 时,f^'' (x)=2≥0。
如果函数 f_1 (x)~f_n (x) 都为凸函数,并且都存在二阶导数,可得 f_1^'' (x)>0,⋯,f_n^'' (x)>0,那么函数
f(x)=f_1 (x)+⋯+f_n (x)
有
f^'' (x)=f_1^'' (x)+⋯+f_n^'' (x)>0
即 f(x) 也是凸函数。
同理,我们可以给出凹函数的定义:f 为区间 l 上的函数,对于区间上任意两个点 x_1 和 x_2,λ∈(0,1),满足
f(λx_1+(1-λ) x_2 )≥λf(x_1 )+(1-λ)f(x_2)
凹函数的开口方向和凸函数相反,是朝向下方的,类似于一个倒放的碗,如图3-5所示。

图3-5
参考凸函数的性质,如果 f^'' (x)≤0,那么函数 f(x) 就是凹函数。y=f(x)=-x^2 就是一个凹函数,其中 f^'' (x)=-2≤0。
需要注意的是,f^'' (x) 只是用来判断函数凹凸性的充分条件,而不是必要条件。这是因为,f^'' (x) 有可能在某些点上不存在。
例如,对于函数 y=f(x)=|x|,它的图形如图3-6所示。根据函数图形和凸函数的定义不难得出,它是一个凸函数,但是如前面的分析,f^' (0) 不存在,所以 f^''(0) 也不存在,因此,不能通过二阶导数进行判断。
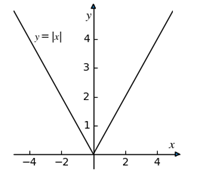
图3-6
最后,需要注意的是,如果 f^'' (x)=0,那么 f(x) 同时属于凸函数和凹函数,例如直线 f(x)=kx+c。
在多元函数 z=f(x_1,x_2,⋯,x_n) 中,二阶导数的求法和一阶基本一样,只不过需要考
虑变量之间的联系。例如,一阶导数 ∂f/(∂x_1 ) 是关于 x_1,x_2,⋯,x_n 的函数,因此,求二阶导时,
不仅需要对 x_1 求导,还需对其他变量求导:
(∂^2 f)/(∂x_1^2 ), (∂^2 f)/(〖∂x〗_1 ∂x_2 ), (∂^2 f)/(〖∂x〗_1 ∂x_n )
对于 ∂f/(∂x_1 )~∂f/(∂x_n ) 的二阶导也有类似结论。
因此,n 个变量的多元函数,二阶导数一共需要求 n^2 个偏导数,并且有如下规律。
(∂^2 f)/(〖∂x〗_j ∂x_i )=(∂^2 f)/(〖∂x〗_j ∂x_i )
举个例子,函数 f(x_1,x_2 )=x_1^2+2x_2^2+2x_1 x_2,那么一阶偏导数为
∂f/(∂x_1 )=2x_1+2x_2
∂f/(∂x_2 )=4x_2+2x_1
二阶偏导数为
(∂^2 f)/(∂x_1^2 )=2, (∂^2 f)/(〖∂x〗_1 ∂x_2 )=2, (∂^2 f)/(∂x_2^2 )=4, (∂^2 f)/(〖∂x〗_2 ∂x_1 )=2
3.6 函数的极大值和极小值
3.6.1 一元函数的极大值和极小值
当我们拿到一个函数后,经常需要知道它的最大值、最小值等指标。但需要注意,最大值和最小值、极大值和极小值是两组不同的概念,它们之间既有联系,又容易混淆。这两组概念的严格的数学定义比较抽象,我们进行一些简化。这两组概念的定义如下。
最大(最小)值:f(x) 在定义域内,能取到的最大(最小)数值。
极大(极小)值:f(x) 在 x0 附近有定义。如果所有 x0 附近的点 x 都有 f(x)<f(x0),那么 f(x0) 就为极大值。如果所有 x0 附近的点 x 都有 f(x)>f(x0),那么 f(x0) 就为极小值。
可以看出:极大值是一个局部概念(x0 附近的点),而最大值是一个全局概念(在定义域内);极小值同理。
举个例子,函数 f(x)=x^2,x∈(-∞,+∞),它的图像如图3-7所示。

图3-7
我们可以很容易地发现,这个函数没有最大值,因为随着 x→±∞,f(x)→∞,但是在整个定义域内,f(0)=0 就是函数的最小值。
下面我们分析极大值。同样,不存在一个点 x0,使 f(x0) 比周围的 f(x) 都大,所以极大值并不存在。在 x0=0 这一点,f(0) 小于周围所有的 f(x),所以 f(0) 为极小值。
我们再分析一下函数 f(x)=x^3+3x^2+3,图形如图3-8所示。可以看出,当 x→+∞ 时 f(x)→+∞,因此函数没有最大值。同理,x→-∞,f(x)→-∞,因此函数没有最小值。但是,当 x0=-2 时,f(x0)=7 比周围的 f(x) 都大,因此,f(-2)=7 为函数的极大值。同理,当 x0=0 时,f(0)=3 比周围的 f(x) 都小,因此 f(x0)=3 为函数的极小值。

图3-8
这里特别要注意,极大(小)值,不仅和具体数值有关,也和自变量相关。例如,在上述函数中,f(x)=3,可以解出 x=0 或 x=-3,但仅当 x=0 时,f(x)=3 才为极小值。
当我们拿到一个函数后,最大(小)值是一个全局概念,需要遍历定义域上的 x 才能最终得到答案,因此,想得到它的最大(小)值其实是一件非常困难的事情。得到极大(小)值相对容易,因为它是一个局部概念,只需和其周围的点比较即可。
如果 f(x0) 为极小值,我们可以发现:
当 x<x0 时,f(x)>f(x0),那么在小区间 (x0-δ,x0) 内函数为减函数,因此,f^' (x)<0,x∈(x0-δ,x0)。
当 x>x0 时,f(x)>f(x0),那么在小区间 (x0,x0+δ) 内函数为增函数,因此,f^' (x)>0,x∈(x0,x0+δ)。
现在,我们可以得出 x0 就是 f^' (x) 的正负交界点,所以有 f^' (x0)=0。同理,我们可以分析出,当函数 f(x0) 为极大值时也有 f^' (x0)=0。
需要注意的是,f^' (x0)=0 只是导数存在时判断极值的必要条件,但我们无法知道 f(x0) 是极大还是极小值(甚至可能不是极值)。例如,常函数 f(x)=3 不存在极大值和极小值,但 f^' (x)≡0。
那么,如何进一步判断当 f^' (x0)=0 时 x0 是极大值、极小值或者都不是呢?这时二阶导数就派上用场了。当 f^'' (x0)>0 时,函数的形状为“碗”状,例如 f(x)=x^2,f^' (0)=0 且 f^'' (0)=2,如图3-9所示。可以看出,f(0) 是极小值。

图3-9
当 f^'' (x0)<0 时,函数的形状为倒扣的“碗”状,例如 f(x)=〖-x〗^2,f^' (0)=0 且 f^'' (0)=-2,如图3-10所示。可以看出,f(0) 是极大值。

图3-10
因此,我们可以结合导数和二阶导数来判断极值,具体如下。
f(x0):{█(极大值f^' (x0)=0且f^'' (x0)>0@极小值f^' (x0)=0且f^'' (x0)<0)┤
需要注意的是,因为有些极小值在导数并不存在的点,例如 f(x)=|x|,所以上述条件为充分不必要条件。
3.6.2 多元函数的凹凸性和海森矩阵
在多元函数 z=f(x_1,x_2,⋯,x_n) 中,我们也可以判断函数的凹凸性。首先,定义海森矩阵,具体如下。

Hessian矩阵就是二阶导数和二阶偏导组成的对称矩阵。略去证明,我们通过它的正负定性判断是函数的凹凸性,并进一步确定是否为极值,是极大值还是极小值。
对多元函数 z=f(x)=f(x_1,x_2,⋯,x_n),我们如何求解极值呢?若 f(x) 在 m=[■(a_1@⋮@a_n )] 的邻域有二阶偏导,并且满足偏导数 ∂f/(∂x_j ) |_(x=m)=0,j=1,⋯,n,那么我们可以知道 f(m) 可能为极大值、极小值或者鞍点(后面会具体解释鞍点)。具体是哪一个呢?我们可
以通过 Hessian(f)|_(x=m) 进一步进行判断。
若 Hessian(f)|_(x=m) 为正定矩阵,f 为凸函数,那么 f(m) 为极小值。
若 Hessian(f)|_(x=m) 为负定矩阵,f 为凹函数,那么 f(m) 为极大值。
若 Hessian(f)|_(x=m) 不属于上面两种情况,那么 f(m) 为鞍点。
鞍点是指从一个方向看是极大值,另一个方向是极小值的点,如图3-11所示。
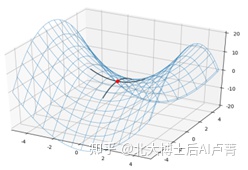
图3-11
通过前面的学习,我们知道可以通过特征值判断 Hessian(f)|_(x=m) 的正负定性。如果特征值 λ_1~λ_n 均大于0,那么 Hessian(f)|_(x=m) 为正定;如果特征值 λ_1~λ_n 均小于0,那么 Hessian(f)|_(x=m) 为负定;其他情况均为鞍点。
当 f 为 n 元函数时,我们假设 λ_i 取正负的概率各占50%,那么 Hessian(f)|_(x=m) 为正定概率为 1/2^n ,为负定的概率也为 1/2^n ,为鞍点的概率则为 1-1/2^n -1/2^n =1-1/2^(n-1) 。可以看出,当 n 非常大时,其为鞍点的概率几乎为1。
在神经网络中,优化对象是关于待训练参数 w=[■(w_1@⋮@w_n )] 的函数,即 Loss(w)。训练目
标是找到 Loss 的极小值所对应的参数 w。神经网络的参数非常多,即 n 非常大,导致 Loss(w) 存在大量鞍点,这增加了优化难度。在鞍点上,尽管损失函数仍然有下降空间,但是在使用梯度下降法优化模型时,∂Loss/∂w=0 会导致梯度不再更新,从而使梯度下降法失效。
3.6.3 凸优化证明
在机器学习中,训练过程其实就是寻找 Loss 函数对应的极小值及相应的参数 w,但有一个前提条件,就是 Loss 函数存在极小值。然而,Loss 函数存在极小值,但可能存在多个极小值,即有局部极小存在,如果初始化不当,w 就有可能最终陷入局部极小,这对学习有一定的不利影响(大多数神经网络都存在这个问题)。
如果我们可以证明 Loss 函数为凸函数,那么它的极值分为以下两种情况。
存在局部极小,即存在 ∂Loss/∂w=0,那么它就只存在唯一的局部极小,并且可以通过梯度下降法求解。因为不存在局部极小,所以模型对初始参数不敏感。
不存在局部极小,即不存在 ∂Loss/∂w=0,但是使用梯度下降法不断减小 Loss 函数的值,也能满足我们的需求。
可以看出,如果 Loss 函数为凸函数,就可以放心使用梯度下降法获得全局唯一最优解。我们真正需要关心的是 Loss 函数是否为凸函数,这就将问题转化为判断 Loss 函数对应的Hessian矩阵是否为正定矩阵了——如果为正定矩阵,就是凸函数。
虽然在大多数神经网络中,Loss 函数并不是凸函数,但是在线性回归和逻辑回归中,Loss 函数是凸函数。因为多个凸函数相加仍然是凸函数,所以,为了方便,我们只需要证明单个样本对应的损失函数为凸函数,它们相加求和的损失函数也为凸函数即可。下面就讲解证明过程。
1.线性回归
在线性回归中,损失函数如下。
Loss(w_0,w_1,⋯,w_n)=(〖〖w_0 x_0+w〗_1 x〗_1+⋯+w_n x_n-y)^2
在这里,x_0≡1(这样写只是为了方便写成统一的形式),并且 x=[■(x_0@x_1@…@x_n )]≠0。
求 Loss 关于 w 的二阶导数,即构建Hessian矩阵。
∂Loss/(∂w_i )=2(〖〖w_0 x_0+w〗_1 x〗_1+⋯+w_n x_n-y) x_i
那么
(∂^2 Loss)/(∂w_i^2 )=2x_i^2
同理
(∂^2 Loss)/(∂w_i ∂w_j )=2x_i x_j
因此,Hessian矩阵为
Hessian(Loss)=[■(2x_0^2&2x_1 x_2&⋯&2x_1 x_n@2x_2 x_1&2x_1^2&⋯&⋮@⋮&⋮&⋱&⋮@2x_n x_1&⋯&⋯&2x_n^2 )]=2xx^T
其中
x=[■(x_0@⋮@x_n )]
我们根据定义证明函数的正定性,即对于任意向量 z∈R^(n+1)(z≠0),有
z^T Hessian(Loss)z=2z^T xx^T z=2‖x^T z‖>0
Hessian是正定矩阵,损失函数 Loss 为凸函数。
2.逻辑回归
在逻辑回归中,损失函数为
Loss(w_0,w_1,⋯,w_n )=-ylogy^'-(1-y)log〖(1-y〗^')
y^'=1/(1+e^(-(〖〖w_0 x_0+w〗_1 x〗_1+⋯+w_n x_n)) )
因此
∂Loss/(∂w_i )=(y^'-y)x_i
那么
(∂^2 Loss)/(∂w_i^2 )=y^' 〖(1-y〗^')x_i^2
(∂^2 Loss)/(∂w_i ∂w_j )=y^' 〖(1-y〗^')x_i x_j
参考线性回归的Hessian矩阵,可得
Hessian(Loss)=y^' 〖(1-y〗^')xx^T
我们可以证明:
z^T Hessian(Loss)z=y^' 〖(1-y〗^')z^T xx^T z=y^' 〖(1-y〗^')‖x^T z‖>0
因此,逻辑回归的损失函数的Hessian矩阵也为正定矩阵。
3.L2正则
在机器学习中,经常会使用L2正则进行优化。我们了解一下L2正则对应的损失函数是否为凸函数。如果为凸函数,那么逻辑回归和L2正则、线性回归和L2正则也仍然为凸函数。L2正则的损失函数如下。
Loss=w_1^2+⋯+w_n^2
所以,有
∂Loss/(∂w_i )=2w_i
那么
(∂^2 Loss)/(∂w_i^2 )=2
(∂^2 Loss)/(∂w_i ∂w_j )=0
因此
Hessian(Loss)=2E
E 为单位矩阵,Hessian(Loss) 显然是一个正定矩阵。因此,L2正则对应的Loss函数也为凸函数。
4.L1正则
L1正则的损失函数如下。
Loss=|w_1 |+⋯+|w_n |
那么,有
∂Loss/(∂w_i )=1
或者
∂Loss/(∂w_i )=-1
但是,无论是上面何种情况,都有
(∂^2 Loss)/(∂w_i^2 )=0
(∂^2 Loss)/(∂w_i ∂w_j )=0
所以,Hessian(Loss) 是一个全0的半正定矩阵,即Loss函数是非凹函数。
第4章 微积分在深度学习中的应用
4.1 梯度下降法
4.1.1 梯度下降法在深度学习中的应用
通过前面的学习,我们知道了函数的极小值、极大值及它们对应的条件。在机器学习中,理想情况下,我们所谓的训练就是通过训练数据找到 Loss 函数的最小值所对应的自变量(待学习参数)。但是,找到最小值是一件非常困难的事情,因为需要遍历整个定义域才能得到,而算力不支持如此庞大的运算量。因此,我们往往退而求其次,降低要求,把求最小值简化成求极小值。
例如,在线性回归中,为了简化问题,假设特征维度为1,损失函数如下。
Loss=1/N ∑_(i=1)^N▒〖(wx_((i) )+w_0-y_((i) ))〗^2
其中,w 和 w_0 为自变量,x_((i) ) 和 y_((i) ) 为常数且 x_((i) ) 至少有一个不为0。如果所有 x_((i) )=0,则损失函数没有意义。
要想求得 Loss 的极小值所对应的 w=w^* 和 w_0=w_0^*,应该怎么做呢?
之前有过证明,线性回归的损失函数 Loss 为凸函数,它只存在极小值。因此,我们只
需要令一阶导数 ∂Loss/∂w=0,∂Loss/(∂w_0 )=0,即可求出极小值对应的 w^* 和 w_0^*,具体如下。
∂Loss/∂w |_(w=w^*,w_0=w_0^* )=2/N ∑_(i=1)^N▒〖x_((i) ) (w^* x_((i) )+w_0^*-y_((i) ))〗=0
∂Loss/(∂w_0 ) |_(w=w^*,w_0=w_0^* )=2/N ∑_(i=1)^N▒〖(w^* x_((i) )+w_0^*-y_((i) ))〗=0
易得
w^*=(∑_(i=1)^N▒〖(x_((i) )-x ̅)(y_((i) )-y ̅)〗)/(∑_(i=1)^N▒〖(x_((i) )-x ̅)〗^2 )
w_0^*=w^* x ̅-y ̅
其中
x ̅=1/N ∑_(i=1)^N▒x_((i) )
y ̅=1/N ∑_(i=1)^N▒y_((i) )
但是,并不是所有的函数都容易找到 w^* 和 w_0^* 的解析解。例如,当函数为多元函数时,有
Loss(w_0,w_1,⋯,w_m)=1/N ∑_(i=1)^N▒〖(w_0+w_1 x_((i),1)+w_2 x_((i),2)+⋯+w_m x_((i),m)-y_((i) ))〗^2
其中,x_((i),1)~x_((i),m) 为常数,w_0~w_m 为变量。
我们记 w=[■(w_1@⋮@w_m )],x=[■(x_1@⋮@x_m )],Loss 可简写成
Loss(w_0,w)=1/N ∑_(i=1)^N▒〖(w_0+w^T x_((i))-y_((i) ))〗^2
我们的目标没变,依旧是求 Loss 函数的极小值,以及对应的 w^*=[■(w_1^*@⋮@w_m^* )]和 w_0^*。因此,我们只需求解方程组
∂Loss/(∂w_j ) |_(w_0=w_0^*,w=w^* )=2/N ∑_(i=1)^N▒〖x_((i),j) (w_0^*+〖w^*〗^T x_((i))-y_((i) ))〗=0,j=1,⋯,m
∂Loss/(∂w_0 ) |_(w_0=w_0^*,w=w^* )=2/N ∑_(i=1)^N▒〖(w_0^*+w^* x_((i))-y_((i) ))〗=0
共计 m+1 个方程,m+1 个未知数。
理论上,我们可以求解 m+1 元1次方程,但在实际应用中,m 一般可以非常大,这时候求解方程就会遇到计算上的困难。既然求解方程行不通,是否还有其他的方法呢?
我们可以随机初始化 w_0=w_0^((0)) 和 w=w^((0)),即向量中每个元素都是随机产生的。其
中,∂Loss/(∂w_j ) |_(w_0=w_0^((0)),w=w^((0)) ) 表示 w_j 变化引起 Loss 变化的方向。下面我们分三种情况对 ∂Loss/(∂w_j ) |_(w_0=w_0^((0)),w=w^((0)) ) 进行讨论。
∂Loss/(∂w_j ) |_(w_0=w_0^((0)),w=w^((0)) )>0,此时函数关于 w_j 为增函数,则表示 w_j 变小,Loss 变小。
∂Loss/(∂w_j ) |_(w_0=w_0^((0)),w=w^((0)) )<0,此时函数关于 w_j 为减函数,则表示 w_j 变大,Loss 变小。
∂Loss/(∂w_j ) |_(w_0=w_0^((0)),w=w^((0)) )=0,则表示 Loss 已经达到最小值,w_j 无需变化。
综合上述三点,可以发现 w_j 朝 ∂Loss/(∂w_j ) |_(w_0=w_0^((0)),w=w^((0)) ) 的反方向变化,就可以使 Loss 变小。需要注意的是,∂Loss/(∂w_j ) |_(w_0=w_0^((0)),w=w^((0)) ) 仅指明了 w_j 变化的方向,并没有指出需要变化多
少。因此,我们可以进行如下更新。
w_j^((1))=w_j^((0))-μ ∂Loss/(∂w_j ) |_(w_0=w_0^((0) ),w=w^((0) ) ),j=0,1,⋯,m
其中,μ 为学习因子,用来控制 w_j 变化的幅度。更新后的 Loss(w_0=w_0^((1)),w=w^((1)) )≤Loss(w_0=w_0^((0)),w=w^((0)) ),w 的变化起到了减小 Loss 的作用。
因此,求解函数 Loss(w_0,w) 的极小值,可以使用如下方法。
随机初始化 w_0=w_0^((0)) 和 w=w^((0)),t=0。
同时,更新参数
w_j^((t+1))=w_j^((t))-μ ∂Loss/(∂w_j ) |_(w_0=w_0^((t) ),w=w^((t) ) ),j=1,⋯,m
和
w_0^((t+1))=w_0^((t))-μ ∂Loss/(∂w_0 ) |_(w_0=w_0^((t)),w=w^((t)) )
如果 t>T(指定迭代次数),或者 Loss 已经足够小了,或者 Loss 的变化已经很小,则任务结束,w^*=w^((t)) 和 w_0^*=w_0^((t))。否则,t=t+1,返回。
上述方法就是梯度下降法。相比于直接求解方程,梯度下降法有如下优点。
避免了方程无解析解,或者计算过于复杂的缺点。
更为通用,任何一个函数,只要存在一阶导数,都可以使用梯度下降法求解极小值。
这里说一下 μ 不能太大的原因。因为我们求解的梯度是在 w^((t)) 和 w_0^((t)) 这个点上的,在这个点周围可以近似认为梯度变化较小,而如果 μ 过大,导致远离该点,那么梯度本身就会发生变化,因此,移动方向就不准了。这就好比给人指路,指路的方向仅在短距离有效,距离越远,方向就越不准。
4.1.2 泰勒公式和梯度下降法
在数学中,我们研究的函数有无数个,如果要全部研究,几乎是一件不可能完成的事情。那么,函数是否有共性呢?例如,各类函数有没有可能都由基础元素组成,只是比例不同。这就好比一家果汁店,有十几种水果,通过不同的组合和比例,可以勾兑出很多种果汁,但是万变不离其宗,基础元素始终就是那十几种水果。泰勒公式就是一把解剖函数的手术刀,它将函数进行分解,找到对应的基本水果,便于我们研究。
泰勒公式的意思是,任何一个光滑的函数都可以用 n 阶多项式函数去逼近,即
f(x)=f(x0)/0!+(f^' (x0))/1! (x-x0)+(f^'' (x0))/2! (x-x0)^2+⋯+(f^((n) ) (x0))/n! (x-x0)^n+R_n (x)
=∑_(i=0)^n▒〖(f^((i) ) (x0))/i! (x-x0)^i 〗+R_n (x)
我们称上式为 f(x) 在 x0 上的泰勒展开,其中 x0 为定义域上各阶导数都存在的任意点。R_n (x) 是一个高阶无穷小,表示展开后的误差,它的大小与 n 和 x 有关。自变量 x 离 x0 越近,R_n (x) 越小,多项式逼近就越准。n 越大,R_n (x) 越小,多项式次数越高,逼近函数就越精确。为了研究方便,一般会直接忽略 R_n (x)。
泰勒公式给了我们一个启示:在机器学习中,无论需要逼近的函数形式有多复杂,最终都可以由 n 阶多项式进行逼近。
当 x=x0 时,对应的函数值为 f(x0)。我们给 x0 添加一个变化,即变为 x0+Δx,函数值则变为 f(x0+Δx)。如果我们希望 f(x0+Δx)≤f(x0),即函数朝小的方向变化,那么 Δx 应该为多少呢?
我们对函数进行一阶泰勒展开,并省略 R_1 (x),可以看到
f(x0+Δx)≈f(x0)+f^' (x0)Δx
为了满足 f(x0+Δx)≤f(x0),易得 f^' (x0)Δx<0,即 Δx 的符号和 f^' (x0) 相反,所以,x 的移动方向为 -f^' (x0)。不过,需要注意的是,我们之所以能够忽略 R_1 (x),是因为 Δx 足够小,从而保证了 x0+Δx 在 x0 附近,忽略 R_1 (x) 不会有太大误差。因此,x0 的移动不能过大,即真实的移动为
x0-μf^' (x0)
μ 通常较小,以保证泰勒展开误差不大。但是,μ 也不宜过小,如果过小,就会导致更新效率变低。以上即为梯度下降法的理论基础。
4.1.3 牛顿迭代法
在求解方程的时候,一些特定的如一元二次方程都有特殊的解析解,即方程解和各项系数有显示的关系,如一元二次方程
ax^2+bx+c=0
对应的解为
x=(-b±√(b^2-4ac))/2a
但是,很多方程复杂的方程很难找到其对应的解析解。例如,对方程
f(x)=x^7+2x^2+4x+3=0
我们就无法找出上面类似的公式直接算出 x。
我们可以使用一种特殊的迭代法来解方程 f(x)=0。设 x^* 为方程的解,即 f(x^* )=0。首先,假设一个初始点 x^((k)),在它附近进行泰勒展开,忽略 R_1 (x),可以得到
f(x)≈f(x^((k)) )+f^' (x^((k) ) )(x-x^((k) ))
令 f(x)=0,可以求得
x=x^((k) )-f(x^((k)) )/(f^' (x^((k) ) ) )
但是,一般来说,x≠x^*,即 x 并不是 f(x)=0 的解。这是因为泰勒展开式仅在 x^((k) ) 附近有效,如果 x^((k) ) 离 x^* 较远,自然就不准确。这只是一个粗略的估计,但相比 x^((k) ) 和 x^* 的距离,x 更靠近 x^*。如果 x^((k) ) 越来越靠近 x^*,那么使用泰勒展开式求解的结果会越来越准。因此,我们使用如下迭代过程求解方程。
随机初始化 x^((0) ),k=0。
计算 x^((k+1) )=x^((k) )-f(x^((k)) )/(f^' (x^((k) ) ) )。
验算 f(x^((k+1) ) )。如果 f(x^((k+1) ) )=0,则迭代结束,x^*=x^((k+1) )。否则,k=k+1,返回。
上述解方程的方法称为牛顿迭代法。只要方程存在解,那么无论方程本身多复杂,通过牛顿迭代法一定能找到。需要注意的是,如果方程有多个解,我们只能找到离初始值 x^((0) ) 最近的解。例如,求解方程
f(x)=x^7+2x^2+4x+3=0
的迭代过程如表4-1所示,初始化 x^((0) )=2。
表4-1
迭代次数 x^((k) ) f(x)
k=0 2.0 147.0
k=1 1.68 53.21
k=2 1.364 20.981
k=3 0.98 9.711
k =4 0.293 4.343
k =5 -0.546 1.397
k =6 -1.245 -3.506
k =7 -1.105 -0.984
k =8 -1.025 -0.184
k =9 -1.002 -0.011
k =10 -1.0 0.0
经过10次迭代,牛顿迭代法找到了 x^7+2x^2+4x+3=0 对应的解 x^*=-1。下面我们看看如何在神经网络中应用牛顿迭代法。
在神经网络中,训练的目的就是找到函数的极小值,而极小值进一步转变为求解方程
f^' (x)=0
我们依然可以使用牛顿迭代法求解。令 〖g(x)=f〗^' (x),那么
g(x^((k) ) )=f^' (x^((k) ) )
g^' (x^((k) ) )=f^'' (x^((k) ) )
因此,求解 f^' (x)=0 其实就是解方程 g(x)=0,迭代过程如下。
随机初始化 x^((0) ),k=0。
计算 x^((k+1) )=x^((k) )-g(x^((k) ) )/(g^' (x^((k) ) ) )=x^((k) )-(f^' (x^((k) ) ))/(f^'' (x^((k) ) ) )。
验算 f^' (x^((k+1) ) )。如果 f^' (x^((k+1) ) )=0,则迭代结束,x^*=x^((k+1) )。否则,k=k+1,返回。
可以看出,使用牛顿迭代法找函数的极值和梯度下降法类似,只不过学习因子 μ 被替换成了 1/(f^'' (x^((k) ) ) )。相比于固定的学习因子 μ,1/(f^'' (x^((k) ) ) ) 更加灵活,可以根据函数当前所在位置动态调整加快收敛速度。例如,对函数
f(x)=x^2
我们求解它的极小值。假设初始值为 x^((0) ),那么
f^' (x^((0) ) )=2x^((0) )
f^'' (x^((0) ) )=2
x^((1) )=x^((0) )-(2x^((0) ))/2=0
即无论初始值 x^((0) ) 为何,均可一步到位,直接找到极小值 x^*=0,加快了收敛速度。
不过,需要注意的是,牛顿迭代法只是用来迭代求解方程 f^' (x^* )=0 的,而 f(x^* ) 有可能是局部极小值,甚至有可能是极大值。
在神经网络中,待求解的参数 w∈R^(n×1) 为向量,也可以使用牛顿迭代法求解,具体迭代方法如下。
w^((k+1) )=w^((k) )-〖H^((k))〗^(-1) g^((k))
其中,g^((k))=├ ∂Loss/∂w┤|_(w=w^((k) ) ),H^((k)) 为 Loss 的 hessian 函数,即
H^((k))=├ hessian(Loss)┤|_(w=w^((k) ) )
线性代数中的逆矩阵就类似于导数。可以看出,牛顿迭代法在求解向量方程的时候并没有特殊之处。
但是,H 是二阶导数对应的矩阵,如果 w∈R^(n×1) 为 n 维向量,那么 H 中一共有 (n(n-1))/2+n 个参数需要计算,这带来的运算量非常大。而且,求大矩阵的逆矩阵也非常消耗计算资源,在神经网络中可行性不高。因此,需要对牛顿迭代法进行改进,改进的方法称为“拟牛顿法”。拟牛顿法涉及的数学内容过多,本书仅给出结论,对此感兴趣的读者可以自行查阅相关资料。
拟牛顿法的核心思路就是让矩阵 G^((k)) 来近似 〖H^((k))〗^(-1),并且 G^((k)) 也可以通过递推的方式计算,省去了求解逆矩阵的过程。
G^((k)) 也有不同的迭代求解方法。首先,我们定义
δ^((k-1))=x^((k))-x^((k-1))
y^((k-1))=g^((k))-g^((k-1))
G^((0))=E
略去推导细节,下面介绍两种最常见的方法。
DFP算法,具体如下。
G^((k))=G^((k-1))+(δ^((k-1)) 〖〖(δ〗^((k-1)))〗^T)/(〖〖(δ〗^((k-1)))〗^T y^((k-1)) )-(G^((k-1)) y^((k-1)) 〖(y^((k-1)))〗^T G^((k-1)))/(〖(y^((k-1)))〗^T G^((k-1)) y^((k-1)) )
BFGS算法,具体如下。
G^((k))=(E-(δ^((k-1)) 〖〖(δ〗^((k-1)))〗^T)/(〖〖(δ〗^((k-1)))〗^T y^((k-1)) )) G^((k-1)) (E-(δ^((k-1)) 〖〖(δ〗^((k-1)))〗^T)/(〖〖(δ〗^((k-1)))〗^T y^((k-1)) ))^T+(δ^((k-1)) 〖〖(δ〗^((k-1)))〗^T)/(〖〖(δ〗^((k-1)))〗^T y^((k-1)) )
这两种算法使用不同的方法计算 G^((k))。在使用牛顿迭代法时,我们用 G^((k)) 去近似 〖H^((k))〗^(-1) 将省去大量的运算,从而提高效率。
4.2 梯度下降法的缺点
通过上面的分析,我们可以使用梯度下降法代替解方程,找到函数Loss的极小值。梯度下降法是目前线性回归、逻辑回归,神经网络的主流训练方法。但是梯度下降法也有其缺点,本节就将着重讲解梯度下降法在机器学习中存在的问题。
首先是局部极小值问题。如图4-1所示:如果初始化在a点,那么根据梯度下降法的原理,w 就会通过梯度下降法移动至c,从而找到局部极小值;但是,如果初始化在b点,那么最终找到的局部极小值就会在d点。可以发现,如果我们的目标是获得Loss最小的值,那么d点显然不如c点好,因此d点也称作局部最优。在使用梯度下降法找寻Loss的极小值时,如果初始点选取不当,很容易陷入局部极小。然而,Loss曲线在高维空间中异常复杂,缺乏正确选取初始点的方法,大部分时候依赖运气和多次尝试。

图4-1
我们使用梯度下降法求解时,如果 ∂Loss/∂w |_(w_1=w_1^((0)),⋯〖,w〗_m=w_m^((0)) )=0,w 就不会进行更新,算法会认为已经找到极小值。但鞍点是一个特殊情况,如图4-2所示。

图4-2
在 w1 方向上,Loss达到了极小值。而在 w2 方向上,虽然 ∂Loss/(∂w_2 ) |_(w_0=w_0^((0)),⋯〖,w〗_m=w_m^((0)) )=0 对应的是极大值,Loss仍然有下降空间,但是算法却会停止迭代。
当我们优化目标为
Loss(w_1,w_2)=〖(〖w_0+w〗_1 x_1+w_2 x_2-y)〗^2
时,为了更直观地理解训练阶段 w=〖[w_1,w_2]〗^T 各维度的数值更新,我们可以画出 w 坐标系中损失函数的等高线图。尽管每个 w 对应于唯一的 Loss,但一个 Loss 会对应于多个取不同值的 w。对应于同一个 Loss 值的 w 连接起来组成的线,称为等高线。如图4-3所示,箭头表示在学习阶段 w 的变化路径(通过梯度下降法进行变化)。同一条等高线上的 Loss 值相同。在学习阶段,梯度下降法会迭代移动 w,使 w 移动到低势的等高线上(靠近中心)。
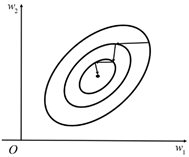
图4-3
如果特征 x_1 的数量级远大于特征 x_2,那么 Loss 将对 w_1 更敏感,w_1 的轻微波动会对Loss造成很大的影响,并最终导致 Loss 剧烈波动;w_2 的变化对 Loss 的影响则相对较小。例如:x_1 表示身高,单位为毫米;x_2 表示体重,单位为千克;数据特征为 〖[1750,60]〗^T。可以看出,x_1 在数量级上是 x_2 的100倍,在等高线上表现为:Loss 等高线在 w_1 方向比较“窄”,w_1 的轻微变化会导致等高线上较大的移动,即 Loss 对 w_1 方向较为敏感。相应的,Loss 对 w_2 方向较为迟钝。因此,在学习阶段,为了使 w_1 和 w_2 对 Loss下降的贡献一致,理想的状态是:敏感的 w_1 每次更新幅度相对较小,迟钝的 w_2 每次更新幅度相对较大。
我们再看看当特征维度 x_1 和 x_2 的数量级差异过大时各维度 w 更新梯度的实际情况,公式如下。
∂Loss/∂w=[■(∂Loss/(∂w_1 )@∂Loss/(∂w_2 ))]=2(w_1 x_1+w_2 x_2-y)[■(x_1@x_2 )]
可以发现,∂Loss/(∂w_i ) 和 x_i 成正比。
在这个例子中,∂Loss/(∂w_1 ) 在数量级上大于 ∂Loss/(∂w_2 ),因此,每次更新 w 时,在 w_1 方向上的移动幅度大于 w_2,这与上面的理想情况相悖。实际学习过程如图4-4所示。这种现象称为
zigzag,等高线 Loss 对 w_1 和 w_2 方向的敏感程度差异过大,非常不利于参数学习。
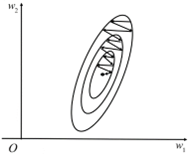
图4-4
在理想情况下,我们希望 w_1 和 w_2 的变化对 Loss 的影响处于同一量级,即 ∂Loss/(∂w_1 ) 和 ∂Loss/(∂w_2 ) 在数值上处于同一量级(有利于优化)。∂Loss/(∂w_1 ) 和 ∂Loss/(∂w_2 ) 数量级不一致的原因是特征 x_1 和 x_2 的数量级不一致。因此,需要制定一个标准,把各维度的特征归一到同一个数量级。
通过方差将 x_1 和 x_2 归一化,也就是说,先计算 x_1 和 x_2 维度的标准差 δ_1 和 δ_2,再更新 x_1 和 x_2,公式如下。
x_1^'=x_1/δ_1 ,x_2^'=x_2/δ_2
此时,w_1 和 w_2 对 Loss 的影响一致,等高线为圆形,如图4-5所示。

图4-5
当等高线为圆形时,等高线对各个维度的敏感程度就是相同的了。此时,可以设置较大的学习因子来减少梯度下降的迭代次数,加快训练进程。图中箭头的方向就是 w 的更新方向,w 不再反复震荡,学习速度得到了提高。
4.3 矩阵求导术
在深度学习中,网络变换一般用矩阵表示,这样更加简洁明了。使用梯度下降法训练神经网络时,就必然涉及矩阵和向量的求导,因此,我们有必要了解矩阵求导。矩阵求导本质上和普通函数求导没有区别,都是反映自变量和因变量之间的变化关系,只不过涉及标量、向量、矩阵,因此显得烦琐。另外,矩阵相乘有尺寸方面的要求,这也让链式法则的应用需要满足一定的规范。
4.3.1 标量对向量和矩阵求导
例如,在线性回归中
y=w^T x+w_0
其中,w∈R^(n×1),x∈R^(n×1),y 为标量。
那么 ∂y/∂w 为多少呢?首先我们要明确一点,因为 w∈R^(n×1),∂y/∂w 的物理意义是 y 随着 w 每个元素的变化而变化的方向,所以 ∂y/∂w 和 w 的尺寸一一对应,它们的向量尺寸一样,即
∂y/∂w=[■(∂y/(∂w_1 )@⋮@∂y/(∂w_n ))], ∂y/∂w∈R^(n×1)
那么,在线性回归中
y=w^T x+w_0=w_1 x_1+⋯+w_n x_n+w_0
∂y/(∂w_i )=x_i
因此,我们可以得到
∂y/∂w=[■(∂y/(∂w_1 )@⋮@∂y/(∂w_n ))]=[■(x_1@⋮@x_n )]=x
类似的,w^T∈R^(1×n) 为行向量,因此
∂y/(∂w^T )=[∂y/(∂w_1 ),⋯,∂y/(∂w_n )]=x^T
同理,当 W∈R^(m×n) 时,∂y/∂W 的尺寸和 W 一样,并且 ∂y/∂W∈R^(m×n) 中的每个元素和 W 是一一对应的,即
∂y/∂W=[■(∂y/(∂w_1,1 )&⋯&∂y/(∂w_(1,n) )@⋮&⋱&⋮@∂y/(∂w_(m,1) )&⋯&∂y/(∂w_(m,n) ))]
例如,y=xWz,W∈R^(m×n),x∈R^(1×m),z∈R^(n×1),那么
y=[x_1,⋯,x_m ][■(w_1,1&⋯&w_(1,n)@⋮&⋱&⋮@w_(m,1)&⋯&w_(m,n) )][■(z_1@⋮@z_n )]
展开可以得到
y=∑_(i=1)^m▒∑_(j=1)^n▒w_(i,j) x_i z_j
那么
∂y/∂W=[■(∂y/(∂w_1,1 )&⋯&∂y/(∂w_(1,n) )@⋮&⋱&⋮@∂y/(∂w_(m,1) )&⋯&∂y/(∂w_(m,n) ))]=[■(x_1 z_1&⋯&x_1 z_n@⋮&⋱&⋮@x_m z_1&⋯&x_m z_z )]
4.3.2 向量对向量求导
如果向量 z=Wx,z∈R^(n×1),W∈R^(n×m),x∈R^(m×1),那么 ∂z/∂x 为多少呢?
当列向量 z 对列向量 x 求导时,对应的物理含义是对 z 中的所有元素 x 求导,并将结果组成向量,即
∂z/∂x=[■((∂z_1)/∂x@⋮@(∂z_n)/∂x)]
根据前面的分析,∂z/∂x 中每个元素 (∂z_i)/∂x 的维度和 x 一样,都是 m 维的列向量,因此,∂z/∂x∈R^(nm×1),即一个 nm×1 维的列向量。例如:
[■(z_1@…@z_n )]=[■(w_11&…&w_1m@…&…&…@w_n1&…&w_nm )][■(x_1@…@x_m )]
所以
∂z/∂x=[■(w_11@…@w_1m@w_21@…@w_2m@…@w_n1@…@w_nm )]
这样计算出来的超长向量往往不便于后续计算,因此我们一般会转而求解 ∂z/(∂x^T )。
根据前面的分析,因为 x^T 〖∈R〗^(1×n),所以 (∂z_i)/(∂x^T ) 的维度和 x^T 一样,即 (∂z_i)/(∂x^T ) 〖∈R〗^(1×n) 为一个行向量。将所有行向量 (∂z_i)/(∂x^T )(i=1,⋯,m)排成一列,构成 ∂z/(∂x^T ),即 ∂z/(∂x^T )=[■((∂z_1)/(∂x^T )@⋮@(∂z_n)/(∂x^T ))],列中的所有元素 (∂z_i)/(∂x^T ) 则对应于一个 R^(1×n) 行的向量,所以,∂z/(∂x^T )∈R^(m×n) 为一个矩阵。因此,对于 z=Wx,z∈R^(n×1),W∈R^(n×m),x∈R^(m×1),有
∂z/(∂x^T )=[■(w_11&…&w_1m@…&…&…@w_n1&…&w_nm )]=W, ∂z/(∂x^T )∈R^(n×m)
4.3.3 链式法则
在神经网络中,Loss 和前层权重都是层层传导相连的,直接求导不方便,所以一般通过链式法则求导。但是,对向量/矩阵使用链式法则求导时,因为涉及对尺寸有匹配要求的矩阵/向量相乘,所以并不像普通函数一样直接。这里介绍两个常用的公式,通过它们,我们基本可以解决神经网络中大部分涉及求导的问题。
第一个公式:x_1~x_n 均为列向量,z 为标量,若它们之间的依赖关系为 x_1→x_2→⋯→x_n→z,则有
∂z/(∂x_1 )=((∂x_n)/(∂(x_(n-1) )^T ) (∂x_(n-1))/(∂(x_(n-2) )^T )⋯(∂x_2)/(∂(x_1 )^T ))^T ∂z/(∂x_n )
例如,z=w^T y,y=Mx,其中,x∈R^(m×1),y∈R^(n×1),M∈R^(n×m),w∈R^(n×1)。带入上式,可以得到
∂z/∂x=(∂y/(∂x^T ))^T ∂z/∂y
根据前面的学习,我们知道
∂y/(∂x^T )=M
∂z/∂y=w
所以,可以得到
∂z/∂x=M^T w
第二个公式:W 为矩阵,z 为标量,x 和 y 均为向量,若 z=f(y),y=Wx,则有
∂z/∂W=∂z/∂y x^T
例如,z=w^T y,y=Mx,其中 x∈R^(m×1),y∈R^(n×1),M∈R^(n×m),w∈R^(n×1),求 ∂z/∂M。带入上式可得
∂z/∂M=∂z/∂y x^T=wx^T
假设有一个双层分类神经网络,输入为 x∈R^(m×1),输出为 y^'∈(0,1) 且为标量,模型具体如下。
z=Wx+w0
d=mz+b
y^'=sigmoid(d)
使用KL距离作为损失函数,y 为数据的真实类别,即
Loss=-ylogy^'-(1-y)log(1-y^')
其中,W∈R^(n×m),z∈R^(n×1),m∈R^(1×n),b∈R,d∈R。
我们通过标量之间的求导得到
∂Loss/(∂y^' )=-y/y^' +(1-y)/(1-y^' )
〖∂y〗^'/∂d=y^' (1-y^')
那么
∂Loss/∂d=∂Loss/(∂y^' ) 〖∂y〗^'/∂d=y^'-y
使用梯度下降法进行训练时,需要计算:
∂Loss/∂m=∂Loss/∂d ∂d/∂m,因为 d=mz+b,所以 ∂d/∂m=z^T,那么有 ∂Loss/∂m=∂Loss/∂d ∂d/∂m=〖(y〗^'-y)z^T。
∂Loss/∂b=∂Loss/∂d ∂d/∂b,因为 d=mz+b,所以 ∂d/∂b=1,那么有 ∂Loss/∂m=∂Loss/∂d ∂d/∂m=〖(y〗^'-y)。
∂Loss/∂W=∂Loss/∂d ∂d/∂W,因为 z=Wx+w0,d=mz+b。根据本节讲解的第二个公式,∂d/∂W=∂d/∂z x^T=m^T x^T,所以 ∂Loss/∂W=∂Loss/∂d ∂d/∂W=〖(y〗^'-y)m^T x^T。
∂Loss/∂w0=∂Loss/∂d ∂d/∂w0,根据本节讲解的第一个公式,∂d/∂w0=(∂z/(∂〖w0〗^T ))^T ∂d/∂z=Em^T=m^T,所以 ∂Loss/∂w0=∂Loss/∂d ∂d/∂w0=〖(y〗^'-y)m^T。
4.4 常见激活函数及其导数
在神经网络中,激活函数起到了非线性化、过滤噪声的作用,对模型效果至关重要,同样的模型结构采用不同的激活函数,带来的训练和预测效果往往会大相径庭。本节深入讲解常用的激活函数特性及它们对应的导数,对设计模型、应对面试大有裨益。
为了解决复杂场景中的问题,神经网络往往会设计得很深,以期获得更好的效果。但是
如果网络过深,那么计算第 层参数的梯度 就需要通过链式法则反向传播求解,而这
涉及 、 等层的激活函数的连乘。激活函数选择不当,数值过大或者过小,就会导致梯度消失或者梯度爆炸。
常见的激活函数,例如Tanh、Sigmoid,公式如下。
Tanh(d)=(ed−e(−d))/(ed+e(−d))=Sigmoid(2d−1)Sigmoid(d)=1/(1+e(−d))
它们的函数和导数,如图4-6所示。

图4-6
可以看出, 函数、Tanh函数的导数都小于1,如果多次相乘,就会趋近于0。
而且,越是网络的前层( 的值越小), 就越接近0(梯度下降法时,涉及连乘的次数
多)。这会导致损失函数对前层参数求导的结果过小,使前层参数因更新幅度过小而得不到更新,这就是所谓“梯度消失”。因为 函数的导数值比 函数大一些,所以梯度消失问题的影响相对小一些。
函数和 函数都有饱和区,如图4-7所示。在饱和区内,输入 的变化几乎不会引起输出 的变化,也就是说,输入的变化对输出的影响极小,并且 ,参数将得不到学习。

图4-7
梯度消失和激活函数饱和问题困扰了业界多年,导致神经网络的发展长期停滞不前。直到将ReLU函数作为激活函数,这些问题才得以解决,神经网络的发展迎来了新高潮。ReLU函数及其导数的图像,如图4-8所示。

图4-8
ReLU函数的公式如下。
a={█(0,如果d<0@d,如果d≥0)┤a={█(0,如果d<0@d,如果d≥0)┤
当 ≥ 时, ,反向传播不会造成梯度消失和梯度爆炸,且没有饱和区。当 时,梯度为0,本次传播中该神经元“死亡”——这是彻底的消失,也是饱和的形式之一。
在实际应用中,ReLU函数会出现“真死”和“假死”两种情况。
ReLU函数“真死”是指对任何输入恒有 ≤ ,此时神经网络将无法得到训练。其中, 为参数矩阵 的第 行, 为第 层神经网络的第 个节点, 为第 层的输出(即第 层的输入)。
在神经网络的中间层, 为上一层ReLU函数的输出,所以有 ≥ 。若 各元素均为非常大的负数,则恒有 。这种情况一般是参数初始化错误或过大的学习因子导致更新权重 过大造成的。因此,在将ReLU函数作为激活函数时,学习因子不宜过大, 的初始化也应遵循一定的准则。
ReLU函数“假死”是指恰巧造成 ,但下次输入不同的 时仍会激活
神经元。ReLU激活函数的神经元死亡问题,在绝大多数情况下都属于假死。适量的假死其实不是坏事,甚至能够提升神经网络的效果,原因如下。
若神经元都不会死亡,即对所有的输入恒有 ≥ ,ReLU函数就达不到非线性化,所有层之间的变换均为线性变换,深层网络将退化成一层网络。
假死的神经元可以理解成对某些输入不予输出,起到了特征选择的作用。
为了避免神经元大量死亡,同时具备非线性处理能力,ReLU函数的诸多变体出现了。其中,LReLU(Leaky-ReLU)函数的应用相对广泛,它的函数图像如图9-4所示。

图4-9
LReLU函数的公式如下。
a={█(kd,如果d<0 @d,如果d≥0)┤a={█(kd,如果d<0 @d,如果d≥0)┤
其中, 为超参数,取值一般在0和1之间。如果LReLU函数中的 是可学习的,那么它就进化成了PReLU函数。
上述激活函数的输入都是 ,输出都是 。各激活函数的不同之处在于 的形式不同。
不同于上述激活函数,Maxout函数的每个神经元都有一批对应的参数 ,因此,该激活函数的输入是多个值,具体如下。
dj((l))(1)=wj((l))(1)a((l−1))
dj((l))(n)=wj((l))(n)a((l−1))
其最终的输出为
aj((l+1))=max(dj((l))(1),⋯,dj((l))(n))
即每个可学习参数( ()(wj((l))(1) wj((l))(n)) )都与当前神经元的输入 a((l−1)) 相乘,然后取最大值。以 n=3 为例,如图4-10所示。

图4-10
Maxout函数的强大之处在于,在进行网络训练时,不仅会学习参数,还会自适应地改变激活函数的形状,起到探索激活函数的作用。
在实际的工程中,PReLU函数和Maxout函数的计算量都偏大,且都有超参数,因此使用最多的还是ReLU函数。
理论上,任何非线性函数都有可能成为激活函数,但在实际应用中,经常使用的也就是上述几种。一个非线性函数能够在实践中胜出,必然有其优点。笔者总结了常用激活函数的优点,列举如下。需要注意的是,并不是所有的激活函数都具备以下所有优点(大部分只具备其中几条),这些优点之间也存在相互冲突的情况。但是,只要优点足够突出,激活函数就有机会“胜出”。
零均值输出(激活函数为奇函数)。例如,Tanh函数在学习阶段,输出的均值是0(输出有正有负), 的各个维度的更新方向可以不同(有正有负),从而避免了单向更新(各个维度只能同增或同减)给学习带来的难度(例如,将 更新至 ,只能走Z字形路线)。
适当的非线性。正如前面所分析的,如果只进行线性变换,那么网络的层数将毫无意义。但是,激活函数的变化不宜过于激烈。如果激活函数的变化过于激烈,那么输入的轻微变化就会导致输出的剧烈变化(稳定性不好)。理想的情况是 。常用激活函数Sigmoid、Tanh、ReLU都有一个近似线性的区域能满足此性质。
导数不宜太小或太大,以免发生梯度消失和梯度爆炸。由于ReLU函数在这方面表现优异,所以它成为深度神经网络激活函数的首选。Sigmoid函数和Tanh函数都不可避免地存在梯度消失问题,在深层神经网络中使用它们时要慎重一些。
单调性。避免因导数忽正忽负而在学习过程中产生震荡。例如, 不适合作为激活函数使用。
输出范围受到限制。如果输出范围没有限制,那么经过层层激活,各层的输出就有可能被放大至一个很大的值,从而导致最后一层的Softmax函数饱和。例如, 不适合作为激活函数使用。
没有超参数。Sigmoid函数、Tanh函数、ReLU函数没有超参数,Maxout函数、PReLU函数有超参数。引入超参数会提高使用难度,而设置超参数本身依赖经验。
运算简单,速度快。在大型神经网络中,神经元动辄百万个,因此,运算速度是一个非常重要的指标。ReLU函数的运算速度具有碾压性的优势。
在逻辑回归、SVM等经典模型中,因为模型相对简单、参数数量较少,所以在多分类任务中常使用1 vs N-1法,通过训练 个二分类模型来完成多分类任务,或者使用1 vs 1法,通过训练 个分类器来完成多分类任务。但是,在深度学习中,模型参数数量较多、单个模型训练速度较慢,使训练多个模型显得不切实际。另一方面,因为多分类任务的前层特征变换的目标是一致的,所以可以使用同一套特征,没有必要训练多个模型。因此,我们使用softmax作为最后一层的激活函数,输出各个类别的概率。softmax输入为向量 ,输出为向量 ,即
y^'=[■(y_1^'@⋮@y_n^' )]=softmax(x)=1/(∑_(i=1)^n▒e^(x_i ) ) [■(e^(x_1 )@⋮@e^(x_n ) )]y^'=[■(y_1^'@⋮@y_n^' )]=softmax(x)=1/(∑_(i=1)^n▒e^(x_i ) ) [■(e^(x_1 )@⋮@e^(x_n ) )]
的作用就是进行概率归一化,确保 。softmax函数很少在神经网络的中间层中使用,一般都用作神经网络的最后一层,直接输出各个类别的概率。当多分类真实类别为 时, 为one-hot向量,有且仅有一个元素为1,其他都为0。最后一层的激活函数为softmax,输出为 。训练阶段的损失函数使用KL距离,即
Loss=∑_(j=1)^n▒〖-y_j logy_j^' 〗Loss=∑_(j=1)^n▒〖-y_j logy_j^' 〗
例如,真实类别为 k , yk=1 ,其他类别为 ( ()yk=0(j≠k) ), Loss=∑_(j=1)^n▒〖-y_j logy_j^' 〗Loss=∑_(j=1)^n▒〖-y_j logy_j^' 〗 可以写成

softmax函数是一种相对特殊的激活函数,仅用在多分类任务的输出层(中间层一般不使用softmax函数进行激活)。
值得注意的是,softmax函数会对概率进行归一化,使各类别的输出的概率之和为1,即 ,因此,它适用于类别互斥且概率之和为1的场景。例如,在文章情感分类
预测场景中,文章所表达的情感为“ ”,适合使用softmax函数。但是,预测学历的场景(例如“ ”)就不适合使用softmax函数,因为其中存在没有考虑到的情况(例如博士、大专以下),即各类别的概率之和不为1。对各类别的概率之和不为1的情况,可对场景略加改造,增加一个类别,例如将预测类别调整为“ ”,以满足softmax函数的要求。
在考勤打卡场景中,假设公司有10个人,在进行人脸识别时,有类别“ ”。这种场景也不适合使用softmax函数,因为“高管”和“老板”会与其他类别的人重复,即类别不互斥。在类别不互斥的情况下,例如判断音乐的类型(摇滚、流行、古典等)时,输出层可以使用Sigmoid函数作为激活函数,但
此时不能保证 。
4.5 常见损失函数及其导数
4.5.1 分类和回归
在有监督的机器学习中,目前常见的训练方法是,定义一套损失函数 ,损失函数用来量化模型输出 和客观事实 的差异性,差异性越大, 越大,反之亦然。模型训练就是通过梯度下降法,不停地改变模型参数,使 越来越小,缩小模型输出和客观事实的差异性。但是,正如我们前面所学,有多种类型的距离定义,它们都可以描述差异性,但不同的距离函数有不同的侧重点,因此就产生了多种损失函数选型。本节专门就常见的损失函数进行讲解,分析它们各自的应用场景。
首先出场的是均方误差,即MSE(Mean Square Error),MSE的值域为 ,因此也常用于作为回归任务的损失函数。MSE其实就是用来衡量输出值和真实值的欧氏距离。为了简便,我们在单个样本上分析问题,即
Loss_MSE (y,y^')=(y^'-y)^2Loss_MSE (y,y^')=(y^'-y)^2
对应的导数为
(∂Loss_MSE)/(∂y^' )=2(y^'-y)(∂Loss_MSE)/(∂y^' )=2(y^'-y)
可以发现,如果使用MSE作为损失函数,那么导数 和误差 成正比,误差越大,调整的力度就越大。
除了用于损失函数,MSE也用在L2正则上,度量待学习参数 和原点之间的距离:
LossL2=‖w‖
除了MSE,MAE(Mean Absolute Error)也可用于回归任务的损失函数,度量输出值和真实值的曼哈顿距离:

单纯从数学的角度看,MAE的导数是不连续的,为了工程上的可行,一般会设 。 的特点是并不会随着误差的变化而变化,始终为 或者 。
这是把双刃剑:好处在于当数据中存在离群噪声点时(误差非常大),MSE会被强烈影响,而MAE对此却并不敏感;坏处在于丧失了根据误差自动调节梯度的能力。
在线性回归中,如果训练样本中存在噪声或者随机性,即同样的输入 对应于多个不同的 ,那么MSE最终会让模型的输出为这诸多 的均值,而MAE则会让模型的输出为这诸多 的中位数。

|w1|+⋯+|wi−Δw|+⋯+|wn|=|w1|+⋯+|wj−Δw|+⋯+|wn|,i≠j
因此,在使用L1正则时,会将 中对任务帮助最小的 直接降为0,而在使用L2正则时, 越大,在它上面减小 会让最终L2减小越多。
当 减少 后,它就不再是最大的了,需要从其他 中挑选,继续减小。因此,使用L2正则的时候,诸多 最终都会趋于一致。
但是,在分类任务中,因为模型的输出是概率值,即 ,此时MSE和MAE就不太适用了,一般使用交叉熵作为损失函数,也称作KL距离。在单输出二分类场景中,KL距离如下。
需要注意的是,KL距离不满足对称性,即 。我们看一下对应的导数:
KL距离看上去相对复杂,但这只是表象。因为在大部分时候,二分类的最后一层都使用sigmoid函数,即
那么
为网络最后层的输出。
根据链式法则,可以得到
也具备非常简洁和明确的物理意义。
当进行 分类时,也同样使用KL距离,即
导数形式在4.4节中已经讲过,这里不再赘述。
在二分类中为什么不使用MSE作为损失函数呢?因为在二分类模型中,为了使得模型输出具有概率意义,最后一层一般都使用sigmoid函数作为激活函数,即
KL和MSE对应的梯度为
因为 ,所以 ,这就会让 变得非常小,甚至是在预测完全错误的情况下(预测完全错误,调整力度应该非常大)。例如,当真实类别为 时,预测结果 ,此时完全预测错误,因此希望 较大,但真实情况却是 ,反之亦然。
还有一个问题: 是关于 的三阶多项式,因此对应的函数曲线会更为复杂,也就是 曲面上会有更多的局部极小。这对梯度下降法的优化也是极为不利的。
KL距离是否是完美无瑕的呢?其实不是,KL距离也有一些自身的问题。例如,在逻辑回归中
如果 ,可以得到
将 扩大 倍,即可得到
那么 。所以,当 时,成倍放大 可以增大 。同理,当 时,成倍放大 可以减小 。
因此,当数据线性可分时(真实类别 时,对应的模型输出都有 。真实类别 时,对应的模型输出都有 ),对应的损失函数为
分别讨论两种情况。
当 时, , 。我们放大 ,从而增大 ,最终 减小。
当 时, , 。我们放大 ,从而减小 ,最终 减小。
因此,在训练过程中,在已经满足正确分类的情况下使用梯度下降法进行训练时,为了让损失函数 变小,仍然会不断的放大 。这就好比一个人已经吃饱了,还在不停地吃,不仅意义不大,还会引发肥胖。体现在机器学习中,无限放大 会导致过拟合。因此,在使用逻辑回归时一定要加上正则项,以防止 无限放大。
还可以通过一种思路来解决这个问题,就是hinge距离。hinge最早起源于支持向量机,后来在深度学习中也得到了广泛的应用。hinge函数的损失函数为
在hinge距离中,会对分类的标识进行改变,真实的类别对应的 或者 。模型的输出 ,当 时是 类,当 时是 类。
虽然使用hinge损失函数后,输出丧失了概率意义,但其优点仍很明显。例如,真实类
别为 ,当 时, ,训练目标减少 ,即增大 。
但是,当 被增大到 时, ,损失函数不再变化,防止 被无限
放大。真实类别 时也有同样的结论。
4.5.2 哈夫曼树和负采样
在机器学习的多分类任务中,一般会使用softmax函数作为分类,即
为前层神经网络的输出。
损失函数为
当预测的目标为 时,其他 , ,使用KL距离作为损失函数,公式如下。
但是这里有个问题:如果 非常大,那么计算 本身将耗时很长。例如,预测任务是中文词,常见的中文词约20万个,即 。显然,采用原始的softmax函数进行分类是不现实的。常用的改良方式是使用哈夫曼(Huffman)树和负采样。
哈夫曼树是一棵二叉树,每个词在树上的位置由它的词频决定,高频词在浅层,低频词在深层。根据词频构建哈夫曼树是一个非常成熟的算法,感兴趣的读者可以查阅相关资料。哈夫曼树如图4-11所示。

图4-11
哈夫曼树的输入 是一个 维向量。在哈夫曼树中,每个非叶子节点对应于一个逻辑回归(二分类), 对应于向上侧子树(右子树)走的概率, 对应于向下侧子树(左子树)走的概率。
在使用哈夫曼树进行指定词的概率预测时,从根节点出发,在每个节点计算向左走或向右走的概率。将这些通过计算得到的概率相乘,就能得到最终的预测概率。
例如,在预测“我”这个词时,对应的概率为
我│P(我│h)=1/(1+exp(−w1h))(1−1/(1+exp(−w2h)))
再如,在预测“内卷”这个相对少见的词时,对应的概率为
=(1−1/(1+exp(−w1h)))(1−1/(1+exp(−w3h)))1/(1+exp(−w5h))(1−1/(1+exp(−w7h)))
因为高频词位于树的浅层,所以预测时需要游走的非叶子节点较少,对应的运算量较小,同时,因为概率项的乘积较小,所以最终的预测概率较大;低频词位于树的深层,对应的计算量较大,最终的预测概率较小。
在训练阶段,当目标词为“我”时,将 作为损失函数,最大化 等价于最小化 ,即
我│Loss=−logP(我│h)=−log(1/(1+exp(−w1h)))−log(1−1/(1+exp(−w2h)))
相应的梯度为

可以看出,在训练时只会更新对应的参数 和 。

4.5.3 度量学习
在机器学习中,除了常见的分类和回归任务外,还有一类问题是度量学习。
在度量学习中,每个样本并没有一个明确的分类或者回归目标。它是通过使用模型将输入特征转换成向量的,训练的目标是使相似数据的向量更为接近,使不相似的数据对应的向量彼此距离较大,整体结构如图4-12所示。
损失函数就是用来度量两个向量之间的距离的,相似的数据,输出向量很近,反之亦然。因此,我们对于模型输出的两个向量 和 定义相似度为 距离,即
在学习的过程中,是希望相似的向量 和 对应的 尽可能大,而不相似向
量之间的 尽可能小。这里说明一下分母 和 的重要性, 和 本质
上就是把向量约束在一个球面上进行比较,如图4-13所示。如果没有分母进行归一化,那
么模型可能会通过增长(缩短)向量的幅值 和 来无限的增加(减少)相似度,此
时模型并没有学到真正的知识。例如, 和 的相似度很高,而 和它们之间的相似度都很低,如果模型没有分母归一化,就有可能学出如图4-14所示的情况。

图4-12
图4-13
图4-14
度量学习出来的特征有时候会提供给后续的分类器进行分类,上述情况产生的向量是线性不可分的,增加了后续分类的难度。
我们定义好相似度 后,相似样本对为正样本,即 、 这些样本对一般都是通过人工标注或者其他方法收集而来。我们另外再选取一些不相似的样本对 和 ,用它们构建一些负样本,记为集合 。一般来说,负样本都是通过随机抽取样本对进行组建。损失函数有如下定义。
▒Loss=−log(e(S(zi,zj)/τ)/(∑(k∈K)▒e(S(zi,zk)/τ)))
上述损失函数被称为InfoNceLoss。可以看出,它的形式和softmax函数非常相像。对于分子来说, 越大,Loss越小,也就是相似样本的向量cosine距离越小。在分母一侧,损失函数鼓励不相似的向量 相互疏远。 是温度参数,会对学习最终的效果产生影响,例如
▒∂Loss/(∂zi)=∂Loss/∂S(zi,zk)∂S(zi,zk)/(∂zi)=1/(τ∑(k∈K)▒e(S(zi,zk)/τ))e(S(zi,zk)/τ)∂S(zi,zk)/(∂zi)∝e(S(zi,zk)/τ)
可以看出,温度超参 越小,会赋予更多的排斥力,将它从 推远,提高学习效率。但是, 并不是越小越好,因为在很多场景下,正样本非常难收集,标注成本非常之高,而其负样本都是随机采集,这里面很有可能掺杂了正样本。如果 过小,就会把潜在的正样本推的更远(本身是正样本,但是没有标注出来,随机采样的时候,被误认为负样本),从而模型的泛化能力变差。
那么,一个不错的度量学习应该达到什么样的标准呢?一般来说,度量学习具备两个属性Alignment和Uniformity,具体含义如下。
Alignment指的是相似的例子,也就是正例,映射到单位超球面后,应该有接近的特征,也就是说,在超球面上距离比较近。
Uniformity指的是系统应该倾向在特征里保留尽可能多的信息,这等价于使映射到单位超球面的特征尽可能均匀地分布在球面上,分布得越均匀,意味着数据之间相互有差异,即它们各自保有独有信息,整体保留的信息越充分。
Uniformity特性的极端反例,是所有数据映射到单位超球面同一个点上,这极度违背了Uniformity原则,因为这代表所有数据的信息都被丢掉了,体现为数据极度不均匀得分。
4.6 积分和求和
4.6.1 积分和不定积分

我们现在对这个数列求和,即 。
如果我们想对一个函数 在一个区间上的所有值进行求和,又应该如何表达,对应的物理意义是什么呢?例如,我们想计算 在区间 上所有函数值之和,其实就是计算如图4-15所示阴影部分的面积。
图4-15
对连续函数 在区间 上求和,写为
上式称作 在区间 上的定积分。
定积分其实就是连续函数的求和。因此,上述阴影部分的面积可以写为
求定积分其实和求导数是一对互逆的计算。如果有函数 ,它的导数满足
那么
不过,需要注意的是,对于 , 并不是唯一的。例如,当 时,有
可以为任意常数。
我们在求解 时,首先找到对应的 ,然后计算
常数 可以相互抵消,因此对最终结果没有影响。
也可以记为 ,此种类型的积分称为不定积分。相比于定积分求出来的结果是一个面积,不定积分求的结果为一个函数。
但是,通过找到 来计算 并不是一个放之四海而皆准的方法,因为对于
有些函数,例如 )、 、 、 、 ,是无法找到对应的 的。这时上述方法失效,这类函数称为不可积函数。但是,上述函数对应的阴影面积是客观存在的,
因此只能用一些特殊的数值方法求解,例如 可以使用二重积分和极限夹逼
定理求得,这里不再赘述,感兴趣的读者可以自行查阅相关资料。
我们一般把 中的 称为积分的上限, 称为积分的下限,但是并不要求 。它们之间满足关系
不过,值得注意的是,面积只对区域有意义,对于单点求积分,它对应的是区域是一根直线,面积为0,即
也可以将一个定积分分解成两部分,即
为 定义域上的任意实数。
虽然积分从面积的概念导出,但是定积分结果也可以为负数,即把 轴下方区域的面积认为是负数,例如 就是计算如图4-16所示阴影部分的面积。
图4-16
因为阴影部分面积都在 轴之下,所以
例如,对于积分 ,所求面积如图4-17所示。

图4-17
可以发现:当区间为 时, ;当区间为 时, 。而且,这两个区间段和 轴之间的面积相等,只不过一个在 轴上方,一个在 轴下方,积分结果刚好相反。因此,很容易得到
4.6.2 多重积分
当 为多元函数时,仍然有对应的定积分,例如
我们要求在区间 、 内所有函数值的和,即求下面空间的体积,如图4-18所示。

图4-18
可以记为
此时,称为二重定积分。
二重积分的解法和定积分基本一样,首先求解 ,把 当作常数,有
那么
因此
二重积分也满足交换律,即
即对多元变量的积分顺序不会影响最终结果。
同理,我们可以对三元函数、四元函数等进行积分。这里统称为多重积分,思路和方法同二重积分类似,不再赘述。
4.6.3 分类模型的效果指标AUC
在二分类模型中,我们把两类记为P类和N类。有很多指标可以进行模型评测,例如准确率、召回率、正确率等。但是,这些指标需要模型输出明确的类别,而模型一般会输出一个分数(概率) ,用来表示模型为P类的概率,然后设定一个阈值 。如果 ,则认为是P类;如果 ,则认为是N类。
这样处理会有一个问题:不同的 会导致准确率和召回率的变化。例如, 的值设置得很大,即判断为P类的条件严格,那么P类的准确率会提升,而召回率会降低。可见,准确率和召回率并不是客观指标,它们依赖于使用者主观设置的 。那么,我们能否找到一个指标,客观反映模型的能力呢?
例如,有 个正样本, 个负样本,模型对它们的打分如下。
正样本: 。
负样本: 。
负样本得分按倒序排列,即 。
首先,取阈值 ,此时所有正样本的得分都会小于1,即0% 的正样本和负样本高于 ,记为坐标 。其中,第一个元素表示负样本中高于阈值的比例,第二个元素表示正样本中高于阈值的比例。接着,取阈值 ,此时有一个负样本的得分不小于 被判断为P类,即占比为 (预测错误),正样本不小于 的数量记为 (预测正确),结果记为 。依此类推,阈值 分别取 ,可以得到 。因为 依次减小,阈值不断降低,所以,被模型判断为P类的样本越来越多, 依次增大。最后,当 时,因为所有正负样本的得分都大于0,所以对应的结果为 。我们一共得到了 个坐标点。将这 个坐标点转换成曲线,如图4-19所示。

图4-19
这条曲线就称为ROC曲线。横坐标表示表示负样本被判断为正样本的比例,记做FP,即假阳率。纵坐标即正样本被判断为正样本的比例,记做TP,即真阳率。那么,这条曲线有什么意义呢?假设我们取两个紧挨着的坐标点 和 ,它们围成的面积为 ,如图4-20所示。

图4-20
图4-20阴影部分面积表示占比 的正样本的得分高于 。因此,ROC曲线下的面积都可以拆解成 个小块,分别表示
占比 的正样本的得分高于
占比 的正样本的得分高于
……
占比 的正样本的得分高于
它们对应的面积,如图4-21所示。

图4-21
图4-21阴影部分面积之和为
▒〖▒〗S=∑(i=1)N▒〖(mi/M×1/N)=(∑(i=1)N▒mi)/(M×N)〗
的分母部分 表示将 个正样本和 个负样本一一比较的次数,在分子部分
表示正样本中得分大于 的数量。因此, 表示正负样本一一比较时,正样本
得分大于负样本的总次数,面积 记为AUC(Aera Under Curve),用来表示模型对正负样本打分的区分能力。
假设一共有100个正样本和100个负样本,正负样本之间可以做100×100次比较。正样本的得分高于负样本,记为1分;正负样本得分相等,记为0.5分;负样本得分高于正样本,记为0分。假设这200个样本进行相互比较,有8000次正样本的得分高于负样本,100次正负样本得分相同,那么AUC为
需要注意的是,得分比较仅在正负样本之间进行,而正样本和负样本内部均不做得分比较。可以看出,AUC关心的只有正负样本之间的分数相对高低,而具体的分值则无关紧要。根据AUC的物理意义,易得 。当 时,意味着所用正样本的得分大于任意负样本,此时分类器效果最佳。
那么AUC最小值是什么呢?如果分类器为随机猜测,即对样本随机打分,那么正负样本两两比较时,正样本有50% 的概率得分高于负样本,此时 。AUC有没有可能小于0.5呢?如果AUC小于0.5,则意味着在大多数的比较中正样本的得分比负样本低,如果此时进行取反,即原有得分为 ,取反为 ,就能保证正样本得分高于负样本的占比较大,即AUC大于0.5。因此,AUC小于0.5理论上可能发生,但实际上不可能发生。综上所述,一般认为 。
如果当正负样本数量足够,那么如图4-21所示的阶梯状图形就会趋近于一条平滑的曲线,如图4-22所示。

图4-22
此时,ROC曲线记为 ,求面积就变成
▒〖〗AUC=∫01▒〖f(x)dx〗
AUC的计算过程就是比较正负样本的得分,和所取阈值无关,因此是一个客观的衡量指标。因为AUC是一个比例值,所以,即使正负样本数量差异较大,也不会对它造成影响。在二分类任务中,AUC值更能表现出模型的本质特征。
第5章 概率的基本概念
5.1 概率入门
概率是一门古老的学科,如果溯源,一般认为其来源于赌博,但是随后其发展出了一套体系理论并拓展到科学和工程的方方面面。特别是在机器学习领域中,概率和统计学可以说奠定了一整套理论基础。概率和统计学本身涉及的知识面非常之广,本书仅围绕机器学习方面的知识展开讨论。
概率是用来度量事情发生的可能性的,通常用 P 表示。概率是续型变量,值域一般定义为 [0,1]。如果一个事情必然发生,那么该事件被称为必然事件。例如,“太阳从东方升起”就是必然事件,我们把它记为 y1,那么对应的概率为 P(y1)=1。如果一个事件绝对不可能发生,那么该事件被称为不可能事件。例如,事件“太阳从西方升起”就是不可能事件,我们把它记为 y2,那么对应的概率为 P(y2)=0。一个事件的发生与否,如果具有一定的不确定性,那么该事件被称为随机事件,对应的概率介于0和1。例如,我们把“明天下雨”记为 y3,如果对应的概率为 P(y3)=0.9,就表示明天下雨的可能性较大,但不代表一定会下雨。
假设我们扔一枚硬币,y=1 表示结果为正面,y=0 表示结果为反面。如果硬币是均质的,那么 P(y=1)=0.5,P(y=0)=0.5,即表示一次投掷两种结果的占比。
概率是怎么算出来的呢?概率和频率的关系也比较密切,除了理论上的推导,最直接的方法就是统计已发生事情的频率。例如,一共投掷硬币100次,其中正面朝上51,反面朝上49次,我们使用频率作为概率的估计,即
P(y=1)=51/100
P(y=0)=49/100
使用频率估计概率是一个相对粗糙但有效的方法,其实就是对已有经验进行总结,前提是实验次数一定要足够多,这样估计的结果才准确。这其实也是机器学习中训练数据要足够大的原因——原则上多多益善。举个反例,如果只投1次硬币,那么必然出现一个面朝上的概率为1,另一个面朝上的概率为0的情况,而这显然是不准确的。
再举个例子。我们掷骰子,投掷结果 y 就是一个典型的随机事件,并且结果是多中选一的。骰子的每一面出现的概率都相等,即
P(y=1)=P(y=2)=P(y=3)=P(y=4)=P(y=5)=P(y=6)
且结果必然是6个面中间的一个,因此,所有面出现的概率相加必然为1,即
P(y=1)+P(y=2)+P(y=3)+P(y=4)+P(y=5)+P(y=6)=1
因此,很容易得到
P(y=1)=P(y=2)=P(y=3)=P(y=4)=P(y=5)=P(y=6)=1/6
需要注意的是,y=1,⋯,6 只表示状态,代表结果 y 为点数,骰子各个面并无大小之分。
通过上面的分析可以知道,虽然不同的随机事件具有不同的特点和使用场景,但是它们有一定的共性,具体如下。
值域固定,即 P(y)∈[0,1]。
有限可加性。如果 n 个事件 y1,y2,y3,⋯,yn 中的任意两个都互斥,即不可能同时发生(例如,每次掷骰子时6个面只会有一个朝上),那么 P(y1∪⋯∪yn)=P(y1)+⋯+P(yn)。y1∪⋯∪yn 表示事件 y1~yn 中至少有一个发生。
概率之和为1。如果对于事件 y,穷举它所可能发生的事件 y1,y2,y3,⋯,yn,并且任意两个事件都不可能同时发生,那么有 P(y1)+⋯+P(yn)=1。
事件的包含性。例如,事件A为掷骰子结果为偶数,事件B为掷骰子结果为2,那么只要事件B发生,事件A就一定发生。对这种情况,我们称事件A包含事件B,此时有 P(事件B)<P(事件A)。
对于任意两个事件 A 和 B,P(A∪B)=P(A)+P(B)-P(A∩B),A∪B 表示 A 和 B 至少发生一个,A∩B 表示 A 和 B 同时发生。例如,A 表示掷骰子结果为偶数,对应的投掷结果为 {2,4,6},P(A)=1/2,B 表示掷骰子结果大于(不包括)3,对应的投掷结果为 {4,5,6},P(B)=1/2,那么 A∪B 表示投掷结果为 {2,4,5,6} 中的任意一个,因此,P(A∪B)=4/6。A∩B 表示投掷结果同时满足两个事件,即 {4,6},因此 P(A∩B)=2/6。我们可以发现,P(A) 和 P(B) 都考虑了结果 {4,6},直接计算 P(A)+P(B) 会重复计算 {4,6} 一次,因此,还需减去重复的部分 P(A∩B)。验算一下,易得
P(A∪B)=4/6
P(A)+P(B)-P(A∩B)=3/6+3/6-2/6=4/6
特别的,当 A∩B=∅,即 A 和 B 为互斥事件,不可能同时发生时,P(A∩B)=0,可以得到
P(A∪B)=P(A)+P(B)
此为有限可加性。
5.2 联合概率和条件概率
我们生活在这个世界上,每天都会发生形形色色的事件,这些事件往往不是孤立存在的,它们之间往往具有联系和相关性,它们之间的发生和结果往往互相影响。
小明是个小学生,每天有下面两组随机事件发生在他身上。
y1={█(1,妈妈批评小明@ 0,妈妈没有批评小明)┤
y2={█( 1,小明考试不及格@ 0,小明考试及格) ┤
我们统计小明最近100天的表现情况,如表5-1所示。表5-1
| y2=1 | y2=0 | |
| y1=1 | 27 | 13 |
| y1=0 | 3 | 57 |
表5-1
可以发现,在这100天中,小明一共有27+13=40天被妈妈批评,剩下60天没有被妈妈批评。我们用频率来估计概率,可以得到
P(y1=1)=40/100=0.4
同理,P(y2=1)=0.3,P(y2=0)=0.7。
上面的概率都是对单个事件进行描述。有时候,我们需要对两个事件的组合概率进行描述。例如,小明考试不及格(y2=1)且没有被妈妈批评(y1=0)的概率,根据统计可得
P(y1=0,y2=1)=3/100
假设小明考试不及格,即 y2=1 已经发生,我们想知道小明会被妈妈批评的概率,又该如何计算呢?用 P(y1|y2) 表示 y2 发生后 y1 会发生的概率,称为条件概率。例如,在 N 天中,小明一共有 n 次考试不及格,考试不及格时被妈妈批评了 m 次,可以通过统计计算条件概率,即
P(y1=1│y2=1)=m/n=(m/N)/(n/N)=(P(y1=1,y2=1))/(P(y2=1))
上式反映了条件概率和联合概率之间的联系。更一般的写法为
P(y1│y2)=(P(y1,y2))/(P(y2))
根据表5-1,我们可以得到
P(y1=1,y2=1)=27/100
P(y2=1)=30/100
因此
P(y1=1│y2=1)=(P(y1=1,y2=1))/(P(y2=1))=(27/100)/(30/100)=0.9
同理,如果小明考试及格,那么他被妈妈批评的概率为
P(y1=1│y2=0)=(P(y1=1,y2=0))/(P(y2=0))=(13/100)/(70/100)=0.19
如果我们不知道考试结果,那么小明被妈妈批评的概率为 P(y1=1)=0.4。可以发现,如果小明考试不及格,即 y2=1,那么他被妈妈批评的概率将显著提升至 0.9。如果小明考试考试及格,即 y2=0,那么他被妈妈批评的概率就会下降至 0.19。因此,考试结果 y2 给我们提供了额外的信息,提升了判断的准确性。在机器学习中,也把条件概率中的条件称为知识。
我们也可以把单个概率写成条件概率之和的形式。例如,y2 只有两种取值情况 y2=0 和 y2=1,那么有
P(y1=1)=P(y2=0)P(y1=1│y2=0)+P(y2=1)P(y1=1│y2=1)
即各个条件概率加权求和,权重为 P(y2=0) 和 P(y2=1)。写得更通用些:
P(y1)=∑_(y2∈Y2)▒〖P(y2)P(y1│y2) 〗
Y2 为 y2 所有可能取值的集合。
特别的,如果 y1 和 y2 相互独立,即这两个随机变量风马牛不相及,那么满足
P(y1,y2)=P(x1)P(x2)
例如,我们投掷两个独立的骰子,第一个骰子为3点、第二个骰子为5点的概率是多少呢?显然,两个独立事件同时发生的概率为两个事件单独发生的概率相乘,即
P(y1=3,y2=5)=P(y1=3)P(y2=5)=1/6×1/6=1/36
再如,y1 和 y2 分别表示一个人的身高和体重,那么
P(y1=175cm,y2=60kg)≠P(y1=175cm)P(y2=60kg)
这是因为一个人的身高和体重具有很强的相关性,当知道一个人的身高后,体重也八九不离十,此时 y1 和 y2 称作不独立。
显然,在上述小明的例子中,妈妈批评小明和小明考试不及格之间存在相互影响,因此 P(y1,y2)≠P(y1)P(y2)。
如果从一个分布中独立抽取 n 个样本,那么这 n 个样本是相互独立的,即
P(y1,y2,⋯,yn)=P(y1)P(y2)⋯P(yn)
例如,随机扔硬币 n 次,虽然扔的是同一个硬币,但是前后结果互相不影响,所以这 n 个结果相互独立。再如,从一个班的学生中“有回放”地随机抽取 n 个人,他们的身高就是随机变量,并且相互独立。所谓“有回放”就是指抽取第一个人后,将他放回班级,下次抽取的时候仍然有同样概率抽取到他。
如果做无回放抽取,即抽取完第一个人后,不把他再放回班级,第二次抽取的时候班级的人数就会由 N 人变成 N-1 人,第二次抽取的概率分布被第一次抽取的结果影响,发生了变化,因此,两次抽取出来的身高就不再是独立的,即
P(y1,y2)≠P(y1)P(y2)
如果要求每次抽取的人性别和上一次不相同,那么前后两次抽取出来的身高也不再是独立事件。
当两个随机变量 y1 和 y2 相互独立时,条件概率有如下结论。
P(y1│y2)=(P(y1,y2))/(P(y2))=(P(y1)P(y2))/(P(y2))=P(y1)
y2 对 y1 发生的概率不会造成任何影响,即 y2 无法为 y1 提供知识。这也相当于投掷两枚独立硬币,第一枚硬币的投掷结果不会对第二枚硬币的投掷结果造成任何影响。
5.3 贝叶斯定理
隔壁邻居听到小明被妈妈批评(y1=1 已经发生),心想小明是不是考试又不及格了(y1=1 已经发生,y2 的概率),那么此时邻居需要计算的条件概率就是
P(y2=1│y1=1)
根据5.2节的公式,我们可以进行如下推导。
P(y2│y1)=(P(y1,y2))/(P(y1))=(P(y1,y2)P(y2))/(P(y1)P(y2))=P(y2)(P(y1│y2))/(P(y1))
上述公式称作贝叶斯定理,它贯穿了机器学习。贝叶斯定理有时也写成如下形式。
P(y2│y1)=(P(y2)P(y1│y2))/(∑_(y2∈Y2)▒〖P(y2)P(y1│y2) 〗)
使用贝叶斯定理,我们可以得到
P(y2=1│y1=1)=P(y2=1) (P(y1=1│y2=1))/P(y1=1) =0.3×0.9/0.4=0.675
我们如何理解贝叶斯定理 P(y2│y1)=P(y2)(P(y1│y2))/(P(y1)) 呢?
我们需要计算的 P(y2│y1) 被称作后验概率,即 y1 发生后 y2 的概率。y1 被称作知识,P(y2) 被称作先验概率,表示在没有任何知识的帮助下 y2 发生的概率。P(y1│y2) 被称作似然函数,它其实表示了 y2 对 y1 的影响。P(y1) 被称作证据因子,如果 y1 本身是低概率事件,那么 y1 一旦发生,对 y2 的影响就会非常大,反之亦然。
在机器学习中,其实就是使用模型判断特征 x 对应的类别 y,即让模型拟合
P(y│x)
机器学习中,通常使用高维特征,因此 x 也被称为特征向量。机器学习的训练就是指利用训练数据 〖{x_((i)),y_((i))}〗_(i=1)^N,使用模型来直接估计 P(y│x)。这种机器学习的方法称为“判别模型”。另一种机器学习方法,模型学习的是 P(x,y),这种方法称为“生成模型”。判别模型和生成模型是机器学习的主要两个流派,考虑到落地难度和最终效果,判别模型的使用相对较多,生成模型也有适用的地方。下面通过一个例子说明二者的异同。
例如,x=175 为人的身高,y=0 表示女性,y=1 表示男性。已知身高,我们想根据身高预测性别,判别模型和生成模型分别是如何计算的?
判别模型可以得到此人为男性的概率 P(y=1|x=175)=0.9,那么,此人为女性的概率就是 P(y=0|x=175)=1-P(y=1|x=175)=0.1。因为 P(y=1│x=175)>P(y=0|x=175),所以模型结论是此人为男性。
在生成模型中,首先计算 P(y=1,x=175)=0.01,表示男性且身高为175cm的人占总人口比例的1%,接着计算 P(y=0,x=175)=0.001,表示女性且身高175cm的人占总人口的比例为0.1%。因为 P(y=1,x=175)>P(y=0,x=175),所以模型判断此人为男性。这里需要注意的是,P(y=1,x=175)+P(y=0,x=175)≠1,原因在于还有很多其他的身高和性别组合并没有被考虑进去,这正是判别模型和生成模型的差别。
判别模型和生成模型各有何优缺点呢?
使用模型估计 P(x,y) 比估计 P(y│x) 更加复杂,模型需要更多的参数及训练样本,因此,常见的模型,例如逻辑回归、神经网络,本质都是判别模型。但是,我们可以通过生成模型生成(采样)一系列符合真实情况的数据,例如男性180cm、女性160cm等,而判别模型只能根据身高来判断性别,缺乏生成数据的能力。
另外,例如 x=300 表示一个人的身高为300cm,这其实是个异常数据,该人为男性或者女性的概率都会很低。如果使用判别模型,因为有 P(y=1|x=300)+P(y=0|x=300)=1 的约束,所以 P(y=1|x=300) 或 P(y=0|x=300) 至少有一个不会太小,不存在二者都趋近于0的情况(这与真实情况矛盾),而判别模型必须二选一,因此会给出错误的结论。但在使用生成模型时,P(y=0,x=175)=10^(-9) 和 P(y=1,x=175)=〖2×10〗^(-9) 是可以存在的,符合真实情况。当在两类概率都超低的情况下,生成模型可以给出数据异常的结论。
5.4 连续概率分布
我们在扔骰子时,最终的结果 X 是一个离散变量,也就是说,X 是可以进行穷举的。例如,掷一个六面骰子,有 P(X=1)=1/6,P(X=2)=1/6 等。但是,在很多情况下,X 是不可穷举的,例如人的身高就是不可穷举的随机变量,无法数完所有情况,这类随机变量称作连续型随机变量。
因为 X 的状态是不可穷举的,所以 P(X) 是无法枚举的,我们需要换一种方式来定义概率。我们用一个非负可积的函数 f(x) 表示 X 的概率密度,它和概率成正比(类似于密度和重量之间的关系),f(x) 称作概率分布密度函数,简称概率密度。f(x) 表示在随机变量 X 在 x 附近的可能性,“可能性”不会为负值,因此 f(x)≥0。另外,因为 X 在 (-∞,+∞) 上所有的可能性相加必为1,所以可得
∫_(-∞)^(+∞)▒f(x)dx=1
例如,男性身高就是一个典型的正态分布,对应的概率密度函数为 f(x)=1/(15√2π) exp(-(x-160)^2/450)。
使用概率分布计算概率时,计算的是区间的概率,而不是某一个点的概率。这就好比我们称重量,一定要有体积的支撑才谈得上重量。例如,水这种物质只有密度,并不存在重量,我们所说的水重量,都是有一桶、一甁这种体积概念作为支撑的。再如,我们要判断一个人身高在区间 (170,175] 的概率,可以把170~175上的所有可能性相加,即
P(170<X≤175)=∫_170^175▒f(x)dx=∫_(-∞)^175▒f(x)dx-∫_(-∞)^170▒f(x)dx=F(175)-F(170)
这里我们把 F(a) 称作累计分布函数,F(a) 即表示 P(x<a)。
概率密度函数 f(x) 有一点“反常理”,在这里详细讲解一下,以便读者深入理解。
首先介绍一下均匀分布。均匀分布也叫矩形分布,是一个常见的连续概率分布,它在相同长度间隔的分布概率是相等的,定义如下。
f(x)={█(1/(b-a),a<x<b@0,其他 )┤
均匀分布通常缩写为 U(a,b),a 和 b 是均匀分布的两个参数。如果 b-a<1,那么 f(x)=1/(b-a)>1。因此,概率密度和概率不能混为一谈,概率不能大于1,而概率密度可以大于1。
另一个“反常理”的现象是,在连续概率分布中,任意一点 x0 发生的概率 P(x=x0) 为
P(x=x0)=∫_x0^x0▒f(x)dx=0
但是,从概率密度 f(x) 上采样,每次采样的结果必然是定义域中的某一个点。因此,可以说明一个事情发生的概率即使为0也未必是不可能事件。
同理,可以得到 P(x≠x0)=1-P(x=x0)=1-0=1,但事件 x=x0 完全有可能发生,即 x≠x0 没有发生。因此,概率为1的事件不一定是必然事件。
多个连续型随机变量也可以组成联合分布。例如,连续型随机变量 X 和 Y 组成的联合分布为 f(x,y),f(x,y)=1/√2π exp(-1/2 x^2-1/2 y^2) 且满足
∫_(-∞)^(+∞)▒∫_(-∞)^(+∞)▒f(x,y)dxdy=1
我们也可以从联合概率分布 f(x,y) 中得到单变量 x 对应的概率密度 f(x),其实就是把另一个变量 y 所有可能性对应的概率密度求和,这叫作边缘分布。例如,边缘分布 f(x) 为
f(x)=∫_(-∞)^(+∞)▒f(x,y)dy
即将 y 的取值都考虑在内。
同理,有
f(y)=∫_(-∞)^(+∞)▒f(x,y)dx
下面我们讨论连续型随机变量的一些性质。这些性质基本和离散型概率类似,只是大部分都是以概率密度替代概率。连续型随机变量 X 和 Y 之间的条件概率有如下关系。
f(x|y)=(f(x,y))/(f(y))
类似的,单变量概率也可以通过条件概率来进行表示,即
f(x)=∫_(-∞)^(+∞)▒〖f(y)f(x|y)dy〗
如果连续型随机变量 X 和 Y 相互独立,那么它们之间的概率密度满足
f(x,y)=f(x)f(y)
连续概率分布之间可以组成联合概率分布,连续概率分布和离散分布也可以组成联合概率分布。这些组合对应的贝叶斯定理如表5-2所示。

表5-2
可以发现,对于连续型随机变量,统一都用概率密度代替概率。
5.5 均值和方差
如果你是一个家长,在给孩子挑选学校时,可能会看重学校的平均考试成绩,它代表了学校的整体教学水平。如果这个数据没有公开,你有什么办法去了解呢?你可以站在校门口,随机挑选 N 个走出校门的学生,询问他们的考试成绩。
假设被询问的学生的考试分数分别为 x_1~x_N,那么平均分就是
X ̅=1/N ∑_(i=1)^N▒x_i
平均数也称为均值。
但是,均值 X ̅ 和我们的采样有关,如果我们刚好全部采样到低分同学,那么 X ̅ 就会整体偏小,反之亦然。因此,X ̅ 本身也是一个随机变量。
假设我们站在“上帝视角”,掌握了学校所有学生的考试分数,考试分数是 0~750 的整数。考试分数为离散随机变量 X,X 的取值就是 0~750 的整数,P(0),⋯,P(750) 为对应的概率,P(x) 表示一个学生分数为 x 的概率,也可以理解成分数为 x 的人数占学校学生数的比例。因为校长掌握了全部信息,并不存在随机抽取,所以校长计算出来的均值就是一个确定的值,我们称之为“期望”,记为 E(X)。
E(X)=∑_(score=0)^750▒〖score×P(x=score)〗
这里的期望 E(X) 是一个确定性的数,不再是随机变量。有时为了简便也用 μ 表示期望。
如果家长站在校门口的时间足够长,询问的学生人数足够多,那么他掌握的资料就很接近“真相”,因此 X ̅ 就越接近 E(X)。
但是,仅仅知道均值有时候不能完全反映真实的情况。例如,一个学校的学生考试分数有可能差距极大,也可能差距不大,在这两种情况下,它们的期望(均值)也有可能相等。因此,期望(均值)也不一定能完全反映一个群体的真实情况。
如果学生的考试分数都远离均值,那么该校学生考试分数的差异较大;如果学生的考试分数都接近均值,那么该校学生考试分数的差异较小。作为家长,随机问询 N 个学生的成绩,使用“样本标准差”s 度量一个学校学生的整体差异
s=√(1/(N-1) ∑_(i=1)^N▒(x_i-X ̅ )^2 )
因为 s 和随机询问的 x_i 有关,所以 s 也是一个随机变量。这里需要注意,分母是 N-1 而不是 N,这主要是为了消除采样时的系统性偏差。
但是,校长掌握所有学生的情况,因此他得到的标准差记为
σ=√(∑_(score=0)^750▒〖P(x=score)〖(score-E(X))〗^2 〗)
一般来说,σ^2 叫作方差,记为 D(X)。标准差和方差是一个确定性事件。
同一个统计量有对应样本和总体两个版本,如表5-3所示。

表5-3
上面都是在随机变量 X 为离散分布时进行分析的。但如果随机变量 X 是连续型随机变量,概率密度为 f(x),计算方式又该如何呢?
如果在采样样本上计算均值和标准差,虽然 X 为连续型随机变量,但是采样后都是一个个具体的数值,因此,仍然使用上述方法计算均值和样本标准差。对于期望和标准差的计算方法如下。
E(X)=∫_(-∞)^(-∞)▒〖xf(x)〗 dx
D(X)=∫_(-∞)^(-∞)▒〖〖(x-E(X))〗^2 f(x)〗 dx
其实很简单,就是把 ∑ 替换成了 ∫,把概率 P 替换成了概率密度函数 f(x)。
期望有一些常见的数学性质,列举如下。
E(C)=C,即常数的期望仍然为它本身。
E(aX)=aE(X),a 为常数。
E(aX+bY)=aE(X)+bE(Y)。
若 X 和 Y 相互独立,则 E(XY)=E(X)E(Y)。
方差的一些常见数学性质,列举如下。
D(X)≥0,若 C 是常数,则 D(C)=0。
D(aX)=a^2 D(X)。
D(aX+bY)=a^2 D(X)+b^2 D(Y)+2abE{(X-E(X))E(Y-E(Y))}。
如果 X 和 Y 相互独立,则 D(aX+bY)=a^2 D(X)+b^2 D(Y)。
D(X+b)=D(X),其中 b 是常数。
D(X)=E(X^2)-E^2 (X)。
期望和方差的这些数学性质都可以从定义中推导出来,这里不再赘述。
均值 X ̅ 本身也是随机变量,它对应的均值和方差又是多少呢?如果 X 对应的期望为 μ,方差为 σ^2,x_1,⋯,x_N 都是独立采样的,它们之间相互独立,那么均值 X ̅ 对应的期望和方差分别为
E(X ̅ )=E(1/N ∑_(i=1)^N▒x_i )=1/N E(∑_(i=1)^N▒x_i )=1/N ∑_(i=1)^N▒〖〖E(x〗_i)=1/N ∑_(i=1)^N▒〖μ=μ〗〗
可以发现,X ̅ 是 μ 的无偏估计,即估计量在统计学上没有偏差。
另外,因为 x_i 之间相互独立,所以 D(∑_(i=1)^N▒x_i )=∑_(i=1)^N▒〖〖D(x〗_i)〗。利用这个性质,可以推出
D(X ̅ )=D(1/N ∑_(i=1)^N▒x_i )=1/N^2 D(∑_(i=1)^N▒x_i )=1/N^2 ∑_(i=1)^N▒〖〖D(x〗_i)=1/N^2 ∑_(i=1)^N▒〖σ^2=σ^2/N〗〗
这说明:尽管 X ̅ 是 μ 的无偏估计,但是每次采样出来的 X ̅ 是在 μ 周围左右摇摆的,只是摇摆的中心为 μ 而已。D(X ̅ ) 表示摇摆力度,这就好比荡秋千,虽然中心不变,但是震荡幅度
是不同的。D(X ̅ )=σ^2/N 也说明,N 越大,D(X ̅ ) 越小,也就是每次采样出来的 X ̅ 偏离 μ 的幅度越小。
在神经网络的训练过程中,训练集一共有 M 个样本,w 为待更新的参数,每个样本对
应的梯度为 g_((i))=(∂Loss_((i)))/∂w。考虑所有训练样本,平均梯度为 ∂Loss/∂w=1/M ∑_(i=1)^M▒(∂Loss_((i)))/∂w=1/M ∑_(i=1)^M▒g_((i)) ,梯度下降法通过如下公式进行参数更新。
w=w-μ ∂Loss/∂w
但是,在实际工程中,M 往往非常大,计算 ∂Loss/∂w 非常耗时。因此,我们可以从 M 个训练样本中随机采样 N 个样本进行梯度计算,这称为SGD算法,公式如下。
g ̅=1/N ∑_(i=1)^N▒g_((i))
通过上面的结论,我们可以知道 g ̅ 为期望 ∂Loss/∂w 的无偏估计。但是,N 越小,g ̅ 在 ∂Loss/∂w 的摆动就越严重——时大时小,不利于训练。不过,g ̅ 适当摆动有利于在学习时逃离鞍点,如图5-1所示。

图5-1
当 w 落在鞍点的时候,∂Loss/∂w=0,w 将不再更新,学习结束。但是,使用SGD算法计算出 g ̅ 为 ∂Loss/∂w 的无偏估计,是一个随机值,因此会有轻微的变化,使 g ̅≠0,从而使 w 得到更新,进而逃离鞍点。
5.6 相关性
在真实世界中,随机变量之间有可能并不独立,它们之间往往相互影响。例如,从人群中随机抽一个人,那么它的身高就是随机变量 X,体重对应的就是随机变量 Y,尽管 X 和 Y 都是随机变量,但是他们之间却是有关系的。例如,知道一个人的身高是180cm,那么他的体重尽管是随机的,但也大概能有个范围,此时就称 X 和 Y 不独立。再如,明天北京的天气是随机变量 X,而我的考试成绩是随机变量 Y,北京的天气和我的考试成绩没有任何关系,因此,随机变量 X 和 Y 相互独立。但是,因为蝴蝶效应的存在,其实很难找出真正独立的事情,例如上海的天气可能会影响北京的天气,而北京的天气会进一步影响我的心情,从而影响我的考试成绩,所以,判断两个事件独立是非常难的。
在实际应用中,我们往往会降低要求,一般只判断两个事件是否线性相关,即两个事件的变化方向是否有规律可循。线性相关又分为两种情况。
正相关:两个变量朝同一方向变化。
负相关:两个变量朝相反方向变化。
如果两个事件的变化方向没有明显的关系,那么称为线性无关。例如,一个人的身高和他的考试成绩没有任何关联。
需要注意的是,线性相关的两个事件一定不独立,但独立的两个事件一定线性无关,即独立性比不相关更加严格。
如上所述,线性相关性是用来描述两个变量的变化方向是否一致的。对相关性进行如下定义。
Cov(X,Y)=E((X-E(X))(Y-E(Y)))
如果变量 X 比均值 E(X) 高(低),Y 也高(低)于均值 E(Y),那么此时认为 X 和 Y 正相关,即 X 和 Y 的变化方向相同。当 X 和 Y 同方向变化时,X-E(X) 和 Y-E(Y) 要么同为正,要么同为负,但相乘结果都为正,因此 Cov(X,Y)>0,表明 X 和 Y 正相关。当 X 和 Y 反方向变化时,那么 Cov(X,Y)<0。
如果 X 和 Y 毫无关系,那么此时 Cov(X,Y)=0,称 X 和 Y 线性无关。如果 X 和 Y 相互独立,根据均值的性质,可以知道
E(XY)=E(X)E(Y)
所以有
Cov(X,Y)=E((X-E(X))(Y-E(Y)))=E(XY-XE(Y)-YE(X)+E(X)E(Y))
=E(XY)-2E(X)E(Y)+E(X)E(Y)=0
即独立一定线性无关。但是,反过来不成立,不相关的两个事件,有可能并不独立,它们之间有更为隐蔽的联系,这也说明独立性比不相关要求更高。
上述是站在“上帝视角”定义的协方差。我们采集到一系列样本对 〖{X_i,Y_i}〗_(i=1)^N,例如一共有 N 个人,X_i 和 Y_i 分别是第 i 个人的身高和体重,协方差的计算方法如下。
Cov(X,Y)=(∑_(i=1)^N▒〖(X_i-X ̅)(Y_i-Y ̅)〗)/(N-1)
X ̅=1/N ∑_(i=1)^N▒X_i
Y ̅=1/N ∑_(i=1)^N▒Y_i
尽管 Cov(X,Y) 可以衡量 X 和 Y 的相关性,但是并没有进行归一化,这会带来数值上的困扰,不方便不同关系之间的比较。例如,同样是计算体重 X 和身高 Y 的相关性,我们把体重的单位从千克换成克,那么对应的 X-E(X) 在数值上被放大1000倍,Cov(X,Y) 也被放大1000倍。我们需要对 Cov(X,Y) 进行归一化,避免被量纲单位所影响,因此提出了相关系数的概念,具体如下。
ρ_XY=(Cov(X,Y))/(D(X)D(Y))
可以发现
ρ_XY∈[-1,1]
因为分母方差的存在,随机变量的量纲上下抵消,ρ_XY 不再受选取量纲的影响,更能反映客观的相关性,以及不同事件相关性的比较。
另外,相关性和我们之前讲解过的距离也有对应关系。例如,x 和 y 都是 n 维向量,即 x=[■(x_1@⋮@x_n )] 和 y=[■(y_1@⋮@y_n )]。为了方便计算,一般采取去中心化的技术对象进行处理,用 x ̅ 表示向量 x 各个维度的均值。去中心化就是
x^'=[■(x_1-x ̅@⋮@x_n-x ̅ )]
完成去中心化,x 各个维度的均值就为0。同理,可以得到 y^'=[■(y_1-y ̅@⋮@y_n-y ̅ )]。
如果我们把 x 和 y 中的每个元素都当成同一个事件,例如 x_i 和 y_i 表示两个人对第 i 部电影的喜爱程度,那么 x ̅ 和 y ̅ 就代表两个人对电影的总体偏好,有些人喜欢看电影,那么整体打分就偏高,反之亦然。接着,我们计算向量 x 和 y 的协方差,它表明两个人对电影品味的相关性,具体如下。
Cov(x,y)=(∑_(i=1)^n▒〖(x_i-x ̅)(y_i-y ̅)〗)/(n-1)=(〖(x^')〗^T y^')/(n-1)
同时,我们可以发现,向量 x 的标准差为
S_x=√((∑_(i=1)^n▒〖(x_i-x ̅)〗^2 )/(n-1))=‖x^' ‖/√(n-1)
同理
S_y=‖y^' ‖/√(n-1)
因此,我们可以得到向量 x 和 y 的相关系数:
ρ_xy=(Cov(x,y))/(S_x S_y )=(〖(x^')〗^T y^')/‖x^' ‖‖y^' ‖ =cosine(x^',y^')
综上所示,向量之间的相关系数就是向量去中心化后的余弦距离,用来表示向量之间的相关性。
5.7 正态分布
5.7.1 正态分布的基本概念和性质
正态分布,也叫高斯分布,它是一个连续型随机变量分布。正态分布不仅在机器学习中应用广泛,在各类工程领域、经济学中都有广泛应用。若随机变量 X 符合正态分布,那么它对应的均值和方差分别为 μ 和 σ^2。概率密度函数
f(x)=1/(√2π σ) exp(-(x-μ)^2/(2σ^2 ))
可以记做 X~N(μ,σ^2),不同的正态分布差异主要在于 μ 和 σ。
正态分布的概率密度函数的图像是一个倒钟型,如图5-2所示。

图5-2
特别的,当 μ=0 和 σ=1 时,我们称之为 N(0,1) 为标准正态分布。
正态分布以 μ 为对称轴左右对称,概率密度 f(x) 在 x=μ 时最大,并且 μ 为分布的均值、中位数、众数。σ 越大,数据越分散,图形铺得越开,如图5-3所示。

图5-3
在正态分布中有一个著名的sigma原则,具体如下,如图5-4所示。
sigma原则:数值分布在 (μ-σ,μ+σ) 中的概率为0.68。
2sigma原则:数值分布在 (μ-2σ,μ+2σ) 中的概率为0.95。
3sigma原则:数值分布在 (μ-3σ,μ+3σ) 中的概率为0.997。
图5-4
通过这个原则,我们可以快速判断数据是否为低概率事件。在实际应用中,一般把区间 (μ-3σ,μ+3σ) 看作随机变量 X 实际可能的取值区间,这称为正态分布的 3σ 原则。如果 X 落在 (μ-3σ,μ+3σ) 以外的概率小于3‰(1-0.9974=0.0026),在实际应用中常认为相应的事件不会发生。
正态分布有一些非常好的数学性质,正是这些性质使得使用它来分析问题非常方便,具体如下。
性质1:如果 X~N(μ,σ^2),a 和 b 是实数,那么 aX+b~N(aμ+b,〖(aσ)〗^2)
这条性质告诉我们,如果随机变量 X 为正态分布,那么它的线性变换也是正态分布。使用这条性质,我们可以很容易地将任意的正态分布 X~N(μ,σ^2) 转换成标准正态分布 N(0,1),即 a=1/σ,b=-μ/σ。
在机器学习中,多维特征有不同的含义,它们在数值上差异非常大。如果特征都属于正态分布,仅是 μ 和 σ 不同,我们可以把各个维度的特征都转换成标准正态分布,从而归一化量纲。例如,有 N 个训练样本 〖{x_((i) ),y_((i) )}〗_(i=1)^N,特征 x_((i) )=〖[x_((i),1),x_((i),2)]〗^T,分别计算各个维度的均值和样本方差,公式如下。
μ_1=1/N ∑_(i=1)^N▒x_((i),1)
μ_2=1/N ∑_(i=1)^N▒x_((i),2)
σ_1=√(1/(N-1) ∑_(i=1)^N▒〖(x_((i),1)-μ_1)〗^2 )
σ_2=√(1/(N-1) ∑_(i=1)^N▒〖(x_((i),2)-μ_2)〗^2 )
对于特征,可以进行如下转换。
(x_((i),1)-μ_1)/σ_1 →x_((i),1)
(x_((i),2)-μ_2)/σ_2 →x_((i),2)
转换后,特征在各个维度的分布都符合标准正态分布 N(0,1),并且数值都在一个数量级。
在深度学习中,为了增强网络的稳定性和提高学习速度,经常采用批标准化(Batch Normalization,BN)的方法对数据进行正规化。
BN一般对激活函数之前的输入 d^((l)) 进行操作。例如,在使用SGD进行训练时,每次都选取 N 个样本计算梯度。神经网络某层(输入层和各个中间层)的输入为 n 维向量,记为 〖{x_((i))}〗_(i=1)^N,x_((i),j) 表示第 i 个样本的第 j 维。计算这批数据各个维度的均值和方差,方法如下。
μ_j=1/N ∑_(i=1)^N▒x_((i),j)
σ_j=√(1/N ∑_(i=1)^N▒〖(x_((i),j)-μ_j)〗^2 )
j=1,⋯,n
然后,将各个样本进行如下变换。
x ̅_((i),j)=γ_j (x_((i),j)-μ_j)/σ_j +β_j,i=1,⋯,N,j=1,⋯,n
这个变换可以分解为两步:第一步,计算 (x_((i),j)-μ_j)/σ_j ,作用是将数据分布规范化至标准正态分布 Ν(0,1);第二步,通过 γ_j 和 β_j 将标准正态分布调整至 Ν(β_j,γ_j^2),其中 γ_j 和 β_j 为待学习参数。
性质2:如果 X~N(μ_x,σ_x^2),Y~N(μ_y,σ_y^2),那么它们的“和”“差”都满足正态分布
公式如下。
X+Y~N(μ_x+μ_y,σ_x^2+σ_y^2)
X-Y~N(μ_x-μ_y,σ_x^2+σ_y^2)
这个性质非常有意思,它极大地扩展了正态分布的使用范围。例如,在线性回归中,有
y^'=w_0+w_1 x_1+⋯+w_n x_n
如果各个特征 x_i 都服从正态分布 N(μ_i,σ_i^2),那么预测结果 y^' 也符合正态分布。
正态分布是一个非常重要的分布,自然界常见的事物,例如人的身高、体重及学生的考试成绩等,都符合正态分布。正态分布为什么会很常见呢?原因在于中心极限定理:多个独立统计量的和的均值,符合正态分布。简单地说,如果一个事物受到多种因素的影响,那么,不管每个因素本身是什么分布,它们加总后,结果的均值就是正态分布。例如,男性身高受遗传因素、饮食因素、体育锻炼等多方面影响,这些因素本身都是随机变量,并且属于不同的分布,但是只要样本量足够,男性身高就会符合正态分布。
这也是我们在做机器学习任务的时候,无论是样本空间分布,还是噪声分布,都会使用正态分布建模的原因——正态分布最接近客观事实。
5.7.2 正态分布和逻辑回归
我们可以通过身高 x 和贝叶斯定理来预测性别 y,y=1 表示男性,y=0 表示女性,男性和女性的身高分布都满足正态分布。
男性的身高分布的概率密度为
f(x|y=1)=1/(√2π σ) e^(-〖(x-μ_1)〗^2/(2σ^2 ))
女性的身高分布的概率密度为
f(x|y=0)=1/(√2π σ) e^(-〖(x-μ_2)〗^2/(2σ^2 ))
其中,男性身高的均值为 μ_1,女性身高的均值为 μ_2,方差都为 σ。我们知道一个人的身高 x,想通过身高预测其性别,这就是一个典型的二分类问题——在判别模型中,其实就是比较 P(y=1│x) 和 P(y=0│x) 的大小。需要注意的是,P(y=1│x)+P(y=0│x)=1。
假设男性和女性的比例为 (P(y=1))/(P(y=0))=α,因为 P(y=1)+P(y=0)=1,所以 P(y=1)=α/(1+α) 和 P(y=0)=1/(1+α)。
根据贝叶斯公式,当一个人的身高为 x 时,其为男性的概率为
P(y=1│x)=(P(y=1)f(x|y=1))/(∑_(y∈Y)▒P(y) f(x|y))=α/(1+α) (f(x|y=1))/(∑_(y∈Y)▒P(y) f(x|y))
同理,当一个人的身高为 x 时,其为女性的概率为
P(y=0│x)=(P(y=0)f(x|y=0))/(∑_(y∈Y)▒P(y) f(x|y))=1/(1+α) (f(x|y=0))/(∑_(y∈Y)▒P(y) f(x|y))
将二者相除,有
(P(y=1│x))/(P(y=0│x) )=α (f(x|y=1))/(f(x|y=0))
根据身高的概率密度函数分布,可知
f(x|y=1)=1/(√2π σ) e^(-〖(x-μ_1)〗^2/(2σ^2 ))
f(x|y=0)=1/(√2π σ) e^(-〖(x-μ_2)〗^2/(2σ^2 ))
那么有
(P(y=1│x))/(P(y=0│x) )=αe^(-〖(x-μ_1 )^2-(x-μ_2 )〗^2/(2σ^2 ))=e^lnα e^(-((2μ_2-2μ_1 )x+(μ_1^2-μ_2^2 ))/(2σ^2 ))=e^(-((2μ_2-2μ_1 )x+(μ_1^2-μ_2^2 ))/(2σ^2 )+lnα)
结合 P(y=1│x)+P(y=0│x)=1,可以得出
P(y=1│x)=1/(1+e^(-(((2μ_1-2μ_2 )x+(μ_2^2-μ_1^2 ))/(2σ^2 )+lnα) ) )
令 w=(μ_1-μ_2)/σ^2 ,w_0=(μ_2^2-μ_1^2)/(2σ^2 )+lnα,则
P(y=1│x)=1/(1+e^(-(wx+w_0)) )
其实,这就是逻辑回归。
逻辑回归是典型的判别式模型,并没有去学习正态分布对应的参数 μ_1、μ_2、σ,而是直
接学习对分类有用参数,即 (μ_1-μ_2)/σ^2 和 (μ_2^2-μ_1^2)/(2σ^2 )+ln (P(y=1))/(P(y=0))。这也是判别模型比生成模简单的原因——判别模型仅学习对分类有帮助的信息,而不是类别本身。
不过,在这里需要注意:将逻辑回归作为分类函数,相当于默认偏置条件“数据满足正态分布”。经统计学方法验证,当数据量足够大时,根据中心极限定义,概率分布都会趋近于正态分布。这也说明,在训练模型时,数据量越大,数据分布越接近正态分布,越符合模型的假设,效果自然越好。
第6章 概率在深度学习中的应用
6.1 概率分布之间的距离
两个人投篮,x=1 表示投中,x=0 表示没投中。第一个人投中的概率是 P(x=1)=0.8,P(x=0)=0.2。第二个人投中的概率是 Q(x=1)=0.7,Q(x=0)=0.3。我们想比较这两个人投篮水平的差异,应该怎么做呢?
一般来说,可以使用KL距离来度量相同事件空间的概率分布 P(x) 和 Q(x) 的差异,公式如下
D(P||Q)=∑_(x∈X)▒〖P(x)log (P(x))/(Q(x))〗
在上例中,我们可以计算
D(P||Q)=P(x=0)log P(x=0)/Q(x=0) +P(x=1)log P(x=1)/Q(x=1)
=0.2∙log 0.2/0.3+0.8∙log 0.8/0.7=0.026
特别的,当两个概率分布相等时,即 P(x)=Q(x),log (P(x))/(Q(x))=log1=0,D(P||Q)=0。
不过,需要注意的是,和其他距离不同的是,KL距离不具备对称性,即
D(P||Q)≠D(Q||P)
我们在进行二分类的时候,两类分别为P类和N类。y 表示样本 x 属于P类的概率,1-y 表示样本 x 属于N类的概率。y 为 x 的真实类别,是一个确定事件,即 y=1 或者 y=0。y^' 为模型预测出来的 x 为P类的概率,1-y^' 表示模型预测样本为N类的概率。模型预测的 y^' 是一个概率,因此 y^'∈(0,1)。
真实情况和模型结果的差异可以由KL距离来度量,公式如下。
D(真实结果||模型结果)=ylog y/y^' +(1-y)log (1-y)/(1-y^' )
例如,有训练样本 〖{x_((i) ),y_((i))}〗_(i=1)^N,我们可以用它们对应的平均KL距离来度量模型结果和真实结果的差异,公式如下。
Loss=1/N ∑_(i=1)^N▒〖(y_((i)) log y_((i))/(y_((i))^' )+(1-y_((i)))log (1-y_((i)))/(1-y_((i))^' )〗)
Loss 越大,说明模型输出结果 y_((i))^' 离真实情况越远。
模型学习的目标就是不断地通过改变参数来改变 y_((i))^',以缩短KL距离。我们可以对上式进行一些简化:
Loss=∑_(i=1)^N▒(y_((i) ) log y_((i) )/(y_((i))^' )+(1-y_((i) ))log (1-y_((i) ))/(1-y_((i))^' ))
=∑_(i=1)^N▒〖y_((i)) log(y_((i)) )-y_((i)) logy_((i))^'+(1-y_((i)) )log(1-y_((i)) )-(1-y_((i)))log(1-y_((i))^')〗
因为我们的最终目标是改变 y_((i))^' 以缩短KL距离,所以只需要保留和 y_((i))^' 有关的项,其他略去,具体如下。
Loss=∑_(i=1)^N▒(-y_((i)) logy_((i))^'-(1-y_((i)))log(1-y_((i))^'))
可以发现,这正是二分类模型常用的损失函数。
6.2 最大似然估计
6.1节说到分类模型所使用的损失函数其实就是KL距离,但是距离有很多种,为什么一定要使用KL距离呢?原因在于KL距离等价于最大似然估计,而最大似然估计是目前数学界最常用、理论基础最扎实的参数估计方法。下面我们具体详细讲解最大似然估计在二分类中的应用。
当我们知道一个事件的概率分布后,就可以通过这个概率分布计算对应的概率。例如,已知后验概率 P(y|x) 的计算方法,x 为身高,y 为性别,我们可以通过一个人的身高预测他的性别概率。机器学习就是通过大量已知的身高和性别数据去找到最适合的 P(y|x)。那么,什么样的 P(y|x) 才算是最合适的呢?
因为已知数据是已经发生的,在没有任何其他信息时,已知事情对应的概率就应该是最大的。例如,我们认为“太阳从东方升起”对应的概率为1,是因为这件事情每天都在发生。
在使用模型预测样本 x_((i) ) 的类别时,模型的输出为 y_((i))^',也就是说,预测结果为P类的概率为 y_((i))^',预测结果为N类的概率为 〖1-y〗_((i))^'。
如果 x_((i) ) 的真实类别为P类,也就是 y_((i) )=1,那么模型预测结果为P类的概率为 P(y=y_((i) ) |x_((i) ) )=y_((i))^'。
如果 x_((i)) 的真实类别为N类,也就是 y_((i))=0,那么模型预测结果为N类的概率为 P(y=y_((i)) |x_((i)) )=1-y_((i))^'。
这是一个典型的0-1分布,可以统一写成
P(y=y_((i)) |x_((i)) )=〖y_((i))^'〗^(y_((i)) ) (1-y_((i))^' )^((1-y_((i))))
N 个训练样本 {〖x_((i) ),y_((i) )〗_(i=1)^N} 之间可能会存在相互矛盾的情况,例如身高170cm的人既有男性也有女性,即 x_((i) )=170、y_((i) )=1 和 x_((j) )=170、y_((j) )=0 同时存在于训练样本中。因此我们不必使所有样本对应的概率都为1,只需要整体最大即可,即最大化
likelihood=∏_(i=1)^N▒P(y=y_((i)) |x_((i)) )
一般称 likelihood 为似然函数。
为了方便计算,我们对似然函数取对数,似然函数变为
likelihood=log∏_(i=1)^N▒P(y=y_((i) ) |x_((i) ) ) =∑_(i=1)^N▒logP(y=y_((i) ) |x_((i) ) )
=∑_(i=1)^N▒〖log[〖y_((i))^'〗^(y_((i) ) )∙(1-y_((i))^' )^((1-y_((i) ) ) ) ]=∑_(i=1)^N▒〖y_((i)) log〖y_((i))^' 〗+(1-y_((i)) ) log(1-y_((i))^' ) 〗〗
因为训练样本是已经发生的事件,所以“好模型”的标准就是能够使似然函数最大化(最大似然估计)。优化目标为最大化似然函数,即 max(likelihood),它等价于 min(-likelihood),故优化目标为
min(-likelihood)〖=min〗[∑_(i=1)^N▒〖-y_((i)) log〖y_((i))^' 〗-(1-y_((i)) ) log(1-y_((i))^' ) 〗]
可以看出,-y_((i)) log〖y_((i))^' 〗-(1-y_((i)) ) log(1-y_((i))^' ) 就是 y_((i))^' 和 y_((i)) 的KL距离,优化目标就是最小化各样本的KL距离之和。
通过以上分析可以发现,使用KL距离的原因就是它等价于最大似然估计。
除了分类问题,回归问题也是机器学习常见的任务。
在回归问题中,模型预测的不再是类别概率,而是一个连续的数值,例如房价、人口
数等。例如,在训练样本 〖{x_((i)),y_((i))}〗_(i=1)^N 中,我们认为因变量(房价)y_((i)) 和自变量(面积、与城区的距离等)x_((i)) 的关系是
y_((i))=w^T x_((i))+w_0
这种模型称为线性回归。y_((i)) 和 x_((i)) 之间的关系可以是更复杂的形式,例如是一个多层神经网络。模型的学习过程,就是利用已知的数据 〖{x_((i)),y_((i))}〗_(i=1)^N 找到合适的 w。
但是,在我们拿到的训练数据中,也会有偏差 ε,例如两座一模一样的房子也有可能卖出不同的价格。这类偏差具有随机性,其影响因素无法在特征中体现,例如购房者自身的偏好、议价能力、单纯的运气等。
为了方便建模,我们把这些因素的影响用一个正态分布表示,对应的概率密度为
f(ε=e)=1/(σ√2π) exp^(-e^2/(2σ^2 ))
那么,y_((i)) 和 x_((i)) 的关系变为
y_((i))=w^T x_((i))+w_0+ε
根据正态分布的性质,此时 y_((i)) 也是一个连续型随机变量,符合正态分布,期望为 w^T x_((i))+w_0,方差为 σ^2。x_((i)) 已知时,y_((i)) 对应的概率密度函数为
f(y=y_((i)) |x_((i)) )=1/(σ√2π) exp^(-〖(y_((i) )-w^T x_((i) )-w_0)〗^2/(2σ^2 ))
机器学习的目标是从数据中找到最优的 w 和 w_0。
从统计学的角度,通过调整参数使训练样本 〖{x_((i)),y_((i))}〗_(i=1)^N 出现的概率最大。因此,考虑所有训练样本,需要最大化的似然函数为
likelihood=∏_(i=1)^N▒〖f(y=y_((i) ) |x_((i) ) )=∏_(i=1)^N▒〖1/(σ√2π) exp^(-〖(y_((i) )-f(x_((i))))〗^2/(2σ^2 )) 〗〗
为了运算方便,我们对似然函数取对数,使似然函数变为
likelihood=log[∏_(i=1)^N▒〖1/(σ√2π) e^(-〖(y_((i) )-f(x_((i))))〗^2/(2σ^2 )) 〗]=∑_(i=1)^N▒[-〖(y_((i) )-f(x_((i))))〗^2/(2σ^2 )-logσ√2π]
模型学习的目标就是最大化似然函数 likelihood,即已经发生的事实,因此,其对应的概率应该最大。
max(likelihood) 即最小化 min(-likelihood),因此,优化目标为最小化下式。
∑_(i=1)^N▒[〖(y_((i) )-f(x_((i))))〗^2/(2σ^2 )+logσ√2π]
由于在似然函数中,只有 w 和 w_0 为变量是我们希望求解的,其他无关项均可去除,所以,优化目标变为最小化下式。
∑_(i=1)^N▒〖〖(y_((i) )-f(x_((i))))〗^2=∑_(i=1)^N▒〖(y_((i) )-y_((i))^')〗^2 〗=∑_(i=1)^N▒〖(y_((i) )-w^T x_((i) )-w_0)〗^2
可以发现,上式就是MSE。可见,当数据符合正态分布时,使用MSE优化线性回归模型等价于最大似然估计。
6.3 logit和softmax
6.3.1 二分类的logit
通过前面的学习,我们知道概率 P 用来描述事件发生的可能性。但有的时候,我们需要知道事件发生和事件不发生之间的比例,因此定义Odds,具体如下。
Odds=P/(1-P)
假设中国队和巴西队踢足球,中国队的胜率为 1/10000,那么对应的Odds为 1/9999。也就是说,在制定赔率时,巴西队胜利赢1元,需要设定中国队胜利赢9999元,这个盘口才公平,才会有人下注。
我们知道,概率 P 的值域为 [0,1],如果直接用模型对概率 P 进行学习,模型的输出范围将会受限,Odds的值域为 [0,+∞]。再进一步,我们定义logit,它为Odds的对数,即
logit=logOdds=log〖P/(1-P)〗
容易看出,logit的值域为 (-∞,+∞)。使用模型来逼近logit,有一个好处就是模型的输出不再有值域的限制,因此模型的选取范围将显著增大。
例如,在二分类中,可以使用模型 f(x)(值域为 (-∞,+∞))对 logit(P(y=1|x)) 建模,即
logit(P(y=1│x))=log〖(P(y=1│x))/(1-P(y=1│x) )〗=f(x)
化简可得
P(y=1│x)=1/(1+e^(-f(x)) )
当 f(x)〖=w〗^T x+w_0,即 f(x) 为线性回归时,可得
P(y=1│x)=1/(1+e^(-(w^T x+w_0)) )
又导出了逻辑回归。
通过上面的例子其实可以发现,逻辑回归和线性回归没有本质上的不同。在逻辑回归中,其实就是用线性回归去拟合logit。
6.3.2 多分类的softmax
在实际项目中,除了二分类,多分类也是常见的任务。这里要说明一下,同样是多类别的分类,多分类和多标签是两种不同的任务。
在多分类中,要求类别之间互斥,且考虑部情况,即 ∑_(i=1)^N▒〖P(y=i│x)=1〗,N 为类别
个数。例如,通过模型预测一个人的学历,即“高中”“本科”“大学”“硕士”“博士”“其他”,那么这必然是一个N选1任务。但有时候类别之间并不互斥,例如预测一首歌属于“摇滚”“流行”“古典”“嘻哈”,一首歌往往会属于多种类型,我们称这类任务为多标签任务。本节仅讨论多分类的相关知识。
在N分类中,模型一般会有 N 个输出 f_1 (x)~f_N (x),但 f_1 (x)~f_N (x) 不宜直接输出概率 P(y=i|x),主要原因如下。
如果直接输出概率,那么 f_1 (x)~f_N (x) 的值域就会被限制为 [0,1],这对模型的选取有极大的限制。
在多分类中,∑_(i=1)^N▒〖P(y=i│x)=1〗 是一个硬性要求,f_1 (x)~f_N (x) 之间互相耦合,这给模型的选取带来了极大的挑战。
我们可以对 f_1 (x)~f_N (x) 进行概率归一化,具体如下。
P(y=i|x)=(f_i (x))/(∑_(i=1)^N▒〖f_i (x) 〗)
虽然解决了 ∑_(i=1)^N▒〖P(y=i│x)=1〗 的问题,但仍然存在其他问题,列举如下。
必须要求 f_i (x)≥0,否则 P(y=i│x)<0,这不符合概率本身的定义。因此,f_i (x) 的值域范围变小了。
概率只反映了 f_1 (x)~f_n (x) 之间的比例差,忽略了绝对差。
例如,当 N=2 时,第一种情况是
f_1 (x)=3
f_2 (x)=6
按上述归一化方法,可以得到
P(y=1|x)=1/3
P(y=2|x)=2/3
第二种情况是
f_1 (x)=300
f_2 (x)=600
按上述归一化方法,可以得到
P(y=1|x)=1/3
P(y=2|x)=2/3
显然,在这两种情况下归一化的概率是相等的,这是因为 f_1 (x):f_2 (x) 的比例并没有发生变化。但是,很明显,在第二种情况下 f_2 (x)-f_1 (x)=300 差值远大于第一种情况(差值为 6-3=3)。按正常思路,在第二种情况下,P(y=2|x) 应该更大。
为了解决上述问题,我们在多分类问题中,一般使用softmax函数进行概率归一化。softmax函数的输入和输出均为向量,具体形式如下。
softmax([■(x_1@⋮@x_N )])=[■(e^(x_1 )/(∑_(i=1)^N▒e^(x_i ) )@⋮@e^(x_N )/(∑_(i=1)^N▒e^(x_i ) ))]=1/(∑_(i=1)^N▒e^(x_i ) ) [■(e^(x_1 )@⋮@e^(x_N ) )]
归一化的结果如下。
[■(P(y=1|x)@⋮@P(y=N|x))]=softmax([■(f_i (x)@⋮@f_N (x) )])=1/(∑_(i=1)^N▒e^(f_i (x) ) ) [■(e^(f_i (x) )@⋮@e^(f_N (x) ) )]
softmax函数有如下优点。
能够满足 ∑_(i=1)^N▒〖P(y=i│x)=1〗。
f_i (x) 的值域可以为 (-∞,+∞),这极大拓宽了模型 f_i (x) 的选择范围。
P(y=i|x) 随 e^(f_i (x) ) 指数级增长,使模型输出对 f_i (x) 的绝对值敏感。
为什么这个函数叫作softmax呢?我们从hardmax函数说起。hardmax函数的输入为一个向量,输出为一个与输入同维度的向量,原向量中最大值对应的位置取1,其他位置都为0。例如:
x=[■(10@20@21)],y=hardmax(x)=[■(0@0@1)]
但是,这样做太“硬”了,会造成如下问题。
20仅比21小了1,但函数输出天差地别。hardmax函数对输入过于敏感,输入轻微变化,输出会有过大震荡。
函数不是一个连续函数,因此会造成求导困难,从而影响梯度下降法的使用。
softmax函数可以克服hardmax函数的上述问题。但是softmax函数在计算时,e^(x_i ) 很容易过大而导致溢出。我们可以做如下转换,以解决这个问题。
d=max(x_1,⋯,x_N )
softmax([■(x_1-d@⋮@x_N-d)])=1/(∑_(i=1)^N▒e^(x_i-d) ) [■(e^(x_1-d)@⋮@e^(x_N-d) )]=1/(∑_(i=1)^N▒e^(x_i ) ) [■(e^(x_1 )@⋮@e^(x_N ) )]=softmax([■(x_1@⋮@x_N )])
即
softmax([■(x_1@⋮@x_N )])=softmax([■(x_1-d@⋮@x_N-d)])
因此,在计算softmax函数时,先对各个元素计算 x_i-max(x_1,⋯,x_N),再进行其他计算,可以有效防止数值溢出。
6.4 语言模型
在自然语言处理中,语言模型是一个非常重要的模型,它用于计算“一句话是合理的”的概率。
例如,P(我喜欢吃饭)>P(我你哦)。“我喜欢吃饭”是常见句。而“我你哦”作为病句,几乎不会出现,其概率应该如何计算呢?“我喜欢吃饭”对应于4个词,w_1=“我”,w_2=“喜欢”,w_3=“吃”,w_4=“饭”,概率记为 P(w_1 w_2 w_3 w_4),即顺序排列的一系列词所对应的联合概率密度分布。需要注意的是,概率和词的顺序有关,即“饭喜欢吃我”对应于概率 P(w_4 w_2 w_3 w_1) 且 P(w_1 w_2 w_3 w_4)≠P(w_4 w_2 w_3 w_1)。P(w_1 w_2 w_3 w_4) 可用贝叶斯定理化简,如下式所示。
P(w_1 w_2 w_3 w_4 )=P(w_1 )×P(w_2│w_1 )×P(〖w_3 |w〗_1 w_2 )×P(w_4│w_1 w_2 w_3 )
其中:P(w_1) 表示词 w_1 出现的概率;P(w_2 |w_1) 表示第一个词为 w_1 时,第二个词为 w_2 的概率;P(〖w_3 |w〗_1 w_2) 表示前两个词为 w_1 和 w_2 时,下一个词为 w_3 的概率……依此类推。
不失一般性,对于由 n 个词构成的句子,语言模型可以写成如下形式。
P(w_1 w_2⋯w_n )=∏_(i=1)^n▒P(w_i |w_1⋯w_(i-1) )
上式在估计概率时有一个明显的缺陷,就是运算量过大。例如,中文有200000个常见词,那么在估计 P(〖w_3 |w〗_1 w_2) 时,w_1、w_2、w_3 各有200000种可能性,因此,需要估计 200000^3 个概率(这几乎是一项不可能完成的工作)。而且,随着词数的增加,P(w_i |w_1⋯w_(i-1) ) 所对应的概率数量将以指数级增长。
在概率中,有一种性质叫作“马尔可夫性”。对于已经发生的时序 {x_1,⋯,x_t},未来时刻 P(x_(t+1)) 仅有前 k 个时刻决定,此时称作k阶马尔可夫,具体如下。
P(x_(t+1) |x_1,⋯,x_t )=P(x_(t+1) |x_(t-k+1),⋯,x_t )
为了简化问题,我们把马尔可夫性用在语言模型上。假设一个词的概率仅由其前面的 n-1 个词决定,这种模型称为n-gram模型(n-1 个前面的词和待预测词本身)。假设一个词出现的概率仅受其前一个词的影响,此时模型称为2-gram模型,公式如下。
P(w_1 w_2 w_3 w_4 )=P(w_1)×P(w_2 |w_1)×P(w_3 |w_2)×P(w_4 |w_3)
不失一般性,2-gram可以写成如下形式。
P(w_1 w_2⋯w_n )=∏_(i=1)^n▒P(w_i |w_(i-1) )
特别地,P(w_1 |w_0 )=P(w_1 )。此时,待估计的概率有 200000^2 个,且不受句子长度的影响,n-gram语言模型具备了可操作性。
那么,概率该如何计算呢?类似于朴素贝叶斯算法,通过数据统计,将频率值作为概率的估计值。例如,估计2-gram模型的相关参数,语料中有以下4句话。
sentence1:w_1,w_2,w_3
sentence2:w_1,w_3,w_4
sentence3:w_1,w_2,w_5
sentence4:w_1,w_5,w_6
w_1 一共出现了4次,w_2 紧接着w_1 出现的次数为2次,因此
P(w_2│w_1 )=2/4
同理,可得 P(w_3│w_1 )=1/4。因为在语料中 w_6 从未紧接着 w_1 出现,所以 P(w_6│w_1 )=0。
将语言模型的概率写成公式,具体如下。
P(w_2│w_1 )=(count(〖w_2;w〗_1))/(∑_w▒〖count(w;w_1)〗)
其中,count(w;w_1) 表示 w_1 后面为 w 的次数,∑_w▒ 表示遍历所有的 w_1 后面的那个词。
P(w_6│w_1 )=0 真的准确吗?不一定,很可能因为数据量不够或数据选择有偏差而导致计算错误。由此可知,在直接使用频率作为概率进行估计时,如果有些小概率情况没有在语料中出现,其概率就会直接被计算为0。为了避免这个问题,可以使用平滑法,具体如下。
P(w_2│w_1 )=(δ+count(〖w_2;w〗_1))/(δV+∑_w▒〖count(w;w_1)〗)
其中,δ 是人为设置的超参数,V 为词表中的总词数。
用平滑法重新估计概率。因为在本例的语料库中一个有6个词,所以 V=6。将 δ 设为1,有
P(w_2│w_1 )=(1+2)/(6+4)=3/10
P(w_6│w_1 )=(1+0)/(6+4)=1/10
需要注意的是,在真实的自然语言中,n-gram算法有一定的局限性。例如,在“我喜欢吃苹果,它酸甜、营养、解渴”这句话中,决定“解渴”的词并不是它前面的“营养”“酸甜”“它”,而是“苹果”。这就是自然语言处理中的长距离依赖问题。n-gram模型为了解决长距离依赖问题,只能增大 n 的值,但这会给概率估计造成困难。所以,在n-gram语言模型中,通常取 n=2(n=3 就到达极限了)。
有时候,我们需要估计 w_1 w_2⋯w_n 中某个单词出现的概率,例如
P(w_4│w_1 w_2 w_3 w_5…w_n )
一般来说,会使用神经网络对概率建模。例如,在Bert模型中,使用 [mask] 字符替换 w_4 位置的字符,然后输出预测 w_4 出现的概率,公式如下。
f(w_1,w_2,w_3,[mask]〖,w〗_5⋯w_n)=P(w_4│w_1 w_2 w_3 w_5⋯w_n )
Bert模型非常像完型填空,用横线遮住 w_4,然后预测横线上应该出现的词。[mask] 字符的作用是进行标识,告诉模型,预测的位置在 w_3 和 w_5 之间。
除了Bert模型,我们也会使用word2vec对 w_4 进行预测。与Bert不同的是,word2vec并没有用句子中所有的词进行预测,而是使用待预测词 w_4 的前后2个词(2称为窗口,是一个超参数,可自行设定)进行预测,它对应的模型为
f(w_2 〖,w〗_3 〖,w〗_5,w_6 )=P(w_4│w_1 w_2 w_3 w_5…w_n )
Word2vec与Bert相比,在模型上做了大量的简化,主要体现在以下两个方面。
只考虑窗口范围的词,减少了模型的输入。
词袋模型,即word2vec对输入 w_2 w_3 w_5 w_6 的顺序不敏感,具体如下。
f(w_2,w_3,w_5,w_6 )=f(w_2,w_5.w_3 〖,w〗_6 )=f(w_6,w_5 〖,w〗_2 〖,w〗_3 )=⋯
这也是word2vec无需使用 [mask] 字符标注位置的原因。
上面这种word2vec模式称为cbow。word2vec还有一种形式,就是通过一个词预测周边窗口内所有词,即对于词 w_4,需要使用模型对如下概率进行建模。
f(w_4 )=P(w_2│w_4 )
f(w_4 )=P(w_3│w_4 )
f(w_4 )=P(w_5│w_4 )
f(w_4 )=P(w_6│w_4 )
这种模式称为skip-gram。与cbow相比,skip-gram可以产生更多的训练样本,使训练效果更好。
由于字数限制,第6章 概率在深度学习中的应用可点击这个卡片链接进行查看学习:
北大博士后AI卢菁:《速通深度学习数学基础》第6章 概率在深度学习中的应用0 赞同 · 2 评论文章
对机器学习感兴趣的读者可以去主页关注我;本人著有《速通深度学习》以及《速通机器学习数学基础》二书,想要完整版电子档可以后台私信我;实体版已出版在JD上有售,有兴趣的同学可以自行搜索了解
如有想跟着本人学习机器学习的话也可以後台私信,本人所做机器学习0基础教程已有60余章还未公开;想了解的话也是後台私信或者评论区留言。















 237
237











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









