






目录
一、Pandas库的介绍
Pandas是Python第三方库,提供高性能易用数据类型和分析工具。当谈论数据处理和分析时,Pandas 库就像一个强大的工具箱,可以帮助你处理和分析各种类型的数据,从简单的电子表格到大规模的数据集。以下是关于 Pandas 库的通俗介绍
1. 数据表格的专家: Pandas 主要用于处理和操作数据表格,就像你在 Excel 或 Google Sheets 中所做的那样。它能够轻松加载、创建、编辑和保存数据表格。
2. 强大的数据结构: Pandas 提供两种主要的数据结构,称为DataFrame和Series。DataFrame 是一个二维的数据表格,而 Series 是一维的数据序列。你可以将它们想象成 Excel 表格中的列和行。
3. 数据清洗和转换: 数据通常不是完美的,可能存在缺失值、重复项或格式问题。Pandas 提供了各种功能,帮助你轻松地清洗和转换数据,使其适合分析。
4. 数据筛选和选择: 你可以使用 Pandas 来选择和过滤数据,只提取你关心的部分。这对于快速查找特定信息非常有用。
5. 数据聚合和分组: Pandas 允许你根据某些列的值对数据进行分组,并进行聚合操作,如计算平均值、总和、中位数等统计数据。
6. 时间序列数据: 如果你处理时间相关的数据,Pandas 也提供了强大的时间序列支持,可以帮助你分析时间序列数据。
7. 数据可视化: Pandas 可以与其他数据可视化库(如Matplotlib和Seaborn)无缝集成,帮助你创建各种类型的图表和图形,以更好地理解数据。
8. 数据导入和导出: Pandas 能够读取和写入各种不同格式的数据,包括 CSV、Excel、SQL 数据库、JSON 等等。
9. 自动化数据处理: 你可以使用 Pandas 来自动化一些常见的数据处理任务,如数据合并、拆分、透视表的创建等。
总之,Pandas 是一个非常强大而灵活的数据处理和分析库,它为数据科学家、分析师和工程师提供了丰富的工具和函数,使他们能够更轻松地处理和分析各种类型的数据,从而做出更明智的决策。无论是初学者还是专业人士,Pandas 都是一个不可或缺的数据分析工具。
二、Pandas使用方法
1 .对象创建
1.1Pandas Series对象
Series 是带标签数据的一维数组
通用结构: pd.Series(data, index=index, dtype=dtype)
data:数据,可以是列表,字典或Numpy数组
index:索引,为可选参数
dtype: 数据类型,为可选参数
1、用列表创建
- index缺省,默认为整数序列
import pandas as pd
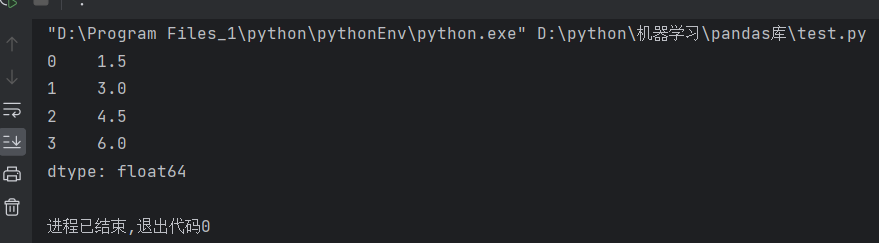
data = pd.Series([1.5, 3, 4.5, 6])
print(data)
运行结果:
- 增加index
import pandas as pd
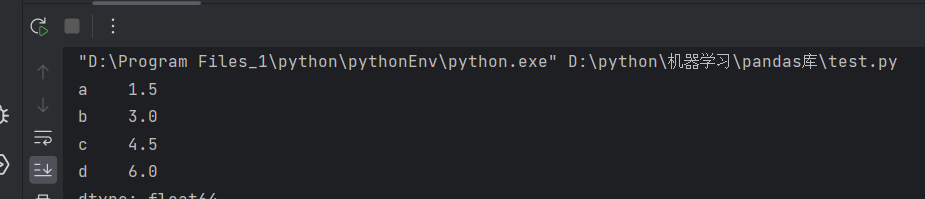
data = pd.Series([1.5, 3, 4.5, 6], index=["a", "b", "c", "d"])
print(data)
运行结果:
- 增加数据类型
import pandas as pd
data = pd.Series([1.5, 3, 4.5, 6], index=["a", "b", "c", "d"],dtype='float')
print(data)
运行结果:

2 Pandas DataFrame对象
DataFrame 是带标签数据的多维数组
DataFrame对象的创建
通用结构: pd.DataFrame(data, index=index, columns=columns)
data:数据,可以是列表,字典或Numpy数组
index:索引,为可选参数
columns: 列标签,为可选参数
2.1通过Series对象创建
import pandas as pd
dict = {"BeiJing": 2154,
"ShangHai": 2424,
"ShenZhen": 1303,
"HangZhou": 981 }
data = pd.Series(dict)
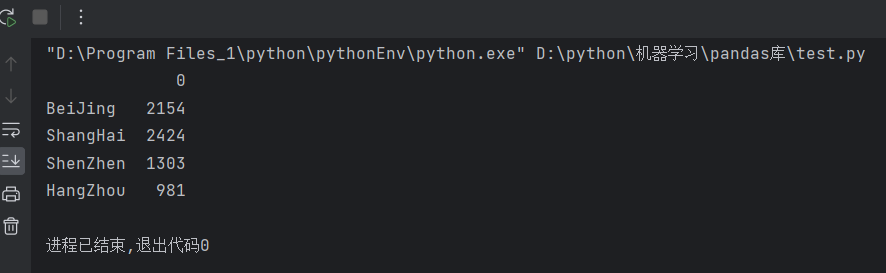
pd.DataFrame(data)
print(pd.DataFrame(data))
运行结果:
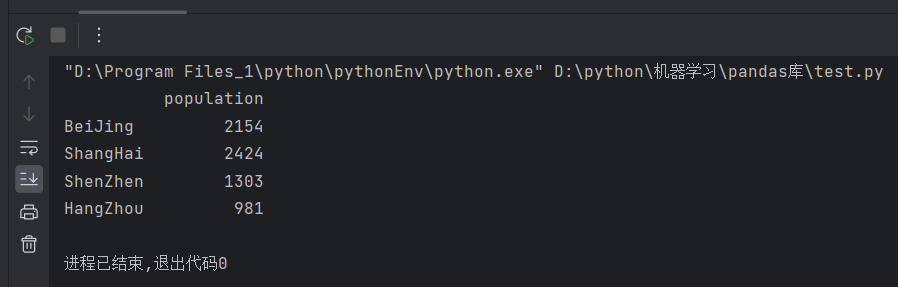
创建的 Series 数据,并将其命名为 "population" 列
pd.DataFrame(data, columns=["population"])
print(pd.DataFrame(data, columns=["population"]))运行结果:
3.文件的读取与写入
3.1文件的写入
写入CSV文件:
import pandas as pd
data_read_path =r"F:\joyful-pandas-master\data\my_csv.csv"
data_write_path = r"F:\joyful-pandas-master\data\my_csv_saved.csv"
data = pd.read_csv(data_read_path)
data.to_csv(data_write_path, index=False) # 此时不能打开被写的文件
data.to_csv(data_write_path, index=False)
把data中的数据 ,写入到data_write_path 中,且设置去除索引操作。
写.txt文件
写txt文件使用的是:
.to_csv()方法
记得设置分割方式:sep
data.to_csv('data/my_txt_saved.txt', sep='\t', index=False)
写入excel文件:
data.to_excel('data/my_excel_saved.xlsx', index=False)
3.2文件的读取
-
读取CSV文件:
import pandas as pd
data=pd.read_csv('path',sep=',',header=0,names=["第一列","第二列","第三列"],encoding='utf-8')
-
path: 要读取的文件的绝对路径
-
sep:指定列和列的间隔符,默认sep=‘,’
-
若sep=‘’\t",即列与列之间用制表符\t分割,相当于tab——四个空格
-
header:列名行,默认为0
-
names:列名命名或重命名
-
encoding:指定用于unicode文本编码格式
import pandas as pd
# 从CSV文件读取数据
df = pd.read_csv('example.csv',header=None)
print(df)其中 header=None用于告诉Pandas不要将第一行数据解释为列名,而是将其作为数据的一部分。
运行结果:
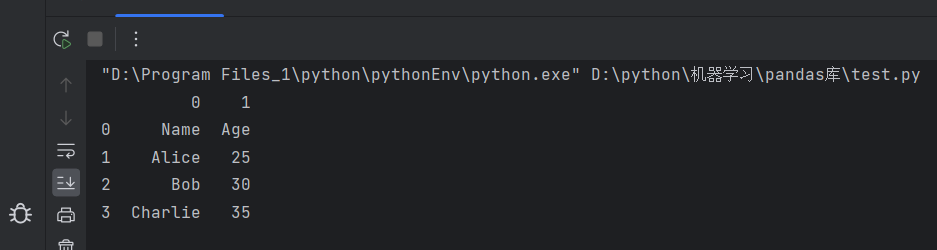
读取Excel文件:
import pandas as pd
# 从Excel文件读取数据
df = pd.read_excel('example.xlsx',header=None)
print(df)
运行结果:
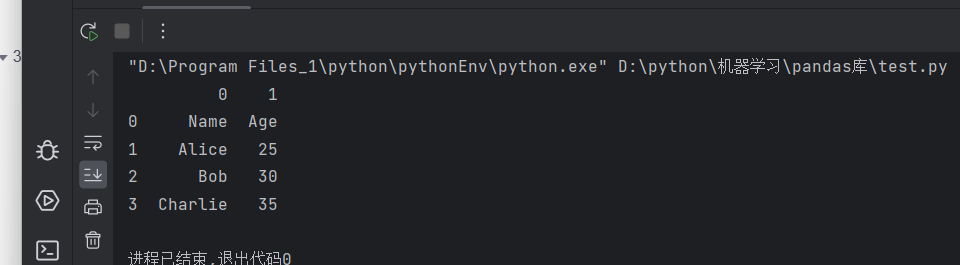
pandas读取xlsx、xls文件
import pandas as pd
data=pd.read_excel('path',sheetname='sheet1',header=0,names=['第一列','第二列','第三列'])
- path:要读取的文件的绝对路径
- sheetname:指定读取excel中的哪一个工作表,默认sheetname=0,即默认读取excel中的第一个工作表
- 若sheetname = ‘sheet1’,即读取excel中的sheet1工作表;
- header:用作列名的行号,默认为header=0
- 若header=None,则表明数据中没有列名行,若header=0,则表明第一行为列名
- names:列名命名或重命名
pandas读取txt文件
read_csv 也可以读取txt文件,读取txt文件的方法同上,也可以用read_table读取txt文件
import pandas as pd
data = pd.read_table('path', sep = '\t', header = None, names = ['第一列','第二列','第三列'])
参考文章:https://book.douban.com/subject/35066598/















 2825
2825











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









