






目录
前提
本项目是对相关购物软件的产品评论进行分类,文本已经进行分类,将文本数据分为优质评论与差评,故直接进行数据准备
1、数据准备与处理
在使用 jieba 分词之前,你需要有一些中文文本数据,这可以是从文件、数据库或其他数据源中获取的文本。确保你的文本数据已经准备好,并且可以在 Python 中进行读取。
cp_content = pd.read_table(r"差评.txt",encoding='gbk')
yzpj_content = pd.read_table(r"优质评价.txt",encoding='gbk')使用pandas库读取准备的文本数据
注:上述数据文本可从上方引用!
2、文本文件分词
cp_segments = []
contents = cp_content.content.values.tolist()
for content in contents:
results = jieba.lcut(content)
if len(results) > 1 :
cp_segments.append(results) 创建一个空列表,用于存储文本数据的分词结果。从读取的“差评.txt”文本中获取相关内容,通过for循环进行遍历迭代,使用jieba库中jieba.cut函数进行分词并将结果储存在results列表中,通过if对所切分的词进行判断,长度大于1的词添加到列表中。
注:后续优质评价文本分词与此处重复,将不再进行解释
results列表保存结果:
![]()
使用debug模式进行调试,可以看到results中保存的数据
3、分词数据转存为Excel
cp_fc_results=pd.DataFrame({'content':cp_segments})
cp_fc_results.to_excel('cp_fc_results.xlsx',index=False)将分词后的数据通过pandas框架保存为一个二维表格型数据,并将该数据写入Excel文件中。此处将index设为False,不将索引保存到Excel表中
Excel表数据结果展示:
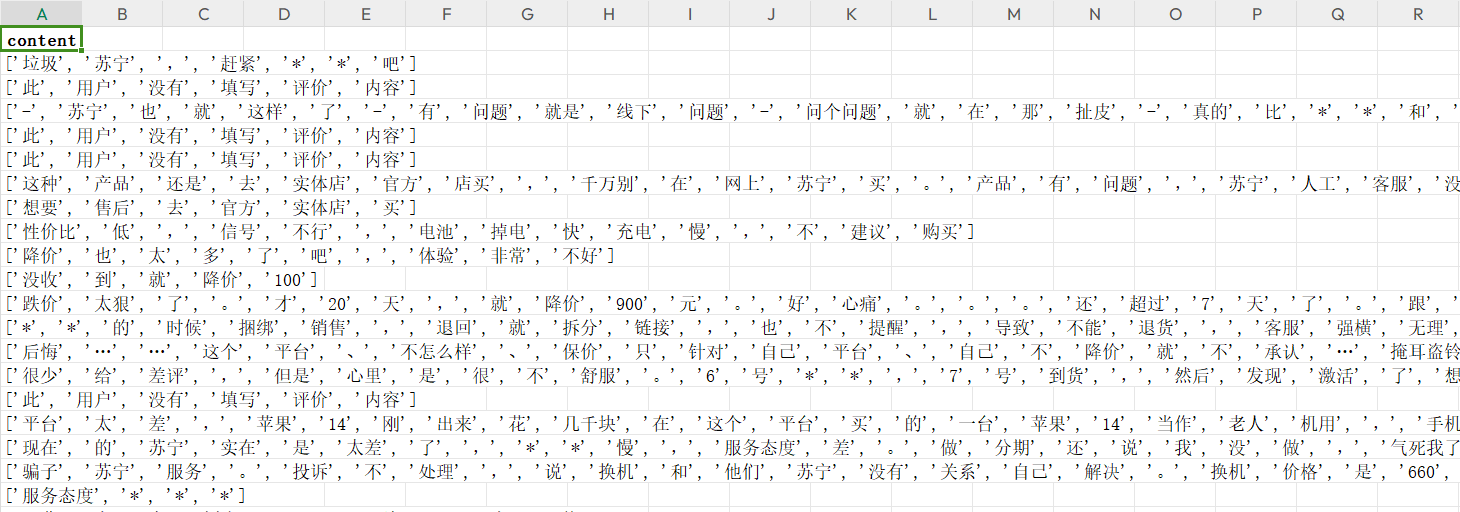
4、移除停用词
4.1、导入停用词库
stopwords = pd.read_csv(r"stop.txt",encoding='utf8', engine='python',index_col=False)将 "stop.txt" 中的停用词数据读取到 stopwords 变量中,以便后续在 Python 中进行处理和使用。停用词通常用于文本处理中的文本清洗或分词等任务,以去除常见但无实际分析意义的词语,从而提高文本处理的效果。
4.2、定义去除停用词函数
def drop_stopwords(contents, stopwords):
segments_clean = []
for content in contents:
line_clean = []
for word in content:
if word in stopwords:
continue
line_clean.append(word)
segments_clean.append(line_clean)
return segments_clean定义两个参数,”contents“为上述处理的评论文本数据,”stopwords“为停用词数据
- segments_clean = []:创建一个空列表,用于存储处理后的文本内容。
- line_clean = []:空列表,用于存储当前文本内容中去除停用词后的词语。
- for word in content:使用嵌套的
“for”循环遍历当前文本内容中的词语。 - line_clean.append(word):如果
“word”不是停用词,就将它添加到“line_clean”列表中,表示这个词语是有效的词汇。 - segments_clean.append(line_clean):在内部循环结束后,将处理后的词语列表
“line_clean”添加到“segments_clean”列表中,表示当前文本内容已经去除了停用词。
4.3、调用停用词函数
contents = cp_fc_results.content.values.tolist() # DataFrame格式转为list格式
stopwords = stopwords.stopword.values.tolist() # 停用词转为list格式
cp_fc_contents_clean_s = drop_stopwords(contents, stopwords)
contents = yzpj_fc_results.content.values.tolist() # DataFrame格式转为list格式
yzpj_fc_contents_clean_s = drop_stopwords(contents, stopwords)将两个不同 DataFrame 中的文本内容提取出来,然后使用停用词函数去除停用词,最终得到去除停用词后的差评文本内容列表 cp_fc_contents_clean_s 和优质评论文本内容列表yzpj_fc_contents_clean_s,分别对应两个不同的文本数据集。这个操作通常用于文本预处理,以准备文本数据用于后续的文本分析或机器学习任务。
移除停用词后展示效果:
差评文本数据:

优质评论文本数据:

5、朴素贝叶斯分类
朴素贝叶斯分类是一种常用的机器学习分类算法,它基于贝叶斯定理进行分类。这个算法的"朴素"之处在于它假设特征之间是相互独立的,这是一个简化的假设,因此称为"朴素贝叶斯"。在本案例中,由于数据都为文本数据,使用朴素贝叶斯分类,可以很好地处理高维稀疏数据,这是文本数据的典型特点。每个词语可以被视为特征,因此文本可以表示为一个高维的特征向量。
5.1、添加数字标签
cp_train=pd.DataFrame({'segments_clean':cp_fc_contents_clean_s,'label':1})
yzpj_train=pd.DataFrame({'segments_clean':yzpj_fc_contents_clean_s,'label':0})
pj_train = pd.concat([cp_train,yzpj_train])
pj_train.to_excel('pj_train.xlsx',index=False)在这里为了创建一个用于文本分类训练的数据集,并将数据保存到 Excel 文件中。
- cp_train = pd.DataFrame({'segments_clean': cp_fc_contents_clean_s, 'label': 1}):创建了一个名为
cp_train的 pandas 数据框架(DataFrame),数据框架包含两列:'segments_clean' 和 'label'。segments_clean 列包含了经过文本处理和去除停用词后的文本内容列表cp_fc_contents_clean_s。label 列用于表示类别标签,这里将所有样本标记为 1,表示差评。 - yzpj_train = pd.DataFrame({'segments_clean': yzpj_fc_contents_clean_s, 'label': 0}):创建了一个名为
yzpj_train的 pandas 数据框架,label列的值标记为0,用于表示优质评论。 - pj_train = pd.concat([cp_train, yzpj_train]):将差评和优质评论的数据按行连接,合并为一个数据集,以便用于文本分类模型的训练。
- pj_train.to_excel('pj_train.xlsx', index=False):将合并后的数据集保存为Excel表文件。
合并后的Excel表数据:
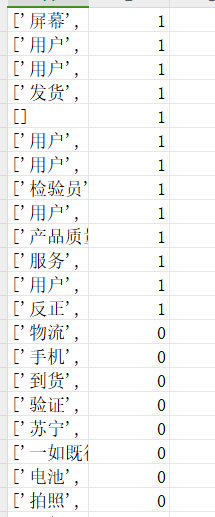
5.2、数据切分
x_train, x_test, y_train, y_test = \
train_test_split(pj_train['segments_clean'].values,
pj_train['label'].values, random_state=0) 使用 Scikit-Learn 库中的 train_test_split 函数将文本分类的训练集(x_train 和 y_train)和测试集(x_test 和 y_test)划分出来,以便进行机器学习模型的训练和评估。
- pj_train['segments_clean'].values:需要划分的特征数据,values将该数据转换为Numpy数组,以便进行后续操作。
- pj_train['label'].values:需要划分的标签数据,表示文本对应的类别标签
5.3、词向量转换
词向量函数CountVectorizer:Scikit-Learn 中用于文本特征提取的函数之一。它的主要作用是将文本数据转换为词袋模型(Bag of Words, BoW)的特征表示,以便用于机器学习模型的训练和分类。
words = [] #转换为词向量CountVectorizer所能识别的列表类型
for line_index in range(len(x_train)):
words.append(' '.join(x_train[line_index]))
print(words)
vec = CountVectorizer(max_features=4000,lowercase = False, ngram_range=(1,1))
vec.fit(words)#在这里仅仅只是得到所有的词库- for line_index in range(len(x_train)):通过循环遍历训练集中的文本数据,其中
x_train是之前划分出的训练集。 - words.append(' '.join(x_train[line_index])):对于每个训练样本,将其内部的文本内容以空格分隔的形式连接起来,并将结果添加到
words列表中 - CountVectorizer(max_features=4000, lowercase=False, ngram_range=(1,1)):文本数据转换为词频向量,max_features=4000指定了词汇表的最大特征数量,表示只考虑最常见的4000个词语。这可以帮助减少特征的维度,提高模型的效率。lowercase=False表示不将文本转换为小写,即保留词语的大小写形式。ngram_range=(1,1)指定了特征的 n-gram 范围,这里为(1,1)表示只考虑单个词语,不考虑词语的组合。
- vec.fit(words):使用
CountVectorizer对象vec对文本数据进行拟合和特征提取。
5.4、导入朴素贝叶斯分类器
classifier = MultinomialNB()
classifier.fit(vec.transform(words), y_train)
train_pr = classifier.predict(vec.transform(words))#训练数据集的测试此处用于训练一个多项式朴素贝叶斯分类器并在训练数据集上进行模型的训练和测试。
- classifier = MultinomialNB():创建一个多项式朴素贝叶斯分类器对象,用于文本分类任务。多项式朴素贝叶斯适用于处理文本数据,特别是词频数据。
- classifier.fit(vec.transform(words), y_train):
vec.transform(words)将文本数据words转换为特征矩阵,这里使用的是之前创建的CountVectorizer对象vec,它会根据训练数据构建词汇表,并将文本数据转换为词频特征。y_train是训练数据集的标签,表示每个文本样本的类别标签。classifier.fit(...)用于训练多项式朴素贝叶斯分类器,通过学习文本特征和标签之间的关系,以便后续进行文本分类。 - train_pr = classifier.predict(vec.transform(words)):
vec.transform(words)用于将相同的训练文本数据words转换为特征矩阵,以便进行预测。classifier.predict(...)用于在训练数据集上进行模型的测试,即对训练数据集进行分类预测。
5.5、相关数据得分分析
test_words = []
for line_index in range(len(x_test)):
test_words.append(' '.join(x_test[line_index]))
test_pr = classifier.predict(vec.transform(test_words))
cm_plot(y_test, test_pr).show()for line_index in range(len(x_test)):进行循环遍历,遍历测试集的每一行test_words.append(' '.join(x_test[line_index])):在每次循环中,将测试集的当前行(预期为单词的列表)用空格连接成一个字符串,然后添加到test_words列表中。classifier.predict(vec.transform(test_words)):首先,vec.transform(test_words)会将test_words中的每个单词转换为向量形式。然后,classifier.predict()函数会使用这些向量进行预测,返回预测的结果(预期为类别的列表)。
6、完整代码及结果
代码部分:
import pandas as pd
cp_content = pd.read_table(r"差评.txt",encoding='gbk')
yzpj_content = pd.read_table(r"优质评价.txt",encoding='gbk')
"""
2.使用jieba分词
"""
# A:对差评分词
import jieba
cp_segments = []
contents = cp_content.content.values.tolist()#将content列数据取出并转化为list格式;目的是分别 jieba.lcut分词
for content in contents:
results = jieba.lcut(content)
if len(results) > 1 :
cp_segments.append(results) #将分词后的内容添加到列表segments中
cp_fc_results=pd.DataFrame({'content':cp_segments})
cp_fc_results.to_excel('cp_fc_results.xlsx',index=False)
# B:对优质评价分词
yzpj_segments = []
contents = yzpj_content.content.values.tolist()#将content列数据取出并转化为list格式。目的是分别 jieba.lcut分词
for content in contents:
results = jieba.lcut(content)
if len(results) > 1 :
yzpj_segments.append(results) #将分词后的内容添加到列表segments中
# #分词结果储存在新的数据框中
yzpj_fc_results=pd.DataFrame({'content':yzpj_segments})
yzpj_fc_results.to_excel('yzpj_fc_results.xlsx',index=False)
"""
# 3.移除停用词
# segments_clean:每一篇文章的分词结果
# all_words:所有文章总的分词结果
"""
#导入停用词库
stopwords = pd.read_csv(r"stop.txt",encoding='utf8', engine='python',index_col=False)
# 定义去除停用词函数
def drop_stopwords(contents, stopwords):
segments_clean = []
for content in contents:
line_clean = []
for word in content:
if word in stopwords:
continue
line_clean.append(word)
segments_clean.append(line_clean)
return segments_clean
# 调用去除停用词函数
contents = cp_fc_results.content.values.tolist() # DataFrame格式转为list格式
stopwords = stopwords.stopword.values.tolist() # 停用词转为list格式
cp_fc_contents_clean_s = drop_stopwords(contents, stopwords)
contents = yzpj_fc_results.content.values.tolist() # DataFrame格式转为list格式
yzpj_fc_contents_clean_s = drop_stopwords(contents, stopwords)
print(yzpj_fc_contents_clean_s)
"""
4.朴素贝叶斯分类
"""
''' 4.1 给每个数据添加数字标签'''
cp_train=pd.DataFrame({'segments_clean':cp_fc_contents_clean_s,
'label':1})
yzpj_train=pd.DataFrame({'segments_clean':yzpj_fc_contents_clean_s,
'label':0})
pj_train = pd.concat([cp_train,yzpj_train])
pj_train.to_excel('pj_train.xlsx',index=False)
#
#
# '''4.2 数据切分 :训练集特征、测试集特征、训练集标签、测试集标签'''
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = \
train_test_split(pj_train['segments_clean'].values,
pj_train['label'].values, random_state=0) #test_size使用默认值
# """4.2 将所有的词转换为词向量"""
words = [] #转换为词向量CountVectorizer所能识别的列表类型
for line_index in range(len(x_train)):
words.append(' '.join(x_train[line_index]))
print(words)
# 导入词向量转化库
from sklearn.feature_extraction.text import CountVectorizer
vec = CountVectorizer(max_features=4000,lowercase = False, ngram_range=(1,1))
vec.fit(words)#在这里仅仅只是得到所有的词库
#
#
# '''4.3 导入朴素贝叶斯分类器'''
from sklearn.naive_bayes import MultinomialNB,ComplementNB
classifier = MultinomialNB()#
classifier.fit(vec.transform(words), y_train)
train_pr = classifier.predict(vec.transform(words))#训练数据集的测试
# 可视化混淆矩阵
def cm_plot(y, yp): #y为真实值,yp为预测值
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
cm = confusion_matrix(y, yp)
plt.matshow(cm, cmap=plt.cm.Blues)
plt.colorbar()
for x in range(len(cm)):
for y in range(len(cm)):
plt.annotate(cm[x, y], xy=(y, x), horizontalalignment='center',
verticalalignment='center')
plt.ylabel('True label')
plt.xlabel('Predicted label')
return plt
cm_plot(y_train, train_pr).show()
#训练集数据预测得分
print(classifier.score(vec.transform(words), y_train))
#测试集数据进行分析
test_words = []
for line_index in range(len(x_test)):
test_words.append(' '.join(x_test[line_index]))
test_pr = classifier.predict(vec.transform(test_words))
cm_plot(y_test, test_pr).show()
#测试集数据预测得分
print(classifier.score(vec.transform(test_words), y_test))结果展示:
词向量列表数据:

数据得分结果:

上方分别为训练集得分和测试集得分结果,总体表现较好















 351
351











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









