






目录
1. sklearn中LinearRegression(最小二乘法)
一、简介
当我们研究一个问题时,通常会涉及到多个自变量(特征)与一个因变量(目标值)之间的关系。多元线性回归是一种统计学和机器学习方法,用于建立多个自变量与一个因变量之间的线性关系模型。
多元线性回归的模型形式为:
y = w1x1 + w2x2 + ... + wn*xn + b
- y是因变量(目标值),是我们要预测的值。
- x1, x2, ..., xn是自变量(特征),是用来预测目标值的输入特征。
- w1, w2, ..., wn是回归系数(斜率),表示自变量对目标值的影响程度。
- b是截距,表示当所有自变量取值为0时,预测的目标值。
在计算机中自变量、参数、因变量如下图所示,其中自变量中主动在原数据中添加了1列,因为恒等于1所以这一列数据只受参数矩阵中的b的影响,就是线性方程中的偏置项。
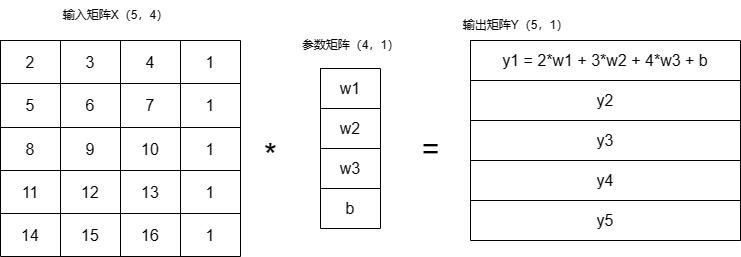
多元线性回归的目标是找到最优的回归系数w1, w2, ..., wn和截距b,使得模型在训练数据上拟合得最好,即预测值与实际目标值之间的误差最小化。
模型的训练过程就是通过拟合训练数据来估计回归系数和截距。一旦模型训练完成,我们就可以使用它来进行预测,给定一组自变量的值,我们可以利用模型来预测相应的目标值。
多元线性回归的优点是简单、易于理解和实现,适用于特征与目标值之间的线性关系。然而,它也有一些限制,例如对于非线性关系的建模,效果较差,对于特征之间存在共线性(相关性)时可能产生过拟合等问题。
在实际应用中,多元线性回归通常用于预测、回归分析和特征重要性评估等任务。如果输入特征之间的关系复杂或存在非线性关系,可能需要使用更复杂的回归模型,例如多项式回归、岭回归、lasso回归等。
1.1 经验总结
y = w1x1 + w2x2 + ... + wn*xn + b
这个函数中x1、x2....输入值为特征数量,训练时和预测时需要保持特征量一致,例如:
现在我需要在图中随意画一下点,得到拟合线,那么我的输入量是多少呢?怎么确定的,训练模型时的输入特征量难道随着我输入的点的增加而增加么?其实只要反着想,就明白了,预测时,我们需要知道某个x对应的y,这就是这条拟合线的作用,然而我们只需要一个特征点x就可以得到y,所以训练输入特征量也为1,那么我们画的点其实就是数据量。
二、参数估计方法
找到最优的回归系数w1, w2, ..., wn和截距b的方式通常涉及最小化某种损失函数,使得模型的预测值与实际目标值之间的误差最小化。在多元线性回归中,最常用的方法是最小二乘法,以及梯度下降法。
- 最小二乘法: 最小二乘法是一种解析方法,通过直接求解正规方程(normal equation)来找到回归系数w1, w2, ..., wn和截距b的最优解。最小二乘法的目标是使得预测值与实际目标值之间的平方误差最小化。这种方法在数据量较小、特征数量较少时较为适用,可以得到全局最优解。在scikit-learn中的LinearRegression类就是使用最小二乘法来进行拟合。
- 梯度下降法: 梯度下降是一种迭代优化算法,通过不断更新回归系数w1, w2, ..., wn和截距b,以减小损失函数(例如均方误差)的值,使预测值与实际目标值之间的误差逐渐减小。梯度下降法可能需要选择合适的学习率和迭代次数,是一种更灵活的方法,适用于大规模数据集和高维度特征。在机器学习领域,梯度下降是常见的优化算法之一,有多个变种,例如批量梯度下降、随机梯度下降、小批量梯度下降等。
选择最优的方法取决于数据集的大小、特征的复杂性和计算资源的可用性。对于小规模数据集和简单的线性回归问题,最小二乘法通常是较好的选择,因为它有解析解,计算速度较快。而对于大规模数据集或更复杂的问题,梯度下降法可能更合适,它可以更好地适应复杂的模型和特征。
三、代码实现
1. sklearn中LinearRegression(最小二乘法)
LinearRegression model_instance
model_instance.fit(x,y)sklearn中LinearRegression的fit函数原理:
在scikit-learn的LinearRegression中,fit方法采用了最小二乘法(Ordinary Least Squares,OLS)来估计模型的参数,而不是梯度下降。最小二乘法直接计算了闭式解,以找到最佳的回归系数,使得预测值与实际目标值之间的残差平方和最小化。
多元线性回归的最小二乘法公式为:
w = (X^T * X)^(-1) * X^T * y
其中:
- w是包含回归系数(w1, w2, ..., wn)和截距(b)的向量。
- X是设计矩阵(m × n),包含m个样本和n个特征的输入特征。
- y是目标向量,包含m个样本的实际目标值。
利用这个公式,LinearRegression类的fit方法直接解决了线性方程组,得到了多元线性回归模型的最优系数和截距,而无需使用梯度下降等迭代优化算法。
2. opencv(最小二乘法)
#include "LinearRegressor.h"
//把字符串转换成数值类型
template<typename T>
T convertStringData(string data)
{
strstream ss;
T y;
ss << data;
ss >> y;
return y;
}
//字符串分割函数
inline vector<string> split(string str, string pattern)
{
string::size_type pos;
vector<string> result;
str += pattern;//扩展字符串以方便操作
int size = str.size();
for (int i = 0; i < size; i++)
{
pos = str.find(pattern, i);
if (pos < size)
{
std::string s = str.substr(i, pos - i);
result.push_back(s);
i = pos + pattern.size() - 1;
}
}
return result;
}
//加载数据
void LinearRegressor::loadDataFromTxt(string filePath, string regx)
{
ifstream fin(filePath);
while (!fin.eof())
{
string temp;
getline(fin, temp);
if (strcmp(temp.c_str(), "") == 0) continue;
vector<string> resStr = split(temp, regx);
//设置x的维数
m_dim = resStr.size() - 1;
double yi = convertStringData<double>(resStr[resStr.size() - 1]);
m_Y.push_back(yi);
Mat data = Mat::zeros(1, m_dim, CV_32FC1);//临时存放每一行的数据
for (int i = 0; i < m_dim; i++){
data.row(0).col(i) = convertStringData<double>(resStr[i]);
}
m_originalX.push_back(data);
}
m_X = Mat::ones(m_originalX.rows, m_dim + 1, CV_32FC1);
m_originalX.copyTo(m_X.colRange(1, m_X.cols));
m_X.col(0) = Mat::ones(m_X.rows, 1, m_X.type());
m_coefficients = Mat::zeros(m_dim + 1, 1, m_originalX.type());
fin.close();
}
void LinearRegressor::genarateRandomData(int row, int col) {
// 设置随机数种子,保证结果可复现
cv::theRNG().state = 42;
// 生成随机数据,输入矩阵
cv::Mat X_train(row, col, CV_64F);
cv::randu(X_train, cv::Scalar::all(0), cv::Scalar::all(1)); // 生成0到1之间的随机数
m_originalX = X_train;
// 输出矩阵
cv::Mat y_train = 10 * X_train.col(0) + 5 * X_train.col(1) + 8 * X_train.col(2) + 15 * X_train.col(3) +
20 * X_train.col(4) + 3 * X_train.col(5) + 7 * X_train.col(6) +
cv::Mat(X_train.rows, 1, CV_64F, cv::Scalar::all(0)); // 假设的线性关系,加上一些噪声
m_Y = y_train;
// 在输入特征中添加一列1,用于计算截距b
cv::Mat X_train_with_intercept;
cv::hconcat(X_train, cv::Mat::ones(X_train.rows, 1, CV_64F), X_train_with_intercept);
m_X = X_train_with_intercept;
}
// 模型训练-最小二乘法公式:w = (X^T * X)^(-1) * X^T * y
void LinearRegressor::fit(cv::Mat XTrain, cv::Mat YTrain, bool ifBias) {
m_X = XTrain;
m_Y = YTrain;
m_dim = XTrain.cols;
// 计算时导入偏置项bias
if (ifBias) {
// 在输入特征中添加一列1,用于计算截距b
cv::Mat X_train_with_intercept;
cv::hconcat(XTrain, cv::Mat::ones(XTrain.rows, 1, CV_64F), X_train_with_intercept);
m_X = X_train_with_intercept;
}
// 使用OpenCV的solve函数求解最小二乘法的解
cv::solve(m_X.t() * m_X, m_X.t() * m_Y, m_coefficients);
m_bias = m_coefficients.at<double>(m_coefficients.cols - 1, 0);
}
void LinearRegressor::saveModel(const std::string& absolutePath) {
cv::FileStorage fs(absolutePath, cv::FileStorage::WRITE);
fs << "coefficients" << m_coefficients;
fs << "dim" << m_dim;
fs.release();
}
bool LinearRegressor::loadModel(const std::string& absolutePath) {
try
{
cv::FileStorage fs(absolutePath, cv::FileStorage::READ);
fs["coefficients"] >> m_coefficients;
fs["dim"] >> m_dim;
fs.release();
return true;
}catch (const std::exception&)
{
printf("加载模型失败");
return false;
}
}
//数据返回
Mat& LinearRegressor::getOriginX(){
return m_originalX;
}
Mat& LinearRegressor::getY()
{
return m_Y;
}
Mat& LinearRegressor::getX(){
return m_X;
}
Mat& LinearRegressor::getCoefficients(){
return m_coefficients;
}
double LinearRegressor::getBias(){
return m_bias;
}
int LinearRegressor::getDim() {
return m_dim;
}
//特征归一化
void LinearRegressor::featureNormalize(Mat& ex)
{
if (ex.cols <= 2) return;//只有一个特征的时候不用归一化
for (int col = 1; col < ex.cols; col++)
{
Mat mean;
Mat stddev;
meanStdDev(ex.col(col), mean, stddev);
//归一化
ex.col(col) = ex.col(col) - mean;
ex.col(col) = ex.col(col) / stddev;
}
}
//预测
//x:一个样本
//theta 训练得到的参数
double LinearRegressor::predict(Mat& x)
{
Mat hx;
calculateHx(x, this->getCoefficients(), hx);
return hx.at<double>(0, 0);
}
//计算假设函数
void LinearRegressor::calculateHx(Mat& x, Mat& theta, Mat& Hx)
{
Hx = x * theta;
}#ifndef _Regression_H_
#define _Regression_H_
#include <vector>
#include <string>
#include <iostream>
#include <strstream>
#include <fstream>
#include <opencv2\core\core.hpp>
using namespace cv;
using namespace std;
class LinearRegressor
{
public:
//加载数据
void loadDataFromTxt(string filePath, string regx);
//数据返回
Mat& getOriginX();
Mat& getX();
Mat& getCoefficients();
double getBias();
Mat& getY();
int getDim();
//特征归一化
void featureNormalize(Mat& x);
//预测
double predict(Mat& x);
//假设函数,此处设成静态函数,是方便在其他类中直接调用
static void calculateHx(Mat& x, Mat& theta, Mat& Hx);
//生成随机数
void genarateRandomData(int row,int col);
//模型训练,最小二乘法
void fit(cv::Mat XTrain, cv::Mat YTrain, bool ifBias = true);
//保存模型
void saveModel(const std::string& filename);
//读取模型
bool loadModel(const std::string& filename);
private:
Mat m_originalX; // 不含偏置b
Mat m_X; //含偏置b
Mat m_Y;
int m_dim = 0;//数据维数
Mat m_coefficients;//系数(w与b)
double m_bias = 0;
};
#endif测试代码,也可以使用genarateRandomData直接生成随机测试代码
// 设置随机数种子,保证结果可复现
cv::theRNG().state = 42;
// 生成随机数据
cv::Mat X_train(50, 7, CV_64F);
cv::randu(X_train, cv::Scalar::all(0), cv::Scalar::all(1)); // 生成0到1之间的随机数
cv::Mat Y_train = 10 * X_train.col(0) + 5 * X_train.col(1) + 8 * X_train.col(2) + 15 * X_train.col(3) +
20 * X_train.col(4) + 3 * X_train.col(5) + 7 * X_train.col(6) +
cv::Mat(X_train.rows, 1, CV_64F, cv::Scalar::all(0)); // 假设的线性关系,加上一些噪声
// LinerRegresion model fit
m_linearRegressor.fit(X_train, Y_train);
// 提取回归系数和截距
Mat coefficients = m_linearRegressor.getCoefficients();
// 打印结果
for (int i = 0; i < coefficients.rows-1; i++)
qDebug() << "回归系数 (斜率): " << coefficients.at<double>(i, 0);
qDebug() << "截距: " << m_linearRegressor.getBias();
m_linearRegressor.saveModel("D:/workspace/TBI_Capture/algorithm/models/LinerRegression.xml");
cv::solve()函数
函数作用:
solve(A,B,w)矩阵计算出 wA=B 中的w
- src1:输入矩阵,通常是方阵。
- src2:输入向量或矩阵。
- dst:输出结果,是src1 * dst = src2的解。
- flags:可选参数,用于指定解线性方程组的方法,默认是cv::DECOMP_LU,表示使用LU分解法。
3.opencv(梯度下降
多元线性回归OpenCV代码_Ch-e-r-i-s-h的博客-CSDN博客
















 151
151











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











