







目录
序言
1. 整体模型架构
1.1. 论文原始图编辑
1.2. 精简图
2. transformer输入
2.1. 词embedding
2.2. 位置embedding
3. Encoder
3.1. 输入
3.2. Multi-Head Attention
3.3. add&norm
3.4. Feed Forward
3.5. 多层编码器堆栈
5. Decoder
5.1. 训练
5.1.1. 训练方法
5.1.2. 输入
5.1.3. Maskd Multi-HeadAttention
5.1.4. cross attention(注意这里不是Masked Multi-head-attention)
5.1.5. 输出
5.2. 推理
5.2.1. 推理过程示意图
5.2.2. 对比encoder和decoder的输入方式
5.2.3. 图解:训练与推理输入不同却等价原因
5.2.3.1. 分析encoder输入
5.2.3.2. 分析teacher forcing的推理输入
5.2.4. 推理模式变种
5.2.4.1. 输出序列长度不和输入等长
5.2.4.2. transformer做回归任务
5.2.5. cross attention
6. 心得
6.1. 全连接网络与矩阵之间的关系
6.2. 问题记录:
6.3. tips
6.4. 思考
6.4.1. 一个值得注意的地方
序言
其实在观看本博客前建议先看一下李宏毅老师的视频作为本博客的铺垫,看完后可以来阅读此博客,你将会对transformer有更加深刻,深入的认识,本博客会贯穿一个例子通过图解的方式更直观地展现transformer的一些较为抽象的地方。尤其是decoder部分,我相信你一定非常苦恼网上decoder部分的教程如此之少还懵懵懂懂,通过本博客你可以详细了解它。
李宏毅老师的视频
Transformer终于有拿得出手得教程了! 台大李宏毅自注意力机制和Transformer详解!通俗易懂,草履虫都学的会!_哔哩哔哩_bilibili
一些比较好的学习博客
层层剖析,让你彻底搞懂Self-Attention、MultiHead-Attention和Masked-Attention的机制和原理_masked attention-CSDN博客
pytorch中transformer模型的使用(非原理)
1. 整体模型架构
1.1. 论文原始图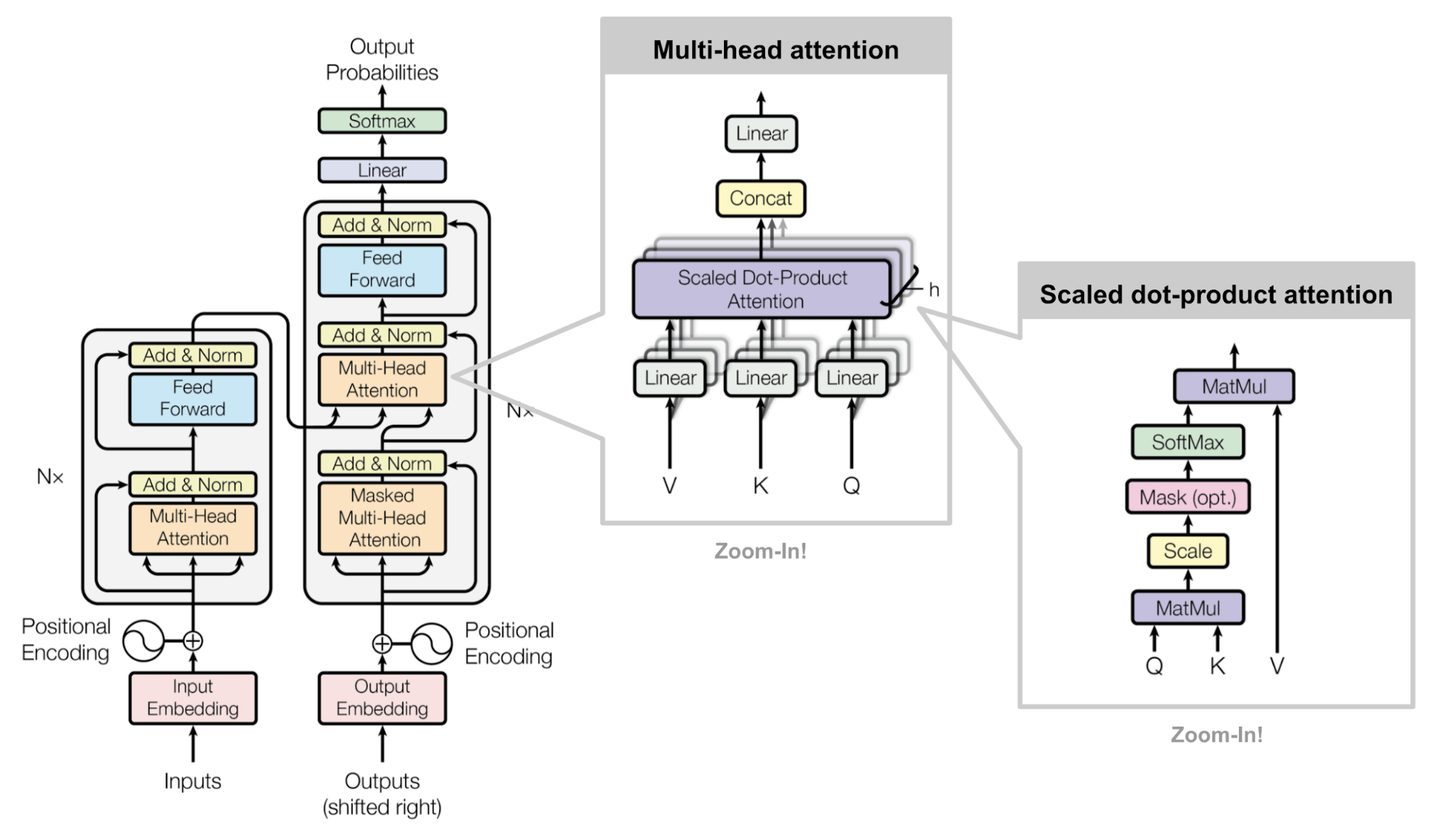
这是Attention Is All You Need论文原始图像,先放在这里,方便查看,后面将详细展开模型中的模块
1.2. 精简图
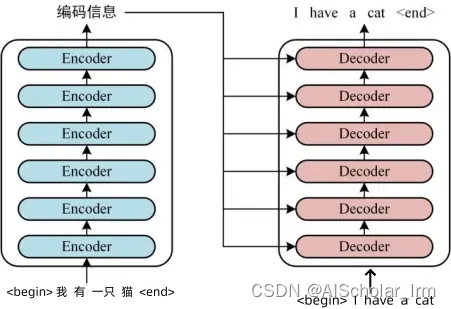
这是上面详细图的一个展开图,把Nx部分展开了,并且我们可以看到左边Nx每个部分都叫一个encoder,同理右边叫Decoder,我们整篇文章将会围绕着一个翻译“我有一只猫”作为例子展开所有细节(这里的tokens中的<begin><end>都是很有讲究的哦,注意看清楚)
2. transformer输入
2.1. 词embedding
注意:建议先别看这部分内容,我们只要知道我们输入的数据转换成了一个输入矩阵就可以了,等将整个流程理解了再来看是如何转换的即可。
【python函数】torch.nn.Embedding函数用法图解-CSDN博客
我们在翻译输入时都需要将我们的输入文字转换成一个词嵌入矩阵,上面这个博客讲的已经非常清楚了,我再来概括一下。
说白了就是创建了一个矩阵存储了所有文本的内容,比如一篇文章100个词汇,那么可以创建一个(100,8)的矩阵存储他们,每一行表示一个词汇,并且每个词汇在第几行都是确认的,当我们想要拿出我这个词的时候利用一个(1,100)的one-hot矩阵(这个矩阵数值为1的位置正好对应embedding矩阵中这个词对应的位置)与这个embedding矩阵叉乘就拿出了这个词的词嵌入表示。
2.2. 位置embedding
位置嵌入部分理解起来会比词嵌入部分困难一点。下面有几个博客写的不错,我们可以看一下。
如何优雅地编码文本中的位置信息?三种positional encoding方法简述
Transformer学习笔记一:Positional Encoding(位置编码)
首先我们要知道positional encoding和input embedding其实是两个矩阵相加的关系,所以我们通过positioanl embedding也会得到一个和词嵌入input embedding一样大小的矩阵。
相信在上面的文章中我们都看到了很多不一样的位置表示方式,及其优劣,其中很重要的两个点就是绝对位置表示和相对位置表示,因为当我们输入一段文字的时候我们需要这个词汇在整句话或者整篇文章中的绝对位置,还有某个词汇和其他的相对位置
我们最先想到的就是用0,1,2,3去直接定义他们的位置关系,问题就是,我们训练时候最多用到了99,我们现在输入一个长度是133的文本进来,这个数字神经网络以前是没见过的,那就容易出问题,用[0,1]之间的数分配每个词汇会让每一次训练、推理文本间隔都不一致。
这个时候我们可以采用多个维度同时表示,怎么操作呢,举个例子,我们想告诉神经网络我这个token绝对位置,我们又希望输入的数据一只都在一定的范围内,因为你要是输入一个100000,神经网络之前没见过,泛化能力就不强,通过引入sin函数让输出结果限制在0-1之间,然后i就相当于一个旋钮,最终虽然每一列得到了都是0-1之间的小数,但是含义可能都是不相同的,i=1那一列距离单位可能是0.001,i=4那一列可能就是1000,这样这些数据经过一个全连接相乘再相加后便得到了它对应的绝对位置。这是只有sin函数的情况下,selef-attention的作者为了引入相对位置加入了cos列,怎么做呢?
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 997
997

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











