









 本文介绍了k最近邻(kNN)算法的基本原理和在文本分类中的应用,强调了距离函数的选择(如欧氏距离和余弦距离)以及归一化的必要性。在C#实现中,通过泛型类设计了一个通用的kNN算法,允许用户自定义数据类型和距离计算。kNN算法的优点包括高准确率、实现简单、对异常值不敏感,但也存在存储需求大、计算复杂度高和k值选择的问题。
本文介绍了k最近邻(kNN)算法的基本原理和在文本分类中的应用,强调了距离函数的选择(如欧氏距离和余弦距离)以及归一化的必要性。在C#实现中,通过泛型类设计了一个通用的kNN算法,允许用户自定义数据类型和距离计算。kNN算法的优点包括高准确率、实现简单、对异常值不敏感,但也存在存储需求大、计算复杂度高和k值选择的问题。
kNN算法又称为k最近邻算法,是各种分类算法中较简单的一种(有可能是最简单的)。他的思路很好理解,即将待分类向量和所有已知向量求距离,再统计k个最小距离向量所属的类型,最多的类型即为待分类向量的类型。虽然简单,但它的效果却不差,kNN具有较高的准确度,对outliers不敏感,同时对所用的数据类型没有任何要求,使用非常简单。目前kNN常用在文本分类等任务中。
在kNN算法中,最重要的也许就是距离函数了,一般常用欧氏距离作为两个向量的度量:
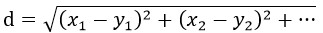
但这不是一定的,可以用来度量距离的函数有很多,比如在文本分类的应用中,常用的就是余弦距离:
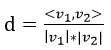
在实际使用kNN的过程中,归一化是必须注意的。由于kNN对数据没有要求,因此不同向量元素间的取值差异可能很大,取值大的元素权重就大,削弱了其他元素的作用,导致分类效果劣化。如下,第一项和第三项的值几乎可以忽略了:
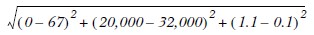
归一化方法也很多,不过最简单也最常用的就是下式所定义的计算方法:
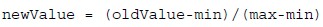
其中min和max分别是所有向量中该元素的最小值和最大值,oldValue是该元素的原始值,newValue是该元素归一化后的值。
另外,用于训练的不同类别的样本数量要尽可能相等,这样才不会在计算距离和投票时,某一类别由于样本数目较多而占优势。
最近由于项目原因,常使用C#,因此习惯性的用C#来写一些东西。kNN对数据类型没有要求,距离函数也可以有很多种,因此要实现一个通用的kNN算法,最好的选择就是将其写为一个C#中的泛型类,该泛型类有两个泛参,TVector和TLabel。TVector是用户自己定义的数据类型,TLabel是分类标签,可以是数字,也可以是字符串等等。在调用分类方法Classify时,需要提供一个用户自己定义的距离函数,最后的分类结果以标签(TLabel)的形式返回。时间紧张,代码拙劣,请谅解。
public class KNN<TVector, TLabel> where TLabel : IComparable
{
public TVector[] DataSet
{
get;
private set;
}
public TLabel[] LabelSet
{
get;
private set;
}
public delegate double DistanceFunction(TVector source, TVector destination);
public void Train(TVector[] samples, TLabel[] labels)
{
if (samples.Length != labels.Length)
throw new ArgumentException("Different length of labels and training_data!");
DataSet = new TVector[samples.Length];
LabelSet = new TLabel[labels.Length];
samples.CopyTo(DataSet, 0);
labels.CopyTo(LabelSet, 0);
}
Dictionary<TLabel, int> m_voting_table = new Dictionary<TLabel, int>(new DicCmp<TLabel>());
public TLabel Classify(TVector vector, int k, DistanceFunction dist_func)
{
if (DataSet == null)
throw new MemberAccessException("There's no vectors in DataSet");
if (k > DataSet.Length)
throw new ArgumentException("The value of k is greater than the vectors' count");
//Calculate distances for all vectors in the dataset
KeyValuePair<TLabel, double>[] label_dist_pair = new KeyValuePair<TLabel, double>[DataSet.Length];
for (int i = 0; i < DataSet.Length; ++i)
{
double dist = dist_func(vector, DataSet[i]);
label_dist_pair[i] = new KeyValuePair<TLabel, double>(LabelSet[i], dist);
}
//Sort via distance.
Array.Sort(label_dist_pair, new SortCmp<TLabel>());
//Do majority voting from the k-nearest neighbors.
m_voting_table.Clear();
for (int i = 0; i < k; ++i)
{
if (m_voting_table.ContainsKey(label_dist_pair[i].Key))
{
m_voting_table[label_dist_pair[i].Key]++;
}
else
{
m_voting_table.Add(label_dist_pair[i].Key, 1);
}
}
//Find out the maximum-frequency label. And that is our result.
int max_freq = 0;
TLabel label_to_return = LabelSet[0];
foreach (var item in m_voting_table)
{
if (item.Value > max_freq)
{
max_freq = item.Value;
label_to_return = item.Key;
}
}
return label_to_return;
}
}最后总结一下kNN的优缺点。
优点:
1、准确率高;
2、实现简单;
3、对outliers不敏感,因为使用多数投票方式决定分类结果;
4、对数据类型无要求,使用灵活方便;
缺点:
1、所需存储空间大,需要将所有训练数据保存起来;
2、计算量大,每一次分类都要遍历一遍所有数据,且对每一对向量都要求距离;
3、对k值的选择没有很好的方法,一般通过实验方式得到k值;

















 2182
2182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









