







0. 简单介绍
FHQ Treap,以下简写为fhq,是一种treap(树堆)的变体,功能比treap强大,代码比splay好写,易于理解,常数稍大.
fhq不需要通过一般平衡树的左右旋转来保持平衡,而是通过分裂split和合并merge来实现操作.
本文力求简明易懂,在看本文前最好先了解过一种平衡树的基本写法,否则代码部分有可能看不懂.
1. 前置操作
置渲染成一坨了 现在修好了
结构
以结构体作为树的每一个节点,存储左子树和右子树的位置,权值,堆权值(用处在下面会说)和子树大小.一般子树大小用于查排名和查值.
root是树根编号,idx是点的编号,x,y,z在下面会用到.
struct Node {
int l, r; // 左右子树编号
int key, val; //key权 val堆权
int size; //子树大小
} tr[N];
int root, idx;
int x, y, z;
fhq和treap一样满足treap的性质,也就是既是BST,又是随机权值的堆.
至于为什么满足堆的性质的BST就能平衡,有如下定理保证:
- 一颗有n个不同关键字随机构建的BST的期望高度为 l o g n logn logn.
随机堆的权值正是模拟了随机构建BST,所以treap是平衡的,同理fhq也平衡.
但是事实上fhq按照这种结构并不是一个标准的BST,后面我会解释.
创建节点和更新子树大小
int get_node(int key) {
tr[++idx].key = key;
tr[idx].val = rnd();
tr[idx].size = 1;
return idx;
}
void update(int p) {
tr[p].size = tr[tr[p].l].size + tr[tr[p].r].size + 1;
}
子树大小由两侧子树和根节点更新.
rnd()为随机值产生函数,需要导入random库,在开头写下如下代码:
std::mt19937 rnd(233); //高性能随机数生成器 随机范围大概在(maxint,+maxint),233为种子,19937指该随机数循环节为2^19937
分裂 s p l i t split split
split操作按key将树由根root开始将树分为两颗x,y,其中x子树中的权值<=key,y中子树的权值>key.下面的x和y都以此为标准.

split的操作如下
- 递归遍历左右子树
- 如果当前节点值<=key,则前当前节点及其左子树都可以放到x上,右子树中可能有可以放到x上的(<=key),继续递归
- 如果当前节点值 > key,则前当前节点及其右子树都可以放到y上,左子树中可能有可以放到y上的( > key),继续递归
- 若当前节点为0,说明为空,令x = y = 0,返回
注意这个操作中x和y都是引用,每一层的x和y都表示一层中的树的根节点.
//将p子树以按key拆成x和y子树,其中x中的点<=key,y中全部大于key
void split(int p, int key, int &x, int &y) {
if (!p)
x = y = 0;
else {
if (tr[p].key <= key) { //当前节点小,放x上
x = p; //x上暂时放的p子树,还要去看p的右子树
split(tr[p].r, key, tr[p].r, y); //去看p右子树,如果有小于key的(大于根)则应该保留在p右子树上(最后给x),否则放在y上
} else {
y = p;
split(tr[p].l, key, x, tr[p].l); //去看p左子树,如果有>=key的则应该放在p左子树上(最后给y),否则放在x上
}
update(p);//写在else里面,防止更新0点(否则0点size++,所有结果都不对)
}
}
合并 m e r g e merge merge
merge操作按照堆权合并x,y两颗子树,合并前要保证x子树中的权值<y子树中的权值
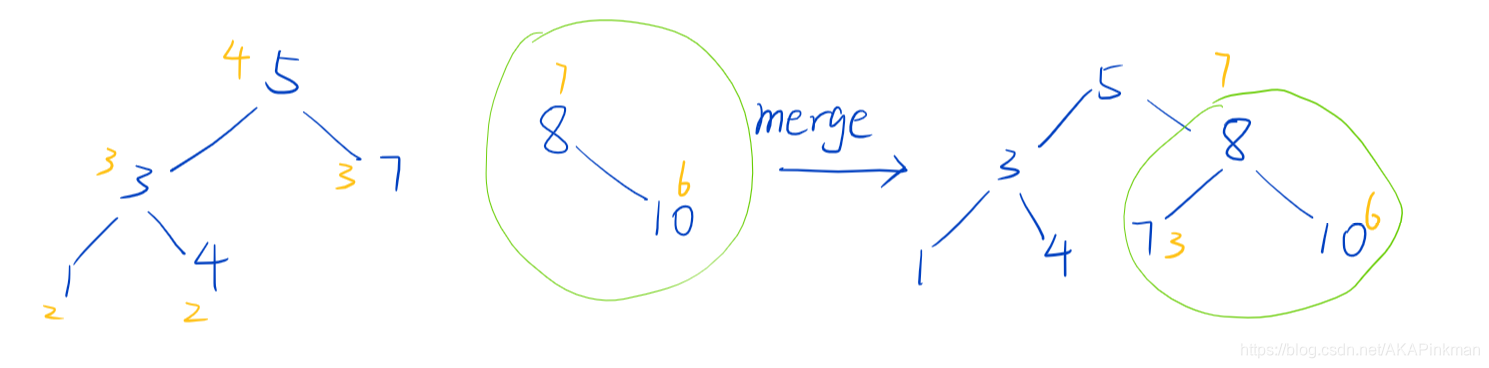
图中黄字为堆权,可以看到8如果直接合并在7的右侧深度会变为4,而根据堆权来看,8堆权为7,7的堆权为3,故排在7的上面,所以如此合并后树仍然平衡.
//合并x,y子树,其中x子树的值<=y子树的值
int merge(int x, int y) {
if (!x || !y) return x + y; //x = 0答案是y,y = 0答案是x,也就是如果有一个子树为空则返回另一个子树
if (tr[x].val > tr[y].val) { //x在堆中是在y的上方,而值小于y,故在y的左上方
tr[x].r = merge(tr[x].r, y); //让x的右子树和y合并
update(x);
return x;
} else { //x在y的左下方
tr[y].l = merge(x, tr[y].l); //x和y的左子树合并
// 不能写成merge(tr[y].l,x) 必须满足x < y
update(y);
return y;
}
}
2. 一般操作
i n s e r t insert insert
插入值为key的节点,只需要将树按key划分(x<=key,y>key),让x树和新节点key合并,再和y后合并即可.
注意:fhq中没有相同节点记录,也就是同值的节点会多次添加,所以不是一颗严格的BST,可能会增加树高.但是这不影响我们划分出x和y.文末会给出记录重复节点的写法.
void insert(int key) {
split(root, key, x, y); //按k分割
root = merge(merge(x, get_node(key)), y); //在x与key节点合并,再与key合并
}
d e l e t e delete delete
删除值为key的节点,将树划分两次,一次按原树以key划分为(x,z),一次按x树以key-1划分为(x,y),那么中间那颗树y上的节点值都为key.
在y上删除一个节点即可,可以选择根节点删除,而删根节点只需要让根节点等于左右子树合并即可(根就没了).最后再合并起来
void del(int key) {
split(root, key, x, z);
split(x, key - 1, x, y);
//x<=key ,再分x <= key - 1,y就是=key的树
y = merge(tr[y].l, tr[y].r); //删除y点(根)
root = merge(merge(x, y), z); //合并x,y,z
}
g e t _ r a n k _ b y _ k e y get\_rank\_by\_key get_rank_by_key
按值查排名,按key-1划分为x,y,x树大小+1就是排名
//按值查排名
int get_rank(int key) {
split(root, key - 1, x, y); //按key-1分割,x子树大小+1就是排名
key = tr[x].size + 1; //储存x的大小+1
root = merge(x, y);
return key;
}
g e t _ k e y _ b y _ r a n k get\_key\_by\_rank get_key_by_rank
按排名查值,搜索
//按排名查值
int get_key(int rank) {
int p = root;
//循环写法
while (p) {
if (tr[tr[p].l].size + 1 == rank)
break; //找到排名了
else if (tr[tr[p].l].size >= rank)
p = tr[p].l; //当前size>=rank,去左子树
else {
//去右子树中找rank -= 左子树大小+1(根)的排名
rank -= tr[tr[p].l].size + 1;
p = tr[p].r;
}
}
return tr[p].key;
}
p r e pre pre
//返回<key的最大数
int get_prev(int key) {
//按key-1分,x最右节点就是前驱
split(root, key - 1, x, y);
int p = x;
while (tr[p].r) p = tr[p].r; //向右走
key = tr[p].key; //临时存储
root = merge(x, y);
return key;
}
n e x t next next
//返回>key的最小数
int get_next(int key) {
split(root, key, x, y); //按key分y最左节点是后继
int p = y;
while (tr[p].l) p = tr[p].l;
key = tr[p].key;
root = merge(x, y);
return key;
}
例题
您需要写一种数据结构(可参考题目标题),来维护一些数,其中需要提供以下操作:
- 插入 x x x 数
- 删除 x x x 数(若有多个相同的数,因只删除一个)
- 查询 x x x 数的排名(排名定义为比当前数小的数的个数 +1 )
- 查询排名为 x x x 的数
- 求 x x x 的前驱(前驱定义为小于 x x x,且最大的数)
- 求 x x x 的后继(后继定义为大于 x x x,且最小的数)
AC代码
#include <iostream>
#include <random>
#define print(a) printf("%d\n",a)
using namespace std;
const int N = 1e5 + 10;
std::mt19937 rnd(233);
struct Node{
int l,r;
int key,val,size;
}tr[N];
int x,y,z;
int root,idx;
void update(int p){
tr[p].size = tr[tr[p].l].size + tr[tr[p].r].size + 1;
}
int get_node(int key){
tr[++ idx].key = key;
tr[idx].val = rnd();
tr[idx].size = 1;
return idx;
}
void split(int p,int key,int &x,int &y){
if(!p) x = y = 0;
else{
if(tr[p].key <= key){
x = p;
split(tr[p].r,key,tr[p].r,y);
}else{
y = p;
split(tr[p].l,key,x,tr[p].l);
}
update(p);
}
}
int merge(int x,int y){
if(!x || !y)return x + y;
if(tr[x].val > tr[y].val){
tr[x].r = merge(tr[x].r,y);
update(x);
return x;
}else{
tr[y].l = merge(x,tr[y].l);
update(y);
return y;
}
}
void insert(int key){
split(root,key,x,y);
root = merge(merge(x,get_node(key)),y);
}
void del(int key){
split(root,key,x,z);
split(x,key - 1,x,y);
y = merge(tr[y].l,tr[y].r);
root = merge(merge(x,y),z);
}
void get_rank(int key){
split(root,key - 1,x,y);
print(tr[x].size + 1);
root = merge(x,y);
}
void get_key(int rank){
int p = root;
while(p){
if(tr[tr[p].l].size + 1 == rank){
break;
}else if(tr[tr[p].l].size >= rank){
p = tr[p].l;
}else{
rank -= tr[tr[p].l].size + 1;
p = tr[p].r;
}
}
print(tr[p].key);
}
void get_prev(int key){
split(root,key-1,x,y);
int p = x;
while(tr[p].r)p = tr[p].r;
print(tr[p].key);
root = merge(x,y);
}
void get_next(int key){
split(root,key,x,y);
int p = y;
while(tr[p].l)p = tr[p].l;
print(tr[p].key);
root = merge(x,y);
}
int main(){
int n;
scanf("%d",&n);
int op,x;
while(n --){
scanf("%d%d",&op,&x);
if(op == 1)insert(x);
else if (op == 2)del(x);
else if (op == 3)get_rank(x);
else if (op == 4)get_key(x);
else if (op == 5)get_prev(x);
else get_next(x);
}
}
3. 文艺操作
待更新…

















 951
951

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









