






YOLOv9的最新创新点,截至2024年2月26日,公开信息中提到YOLOv9在目标检测领域实现了SOTA(state-of-the-art)性能,并且在实时性方面表现优秀,超过了RT-DETR、YOLOv8等先前版本和竞品。然而,具体的创新点细节没有直接提供。
gui界面 与交互式选择按钮!如下
YOLO系列模型通常会在以下几个方面进行迭
代和创新:
- 网络结构优化:可能会引入新的或改进的模块,比如E-ELAN模块,或者对Backbone架构进行改进以增强特征提取能力。
- 缩放方法:YOLOv7中提出的基于拼接模型的缩放方法可能也被应用到YOLOv9中,使得模型能够更灵活地适应不同的计算资源和精度需求

- 全局上下文建模:借鉴Global Context Block或其他全局注意力机制来提升对图像全局信息的利用,从而提高检测精度。
- 重参数化卷积(RepConvN):YOLOv7中使用了重参数化卷积应用于残差模块,YOLOv9可能进一步发展了这一技术。
- 轻量化与效率:结合Ghost卷积、转置卷积以及高效通道注意力机制如ECA等实现模型的轻量化和加速,同时保持甚至提升检测性能。
- 信息损失减少:针对输入数据逐层处理导致的信息丢失问题,YOLOv9可能会提出新的策略来保留或恢复重要信息。
至于YOLOv9的实际效果图,由于没有具体资料展示,通常这类深度学习目标检测模型的效果图会包括多个示例,显示模型对不同场景下各类物体的准确检测框及其类别标注。
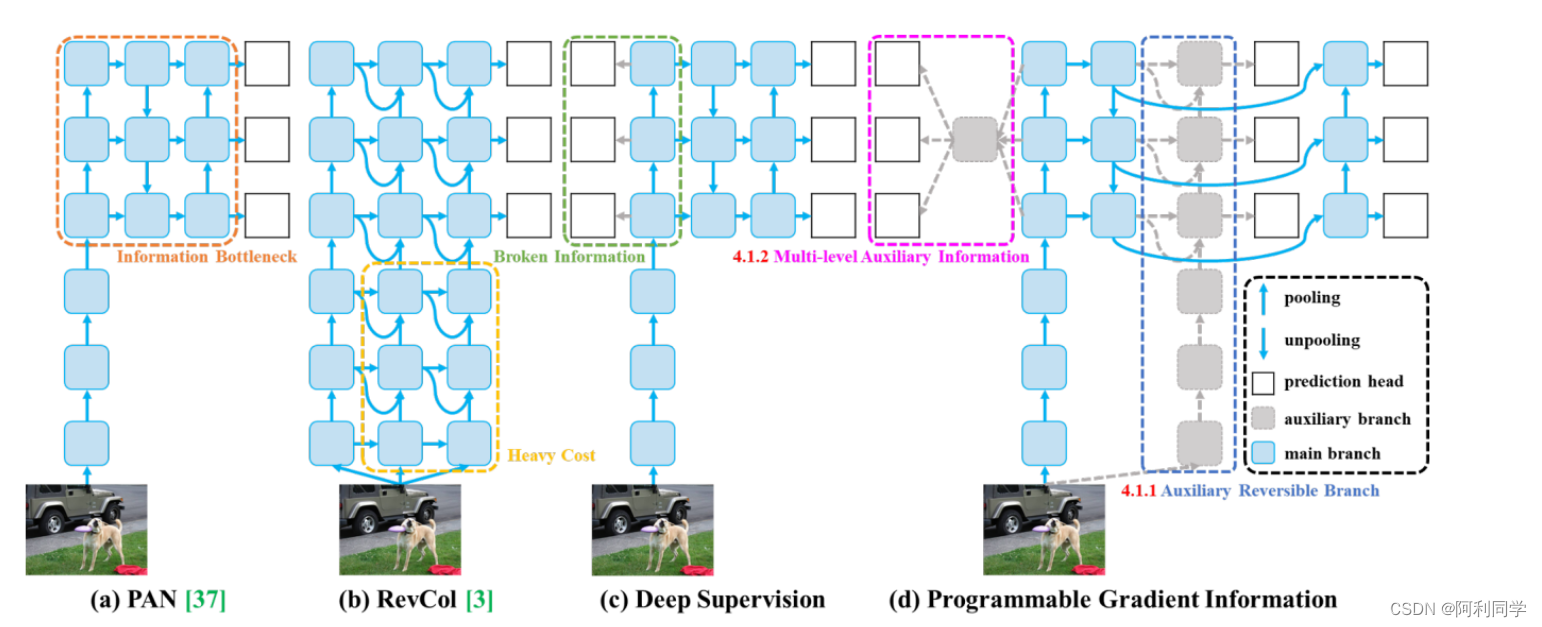
性能至于YOLOv9的实际效果图,由于没有具体资料展示,通常这类深度学习目标检测模型的效果图会包括多个示例,显示模型对不同场景下各类物体的准确检测框及其类别标注。
在MS COCO数据集上的表现
| 模型 | 测试图像尺寸 | APval(所有IoU) | AP50val(IoU=0.5) | AP75val(IoU=0.75) | 参数量(M) | FLOPs(G) |
|---|---|---|---|---|---|---|
| YOLOv9-S | 640 | 46.8% | 63.4% | 50.7% | 7.2 | 26.7 |
| YOLOv9-M | 640 | 51.4% | 68.1% | 56.1% | 20.1 | 76.8 |
| YOLOv9-C | 640 | 53.0% | 70.2% | 57.8% | 25.5 | 102.8 |
| YOLOv9-E | 640 | 55.6% | 72.8% | 60.6% | 58.1 | 192.5 |
有用链接
展开
安装指南
推荐使用Docker环境
展开
评估方法
- yolov9-c.pt
- yolov9-e.pt
- gelan-c.pt
- gelan-e.pt
评估YOLOv9模型
python val_dual.py --data data/coco.yaml --img 640 --batch 32 --conf 0.001 --iou 0.7 --device 0 --weights './yolov9-c.pt' --save-json --name yolov9_c_640_val
gui界面 与交互式选择按钮!

评估gelan模型
# python val.py --data data/coco.yaml --img 640 --batch 32 --conf 0.001 --iou 0.7 --device 0 --weights './gelan-c.pt' --save-json --name gelan_c_640_val
执行上述命令后,您将得到以下结果:
平均精度 (AP) @[ IoU=0.50:0.95 | 区域=全部 | 最大检测数=100 ] = 0.530
平均精度 (AP) @[ IoU=0.50 | 区域=全部 | 最大检测数=100 ] = 0.702
平均精度 (AP) @[ IoU=0.75 | 区域=全部 | 最大检测数=100 ] = 0.578
平均精度 (AP) @[ IoU=0.50:0.95 | 区域=小 | 最大检测数=100 ] = 0.362
平均精度 (AP) @[ IoU=0.50:0.95 | 区域=中 | 最大检测数=100 ] = 0.585
平均精度 (AP) @[ IoU=0.50:0.95 | 区域=大 | 最大检测数=100 ] = 0.693
平均召回率 (AR) @[ IoU=0.50:0.95 | 区域=全部 | 最大检测数=1 ] = 0.392
平均召回率 (AR) @[ IoU=0.50:0.95 | 区域=全部 | 最大检测数=10 ] = 0.652
平均召回率 (AR) @[ IoU=0.50:0.95 | 区域=全部 | 最大检测数=100 ] = 0.702
平均召回率 (AR) @[ IoU=0.50:0.95 | 区域=小 | 最大检测数=100 ] = 0.541
平均召回率 (AR) @[ IoU=0.50:0.95 | 区域=中 | 最大检测数=100 ] = 0.760
平均召回率 (AR) @[ IoU=0.50:0.95 | 区域=大 | 最大检测数=100 ] = 0.844
训练准备
bash scripts/get_coco.sh
下载并获取MS COCO数据集的图片(训练、验证、测试)及标签。如果您之前使用过YOLO的不同版本,强烈建议删除train2017.cache和val2017.cache文件,并重新下载标签。
单GPU训练
训练YOLOv9模型
python train_dual.py --workers 8 --device 0 --batch 16 --data data/coco.yaml --img 640 --cfg models/detect/yolov9-c.yaml --weights '' --name yolov9-c --hyp hyp.scratch-high.yaml --min-items 0 --epochs 500 --close-mosaic 15
训练gelan模型
python train.py --workers 8 --device 0 --batch 32 --data data/coco.yaml --img 640 --cfg models/detect/gelan-c.yaml --weights '' --name gelan-c --hyp hyp.scratch-high.yaml --min-items 0 --epochs 500 --close-mosaic 15
多GPU训练
训练YOLOv9模型
python -m torch.distributed.launch --nproc_per_node 8 --master_port 9527 train_dual.py --workers 8 --device 0,1,2,3,4,5,6,7 --sync-bn --batch 128 --data data/coco.yaml --img 640 --cfg models/detect/yolov9-c.yaml --weights '' --name yolov9-c --hyp hyp.scratch-high.yaml --min-items 0 --epochs 500 --close-mosaic 15
训练gelan模型
python -m torch.distributed.launch --nproc_per_node 4 --master_port 9527 train.py --workers 8 --device 0,1,2,3 --sync-bn --batch 128 --data data/coco.yaml --img 640 --cfg models/detect/gelan-c.yaml --weights '' --name gelan-c --hyp hyp.scratch-high.yaml --min-items 0 --epochs 500 --close-mosaic 15

















 4745
4745











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











