






前言
单链表在存储结构上与数组和顺序表这类数据结构稍有不同,因为顺序表在内存中是连续存放的,可以通过指针的算术运算来访问顺序表中的每一个元素,而链表在内存中一般都不是连续的,所以也就无法简单地通过指针的算术运算来遍历链表。本文会从零开始刨析单链表的结构和功能,让你对单链表有新的认识......
单链表详解
概念
单链表,全称单向链表(Singly Linked List),是线性表的一种。所谓单链表是,将多个元素如同链条般有顺序地连接起来,形成一种物理上非连续、逻辑上整齐排列的数据结构。其中,每个元素是单链表的节点,多个节点有序地连接起来构成单链表的结构。

如图是单链表的参考图,接下来我们会多次与这个模型打交道,务必牢记其形式。
定义
要学习单链表就得先搞清楚节点的结构,单链表一个节点的结构由数据和指针两部分组成。如下图所示

//节点类型的定义
typedef struct SListNode
{
SLDataType data;
struct SListNode* next;
}SListNode;一个节点该有两个功能,一是能够存储数据,二是能够找到下一个节点。因此,需要在该结构体成员中定义一个next指针用于存储下一个节点的地址。
节点的创建
两种方法:
方法一:创建结构体变量
该方法是直接用自定义类型来创建一个节点变量,然后再将每个节点连接起来。如下所示
SListNode node4 = { .data = 4, .next = NULL };
SListNode node3 = { .data = 3, .next = &node4 };
SListNode node2 = { .data = 2, .next = &node3 };
SListNode node1 = { .data = 1, .next = &node2 };
SListNode* plist = &node1;值得注意的是最后一个节点的next值需要置为空,以免造成野指针,再者要用这种方式创建节点需要倒着创建,原因在于前一个节点指向下一个节点,就得先存在下一个节点,才能将下一个节点的地址赋给前一个节点的next。
当然我这只是比较在意美观的写法,你也可以先创建节点再挨个赋值,此时就不用像上面那样倒着创建那么别扭。如下所示:
SListNode node1;
SListNode node2;
SListNode node3;
SListNode node4;
SListNode* plist = &node1;//创建头节点
node1.data = 1; node1.next = &node2;
node2.data = 2; node2.next = &node3;
node3.data = 3; node3.next = &node4;
node4.data = 4; node4.next = NULL;//最后一个节点的next记得置为空
方法二:创建结构体指针,指向动态申请的结构体空间
直接利用malloc动态申请一块节点大小的空间,然后将申请到的空间利用指针进行管理,这是一种间接的方式,这种方式的特殊之处在于并没有创建一个结构体变量直接对结构体进行管理,而是先创建一块空间再将这块空间的地址赋给一个指针,通过这块指针对这块空间进行间接的管理。很多同学(包括我自己)刚开始对这个方式没有深刻的理解,于是在单链表这卡了好久。这个问题就当做本文的一个小彩蛋留在文章末尾再进行讨论,如果现在就对你很需要,那也可以先跳转至文章末尾,理解清楚再回来接着往下看。
回到这个方法:我们可以将申请一个节点的方法封装成一个函数SLBuyNode函数声明和实现如下:
SListNode* SLBuyNode(SLDataType x);//x为该节点需要存储的数据
SListNode* SLBuyNode(SLDataType x)
{
SListNode* plist = (SListNode*)malloc(sizeof(SListNode));
if (plist == NULL)
{
perror("malloc fail");
exit(-1);
}
plist->data = x;
plist->next = NULL;
return plist;
}
这样就能够快速地创建一个新节点,并且初始化里面的内容了。
数据的打印(SLPrint)
数组和顺序表的打印是按照指针+1遍历数组和顺序表来实现的,相较于二者,单链表的打印就没那么简单了。单链表节点的结构有一个特点,就是除了一个数据位外,还留有一个成员用于存储下一个节点的地址。此外,最后一个节点存储的地址为NULL,所以可以利用最后一个节点指向NULL作为单链表的结束条件。如下图所示:
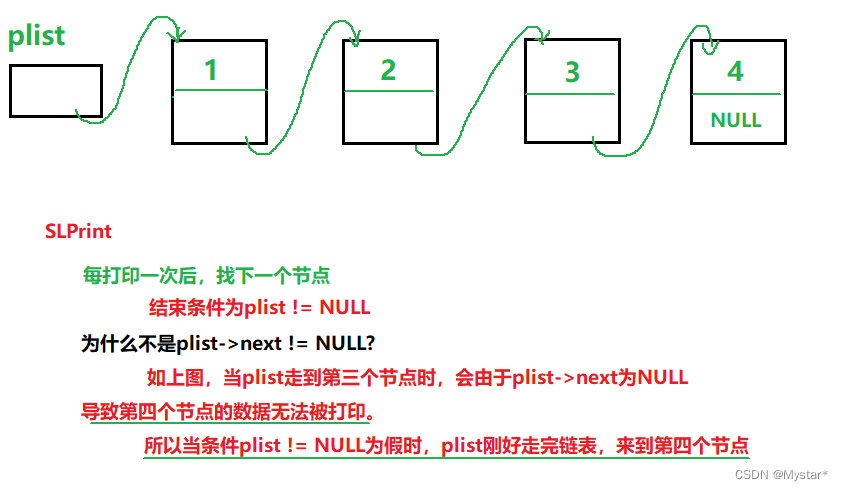
void SLPrint(SListNode* phead)
{
assert(phead);
while (phead)
{
printf("%d->", phead->data);//打印当前节点的数据
phead = phead->next;//走向下一个节点
}
printf("NULL\n");
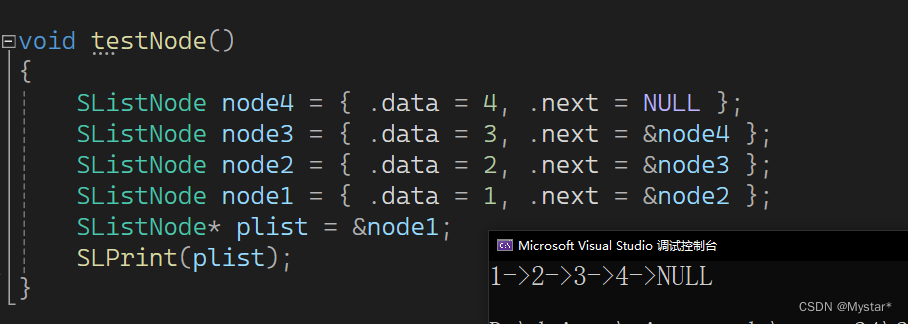
}下图为用第一种方法创建节点输出的数据:
数据的查找(SLFind)
数据的查找是方便后续实现找到指定位置而设计的,通过SLFind能够快速找到数据所在的节点地址,并作为返回值被返回。目前在单链表中查找数据只能通过循环遍历链表来实现,也不难写,就直接上代码不做过多的讲解。
SListNode* SLFind(SListNode* phead, SLDataType x)
{
SListNode* ptail = phead;
if (phead == NULL)
{
printf("链表为空,查找失败\n");
exit(-1);
}
else
{
while (ptail)
{
if (ptail->data == x)
{
return ptail;
}
ptail = ptail->next;
}
}
return NULL;
}六大增删接口函数
增加数据:头插、尾插、指定位置之后插
头插(SLPushFront)
首先创建一个待插入的新节点,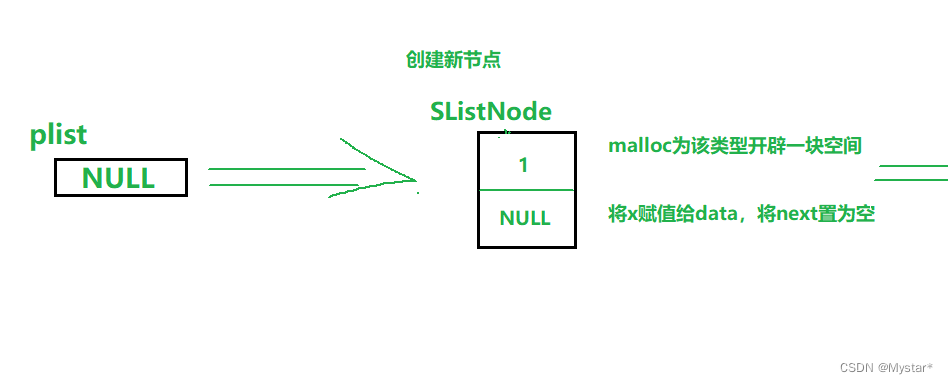
然后对待插入链表的数据情况进行讨论,有两种情况,一是该链表中没有数据,二是链表中有数据。

接着对每种情况都进行分析,找出二者是否兼容,如果不兼容则分情况头插,反之合并头插。
按照上面的逻辑我们可以写下以下代码:
void SLPushFront(SListNode** pphead, SLDataType x)//头插一个数据,传二级指针是因为头节点需要被改变
{
assert(pphead);//防止传入空指针的情况
SListNode* newNode = SLBuyNode(x);//创建新节点
newNode->next = *pphead;//将新节点与旧节点连接起来
*pphead = newNode;//将头节点与新节点连接起来
}综上就顺利头插完成了。
尾插(SLPushBack)
第一步同样是创建新节点,这里就不过多赘述(下面也一样),重点来看如何将新节点尾插到链表后面去。同样分为两种情况:同头插一样,一是链表中无数据,二是链表中有数据;当链表中无数据时,直接让头节点指向新节点就行,如果是第二种情况,那就得先找到原链表的尾节点,接着再把尾节点的next指针指向新节点就可以,听不懂的可以看图
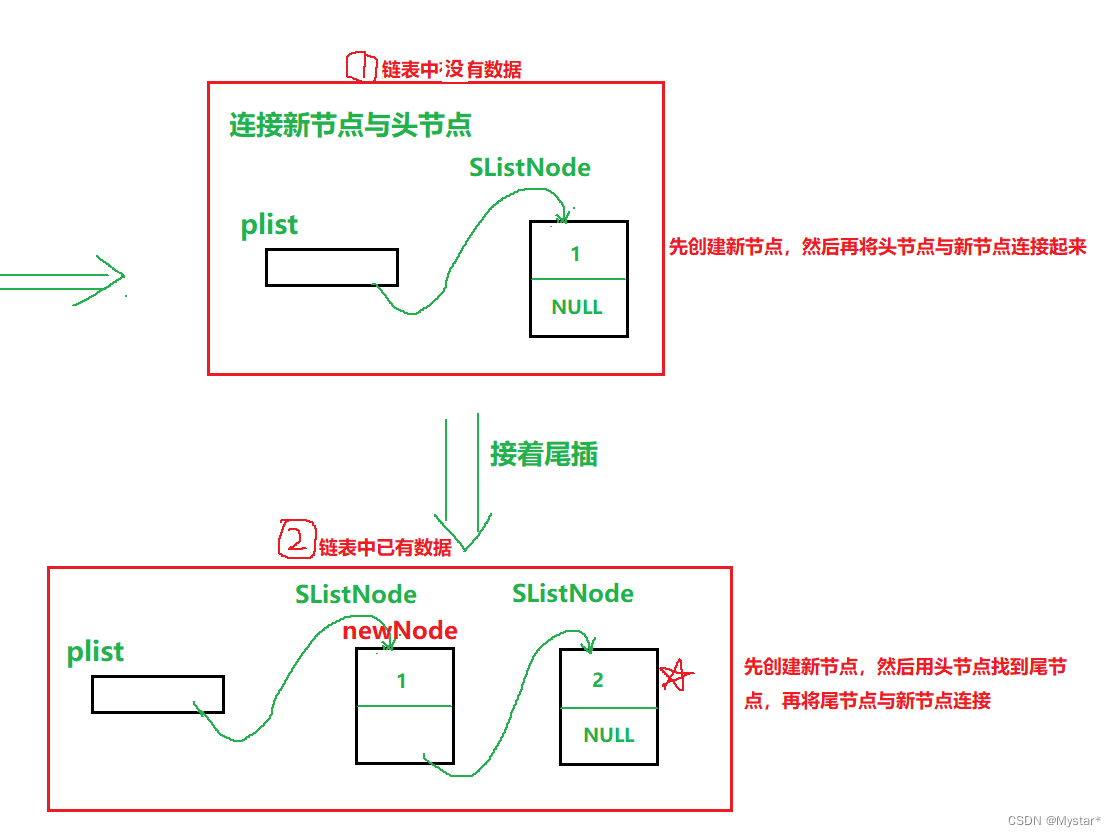
以下是尾插的代码
void SLPushBack(SListNode** pphead, SLDataType x)//尾插一个数据
{
assert(pphead);
SListNode* newNode = SLBuyNode(x);
if (*pphead == NULL)//两种情况不兼容所以应分开执行
{
*pphead = newNode;
}
else
{
SListNode* ptail = *pphead;
while (ptail->next)//先找尾节点
{
ptail = ptail->next;
}
ptail->next = newNode;//接着将尾节点的next指针指向newNode
}
}指定位置之后插(SLInsert)
首先来解释为什么不是指定位置之前或者指定位置插,而偏偏是指定位置之后插。这其实是由单链表的特性决定的,单链表就是单向链表,单向是它的特性。因此当你拿到指定位置之后是无法往回走,也就无法直接插入到指定位置之前;但是,通过再定义一个指针prev用于找指定位置的前一个位置也是能够做到指定位置插的。简单来说就是,用指定位置之后插会比较方便,而且C语言库中也实现的是指定位置之后插。
这种插入方式会遇到三种情况:一是链表中没有数据,二是链表中只有一个节点或者单链表有多个节点且待插入的位置为尾节点,三是除去情况一、二也就是有多个节点且不为特殊节点。
情况一很好解决,由于没有数据因此也就没有指定的位置,直接断言掉就行。重点是情况二三,情况二其实就是在该位置上尾插一个数据就行,情况三就得在pos位置之后插入一个新节点,并且新节点还要和和下一个节点绑起来

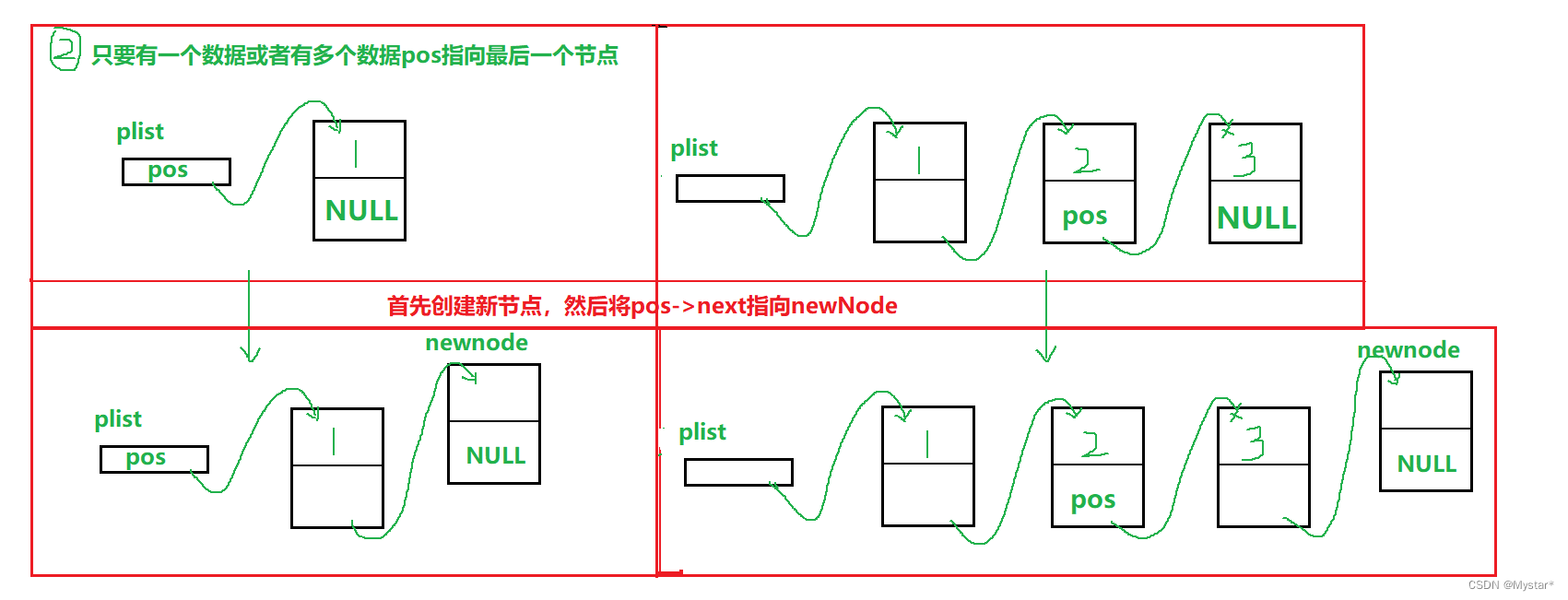

void SLInsert(SListNode* pos, SLDataType x)//指定位置之后插入一个数据
{
assert(pos);//排除链表为空的情况
SListNode* newNode = SLBuyNode(x);
if (pos->next == NULL)
{
pos->next = newNode;
}
else
{
newNode->next = pos->next;//留意顺序,这里是先将新节点的next指向后一个旧节点
pos->next = newNode;//接着再将前一个旧节点指向新节点
}
}头删(SLPopFront)
存在两种情况:一、该链表为空,二、链表不为空。当链表为空就无法删除,因此第一种情况应排除掉;接着是第二种情况,当链表不为空时,要头删一个节点就得先让头指针指向第二个节点,并且释放掉头节点。因此按照思路可以知道,需要先定义一个临时指针tmp用于存储第二个节点的地址,待头指针被释放后在将tmp赋值给plist。
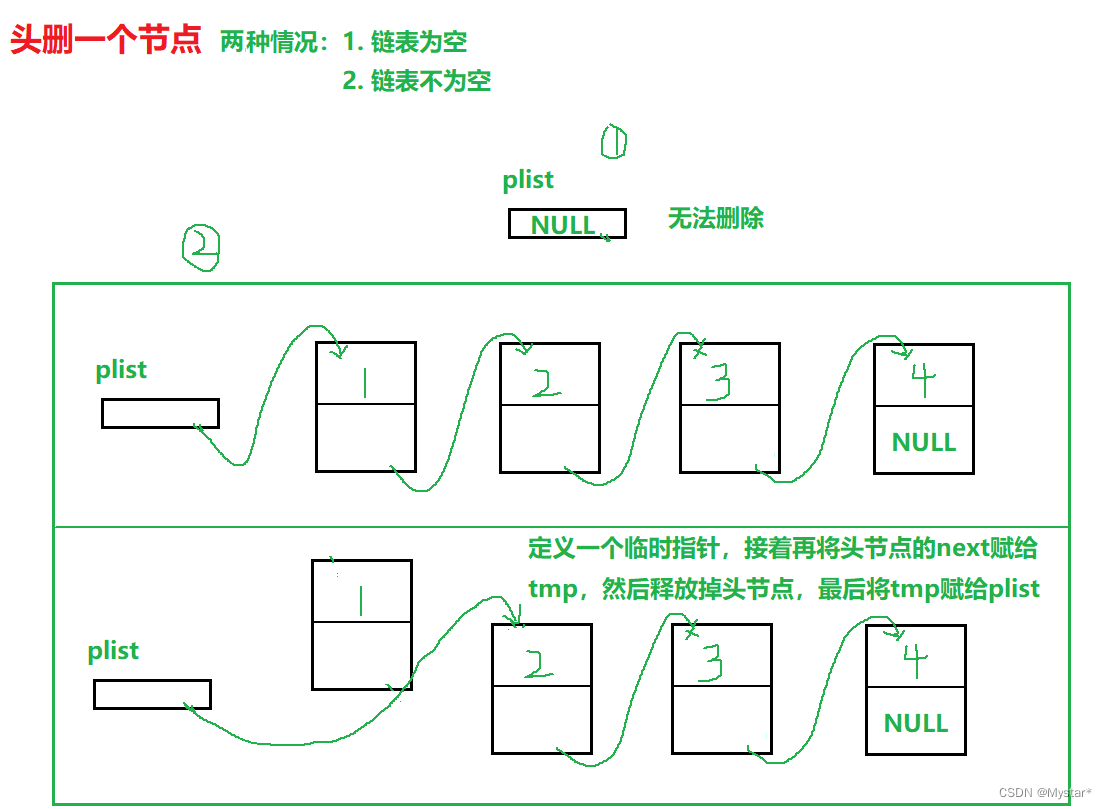
void SLPopFront(SListNode** pphead)//头删一个节点
{
assert(pphead && *pphead);
SListNode* tmp = (*pphead)->next;
free(*pphead);
*pphead = tmp;
}尾删(SLPopBack)
尾删有三种情况,第一种为链表为空;第二种为链表只有一个节点;第三种为链表有多个节点。
ru
如上,当链表只有一个节点时,直接将头节点释放掉,再将plist置为空;当链表存在多个节点时,应先创建两个指针prev和ptail,用ptail找到尾节点,prev指向ptail所在的节点,最后先用ptail释放掉尾节点,接着用prev将ptail置为空即可。
代码实现如下
void SLPopBack(SListNode** pphead)//尾删一个节点
{
assert(pphead && *pphead);//排除传入空指针以及链表为空的情况
if ((*pphead)->next == NULL)//第二种情况,链表只有一个节点
{
free(*pphead);
*pphead = NULL;
}
else//第三种情况,链表存在多个节点
{
SListNode* ptail = *pphead;
SListNode* prev = *pphead;//指向尾节点
while (ptail->next)//找尾
{
prev = ptail;
ptail = ptail->next;
}
free(ptail);//先释放尾节点
ptail = NULL;
prev->next = NULL;//再将ptail置为空
}
}指定位置之后删(SLErase)
三种情况:1. 链表为空,无法删除; 2. 链表只有一个节点,无法删除; 3. 链表有多个节点。情况1和2可以直接通过断言解决,情况三需要创建一个临时指针,用于存储待删除位置的下一个节点的地址,待指定位置下一个节点被删除后赋值给pos->next。

需要注意的是赋值顺序的问题,需要确保被删除节点的next内容没有丢失。代码实现如下:
void SLErase(SListNode* pos)//指定位置(之后)删
{
assert(pos && pos->next);
SListNode* tmp = pos->next->next;
free(pos->next);
pos->next = tmp;
}单链表的销毁
由于结构的差异,导致链表的销毁没有顺序表那样方便,顺序表是用realloc直接开辟一块连续的空间用于存储数据,而单链表是一次开辟一块空间,因此销毁时就需要一次释放一块空间,直至遇到NULL。
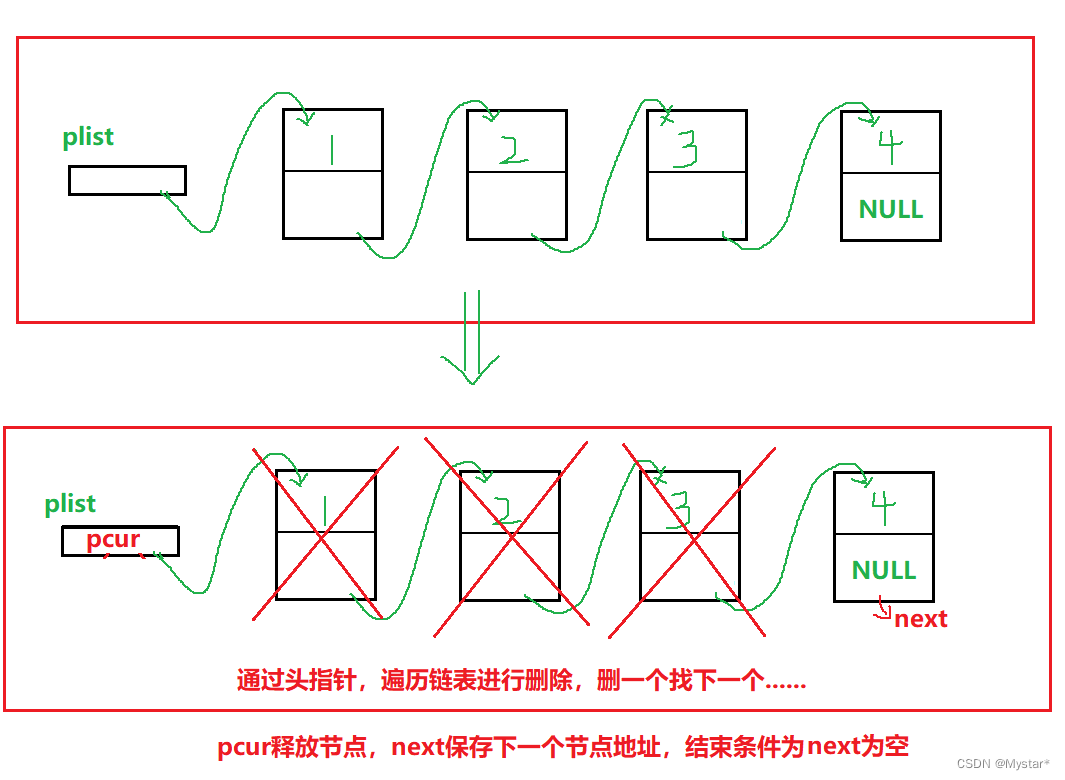
先让pcur指向头节点,接着定义一个指针next并让next = pcur -> next(存储下一个节点的地址),接着再更新pcur的地址,如此迭代,直到pcur == NULL,最后别忘了将plist置为NULL。
代码实现如下:
void SLDestroy(SListNode** pphead)
{
assert(pphead && *pphead);
SListNode* pcur = *pphead;
while (pcur)
{
SListNode* next = pcur->next;
free(pcur);
pcur = next;
}
*pphead = NULL;
}以上就是单链表的所有有关内容了,掌握基础才能攀高峰,只有清晰地理解好每种功能的结构和实现方式才能理解相关题目的构思逻辑,如果文章对您有所帮助还望您高抬贵手点点赞,分享给更多有需要的人......
小彩蛋:关于以类型创建变量和用动态内存函数申请空间后用指针管理的异同
二者都是创建了一块空间,并且都二者都能找到对应的空间
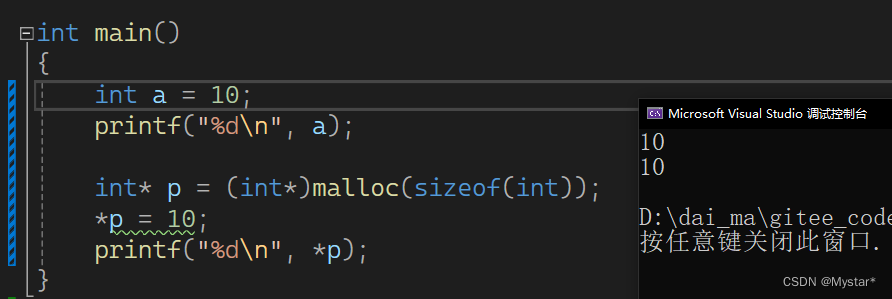
差异在于,两块空间的访问方式不同,第一个用类型创建的变量a是直接访问该空间,而p则是通过指针间接访问空间。如果不懂我说的是什么,看一下下面这张图你大概就懂了。
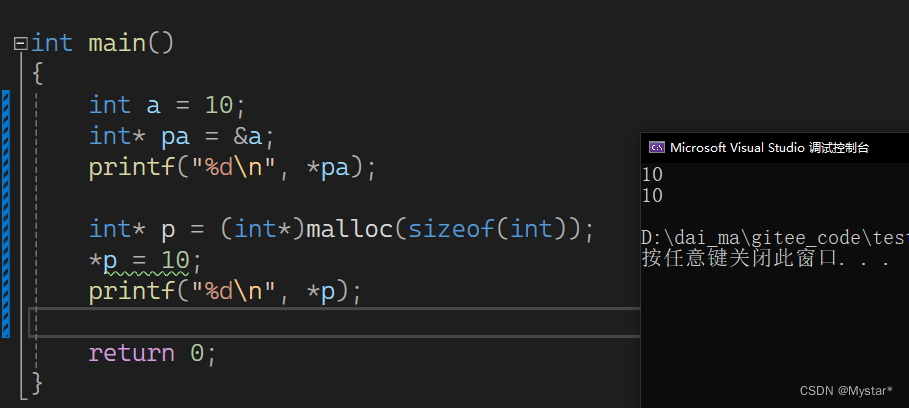
如图所示,变量a是用int类型创建的,既可以直接访问(变量名)也可以间接访问(指针),而用malloc申请的空间则只能用指针的方式进行访问。这种情况在上面的节点创建中也有体现,也就是直接创建节点和利用malloc创建一块SListNode类型的节点。
其次就是想再补充一下,用malloc申请的一块空间在强制类型转换成SListNode* 类型后其空间内部结构也会被划分为对应空间类型的形式。
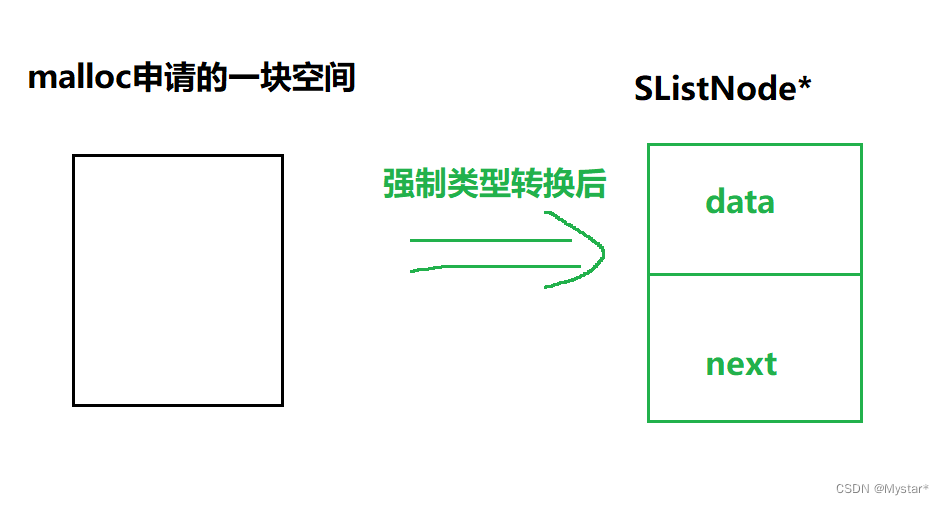
正因如此,才能做到申请到一块节点空间后通过指针进行管理。















 1500
1500

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









