







第二章 数据
前言
第二章第一部分围绕数据的存取过程展开,介绍了如何利用python从数据库中抽取数据,并按照客群进行分类。
本章是数据章节的第二部分,该部分将介绍如何从原始数据中找出适合建模的数据。
在此之前,我们先回顾一下基础篇中“数据”小节中的示例,提前了解各个指标的含义。
一、单客群处理
建模之前需考虑使用哪些样本,数据可能会有多个客群,而每个客群会有多个月份,是全部放在一起进行处理,还是分开处理?
若在不同客群坏客户占比差异较大的情况下统一训练,最终会得到的一个用来识别不同客群而不是识别坏客户的模型。这么做已经违背建模的初衷。
所以,在对客群之间联系不知晓的前提下,单客群处理是更优解。
1.数据筛选
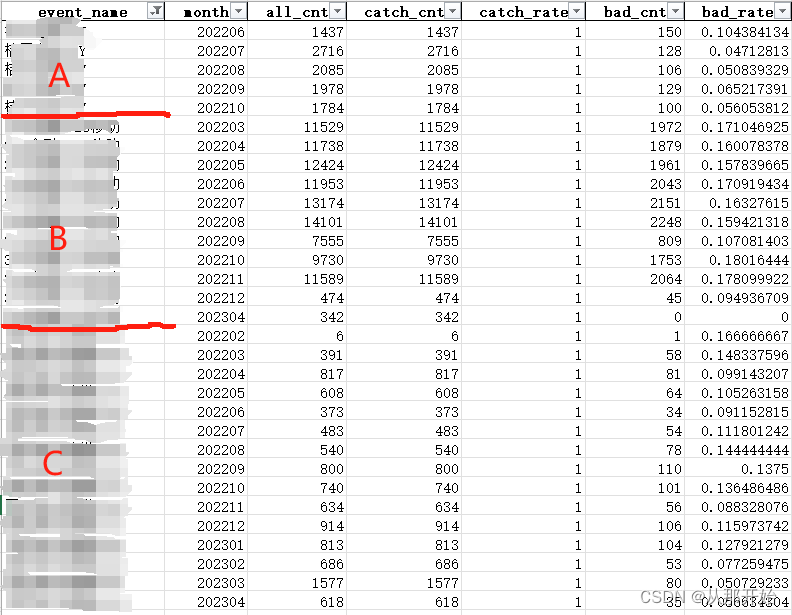
这里把数据分为三个客群A、B、C。A客群共有5个月,每个月的总数据量在2000左右,坏客户数量在100到150之间。B客群共有11个月,大多数月份的总数据量在10000条左右,坏客户数量在2000左右。C客群每个月的总数据量都比较小,坏客户数量基本都小于100。
在选择入模数据的时候,需要遵循一条准则:
总数据量至少要大于10000,最好可以在20000以上;坏客户数量至少超过500。
那么,A客群全体数据入模;B客群符合数量要求的相邻月份入模(相邻月份客群相似,且调用量超过20000),总数据量不超过500的月份不参与入模;C客群全体入模。
2.对比分析
结果生成步骤如下:
1.设置训练集,用列表或字典进行存储,目的是为循环建模。
2.粗筛特征,用于建模特征。
3.训练贝叶斯参数,用于设置模型最优参数。
4.训练模型。
5.全量打分。
6.模型评估。
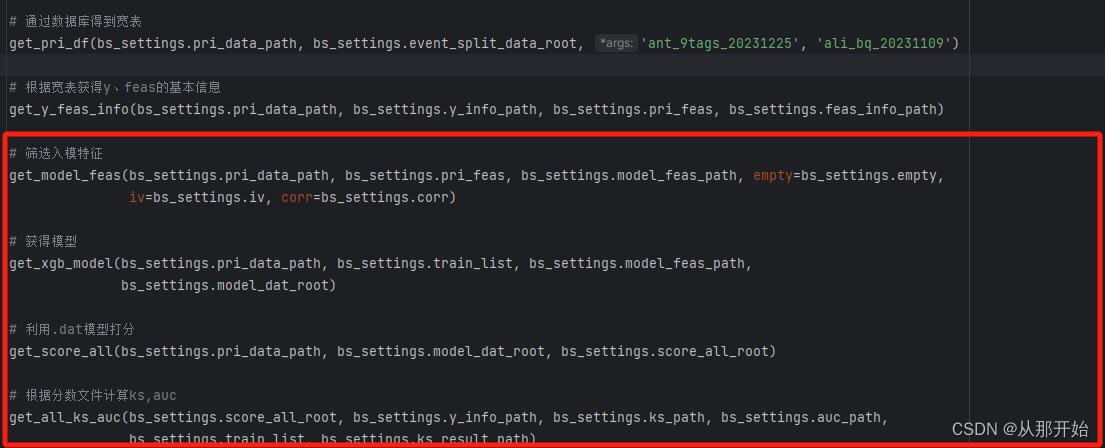
该图展示的是上述步骤用到的函数,想参考具体代码可联系作者哈,篇幅有限。

该图展示的是过程中生成的相关文件。最终用于分析模型好坏的是y_info.csv
接下来,打开文件,观察最终结果。
A:

B:
C:
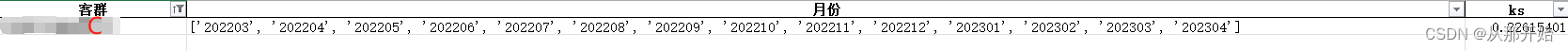
可自行比较各个结果。
在此基础上,观察到B客群的5、6月和7月、8月的ks相近,且四个月的坏账量、坏账率相似。
那么可以,对B客群进行第二次处理——把4个月的数据放到一起建模。
D:

最终结果是:4个月放在一起建模的效果比任何2个月放在一起建模的效果更好。
总结
以上就是数据章节的第二部分,本部分介绍了单客群样本的选择流程。下一篇文章会介绍如何把单客群进行合并,形成合适的多客群样本,并观察比较效果是否会有提升。
代码问题或其他任何问题想要咨询的小伙伴可以加作者微信:HopesXj
咱们下次见。
















 1133
1133











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











