







实验项目名称:MapReduce 编程基础 – topn
编写一个MapReduce程序对天气数据进行处理,求出每个月最高温度的两天
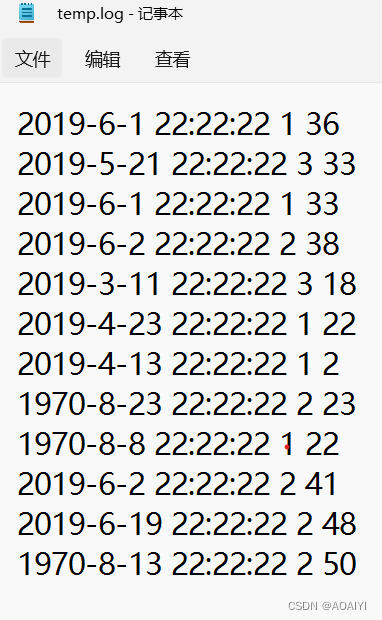
1.上传temp.log到HDFS
2.创建MapReduce工程
(1)设计TKey类
(2)TMapper类
(3)自定义排序器TSortComparator
(4)自定义分区器TPartitioner
(5)自定义分组比较器TGroupingComparator
(6)TReducer类
(7)TopNDriver类
3.提交MapReduce程序作业
4.下载查看统计结果
首先,该实验先在ieda中创建maven项目,其次,在此基础上,编写相关的类,最后,打包成jar包上传到Hadoop集群中。
补充:首先,需要将 temp文件上传到已经在Hadoop创建好的输入地址中,最后,将jar包解压。
1.上传temp.log到HDFS
先在Hadoop创建好文件,/data/topn/input 是输入地址

将temp.log上传到Hadoop中

ps:需要上传的文件,在该文件里要有temp.log才行,不知道目前文件中有没有,可以ls 查看
2.创建MapReduce工程
(1)设计TKey类
package com.hadoop.mapreduce.topn;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class TKey implements WritableComparable<TKey> {
private int year;
private int month;
private int day;
private int temp;
public int getYear() {
return year;
}
public void setYear(int year) {
this.year = year;
}
public int getMonth() {
return month;
}
public void setMonth(int month) {
this.month = month;
}
public int getDay() {
return day;
}
public void setDay(int day) {
this.day = day;
}
public int getTemp() {
return temp;
}
public void setTemp(int temp) {
this.temp = temp;
}
@Override
public int compareTo(TKey that){
int c1 = Integer.compare(this.year,this.getYear());
if (c1 == 0){
int c2 = Integer.compare(this.month,this.getMonth());
if (c2 == 0){
return Integer.compare(this.day,this.getDay());
}
return c2;
}
return c1;
}
/** 序列化*/
@Override
public void write(DataOutput out) throws IOException{
out.writeInt(year);
out.writeInt(month);
out.writeInt(day);
out.writeInt(temp);
}
/** 反序列化*/
@Override
public void readFields(DataInput in) throws IOException{
this.year = in.readInt();
this.month = in.readInt();
this.day = in.readInt();
this.temp = in.readInt();
}
}
(2)TMapper类
package com.hadoop.mapreduce.topn;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class TMapper extends Mapper<LongWritable, Text,TKey, NullWritable> {
TKey mkey = new TKey();
@Override
protected void map(LongWritable key,Text value,Context context) throws IOException,InterruptedException{
String[] split = value.toString().split(" ");
System.out.println(split.length);
String[] time = split[0].split("-");
String temp = split[3];
mkey.setYear(Integer.parseInt(time[0]));
mkey.setMonth(Integer.parseInt(time[1]));
mkey.setDay(Integer.parseInt(time[2]));
mkey.setTemp(Integer.parseInt(temp));
context.write(mkey,NullWritable.get());
}
}
(3)自定义排序器TSortComparator
package com.hadoop.mapreduce.topn;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class TSortComparator extends WritableComparator {
public TSortComparator() { super(TKey.class,true);}
@Override
public int compare(WritableComparable a,WritableComparable b){
TKey k1 = (TKey) a;
TKey k2 = (TKey) b;
int c1 = Integer.compare(k1.getYear(), k2.getYear());
if(c1 == 0){
int c2 = Integer.compare(k1.getMonth(), k2.getMonth());
if (c2 == 0){
return Integer.compare(k2.getTemp(),k1.getTemp());
}
return c2;
}
return c1;
}
}
(4)自定义分区器TPartitioner
package com.hadoop.mapreduce.topn;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Partitioner;
public class TPartitioner extends Partitioner<TKey, NullWritable> {
@Override
public int getPartition(TKey tKey,NullWritable nullWritable,int numPartition){
System.out.println("numpartition = " + numPartition);
return tKey.getYear() % numPartition;
}
}
(5)自定义分组比较器TGroupingComparator
package com.hadoop.mapreduce.topn;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class TGroupingComparator extends WritableComparator {
public TGroupingComparator(){
super(TKey.class,true);
}
@Override
public int compare(WritableComparable a, WritableComparable b){
TKey k1 = (TKey) a;
TKey k2 = (TKey) b;
int c1 = Integer.compare(k1.getYear(), k2.getYear());
if(c1 == 0){
int c2 = Integer.compare(k1.getMonth(), k2.getMonth());
return c2;
}
return c1;
}
}
(6)TReducer类
package com.hadoop.mapreduce.topn;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.Iterator;
public class TReducer extends Reducer<TKey, NullWritable, Text, IntWritable> {
private Text rkey = new Text();
private IntWritable rval = new IntWritable();
protected void reduce(TKey key, Iterable<NullWritable> values, Reducer<TKey, NullWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int flag = 0;
int day = 0;
Iterator<NullWritable> iterator = values.iterator();
while (iterator.hasNext()){
iterator.next();
if (flag == 0){
rkey.set(key.getYear() + "-" + key.getMonth() + "-"+ key.getDay());
rval.set(key.getTemp());
context.write(rkey,rval);
flag++;
System.out.println("top1 -"+ key.getYear()+"-"+key.getMonth()+"-"+key.getDay()+":"+key.getTemp());
day = key.getDay();
}
if (flag != 0 && key.getDay() != day){
rkey.set(key.getYear() + "-" + key.getMonth() + "-"+ key.getDay());
rval.set(key.getTemp());
context.write(rkey,rval);
System.out.println("top1 -"+ key.getYear()+"-"+key.getMonth()+"-"+key.getDay()+":"+key.getTemp());
break;
}
}
}
}
(7)TopNDriver类
package com.hadoop.mapreduce.topn;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class TopNDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration(true);
Job job = Job.getInstance(conf);
job.setJarByClass(TopNDriver.class);
job.setJobName("Topn");
// Input Path
TextInputFormat.addInputPath(job,new Path(args[0]));
// Output Path
Path outputPath = new Path(args[1]);
if (outputPath.getFileSystem(conf).exists(outputPath)){
outputPath.getFileSystem(conf).delete(outputPath, true);
}
TextOutputFormat.setOutputPath(job, outputPath);
//MapTask
//map
job.setMapperClass(TMapper.class);
job.setMapOutputKeyClass(TKey.class);
job.setMapOutputValueClass(NullWritable.class);
//paratitioner 按年、月分区
job.setPartitionerClass(TPartitioner.class);
//numparatition
job.setNumReduceTasks(2);
//sortcomparator 按年、月、温度,且温度倒序
job.setSortComparatorClass(TSortComparator.class);
job.setGroupingComparatorClass(TGroupingComparator.class);
job.setReducerClass(TReducer.class);
//提交job
boolean result = job.waitForCompletion(true);
System.exit(result? 0: 1);
}
}
3.提交MapReduce程序作业
打包jar包上传到Ubuntu中
在该地址中解压上传到Hadoop

ps:还需要再主类后面加上输入地址和输出地址(输出地址不用提前创建)
4.下载查看统计结果

总结:完成mapreduce,需要思路清晰,该项目是在Hadoop集群一配置好的情况下完成的,有何问题可以@小AO。

















 524
524











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











