







 本文介绍了一个针对在线中药店的毕设项目,利用Python的Pandas和相关机器学习算法如随机森林和FP-Growth进行销售数据分析,同时展示了如何通过Django搭建服务器并处理数据,包括数据收集、预处理、趋势分析和可视化。
本文介绍了一个针对在线中药店的毕设项目,利用Python的Pandas和相关机器学习算法如随机森林和FP-Growth进行销售数据分析,同时展示了如何通过Django搭建服务器并处理数据,包括数据收集、预处理、趋势分析和可视化。
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长计算机毕设专题,本次分享的课题是
🎯基于python的在线中药店销售数据分析可视化系统
项目背景
随着互联网的快速发展,电子商务成为了商业领域的重要组成部分。中药作为传统的医药形式,在当今社会依然具有广泛的应用和市场需求。为了更好地了解和分析中药店的销售情况,以便进行市场调研、销售策略优化和业绩预测,设计和开发一个基于Python的在线中药店销售数据分析可视化系统具有重要的意义。该系统可以帮助中药店管理者和市场分析师快速获取和解读销售数据,提供数据可视化和分析功能,为他们提供决策支持和业务洞察。
设计思路
Pandas是一个强大而灵活的数据处理和分析工具,它提供了高效的数据结构和数据操作功能,使得数据分析变得简单而直观。通过Pandas,可以轻松加载、处理和转换各种类型的数据,包括结构化数据、时间序列数据和面板数据。Pandas的主要数据结构是Series和DataFrame,它们可以处理不规则、缺失或混合数据,并提供了丰富的函数和方法来处理数据的选择、过滤、排序、聚合和透视等操作。此外,Pandas还与其他数据分析和可视化库(如NumPy、Matplotlib和Scikit-learn)紧密集成,为用户提供了一个完整的数据分析生态系统。
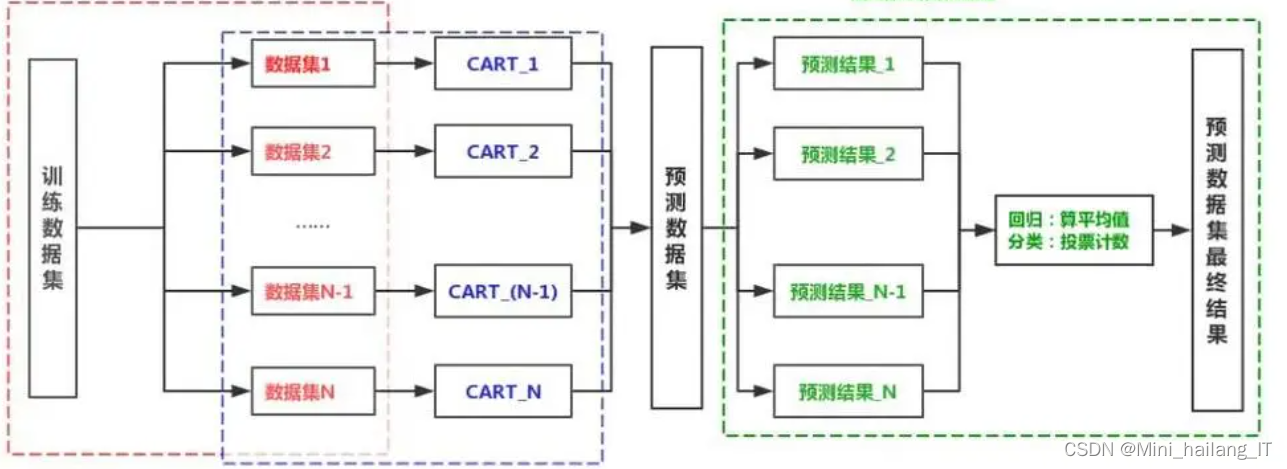
随机森林分类算法在在线中药店销售数据分析可视化系统中的应用非常广泛。通过随机森林算法,可以对顾客进行分类、实现个性化的产品推荐,进行销售预测,对产品进行分类,以及进行特征重要性分析。这些功能可以帮助中药店更好地了解顾客需求、优化产品策略、提高销售转化率,并辅助决策制定。随机森林算法具有准确性高、鲁棒性强的特点,能够处理大量数据和复杂关系,为中药店提供有价值的数据洞察和决策支持。
FP-Growth算法是一种常用的关联规则挖掘技术,用于发现销售数据中的关联性和频繁项集。通过FP-Growth算法,可以从大规模的销售数据中快速识别出经常一起出现的商品组合和购买模式。这种关联性分析可以帮助在线中药店揭示顾客购买行为中的潜在规律和关联关系,从而优化产品陈列、制定捆绑销售策略和提供个性化的推荐服务。FP-Growth算法基于树型结构和频繁模式的挖掘,能够高效地处理大规模数据,并且能够处理多层次的关联规则。通过这种技术,中药店可以深入了解顾客需求和购买习惯,提高销售效益和顾客满意度。
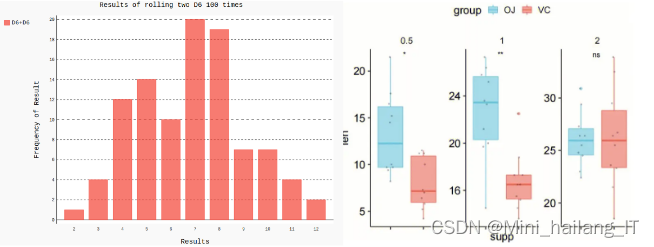
直方图是一种常用的数据可视化方式,可以使用Pandas的hist()函数或Matplotlib库来绘制。直方图展示了不同数值范围内数据的频率分布,帮助我们了解销售数据的集中趋势、离散程度和异常情况。通过观察直方图,我们可以发现销售额和销售量的分布形态,识别是否存在偏态分布、多峰分布或集中分布等特征。另一种常见的数据分布分析方法是箱线图,可以使用Seaborn库的boxplot()函数绘制。箱线图展示了数据的分位数、中位数以及异常值,有助于我们了解销售数据的中心位置、离散程度和异常值情况。通过箱线图,我们可以观察到销售额和销售量的中位数、上下四分位数,进而评估数据的离散程度和异常点的存在。
数据集
由于网络上没有现有的合适的中药店销售数据集,我决定自己进行数据收集和制作,以支持基于Python的在线中药店销售数据分析可视化系统的研究。我联系了几家中药店,并获得了他们的销售数据,包括销售额、销售时间、销售地点等信息。通过与中药店的合作,我能够获取真实的销售数据并确保数据的准确性。此外,我还使用网络爬虫技术收集了相关的市场数据和竞争对手的销售情况。
为了提升基于Python的在线中药店销售数据分析可视化系统的功能和可靠性,我计划对数据集进行扩充和更新。整合其他相关数据源,如用户评价、产品信息等,以丰富数据集的内容。其次,我将使用数据增强技术对原始数据进行处理,生成更多样化、更真实的数据样本,以增加模型的泛化能力。此外,我还将考虑引入时间序列分析和预测模型,以对销售趋势进行预测和分析。通过这些数据扩充和增强的方法,我期望能够进一步完善基于Python的在线中药店销售数据分析可视化系统,提供更准确、全面的数据分析结果,为中药店的经营决策提供更有力的支持。
# 读取销售数据
sales_data = pd.read_csv('sales_data.csv')
product_data = pd.read_csv('product_info.csv')
review_data = pd.read_csv('user_reviews.csv')
# 数据整合
merged_data = pd.merge(sales_data, product_data, on='ProductID')
merged_data = pd.merge(merged_data, review_data, on='UserID')
# 数据增强(根据需求进行)
# 使用数据增强技术,生成更多样化、更真实的数据样本
# 时间序列分析
sales_data['Date'] = pd.to_datetime(sales_data['Date'])
sales_data.set_index('Date', inplace=True)
monthly_sales = sales_data['Sales'].resample('M').sum()
# 时间序列分解
decomposition = seasonal_decompose(monthly_sales, model='additive')
# 绘制销售趋势图
plt.figure(figsize=(10, 6))
plt.plot(monthly_sales.index, monthly_sales.values, label='Sales')
plt.title('Monthly Sales Trend')
plt.xlabel('Date')
plt.ylabel('Sales')
plt.legend()
plt.show()模型训练
在使用Django框架搭建服务器时,有几个重要的文件起到关键作用。首先是__init__.py,它是一个空文件,用于将包所在的目录标识为一个Python包。接下来是settings.py,它是项目的配置文件,用于设置数据库连接、静态文件路径、中间件等项目相关的参数。然后是urls.py,它是URL配置文件,用于将不同的URL路径映射到相应的视图函数。最后是wsgi.py,它是服务器部署文件,负责与Web服务器进行通信。
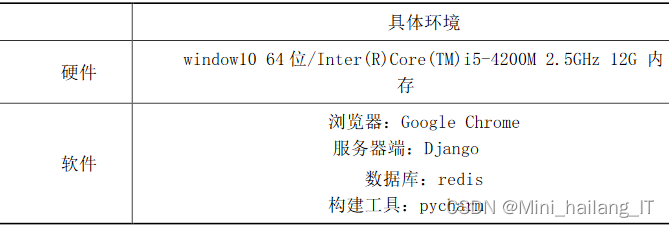
相关代码示例:
import pandas as pd
import matplotlib.pyplot as plt
# 读取销售数据
sales_data = pd.read_csv('sales_data.csv')
# 数据预处理和清洗(根据需求进行)
# 分析销售额和销售量的趋势
sales_data['Date'] = pd.to_datetime(sales_data['Date'])
sales_data['Month'] = sales_data['Date'].dt.month
monthly_sales = sales_data.groupby('Month')['Sales'].sum()
monthly_quantity = sales_data.groupby('Month')['Quantity'].sum()
# 可视化销售额和销售量的趋势
plt.figure(figsize=(10, 6))
plt.plot(monthly_sales.index, monthly_sales.values, label='Sales')
plt.plot(monthly_quantity.index, monthly_quantity.values, label='Quantity')
plt.xlabel('Month')
plt.ylabel('Amount')
plt.title('Monthly Sales and Quantity')
plt.legend()
plt.show()
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









