







 本文介绍了一种基于深度学习,特别是RNN和LSTM的信用贷款逾期风险预测系统,结合随机森林算法进行风险评估。文章详细阐述了项目背景、设计思路,包括数据集的收集与增强,模型训练过程中的交叉验证和性能指标(如ROC曲线、AUC值、F1_score等)。
本文介绍了一种基于深度学习,特别是RNN和LSTM的信用贷款逾期风险预测系统,结合随机森林算法进行风险评估。文章详细阐述了项目背景、设计思路,包括数据集的收集与增强,模型训练过程中的交叉验证和性能指标(如ROC曲线、AUC值、F1_score等)。
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长计算机毕设专题,本次分享的课题是
🎯基于深度学习的信用贷款逾期风险预测系统
项目背景
信用贷款逾期风险是金融机构面临的重要挑战之一。准确预测逾期风险可以帮助金融机构减少损失和风险,提高贷款审批的效率和准确性。信用贷款逾期风险预测系统通过对大量贷款数据的分析和学习,可以实现准确、实时的逾期风险预测,为金融机构提供决策支持和风险管理工具。
设计思路
算法理论技术
深度学习
深度学习算法在信用贷款逾期风险预测系统中通过构建多层神经网络模型,能够自动学习和提取数据中的高级特征,从而有效地识别和预测贷款客户的逾期风险。这种方法充分利用了大数据的优势,通过处理和分析大量的历史数据,学习到的模型能够捕捉到贷款逾期行为背后的复杂规律,提供更为精准的风险评估。同时,深度学习算法的并行处理能力大幅度提高了运算效率,使得风险评估过程更加快速和实时。此外,该技术在不断的学习和反馈中自我优化,提高了模型的适应性和稳定性,为金融机构提供了强有力的风险管理工具,优化了信贷流程,降低了金融风险。
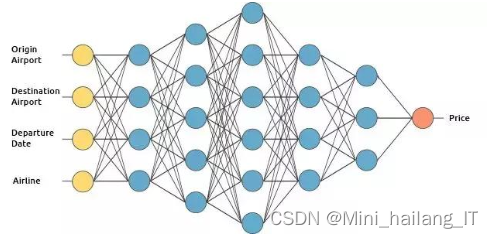
循环神经网络(RNN)是一种深度学习算法,特别适用于处理序列数据。它的核心思想是能够记住前面的信息,并将这些信息用于影响后续的处理。这使得RNN在处理如时间序列数据、语音、文本等类型的数据时具有显著优势。RNN能够捕捉到数据中的时间依赖性,从而在预测和分类任务中表现出优异的性能。例如,在信用贷款逾期风险预测系统中,RNN可以有效地利用历史还款记录,预测客户的未来逾期可能性。

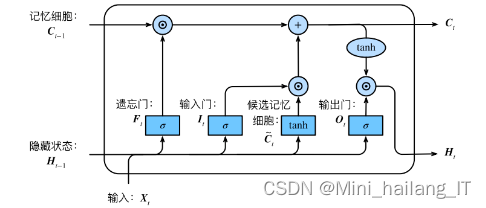
RNN还可以通过堆叠多个网络层或使用长短时记忆(LSTM)单元等方法来解决传统RNN在处理长序列时遇到的梯度消失或梯度爆炸问题,进一步提高模型的预测准确性和稳定性。LSTM单元是循环神经网络(RNN)中的一种特殊结构,它能够解决传统RNN在处理长序列数据时出现的梯度消失问题。通过引入门控机制和细胞状态,LSTM能够有效地保持和传递长期依赖信息,从而在处理具有时间动态性的数据,如语音、文本和时间序列分析等领域展现出卓越的性能。这使得LSTM成为深度学习在信用贷款逾期风险预测等应用中的重要组件,帮助模型更准确地捕捉和利用历史数据中的关键信息,进行高效的风险评估。
随机森林算法
随机森林算法在信用贷款逾期风险预测系统中应用广泛,它通过构建大量决策树并进行投票集成,实现了高精度、高稳定性的风险评估。随机森林能够处理高维数据,自动提取特征,并能够在复杂的非线性关系中捕捉到逾期行为的规律。这种方法不仅提高了预测的准确性,还减少了过拟合的风险。
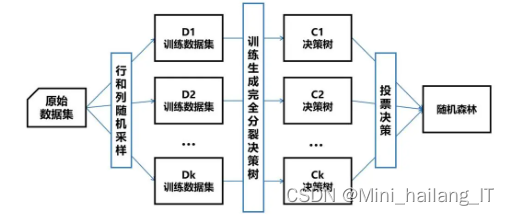
随机森林(Random Forest)是一种集成学习方法,它由多个决策树组成,每个树都是通过随机选择特征和数据样本来构建的。在训练过程中,随机森林对数据进行多次划分,每个树独立进行决策,最后通过投票或平均的方式得出最终结果。这种方法能够有效地处理高维数据,减少过拟合的风险,并在许多分类和回归问题中表现出良好的性能。
数据集
由于网络上没有现有的合适的信用贷款逾期风险数据集,本研究决定通过网络爬取的方式收集数据并制作一个全新的数据集。通过编写爬虫程序,我们从金融机构公开的贷款数据、信用报告数据和还款记录中收集了大量包含贷款逾期风险的信息。这些数据包括借款人的个人信息、贷款金额、还款情况等关键指标。
通过应用数据增强技术和生成模型,我们对原始数据进行了扩充和增强。具体而言,我们使用了生成对抗网络(GAN)和变分自编码器(VAE)等模型生成与原始数据相似的新样本,并将其添加到数据集中。此外,我们还通过数据插值、噪声添加和样本合成等技术对原始样本进行了增强,生成更多样、更具代表性的信用贷款逾期风险样本。
实验环境

模型训练
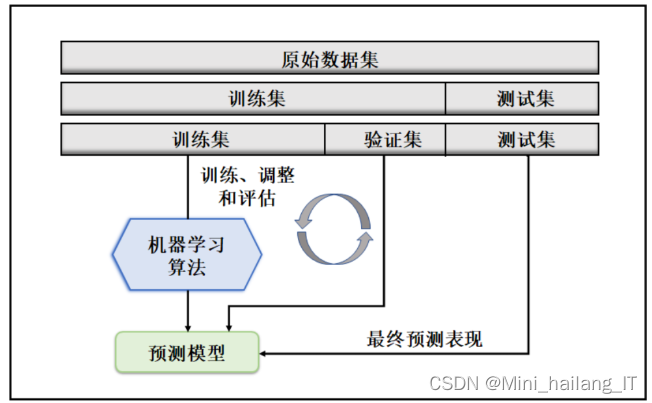
交叉验证是一种评估机器学习模型泛化能力的方法,通过将数据集划分为多个互不重叠的折叠(fold),依次选取每个折叠作为验证集,其余折叠作为训练集,多次重复这一过程,以确保每个折叠都充当过验证集。这种方法有助于识别和减小模型过拟合的风险,提高模型在实际业务场景中的表现。在本研究中,由于样本量大和CPU算力有限,采用了比例法进行交叉验证,即将数据集分为70%的训练集和30%的验证集,通过评估不同模型的预测误差,选择误差最小的模型作为最优分类器。
在机器学习模型的评价中,ROC曲线和AUC值是常用的性能评估工具。ROC曲线以假正例率(FPR)为横坐标,真正例率(TPR)为纵坐标,通过这条曲线可以直观地比较不同模型的分类性能。AUC值则是ROC曲线下的面积,用于量化模型的准确性。此外,F1_score和G-mean也是重要的评价指标,F1_score是召回率和查准率的加权平均,而G-mean是召回率与特异度的几何平均。这些指标综合反映了模型的精确度、召回率和泛化能力,有助于选择最优模型并改进模型参数。
相关代码示例:
from sklearn.metrics import accuracy_score, recall_score, precision_score, f1_score, classification_report
# 确保模型已经训练好
model.evaluate(X_test, y_test)
# 获取预测结果
y_pred = model.predict(X_test)
y_pred = (y_pred > 0.5) # 对于二分类问题,将输出概率转换为类别标签
# 计算性能指标
accuracy = accuracy_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
# 打印性能指标
print(f'Accuracy: {accuracy*100}%')
print(f'Recall: {recall*100}%')
print(f'Precision: {precision*100}%')
print(f'F1 Score: {f1*100}%')
# 如果你想要更详细的报告,可以使用classification_report
report = classification_report(y_test, y_pred)
print(report)
海浪学长项目示例:























 387
387

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









