






一、主要内容
信用风险是指金融机构客户可能会因违规而造成信贷不能收回,从而造成呆账。在企业的经营过程中,风控机构的重要性日益凸显,风控机构的工作对于保障银行业务的安全性和高效性至关重要。随着贸易对方贷款信用质量的下降,私人信贷、住房信贷、企业信贷等其他投资项目的不良贷款数量急剧上升,引起短期流动性风险的出现,最终引起银行倒闭,给经济带来了极大的损失。因此,对信用违约风险进行准确的评估和预测是极为重要的。
首先,探讨信贷行业违约风险预测模型和不平衡数据分类的现有种类和汇总各类方法的利弊,并分析了可改进的方向。接着对模型采用到的相关理论加以梳理分析,并结合国内发展现状,辨别现有方法的优劣,剖析每种方法的不足。同时本文旨在改进 Borderline-Smote 的数据生成比例控制,并引入 K 值寻优算法,以提高模型的准确性和可靠性。为此,本文提出了新的预处理算法,从少数类样品中产生新的可控数目的新样本,并将合并后的样本输入到 Easyensemble 分类器中,最终得到基于边界过采样的Easyensemble 组合模型。经过改进的 Easyensemble 组合模型可以有效地处理不平衡分类问题,并且通过实验研究证明了其合理有效性。此外,为了进一步提高对少数类违约客户的分类准确性,并使预测过程可以自适应的进行分类器的优劣选择,减少人工监督,并提供违约预测过程的可解释性和强逻辑性,避免银行业主观因素影响信贷决策的问题。近年来,深度强化学习的发展迅猛,它不断探索如何利用环境与智能体的交互来掌握最优策略,以提高分类效果。本文设计了一个融合DDQN 深度强化学习算法的 Easyensemble 组合模型,以此来评估每个基分类器的优劣,给予优秀的分类器更高的权重,从而构建一个预测能力有所提升的信贷违约风险决策模型,以期望能够更好地解决不均衡数据集在信贷违约预测领域的问题。以上述思路为基础,利用深度强化学习 DDQN,可以从每个基分类器赋予初始权重开始,自适应地优化出能够提升分类结果的最佳权重决策,而无需人工干预。最后,本文提出了一种融合深度强化学习的分类模型,用于预测信贷违约风险,并进行信贷真实数据集的实验分析。该模式基于已有分类器的结果,通过自适应学习来确定每个分类器合适的权重,从而进一步提高信贷领域不平衡数据分类模型的准确度。通过这种方法,可以更好地解释信贷领域的违约风险决策过程,并进一步提高自适应学习的效果。
二、核心过程
输入:F 样本集,Smin 少数类样本集,Smaxj 多数类样本集,m 是相邻样本的数目
fi 是样本的性质,fij 是相邻样本的所有性质,fn 是近邻的样本
输出:新合成少数类样本Snew
1:for i in F:
2: 计算F 中的每个样本点pi 与全部样本间的欧式距离,确定它们相互之间的m 近
邻。
3: 记pi 附近多数类个数为m’,取划分符合m’< m 且m / 2 < m’的样本点为danger 点
pi’,放入DANGER 集合中。
4: 在DANGER 集合中,随机寻找的K 个最近邻样本,并从中选取与少数类样本点pi
最近邻的S 个样本,分别计算pi’与最近S 个的距离dif。
5: for j in range(i):
6: 生成属性为(rj*dif+pi’)的S 个新少数类样本pnew,rj 属于(0,1)。
7: end for
8:end for
9:生成K*S 个新少数类样本点pnew。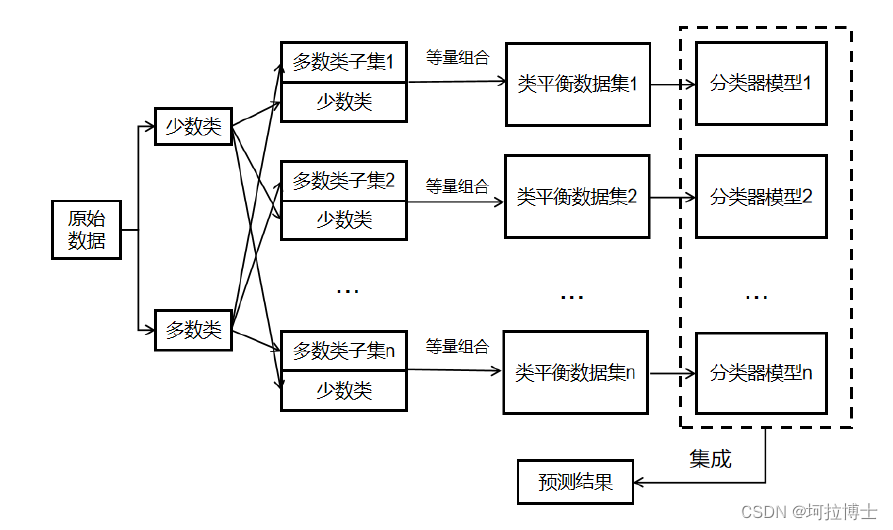
EasyEnsemble 算法流程
Easyensemble 的基分类器默认为Adaboost,Adaboost 为一种迭代算法,也是一种集成学习的方法,其算法思想是:首先初始化每个样本的权重值,每个样本的初始权重值相等,接着训练弱分类器,样本分类正确,则在下一个样本集训练时,这个分类正确的样本值权值就会降低,分类错误时,权重值会提高。更新迭代样本集中每个样本的权重值,继续训练。最后,将所有弱分类器集成为强分类器,其中每个弱分类器的训练后,经过评价指标的验证,将分类效果好的分类器给予更高的权重,将分类效果不好的分类器给予更低的权重。

输入:预处理后的状态特征向量。
输出:神经网络的参数θ。
1:随机初始化Q(s,a;θ) ,随机初始化θo , ∀𝑠 ∈ 𝑆, ∀a∈A
2:初始化经验池D
3:初始化𝜀-greedy算法参数
4:for i=1 to N
5: 𝑦𝑠,𝑎
𝑖 = 𝐸𝐷[𝑟 + 𝛾max
𝑎
′ 𝑄(𝑠′, 𝑎′; 𝜃𝑖−1) ∣ 𝑠, 𝑎]
6: 𝜃𝑖 = arg min𝜃 𝐸𝐷 [(𝑦𝑠,𝑎
𝑖 − 𝑄(𝑠, 𝑎; 𝜃))2]
7: 将(s,a,r,s')添加到经验池D 中
8: 𝑠 ← 𝑠′
9:end forDDQN 算法
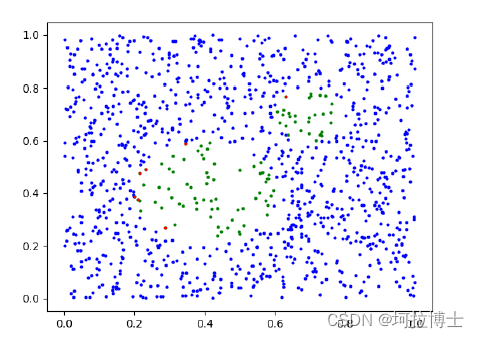
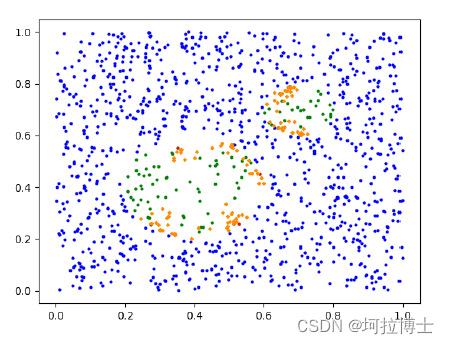
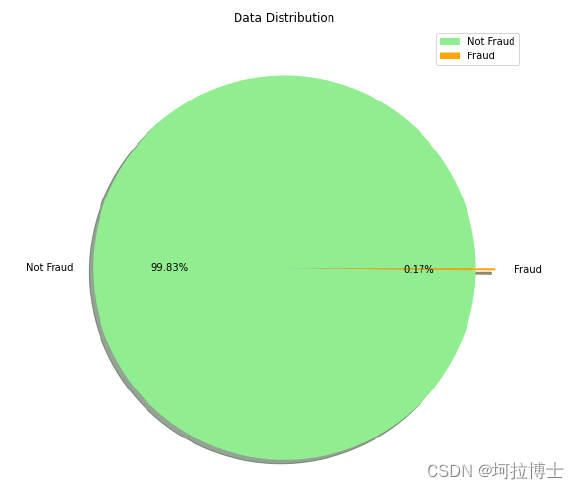
实验数据集采用 2 种公开数据集 Credicard、Genman 对 KBS—EasyEnsemble 算法的实验效果进行了分析。以阿里云天池信贷违约预测数据集为例进行数据集说明,该数据集收集了 120w 条贷款记录,包含四十七列变量,其中十五列是匿名变量。这个数据集中贷款违约与不违约的比例如下图3.3 所示,表明这些数据集存在极度不平衡。由于 Credicard 数据集数据量巨大,故进行了数据抽取和特征选择,划分出不平衡比率为 577.87 的,特征数为 28 的数据量为284807 的 Credicard 作为实验数据集。模型的输出将生成一个二进制值,作为分类器帮助银行识别借款人是否会违约。
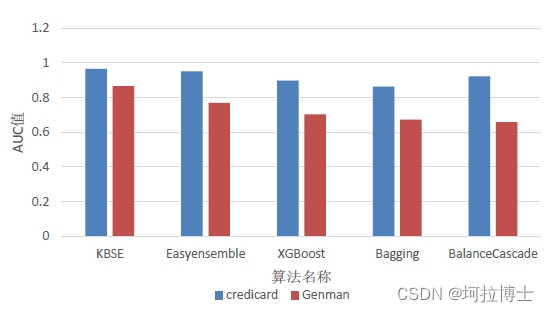
算法结果对比


















 1824
1824

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











