







 本文介绍了如何利用ShuffleNetv2和PANet构建行人闯红灯检测系统,包括数据集的采集与增强、设计思路(特征提取、多尺度融合与预测)、以及目标检测的损失函数。通过改进的模型,系统旨在提高交通安全性并促进计算机视觉技术在交通安全领域的应用。
本文介绍了如何利用ShuffleNetv2和PANet构建行人闯红灯检测系统,包括数据集的采集与增强、设计思路(特征提取、多尺度融合与预测)、以及目标检测的损失函数。通过改进的模型,系统旨在提高交通安全性并促进计算机视觉技术在交通安全领域的应用。
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长计算机毕设专题,本次分享的课题是
🎯基于计算机视觉的行人闯红灯检测系统
项目背景
随着城市交通的日益拥堵和交通安全问题的凸显,行人闯红灯行为已成为一个严重的社会问题。为了提高交通安全并减少交通事故的发生,开发一种基于计算机视觉的行人闯红灯检测系统具有重要意义。该系统可以利用计算机视觉技术,通过实时监测交通场景中的行人行为,并准确判断是否存在闯红灯的情况。通过及时发出警报或采取其他预防措施,可以有效降低行人闯红灯导致的交通事故发生率,提高交通流畅性和城市交通管理水平。
数据集
由于网络上没有现有的合适数据集,本研究决定自行进行数据采集。通过网络爬取技术,收集了大量行人在不同场景下闯红灯的图片,包括城市交通路口、行人过街等。同时,还考虑了不同时间、天气和光照条件下的变化,以获得更多样化和真实的数据。通过自制的数据集,我们能够提供一个全面且具有挑战性的数据集,为行人闯红灯检测系统的研究和评估提供更准确可靠的数据基础。

为了进一步增强数据集的多样性和鲁棒性,我们对采集到的原始数据进行了数据扩充。采用了各种数据增强技术,如旋转、平移、缩放和镜像等,以生成更多样化的图像样本。此外,还应用了遮挡、模糊和光照等效果,模拟实际行人闯红灯场景中的不同情况和挑战。通过数据扩充,我们能够增加数据集的容量和多样性,提高行人闯红灯检测系统的鲁棒性和性能。这将为研究人员提供更全面的数据资源,并促进该领域的发展和应用。

设计思路
闯红灯检测模型的构建包括四个关键层:输入层、特征提取层、PANet(Path Aggregation Network)和多尺度预测层。输入层接收经过预处理的图像数据和标注信息,并将其转化为模型接受的三通道416×416大小的图片。特征提取层基于修改后的ShuffleNet v2网络进行结构化特征提取,其中包含多个堆叠的模块,通过逐点分组卷积和通道混合操作来减少参数量,提升检测速度。
PANet是闯红灯检测模型中的关键组件,用于融合来自不同高度的特征信息。它通过自顶向下和自底向上的路径,将浅层和深层特征进行聚合和融合,以获取更全局和更局部的特征表达。这种多尺度的特征融合能够提高模型的感受野,并增强对不同尺度车辆的检测能力。
最后,多尺度预测层用于预测输入图像中的车辆目标信息。通过使用不同尺度的特征图和锚框,模型可以检测不同尺度和大小的车辆目标。这种多尺度的预测能力使得模型更加全面和准确地捕捉到图像中的车辆信息。
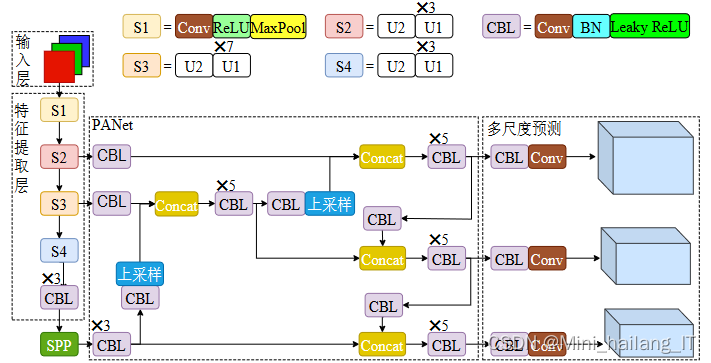
特征提取层采用了修改后的ShuffleNet v2网络,通过逐点分组卷积和通道混合操作来压缩模型、减少参数量,并提高特征融合能力。PANet用于融合来自不同高度的特征信息,增强模型的感受野和对不同尺度车辆的检测能力。多尺度预测层则用于预测输入图像中的车辆目标信息,通过利用不同尺度的特征图和锚框来检测不同尺度和大小的车辆目标。
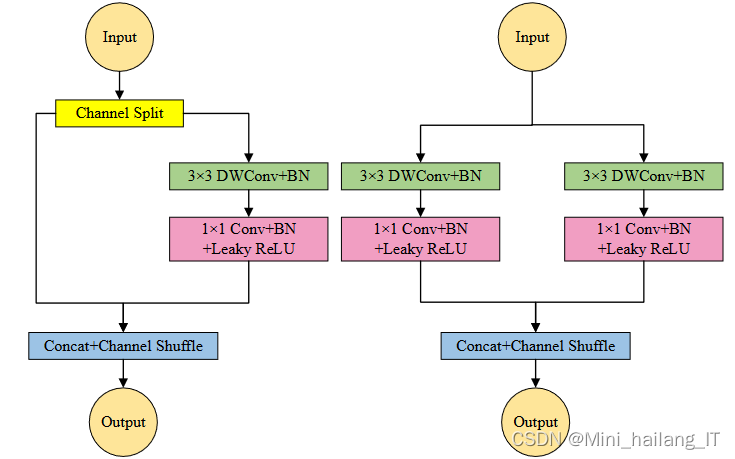
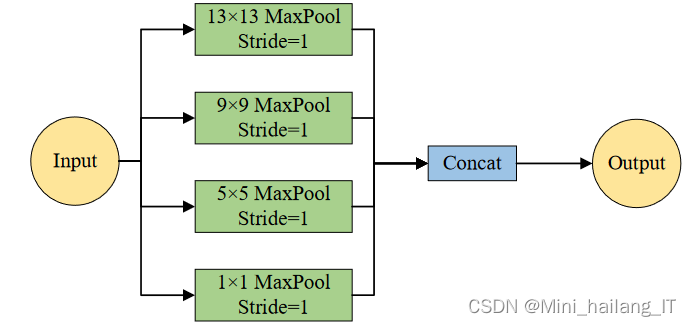
通过改进的ShuffleNet v2车辆检测模型中的PANet和SPP模块,实现了多尺度特征的融合和预测。PANet通过将来自不同高度的特征进行拼接,丰富了特征图中的信息,提高了模型对不同尺度车辆的检测能力。SPP模块利用多个不同大小的池化核进行特征池化,并将池化结果拼接在一起,扩大了网络的感受野并融合了不同尺度的特征。这种多尺度特征融合为模型提供了更全面的信息,有助于解决车辆目标存在大小差异的问题。最终的多尺度预测层接收来自PANet的不同高度特征,并输出相应尺度的回归框,实现了对小、中、大尺度车辆的预测。通过后处理策略,如NMS,可以筛选出置信度高的回归框作为最终的车辆检测结果。综上所述,PANet和SPP模块在改进的ShuffleNet v2车辆检测模型中起到了关键作用,提升了模型的多尺度特征融合和预测能力,为准确的车辆检测提供了强大支持。
目标检测网络的损失函数通常由目标类别损失、目标置信度损失和目标位置损失三部分组成。目标类别损失(LLxc)使用二元交叉熵计算,用于确定检测目标的类别信息。目标置信度损失(LLxo)也使用二元交叉熵计算,包括两个部分:包含目标的锚框损失和不包含目标的预测框损失。目标位置损失(LLgd)则不使用均方误差损失,而是考虑了目标中心点位置、宽高之间的制约关系,综合考虑了真实框与预测框的重合度、中心点距离和宽高比例。
在车辆检测任务中,通过训练完成的模型对闯红灯违法影像中的车辆进行检测,并进行后处理以获取与车辆相关的可用信息。使用HyperLPR工具对检测出的车辆进行车牌识别。检测结果通过红色矩形框标注出候选车辆,若矩形框内有绿色字体,则表示成功识别到该车的车牌信息,否则表示未能识别到车牌信息。
相关代码示例:
import torch
import torch.nn as nn
class DetectionLoss(nn.Module):
def __init__(self):
super(DetectionLoss, self).__init__()
self.class_loss = nn.BCELoss() # 目标类别损失,使用二元交叉熵计算
self.confidence_loss = nn.BCELoss() # 目标置信度损失,使用二元交叉熵计算
def forward(self, pred_class, true_class, pred_confidence, true_confidence, pred_bbox, true_bbox):
# 计算目标类别损失
class_loss = self.class_loss(pred_class, true_class)
# 计算目标置信度损失
positive_mask = true_confidence > 0.5 # 正样本的掩码
negative_mask = true_confidence <= 0.5 # 负样本的掩码
# 计算包含目标的锚框损失
confidence_pos_loss = self.confidence_loss(pred_confidence[positive_mask], true_confidence[positive_mask])
# 计算不包含目标的预测框损失
confidence_neg_loss = self.confidence_loss(pred_confidence[negative_mask], true_confidence[negative_mask])
# 计算目标置信度损失
confidence_loss = confidence_pos_loss + confidence_neg_loss
# 计算目标位置损失
pos_mask = true_confidence.unsqueeze(2).expand_as(true_bbox)
bbox_loss = nn.functional.smooth_l1_loss(pred_bbox[pos_mask], true_bbox[pos_mask], reduction='sum')
bbox_loss /= positive_mask.sum()
# 总损失为目标类别损失、目标置信度损失和目标位置损失的加权和
total_loss = class_loss + confidence_loss + bbox_loss
return total_loss海浪学长项目示例:























 551
551

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









