







目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长计算机毕设专题,本次分享的课题是
🎯基于机器学习的校园考场作弊行为监测
项目背景
在现代教育环境中,智能手机的普及对学生的学习方式和课堂秩序产生了深远影响。虽然手机为学生提供了丰富的学习资源,但在上课和考试期间,学生玩手机的行为可能导致注意力分散,影响学习效果,甚至可能被视为作弊行为。因此,开发一种智能化的检测系统,以实时监测课堂和考场中的手机使用情况,变得尤为重要。通过应用深度学习和计算机视觉技术,可以实现对学生行为的自动监测与分析,及时识别出玩手机的行为,帮助教师和管理者维护良好的课堂秩序和考试环境。
数据集
图像的主要来源为考场监控画面截取。通过使用校园内部的监控系统,监控画面能够捕捉到考生在考试期间的各种行为,包括正常的考试行为和潜在的作弊行为,如抄袭、使用非法设备或与他人交流等。利用已有的公开数据集、社交媒体或教育机构发布的相关资料,收集与考场作弊行为相关的图像和视频。这种双重采集方式能够有效丰富数据集,涵盖更多的行为场景和背景。使用标注工具对采集到的图像进行标注,标注人员需要仔细审核每张图像,识别并标记出考生的行为是否存在作弊情况。可以为每种作弊行为分配不同的标签,以提高数据集的可用性和针对性。

将数据集划分为训练集、验证集和测试集,以便于评估模型的性能。在划分过程中,可以采用70%作为训练集,15%作为验证集,15%作为测试集的比例。此外,为了增加数据集的多样性和样本数量,可以采取数据扩展技术,如图像旋转、缩放、翻转和噪声添加等。这些数据扩展手段能够有效提升模型的鲁棒性,使其在实际应用中能够更好地适应不同的场景和条件。
设计思路
随着深度学习技术的成熟,许多工作开始使用神经网络提取视频中的特征,深度学习成为行为检测任务的主流研究方法。神经元接收多个由其他神经元传递的输入信号,这些输入信号通过带权重的连接进行传递。为了对输入信号进行非线性变换,神经元将接收到的总输入值输入激活函数,将激活函数计算得到的值作为输出。
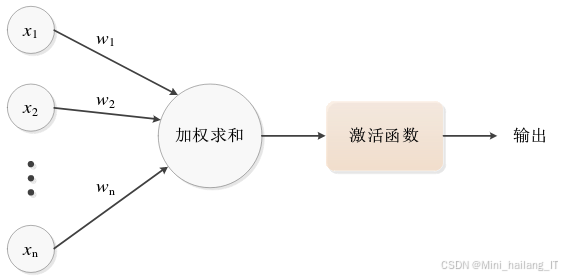
神经元模型中,ReLU(修正线性单元)、sigmoid及tanh是深度学习中常用的三种激活函数。sigmoid及tanh激活函数分别将输入值映射到区间(0,1)及(-1,1),具备较好的非线性表示能力,但存在两个问题。首先,当输入值接近0时,sigmoid及tanh激活函数对该输入值的导数较大,可能导致反向传播过程中的梯度爆炸。其次,当输入值较大或较小时,激活函数对输入的导数值接近于0,容易引发梯度消失。
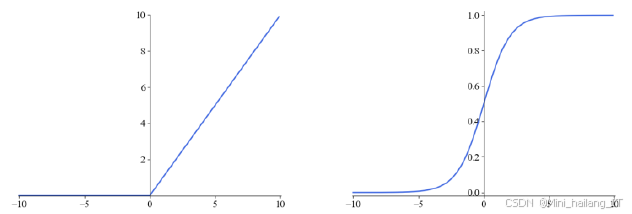
多层感知机(MLP),也称为多层前馈神经网络,是深度学习中最简单、最基础的模型。MLP由一个输入层、一个输出层以及多个隐藏层构成。输出层和隐藏层由多个神经元组成,隐藏层中的神经元与输出层中的每个输入完全连接,每个隐藏层中的神经元也与下一层神经元完全连接,神经元之间不存在同层连接及跨层连接。因此,MLP中的隐藏层也称为全连接层。
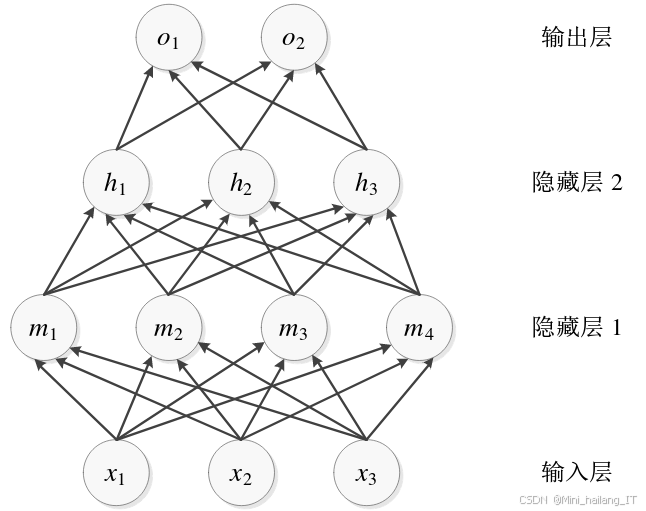
YOLOv5在网络架构、训练策略和数据增强等方面进行了多项改进,使得模型在准确性和速度上都有显著提升。模型的结构主要由三个部分组成:主干网络(Backbone)、颈部网络(Neck)和头部网络(Head)。主干网络用于特征提取,颈部网络用于特征融合,而头部网络则负责最终的目标分类和边界框回归。在训练过程中,YOLOv5利用了多种数据增强技术,如随机缩放、翻转、裁剪和颜色变换等,以提高模型的鲁棒性。此外,YOLOv5还支持使用迁移学习,可以在已有的预训练模型的基础上进行微调,从而加速训练过程并提高检测性能。
从校园考场监控系统中收集真实的监控画面。通过截取监控视频中的关键帧,可以获取到考生在考试期间的行为数据。这些数据应覆盖不同的考场环境,包括不同的光照条件、考生的行为模式以及不同的考试科目。确保数据的多样性和真实性,以便后续的模型训练能够有良好的泛化能力。对采集到的图像进行清洗和标注。首先,去除模糊、不完整或不相关的图像。然后,使用标注工具对每张图像进行标注,标记出考生的行为(例如“正常”、“抄袭”、“使用手机”等)。通过这些标注信息,为后续的模型训练提供必要的标签。
import cv2
import os
def capture_frames(video_path, output_dir, frame_interval=30):
cap = cv2.VideoCapture(video_path)
count = 0
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
if count % frame_interval == 0: # 每隔一定帧数截取一帧
frame_name = os.path.join(output_dir, f'frame_{count}.jpg')
cv2.imwrite(frame_name, frame)
count += 1
cap.release()
video_path = 'path/to/exam_monitoring_video.mp4'
output_dir = 'path/to/output_frames'
capture_frames(video_path, output_dir)选择适合的深度学习模型进行目标检测或行为识别。基于已有的预训练模型进行微调,以适应校园考场作弊行为监测的任务。构建模型时,需要定义网络架构、损失函数和优化器。使用准备好的训练集对模型进行训练。定义损失函数和优化器,设置训练参数(如学习率、批量大小等),并运行训练循环。可以使用早停策略监控验证集的性能,以防止过拟合。
import torch.optim as optim
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
def train_model(model, train_loader, num_epochs=25):
model.train()
for epoch in range(num_epochs):
for inputs, labels in train_loader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')
# train_loader 应该是预先定义的 DataLoader 实例
train_model(model, train_loader)训练完成后,使用验证集对模型进行评估,计算准确率、召回率等指标,以了解模型的性能。根据评估结果进行超参数调优,调整学习率、批量大小等,以提升模型效果。 经过充分训练和评估后,最终模型可以进行部署,以便在实际应用中进行作弊行为监测。
from sklearn.metrics import accuracy_score
def evaluate_model(model, val_loader):
model.eval()
all_preds = []
all_labels = []
with torch.no_grad():
for inputs, labels in val_loader:
outputs = model(inputs)
_, predicted = torch.max(outputs, 1)
all_preds.extend(predicted.numpy())
all_labels.extend(labels.numpy())
accuracy = accuracy_score(all_labels, all_preds)
print(f'Validation Accuracy: {accuracy * 100:.2f}%')
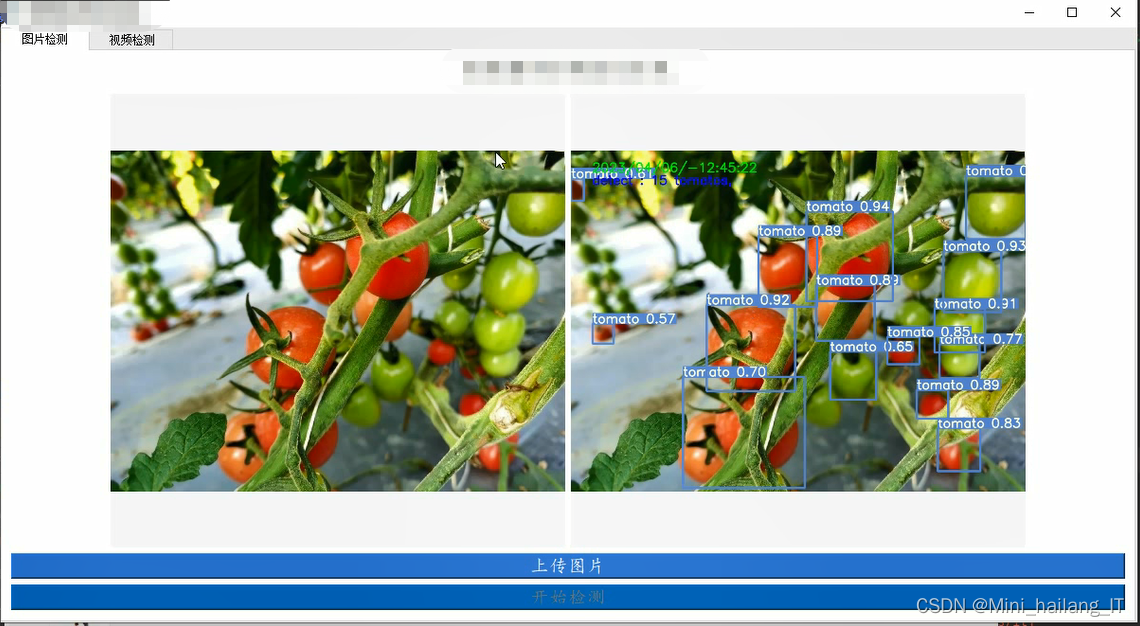
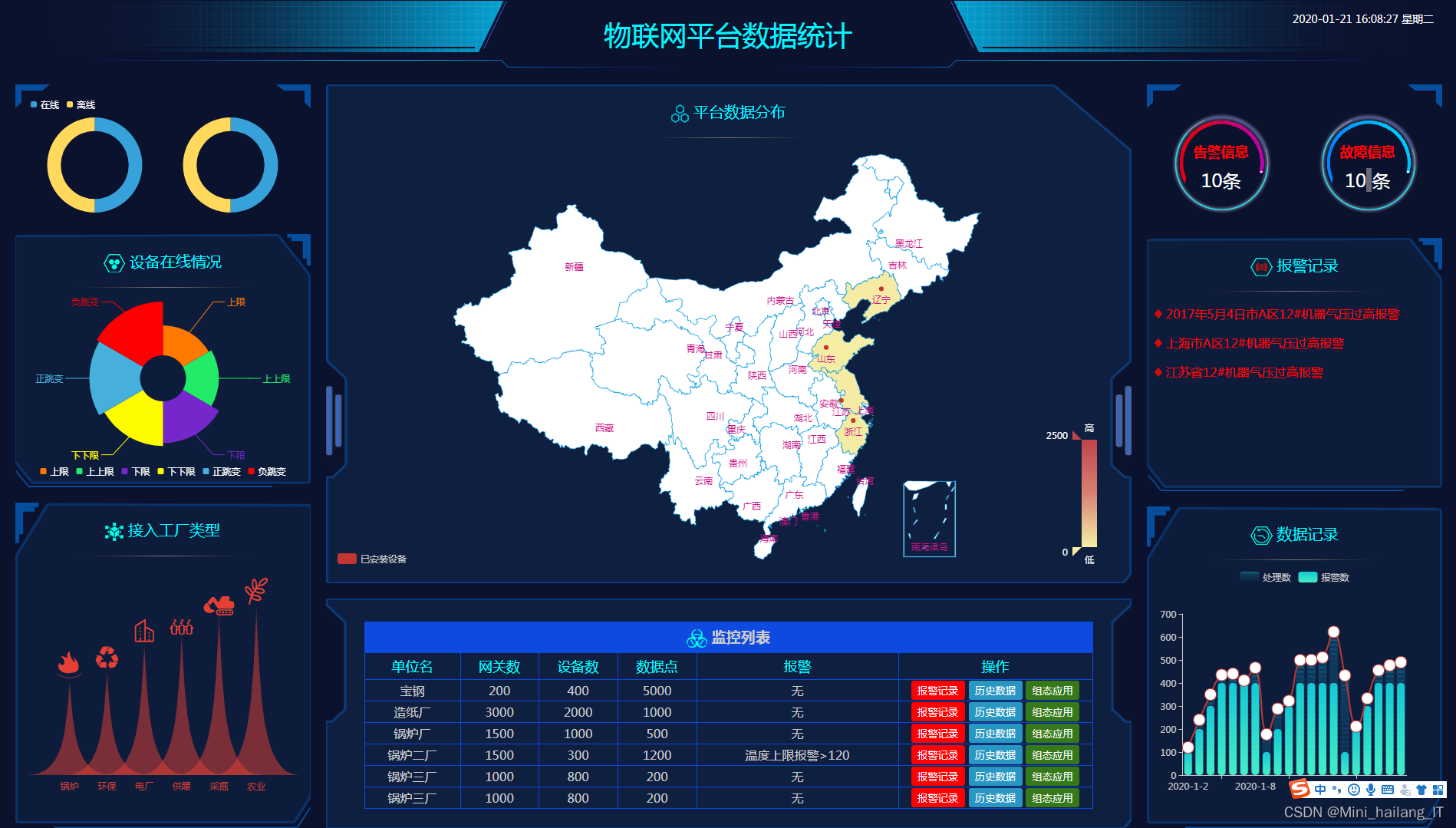
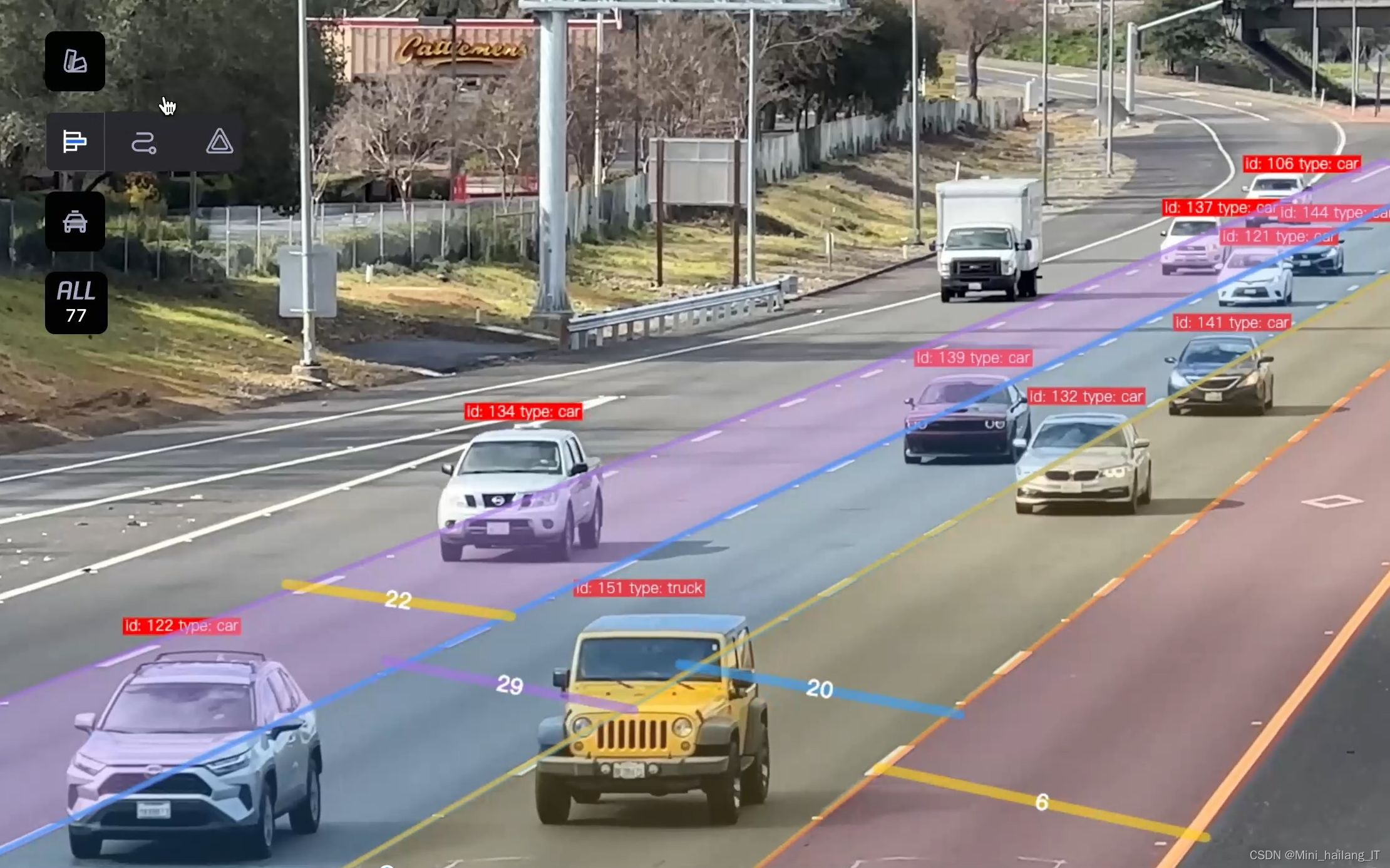
evaluate_model(model, val_loader)海浪学长项目示例:





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









