







文章目录
前言
------不知道各位在做故障检测的时候,有没有发现一个问题。就是在同一个采样频率下,如果是对CWRU分出的4类故障进行诊断(内圈故障、滚动体故障、外圈故障)进行分类会发现准去率会很高。如果只做有无故障诊断的二分类时,正确率达到1也不是一件难事。
------这也是我一开始接触这个问题所遇到的问题,我想咦,既然准确率那么高。我为什么还要去搞那么多高深的网络呢?
------然后我就发现了他们的玩法,那就是跨工况或者对故障的不同程度进行分类预测。这样难度就上来了。同时也不得不说,这样细致的划分才是更加符合实际的。
一、什么是跨工况
------在最早接触到跨工况这个概念是我一位师兄戏谑的说:“做跨工况好的嘞,发文章嘎嘎往一区二区投。”当然我也不清楚这句话的真实性,但是后面我发现在这方面做研究的论文确实挺多。
1.1 跨工况概念
------首先说明什么是工况,工况是指在一定的工作环境下,设备或系统所处的状态和工作条件。它通常包括环境温度、湿度、气压、电压、电流、功率、负载等因素。
------故障诊断跨工况直给的描述就是在不同工况下对机器或设备进行故障诊断。在实际应用中,由于工况的变化,机器或设备的性能参数也会发生变化,因此在不同工况下进行故障诊断是非常必要的。
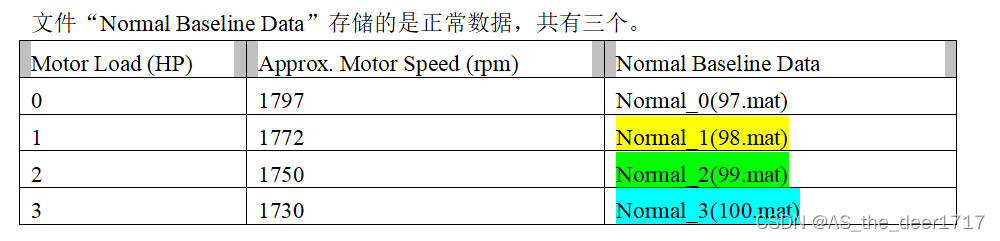
1.2 在CWRU中跨工况?
在CWRU中的工况就是电机载荷(马力),在数据集中就是四个文件夹0HP、1HP…
这四种马力对应了4个近似转速。具体来说,跨工况就可以认为是我拿0工况的数据进行模型的学习之后,我要使用其他工况的数据进行模型的验证。其实说到这儿,我想应该会有人明白这其实有迁移学习与域适应的成分。(但是本文并没有拿源域训练后的模型再去目标域进行微调,所以仍存在着区别。)
二、CWRU轴承数据集使用CNN跨工况故障检测
2.1模型结构说明
------本文使用的代码参考了一个迁移学习库https://github.com/Feaxure-fresh/TL-Bearing-Fault-Diagnosis里面给出了几种迁移学习的模型,如ACADNN、ADACL、BSP、CDAN、DAN等。但是本文只介绍了如何使用CNN进行跨工况故障检测,因此对代码结构进行了简化。但是CNN模型并没有做任何改变。
模型在model_base.py中,关于CNN模型可以分为两个部分一个是FeatureExtractor,另一个是ClassifierMLP。
------其中FeatureExtractor部分有5层,每一层的基本结构就是一个卷积层+批标准化+激活函数+一个最大池化层。
class FeatureExtractor(nn.Module):
def __init__(self,
in_channel=1, kernel_size=7, stride=1, padding=1,
mp_kernel_size=2, mp_stride=2):
super(FeatureExtractor, self).__init__()
layer1 = nn.Sequential(
nn.Conv1d(in_channel, 4, kernel_size=kernel_size, stride=stride, padding=padding),
nn.BatchNorm1d(4),
nn.ReLU(inplace=True),
nn.MaxPool1d(kernel_size=mp_kernel_size, stride=mp_stride))
layer2 = nn.Sequential(
nn.Conv1d(4, 16, kernel_size=kernel_size, stride=stride, padding=padding),
nn.BatchNorm1d(16),
nn.ReLU(inplace=True),
nn.MaxPool1d(kernel_size=mp_kernel_size, stride=mp_stride))
layer3 = nn.Sequential(
nn.Conv1d(16, 32, kernel_size=kernel_size, stride=stride, padding=padding),
nn.BatchNorm1d(32),
nn.ReLU(inplace=True),
nn.MaxPool1d(kernel_size=mp_kernel_size, stride=mp_stride))
layer4 = nn.Sequential(
nn.Conv1d(32, 64, kernel_size=kernel_size, stride=stride, padding=padding),
nn.BatchNorm1d(64),
nn.ReLU(inplace=True),
nn.MaxPool1d(kernel_size=mp_kernel_size, stride=mp_stride))
layer5 = nn.Sequential(
nn.Conv1d(64, 128, kernel_size=kernel_size, stride=stride, padding=padding),
nn.BatchNorm1d(128),
nn.ReLU(inplace=True),
nn.AdaptiveMaxPool1d(4), # 128*4=512
nn.Flatten())
self.fs = nn.Sequential(
layer1,
layer2,
layer3,
layer4,
layer5)
def forward(self, tar, x=None, y=None):
h = self.fs(tar)
return h
------ClassifierMLP层是一个多层感知机分类器,简单的理解就是接收特征提取器提取到的特征进行分类。
class ClassifierMLP(nn.Module):
def __init__(self,
input_size,
output_size,
dropout,
last='tanh'):
super(ClassifierMLP, self).__init__()
self.last = last
self.net = nn.Sequential(
nn.Dropout(p=dropout),
nn.Linear(input_size, int(input_size/4)),
nn.ReLU(),
nn.Linear(int(input_size/4), int(input_size/16)),
nn.ReLU(),
nn.Linear(int(input_size/16), output_size))
if last == 'logsm':
self.last_layer = nn.LogSoftmax(dim=-1)
elif last == 'sm':
self.last_layer = nn.Softmax(dim=-1)
elif last == 'tanh':
self.last_layer = nn.Tanh()
elif last == 'sigmoid':
self.last_layer = nn.Sigmoid()
elif last == 'relu':
self.last_layer = nn.ReLU()
def forward(self, input):
y = self.net(input)
if self.last != None:
y = self.last_layer(y)
return y
2.2训练逻辑
------设置工况1为源域数据,工况2为目标域数据。在每个epoch中对工况1的数据进行训练,并计算准确度。同时在工况2的数据中进行测试。计算获得最优准确率,并保存该准确率下的模型参数。
class Trainset(InitTrain):
def __init__(self, args):
super(Trainset, self).__init__(args)
self.model = model_base.BaseModel(input_size=1, num_classes=args.num_classes,
dropout=args.dropout).to(self.device)
self._init_data()
def save_model(self):
torch.save({
'model': self.model.state_dict()
}, self.args.save_path + '.pth')
logging.info('Model saved to {}'.format(self.args.save_path + '.pth'))
def load_model(self):
logging.info('Loading model from {}'.format(self.args.load_path))
ckpt = torch.load(self.args.load_path)
self.model.load_state_dict(ckpt['model'])
def train(self):
args = self.args
if args.train_mode == 'supervised':
src = None
elif args.train_mode == 'single_source':
src = args.source_name[0]
elif args.train_mode == 'source_combine':
src = args.source_name
elif args.train_mode == 'multi_source':
raise Exception("This model cannot be trained with multi-source data.")
self.optimizer = self._get_optimizer(self.model)
self.lr_scheduler = self._get_lr_scheduler(self.optimizer)
best_acc = 0.0
best_epoch = 0
best_features = []
best_labels = []
best_pred = []
best_preds = []
for epoch in range(1, args.max_epoch + 1):
logging.info('-' * 5 + 'Epoch {}/{}'.format(epoch, args.max_epoch) + '-' * 5)
# Update the learning rate
if self.lr_scheduler is not None:
logging.info('current lr: {}'.format(self.lr_scheduler.get_last_lr()))
# Each epoch has a training and val phase
epoch_acc = defaultdict(float)
# Set model to train mode or evaluate mode
self.model.train()
epoch_loss = defaultdict(float)
num_iter = len(self.dataloaders['train'])
for i in tqdm(range(num_iter), ascii=True):
if src is not None:
source_data, source_labels = utils.get_next_batch(self.dataloaders,
self.iters, src, self.device)
else:
source_data, source_labels = utils.get_next_batch(self.dataloaders,
self.iters, 'train', self.device)
# forward
self.optimizer.zero_grad()
pred, _ = self.model(source_data)
loss = F.cross_entropy(pred, source_labels)
epoch_acc['Source Data'] += utils.get_accuracy(pred, source_labels)
epoch_loss['Source Classifier'] += loss
# backward
loss.backward()
self.optimizer.step()
# Print the train and val information via each epoch
for key in epoch_loss.keys():
logging.info('Train-Loss {}: {:.4f}'.format(key, epoch_loss[key] / num_iter))
for key in epoch_acc.keys():
logging.info('Train-Acc {}: {:.4f}'.format(key, epoch_acc[key] / num_iter))
# log the best model according to the val accuracy
features, labels, new_acc, y_pred, y_preds = self.test()
if new_acc >= best_acc:
best_acc = new_acc
best_epoch = epoch
best_features = features
best_labels = labels
best_preds = y_preds
logging.info("The best model epoch {}, val-acc {:.4f}".format(best_epoch, best_acc))
if self.lr_scheduler is not None:
self.lr_scheduler.step()
# 在训练最后的时候获取CNN网络提取的特征
if epoch == args.max_epoch:
# 特征可视化
visualize_tsne(np.concatenate(best_features), np.concatenate(best_labels))
# 混淆矩阵的计算
#y_preds是1280的数据量的20*64的数据,想进行混淆矩阵的计算,就得先进行匹配式提取,提取成为9标签的标准数据。那么我为什么不直接进行统计类。
cauculate_cm_plt(best_labels, best_preds, label_name=['Class 0', 'Class 1', 'Class 2', 'Class 3',
'Class 4', 'Class 5', 'Class 6', 'Class 7', 'Class 8'], title="confusion_matrix of CNN_CW")
def test(self):
self.model.eval()
acc = 0.0
features = []
labels = []
preds = []
iters = iter(self.dataloaders['val'])
num_iter = len(iters)
with torch.no_grad():
for i in tqdm(range(num_iter), ascii=True):
target_data, target_labels, _ = next(iters)
target_data, target_labels = target_data.to(self.device), target_labels.to(self.device)
# Extract features instead of predicting
pred, feature = self.model(target_data)
features.append(feature.cpu().numpy())
labels.append(target_labels.cpu().numpy())
preds.append(pred.argmax(dim=1).cpu().numpy())
acc += utils.get_accuracy(pred, target_labels)
acc /= num_iter
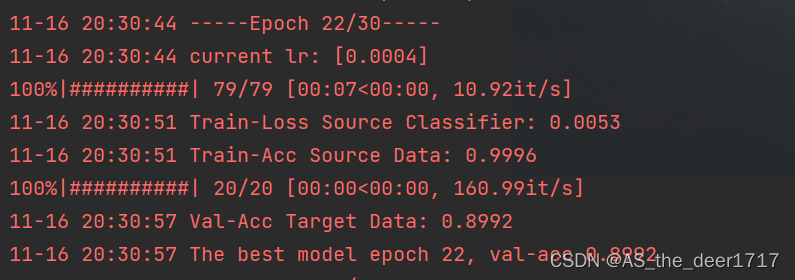
logging.info('Val-Acc Target Data: {:.4f}'.format(acc))
return features, labels, acc, pred, preds
2.3直接给代码
-----关于完整可运行的代码,我将其放在了github中https://github.com/Asthedeer/CNN-cross_working_condition。当然了,关于CWRU数据集也在其中。
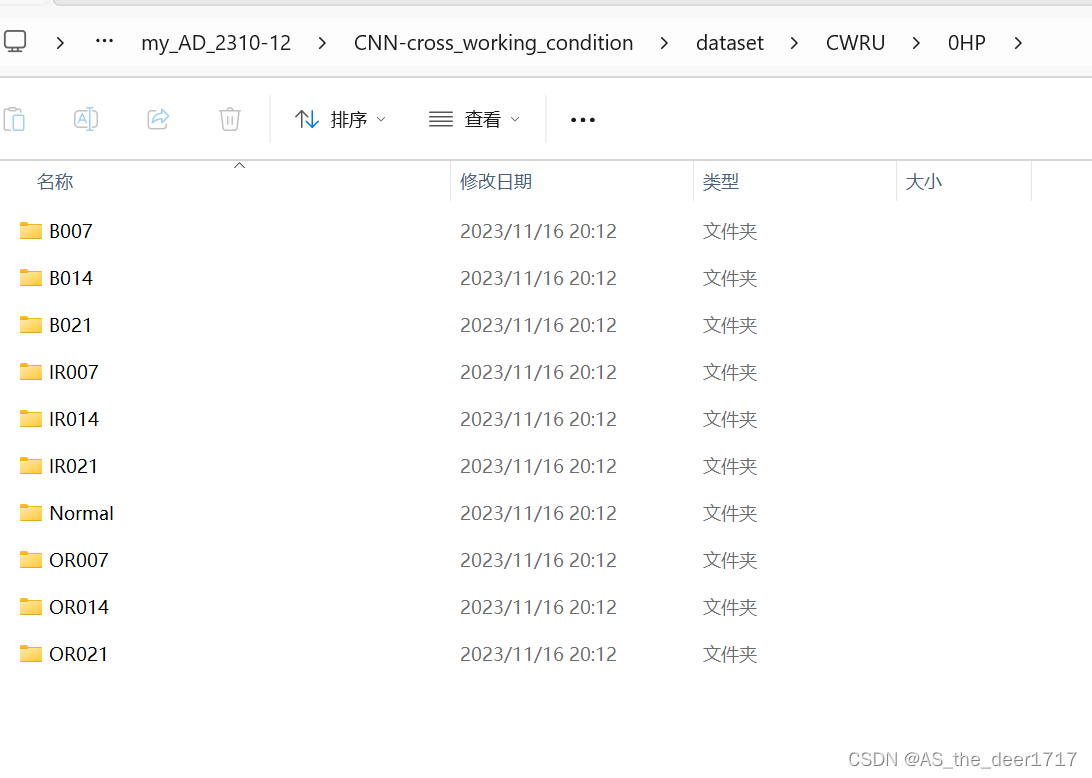
-----关于数据集,这是一个4中工况10分类的数据。3中故障类别,每种类别又分3种故障直径。我竟然对着数字说明表,一个一个自己分出来也是无语的(因为文件名字是数字的,感觉写代码分也麻烦)。但是代码中只进行了9分类,没有把正常数据集放进去。
2.4 结果分析
2.4.1 特征降维图(t-sne)
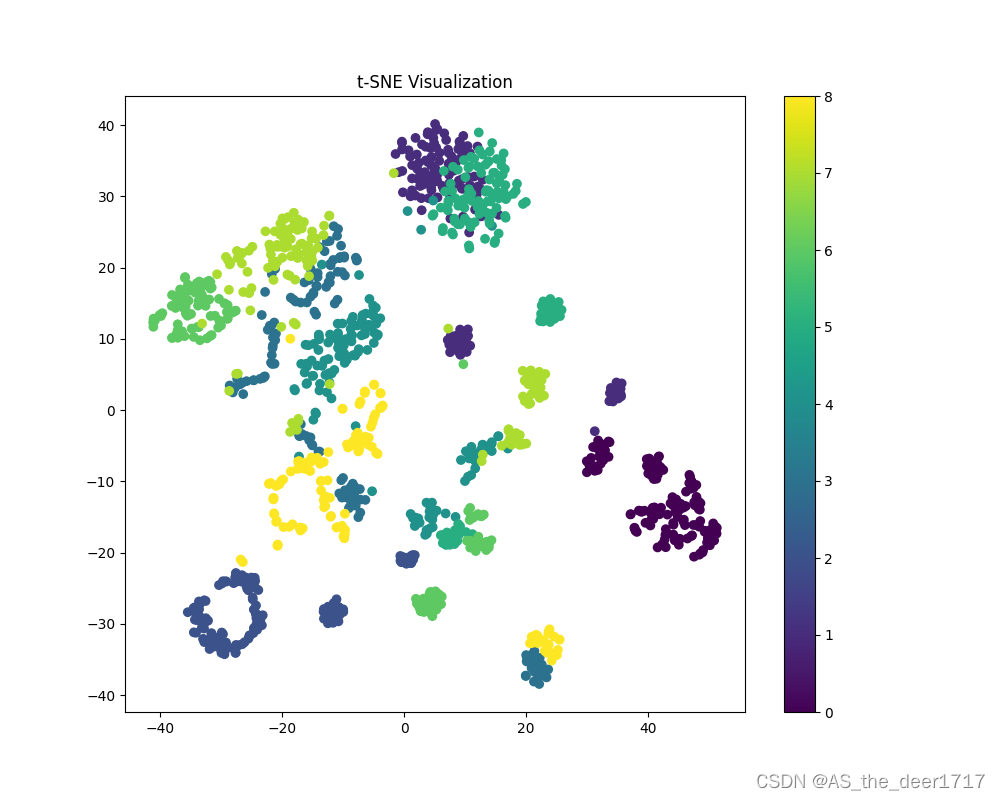
是不是感觉分类的效果并不是很好,因为工况1训练下的模型在工况2中最优的准确率也只有0.8992。同时特征降维之后,其是否聚合还是分离关系到的是模型的可解释性。在极端情况下,提取的特征效果不理想也有得到一定结果的可能。
关于特征可视化,该链接中的内容可能会给各位一点启发。保姆级教程之SABO-VMD-CNN-SVM的分类诊断,特征可视化
使用t-sne降维,特征可视化的代码如下。
def visualize_tsne(features, labels):
tsne = TSNE(n_components=2, random_state=2)
embedded_features = tsne.fit_transform(features)
plt.figure(figsize=(10, 8))
plt.scatter(embedded_features[:, 0], embedded_features[:, 1], c=labels, cmap='viridis')
plt.colorbar()
plt.title('t-SNE Visualization')
plt.show()
2.4.2 混淆矩阵

使用混淆矩阵计算,其代码如下
def cauculate_cm_plt(labels_true, label_pred, label_name, title=" "):
#首先要明确,我的数据list 20。
all_labels = np.concatenate(labels_true, axis=0)
all_preds = np.concatenate(label_pred, axis=0)
cm = confusion_matrix(y_true=all_labels, y_pred=all_preds, normalize='true')
plt.imshow(cm, cmap='Blues')
plt.title(title)
plt.xlabel("Predict label")
plt.ylabel("Truth label")
plt.yticks(range(label_name.__len__()), label_name)
plt.xticks(range(label_name.__len__()), label_name, rotation=45)
plt.tight_layout()
plt.colorbar()
for i in range(label_name.__len__()):
for j in range(label_name.__len__()):
color = (1, 1, 1) if i == j else (0, 0, 0) # 对角线字体白色,其他黑色
value = float(format('%.2f' % cm[j, i]))
plt.text(i, j, value, verticalalignment='center', horizontalalignment='center', color=color)
plt.show()
3、结论
-----本文仅对CWRU轴承数据集使用CNN跨工况检测进行说明,并给出了一种实现方法。关于其他模型进行跨工况检测还希望读者能够自行探索。

















 942
942

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









