









这是做的O’Relly的一个开篇练习,尝试利用http://grouplens.org/datasets/movielens/上的关于影评数据的dataset做的一个分析。
刚开始要读取压缩包中的user数据的时候,我用了以下代码:
users = pd.read_table('C:\Python27\data\ml\u.user',
sep = "::",
header = None,
names = unames)(其实就是书上的代码)
但是提示报错,报错信息如下:
C:\Python27\Scripts\ipython:1:
ParserWarning:
Falling back to the 'python' engine because the 'c' engine does not support regex separators;
you can avoid this warning by specifying engine='python'.看提示应该是引擎的缘故,我就在原先的pd.read_table参数列表中加上了engine='python',还是显示报错,报错内容如下:
ValueError Traceback (most recent call last)
<ipython-input-8-98b02f625a19> in <module>()
----> 1 users = pd.read_table('C:\Python27\data\ml\u.user',sep = "::",header = None,names = unames,engine='python')
C:\Python27\lib\site-packages\pandas\io\parsers.pyc in parser_f(filepath_or_buffer, sep, dialect, compression, doubl
te, escapechar, quotechar, quoting, skipinitialspace, lineterminator, header, index_col, names, prefix, skiprows, sk
oter, skip_footer, na_values, true_values, false_values, delimiter, converters, dtype, usecols, engine, delim_whites
, as_recarray, na_filter, compact_ints, use_unsigned, low_memory, buffer_lines, warn_bad_lines, error_bad_lines, kee
fault_na, thousands, comment, decimal, parse_dates, keep_date_col, dayfirst, date_parser, memory_map, float_precisio
rows, iterator, chunksize, verbose, encoding, squeeze, mangle_dupe_cols, tupleize_cols, infer_datetime_format, skip_
k_lines)
496 skip_blank_lines=skip_blank_lines)
497
--> 498 return _read(filepath_or_buffer, kwds)
499
500 parser_f.__name__ = name
C:\Python27\lib\site-packages\pandas\io\parsers.pyc in _read(filepath_or_buffer, kwds)
283 return parser
284
--> 285 return parser.read()
286
287 _parser_defaults = {
C:\Python27\lib\site-packages\pandas\io\parsers.pyc in read(self, nrows)
745 raise ValueError('skip_footer not supported for iteration')
746
--> 747 ret = self._engine.read(nrows)
748
749 if self.options.get('as_recarray'):
C:\Python27\lib\site-packages\pandas\io\parsers.pyc in read(self, rows)
1603 content = content[1:]
1604
-> 1605 alldata = self._rows_to_cols(content)
1606 data = self._exclude_implicit_index(alldata)
1607
C:\Python27\lib\site-packages\pandas\io\parsers.pyc in _rows_to_cols(self, content)
1978 msg = ('Expected %d fields in line %d, saw %d' %
1979 (col_len, row_num + 1, zip_len))
-> 1980 raise ValueError(msg)
1981
1982 if self.usecols:
ValueError: Expected 5 fields in line 1, saw 1
In [9]: users = pd.read_table('C:\\Python27\\data\\ml\\u.user',sep = "::",header = None,names = unames,engine='pytho
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-9-1fe25bfe7607> in <module>()
----> 1 users = pd.read_table('C:\\Python27\\data\\ml\\u.user',sep = "::",header = None,names = unames,engine='pytho
C:\Python27\lib\site-packages\pandas\io\parsers.pyc in parser_f(filepath_or_buffer, sep, dialect, compression, doubl
te, escapechar, quotechar, quoting, skipinitialspace, lineterminator, header, index_col, names, prefix, skiprows, sk
oter, skip_footer, na_values, true_values, false_values, delimiter, converters, dtype, usecols, engine, delim_whites
, as_recarray, na_filter, compact_ints, use_unsigned, low_memory, buffer_lines, warn_bad_lines, error_bad_lines, kee
fault_na, thousands, comment, decimal, parse_dates, keep_date_col, dayfirst, date_parser, memory_map, float_precisio
rows, iterator, chunksize, verbose, encoding, squeeze, mangle_dupe_cols, tupleize_cols, infer_datetime_format, skip_
k_lines)
496 skip_blank_lines=skip_blank_lines)
497
--> 498 return _read(filepath_or_buffer, kwds)
499
500 parser_f.__name__ = name
C:\Python27\lib\site-packages\pandas\io\parsers.pyc in _read(filepath_or_buffer, kwds)
283 return parser
284
--> 285 return parser.read()
286
287 _parser_defaults = {
C:\Python27\lib\site-packages\pandas\io\parsers.pyc in read(self, nrows)
745 raise ValueError('skip_footer not supported for iteration')
746
--> 747 ret = self._engine.read(nrows)
748
749 if self.options.get('as_recarray'):
C:\Python27\lib\site-packages\pandas\io\parsers.pyc in read(self, rows)
1603 content = content[1:]
1604
-> 1605 alldata = self._rows_to_cols(content)
1606 data = self._exclude_implicit_index(alldata)
1607
C:\Python27\lib\site-packages\pandas\io\parsers.pyc in _rows_to_cols(self, content)
1978 msg = ('Expected %d fields in line %d, saw %d' %
1979 (col_len, row_num + 1, zip_len))
-> 1980 raise ValueError(msg)
1981
1982 if self.usecols:
ValueError: Expected 5 fields in line 1, saw 1上stack overflow搜到的解决方案是把路径中的单斜杠‘\’转换为双斜杠‘\’,依旧报错,保错内容同上。
再找,看到有一条这样的回复:
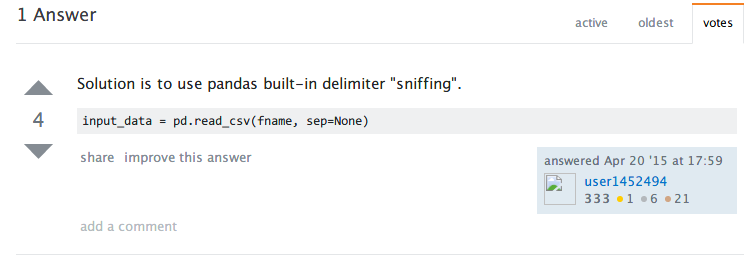
将原先的pd.read_table参数列表的sep = "::"改为sep = None后问题解决。

















 802
802

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









