







 本文介绍了使用Python构建的一个百科爬虫的整体架构和流程,包括调度端、URL管理器、HTML解析器和数据输出器四个关键部分,最终展示爬取结果。
本文介绍了使用Python构建的一个百科爬虫的整体架构和流程,包括调度端、URL管理器、HTML解析器和数据输出器四个关键部分,最终展示爬取结果。
本爬虫的目的是截取某百科下的所有相关链接的标题和简介,最终以html表格的形式呈现
爬虫整体架构
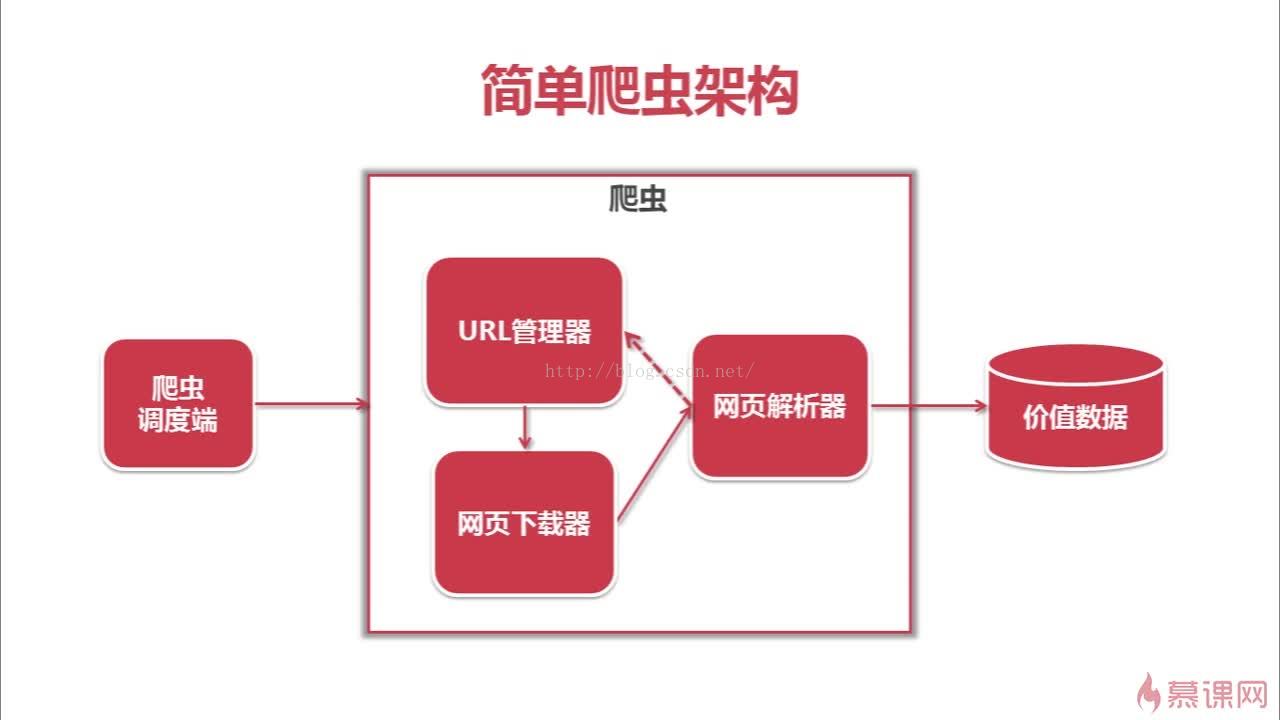
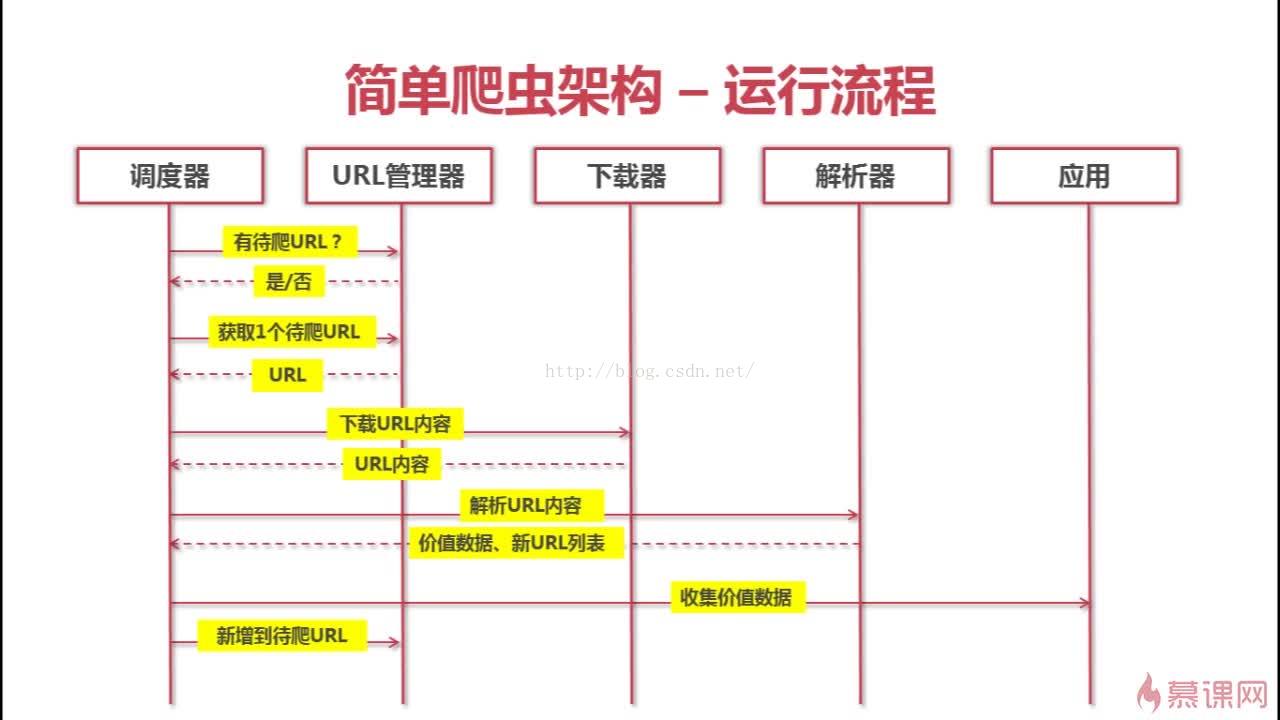
爬虫整体流程
结果展示:

代码部分
调度端- baike_spider:
# coding:utf-8
from baike_spider import url_manager, html_downloader, html_parser, html_outputer
class SpiderMain(object):
def __init__(self) :
self.urls = url_manager.UrlManager()
self.downloader = html_downloader.HtmlDownloader()
self.parser = html_parser.HtmlParser()
self.outputer = html_outputer.HtmlOutputer()
def craw(self,root_url,num):
count = 1
self.urls.add_new_url(root_url) # url管理器加入根链接
while(self.urls.has_new_url()): # 当管理器中存在链 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 964
964

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









