






1. 简述
本次爬取维基百科“百科全书”词条页面内链,仅发送一次请求,获取一个 html 页面,同时不包含应对反爬虫的知识,仅包含最基础的网页爬取、数据清洗、存储为 csv 文件。
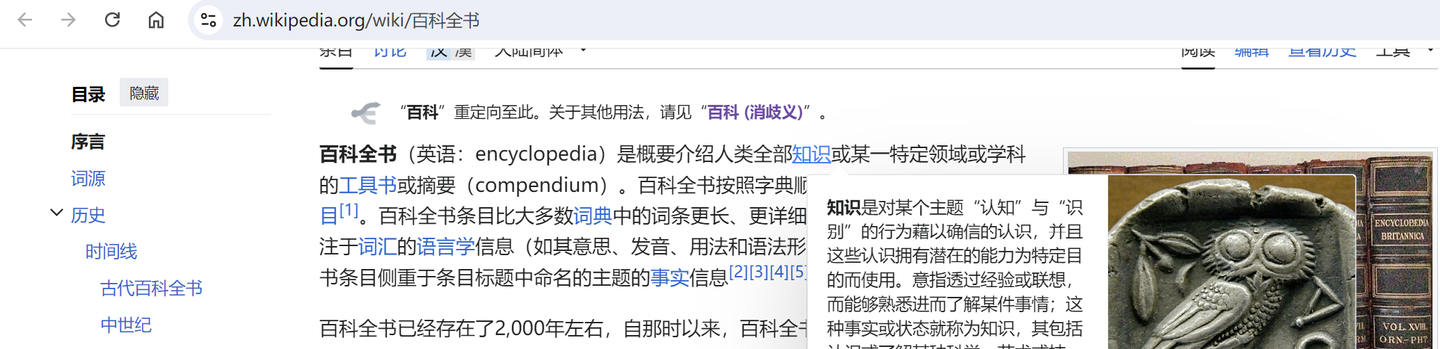
爬取网址 url 为 “https://zh.wikipedia.org/wiki/百科全书”,爬取内容为该页面所有内链及内链标识(下图蓝色字体部分)
将整个爬虫代码拆分为以下四部分介绍,同时列出相应部分代码并详解:
-
导入所需的库
-
请求并返回 “百科全书” 词条页面 html 文档
-
解析 html 文档,获取此页面包含的词条链接信息
-
持久化存储获得的词条链接信息,保存为 csv 文件
步骤 2、3、4 都设置一个函数,最后调用即可。
data = request_html()
results = parse_links(data)
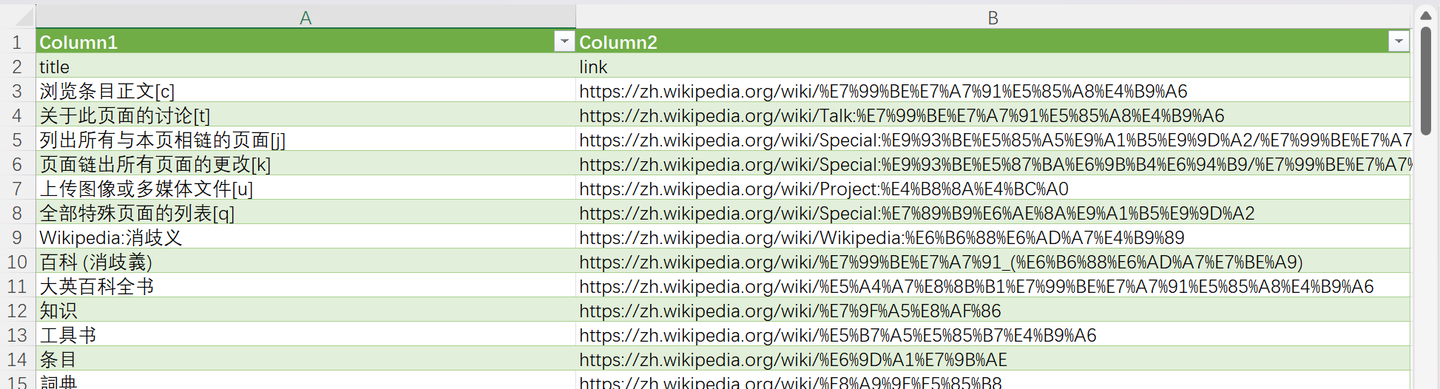
save_csv(results)下图为最终结果:
2. 导入所需库
使用 requests 库中的 get 函数发送请求;
使用 beautifulsoup 库解析 html 网页,同时使用 re 库进行正则匹配,获取想要数据;
使用 csv 库将解析得到的结果存储为 csv 文件。
源码为:
from requests import get
from bs4 import BeautifulSoup
import re
from csv import DictWriter3. 请求并返回 html 文档
设置 请求头headers,将 UA 添加到 headers 中;
使用 get 函数发送请求,获取返回的内容。
源码为:
def request_html():
url = 'https://zh.wikipedia.org/wiki/百科全书'
user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36'
headers = {'user-agent': user_agent}
response = get(url, headers=headers)
return response.text4. 获取所需数据
想要获取所需数据,大致思路为:
首先创建 html 的 BeautifulSoup 实例,为了简单,直接使用内置的 html.parser 解析器;
然后使用 find 与 find_all 函数,通过匹配标签名与属性,获取所需的标签列表;
逐个处理标签列表中的标签,将所需数据以列表形式返回。
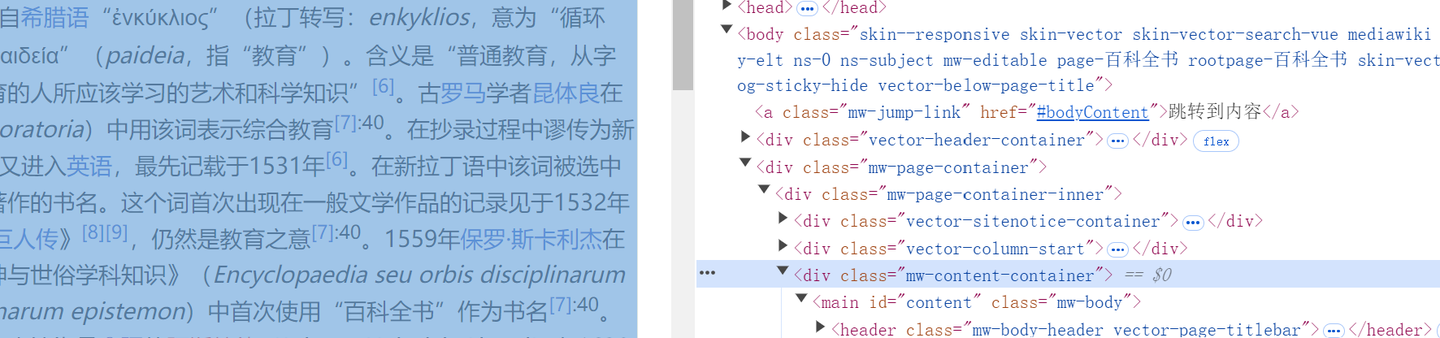
上述思路中,最主要的是通过 find 函数查找到所需标签列表,通过 F12 可知:
整个页面内容部分包含在 “class” 属性值为 “mw-content-container” 的 “div” 标签中,因此可通过 bs对象 查找所需标签 bs.body.find('div', {'class': 'mw-page-container'}).find('div', {'class': 'mw-content-container'})
词条链接都包含在 “a” 标签中,且以 “/wiki/” 开头,因此可通过正则进行匹配 find_all('a', {'href': re.compile('^/wiki/.*')})

源码为:
def parse_links(html_data: str):
bs = BeautifulSoup(html_data, 'html.parser')
tags = bs.body.find('div', {'class': 'mw-page-container'}).find(
'div', {'class': 'mw-content-container'}).find_all(
'a', {'href': re.compile('^/wiki/.*')})
results = []
links = set()
for tag in tags:
link = 'https://zh.wikipedia.org' + tag['href']
if link not in links:
links.add(link)
else:
continue
try:
title = tag['title']
except KeyError:
continue
result = {}
result['title'] = title
result['link'] = link
results.append(result)
return results5. 存储为 csv 文件
将得到的数据直接存储到 csv 文件中即可。
源码为:
def save_csv(data: list[dict]):
with open('inner_links.csv', 'w', encoding='utf-8', newline='') as f:
f_writer = DictWriter(f, ['title', 'link'])
f_writer.writeheader()
f_writer.writerows(data)














 75万+
75万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









