







 本文介绍了如何使用Python开发轻量级网络爬虫,主要用于抓取无需登录和异步加载的静态网页数据,特别是在百度百科上的词条信息。爬虫架构包括URL管理器、网页下载器(urllib2)和网页解析器(BeautifulSoup),可以爬取N个页面的数据。
本文介绍了如何使用Python开发轻量级网络爬虫,主要用于抓取无需登录和异步加载的静态网页数据,特别是在百度百科上的词条信息。爬虫架构包括URL管理器、网页下载器(urllib2)和网页解析器(BeautifulSoup),可以爬取N个页面的数据。
爬虫是一段自动抓取互联网信息的程序。一般情况下采取人工方式从互联网上获取少量的信息,爬虫可以从一个URL出发,访问它所关联的URL,并且从每个页面中获取有价值数据。
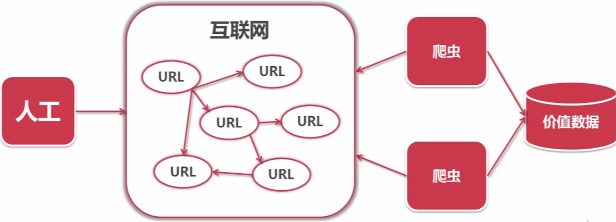
这是轻量级(无需登录和异步加载的静态网页的抓取)网络爬虫的开发,采用python语言编写,主要包括URL管理器、网页下载器(urllib2)、网页解析器(BeautifulSoup),实现百度百科网络爬虫词条相关的N(自行设置)个页面数据,简单爬虫的架构如下:
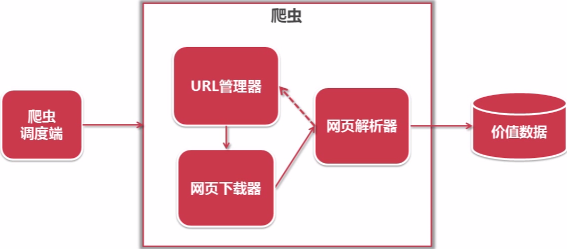
简单爬虫架构流程如下:
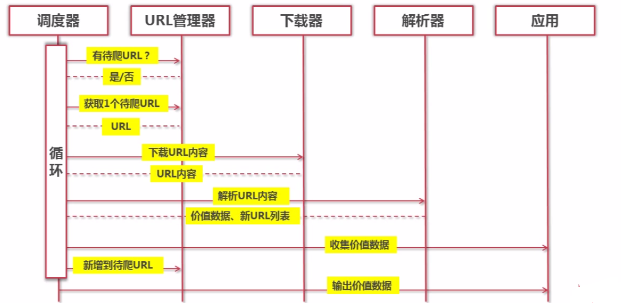
程序按照架构分为以下五个主要的py文件:
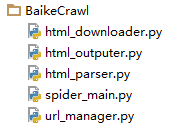
主调度文件为spider_main.py
#coding:utf8
import html_outputer
import html_parser
import url_manager
import html_downloader
class SpiderMain(object):
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5650
5650

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









